一种基于PPO强化学习的机器人恒力控制打磨方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明属于机器人磨抛相关技术领域,更具体地,涉及一种基于PPO强化学习的机器人恒力控制打磨方法。
背景技术
为了实现机器人和环境的稳定交互,越来越需要机器人末端稳定的力控制。基于位置的阻抗控制器用于接收接触力信号以跟踪恒定的期望力。大部分机器人的动力学参数经常难以辨识,而且,这些机器人考虑安全性的影响,开放程度不高,一般不开放底层的控制接口,只提供了位置控制模式,无法直接访问关节电流。在这一类机器人上进行机器人末端力控制时,需要通过生成现有位置控制器的参考轨迹来控制机器人的机械阻抗特性,即基于位置的阻抗控制。
传统阻抗控制的结构简单,在机器人力控制领域中应用较广泛,常用来实现机器人的柔顺控制。在与未知环境接触时,由于缺乏精确的环境参数信息,这会导致较差的接触力控制效果。为了减少接触力的稳态误差,需要事先知道环境的表面位置以及刚度。因此,亟需一种方法实现磨抛过程中接触力的稳态控制。
发明内容
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于PPO强化学习的机器人恒力控制打磨方法,解决磨抛过程中如何实现磨抛力的恒力控制的问题。
为实现上述目的,按照本发明的一个方面,提供了一种基于PPO强化学习的机器人恒力控制打磨方法,该方法包括下列步骤:
S1对于待加工工件的三维模型或点云模型,获取加工该待加工工件的磨抛原始轨迹;
S2选取阻抗控制的方式进行恒力打磨控制,并以此构建包含未知参数的阻抗控制器以及对应的约束条件;
S3实时计算机器人末端的环境刚度和位置,利用计算获得的环境刚度和位置计算机器人法向控制指令,根据该法向控制指令实时调整所述原始轨迹的法向位移,使得实际磨抛力等于预设期望磨抛力;
S4求解所述阻抗控制器中的未知参数进而确定所述阻抗控制器,按照该阻抗控制器对机器人进行恒力打磨。
进一步优选地,在步骤S2中,所述阻抗控制器按照下式进行:
其中,m是惯性系数,b是阻尼系数,k是刚度系数,Δx是机器人末端实际位置x与期望位置x
进一步优选地,在步骤S2中,所述约束条件按照下列步骤获得:
S21计算打磨中环境的初始刚度和阻尼,其中,环境是将打磨工具和工件作为一个整体;
S22利用获得的初始刚度和阻尼构建约束条件。
进一步优选地,在步骤S21中,所述初始刚度和阻尼按照下式进行:
其中,ω
进一步优选地,在步骤S22中,所述约束条件按照下列进行:
其中,m,b,k是阻抗方程中的系数,κ,ξ
进一步优选地,在步骤S3中,所述机器人的法向控制指令按照下式进行:
其中,x
进一步优选地,所述环境刚度和位置按照下式进行:
其中,k
进一步优选地,在步骤S4中,所述未知参数的求解采用强化学习的方法。
进一步优选地,所述强化学习的方法按照下列步骤进行:
S41构建强化学习的奖励函数,设置动作空间和状态空间;
S42将状态空间的参数作为输入,动作空间的参数作为输出构建强化学习策略神经网络,对所述未知参数赋予初始值,当训练的奖励值稳定收敛时停止训练,当前对应的未知参数值即为所需的未知参数值。
进一步优选地,在步骤S41中,所述奖励函数按照下式进行:
所述工作空间按照下式进行:
a=[K
所述状态空间按照下式进行:
其中,Δf是实际力和期望力的偏差,
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具备下列有益效果:
1.本发明构建的阻抗控制器中包括了K
2.本发明在步骤S3中,通过对环境位置和刚度的估计,对原始磨抛轨迹中的法向位移进行补偿,使得实际磨抛力等于预设期望磨抛力,解决阻抗控制器的固有缺陷,实现对实际磨抛力的补偿,提高磨抛精度;
3.本发明步骤S4中对未知参数的求解获得的K
4.本发明通过使用PPO强化学习应用在机器人恒力打磨的控制中。使用李亚诺夫稳定性判定的方法,对环境位置和刚度进行在线估计,调整机器人参考轨迹,减少力跟踪的稳态误差。采用强化学习方法,加入了力闭环控制,无需建立控制参数和磨抛力误差的先验模型,提高恒力跟踪的鲁棒性;
5.本发明为了提高力跟踪性能,采用强化学习的方式进行调整,不需要专家知识,也不需要对底层复杂世界有先验理解,在不断与环境反复交互的过程中,能自主地发现最优行为,所提出的方法旨在将力控制与RL相结合,以在使用位置控制机器人时学习接触恒力磨抛任务。
