一种基于深度学习的单目标快速检测方法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明涉及计算机视觉的技术领域,尤其涉及一种基于深度学习的单目标快速检测方法。
背景技术
目标检测(Object Detection,OD)是计算机视觉领域的核心问题之一,目标检测的基本任务是分类和定位,即找出图像或视频中的感兴趣物体,同时检测出它们的位置和大小。目前,目标检测方法可以分为两大类:传统的目标检测算法和基于深度学习的目标检测算法。
传统的目标检测算法是基于滑动窗口遍历进行区域选择,然后使用方向梯度直方图(Histogram of Oriented Gradient,HOG)、尺度不变特征变换(scale-invariantfeature transform,SIFT)等特征对滑动窗口内的图像块进行特征提取,最后使用支持向量机(Support Vector Machine,SVM)、AdaBoost等分类器对已提取特征进行分类。这种目标检测方法需要手工构建特征,构建过程较为复杂,检测精度提升非常有限,对复杂背景的适应能力差。目前,更多的研究转向基于深度学习的方法。
基于深度学习的目标检测算法主要使用卷积神经网络(Convolutional NeuralNetworks,CNN)对图像特征进行提取,并通过池化、采样等操作完成对目标的检测。一般来讲,网络的性能与网络的深度成正相关。为了提取更多的图像信息,网络的深度不断加深,网络的参数越来越庞大。尽管性能上有很大提升,但由于网络规模庞大,目标检测的实时性严重依赖计算能力,这大大限制了这类算法在移动平台的部署。
发明内容
为解决现有技术存在的局限和缺陷,本发明提供一种基于深度学习的单目标快速检测方法,包括:
步骤S1、对视频序列进行检测;
步骤S2、在初始状态或者上一帧图像未检测出目标位置的情况下,使用滑动窗口的方法,对整个图像进行遍历,将每个窗口的图像送入卷积神经网络进行计算,直到检测出目标位置信息;
步骤S3、由于目标的运动过程是连续的,上一帧图像中目标位置与当前帧图像中目标位置之间的差距在一定范围之内,当上一帧图像中目标位置信息已经确定时,根据所述上一帧图像中目标位置信息形成滑动窗口对当前帧图像进行检测,所述上一帧图像为k-1帧,所述当前帧图像为k帧,所述上一帧图像中目标位置信息为(x
步骤S4、将中心坐标为(x
步骤S5、若判断结果为所述窗口存在目标位置信息,执行步骤S6;若判断结果为所述窗口不存在目标位置信息,执行步骤S2;
步骤S6、进行下一帧图像的检测。
可选的,所述步骤1之前包括如下步骤:
设置网络的损失函数,所述损失函数包括预测中心坐标损失函数、预测边界框尺寸损失函数、预测类别损失函数和预测置信度损失函数;
所述预测中心坐标损失函数的计算公式为:
其中,λ
所述预测边界框尺寸损失函数的计算公式为:
其中,(w,h)为预测框尺寸,
所述预测类别损失函数的计算公式为:
其中,
所述预测置信度损失函数的计算公式为:
其中,c
设置网络的总损失函数为J,J的计算公式如下:
J=L
根据误差计算权重更新梯度,计算公式如下:
其中,g
通过基于梯度的优化算法更新权重,计算公式如下:
本发明具有下述有益效果:
本发明提供的基于深度学习的单目标快速检测方法,对视频序列进行检测,在初始状态或者上一帧未检测出目标位置的情况下,使用滑动窗口的方法,对整个图像进行遍历,将每个窗口的图像送入卷积神经网络进行计算,直到检测出目标位置信息,然后开始进行下一帧图像检测。由于目标的运动是连续的过程,前后两帧图像的位置之差在预设的范围内。当上一帧图像中目标位置信息(x
由于神经网络的规模和网络输入大小息息相关,本发明提供的技术方案通过控制网络的输入大小就能够对网络进行优化,保证性能的同时降低网络的规模,提高网络的计算速度,进而提高目标检测算法的实时性。
本发明提供的技术方案通过减小神经网络输入的大小,能够保证高精度的同时降低网络规模,有效提高神经网络的推理速度,提高了目标检测算法的实时性。另外,在目标检测过程中,本发明只把高价值窗口图像送入网络进行运算,有效避免了低价值区域的干扰信息,有利于提高算法的精度。
附图说明
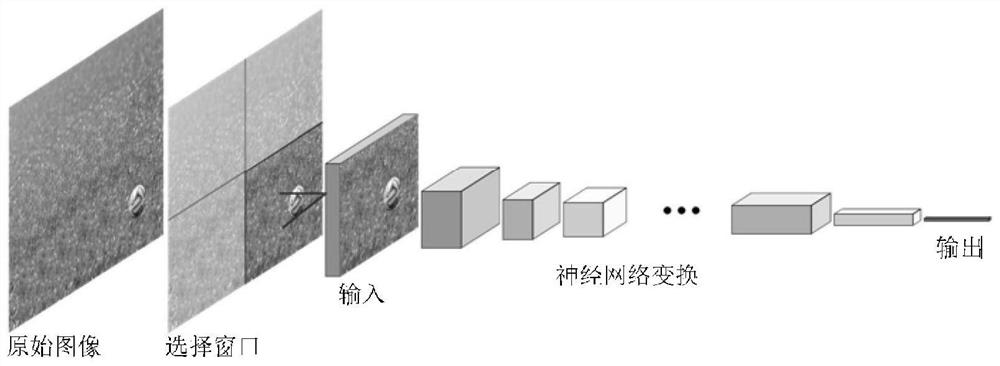
图1为本发明实施例一提供的基于深度学习的单目标快速检测方法的