附图说明
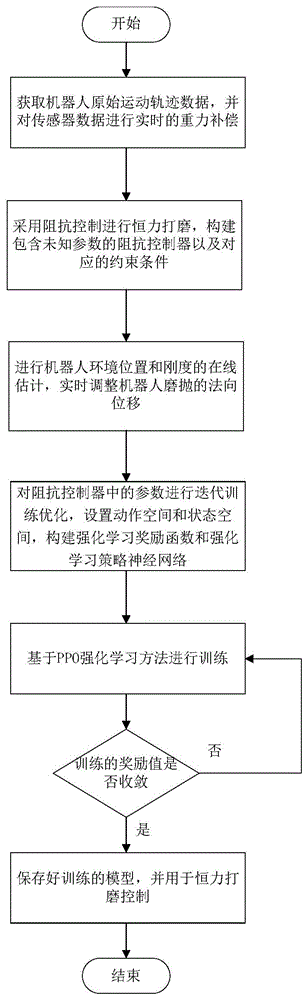
图1是按照本发明的优选实施例构建的一种基于PPO强化学习的机器人恒力控制打磨方法的流程图;
图2是按照本发明的优选实施例的待处理工件的结构图,其中,(a)是斜面工件,(b)是曲面工件;
图3是按照本发明的优选实施例的基于可变遗忘因子的递归最小二乘法得到的环境的初始刚度和阻尼,其中,(a)是估计的刚度,(b)是估计的阻尼;
图4是按照本发明的优选实施例的强化学习价值函数网络结构和策略网络结构的设计图,其中,(a)是强化学习价值函数网络结构示意图,(b)是策略网络结构的设计图;
图5是按照本发明的优选实施例构建的机器人基于强化学习磨抛恒力控制框图;
图6是按照本发明的优选实施例的强化学习训练100次奖励值图像;
图7是按照本发明的优选实施例的实际打磨力跟踪图,其中,(a)是机器人强化学习训练后斜面打磨力跟踪图,(b)是机器人强化学习训练后曲面打磨力跟踪图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,一种基于PPO强化学习的机器人恒力控制打磨方法,具体包括如下步骤:
S1通过工件的三维模型或点云模型获取机器人磨抛原始轨迹数据。
通过工件的三维模型或者点云,通过轨迹生成方法,生成机器人的磨抛初始轨迹。
S2通过递归增广最小二乘法估计环境初始刚度和阻尼,设计机器人阻抗控制器,选择合适的阻抗参数,在本实施例中,环境是指将打磨工具和工件作为一个整体的。
S21采用递归增广最小二乘法来对机器人末端和工件的等效刚度进行初始估计,采用可变的遗忘因子λ,
设打磨工具和工件接触的动力学为
其中,f
则需要估计的参数使用RELS递推公式如下所示:
其中增益向量L(k+1)如下计算:
最终得到环境的初始刚度和阻尼:
最终得到的实验结果如图3所示。
其中
S22采用阻抗控制的方式来进行恒力打磨控制,现有的阻抗控制的控制方程如下
在此范围内,进行阻抗参数选择,选定m,k参数,则b可以通过
S23构造阻抗控制器,
S3采用李雅普诺夫稳定性方法,进行环境位置和刚度参数的估计,调整机器人磨抛的原始轨迹,减少稳态误差。
通过李雅普诺夫稳定性的方法,根据环境刚度和位置的估计方程:
其中,k
S4计算K
S41分析恒力控制的影响因素,构建强化学习奖励函数,设置动作空间和状态空间。
机器人训练的目标是尽可能使得机器人末端实际接触力与期望接触力更小,使得机器人末端法向的速度更小。
设置的奖励函数为
设置强化学习的动作空间为a=[K
S42构建强化学习策略神经网络,基于PPO强化学习方法进行训练,并用训练好的模型进行机器人恒力打磨控制。
如图4所示,为强化学习训练过程中的深度神经网络的设计,包含策略网络的设计和价值函数的网络设计。因为训练的参数并不太复杂,采用三层神经网络的结构进行训练,每层网络128个节点,各隐藏层之间的激活函数为Tanh激活函数,策略网络的输出为高斯分布的采样值。
训练数据是通过设定了初始值的K
对训练数据进行归一化,对神经网络的输入状态量和输出状态量进行归一化,都除以各自对应的上限值,使的神经网络的输入和输出的值域都为[-1,1]。通过阻抗方程得到的控制指令为[p
在本实施例中,还需对测量到的六维力传感器数据进行重力补偿,机器人末端设置打磨工具,传感器设置在机器人末端和打磨工具之间,传感器显示的结果包括了打磨工具的重力和打磨过程中与工件的接触力,重力补偿的在于减去打磨工具的重力以此获得打磨工具与工件的接触力。具体为:通过最小二乘法计算得到机器人末端工具的质心[x,y,z]、重力[g
采用PPO强化学习方法进行机器人磨抛恒力控制,加工过程总共包含750个控制周期,控制频率为50Hz,力传感器的频率为125Hz,其中前200个控制周期为机器人接近阶段。
如图5所示,整个机器人控制步骤如下:
设置初始轨迹和期望力,初始化PPO强化学习算法。
估计环境的刚度和位置,调整机器人的参考运动轨迹,机器人沿着参考轨迹运动,计算力误差Δf=f
选择动作(K
计算当前K
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。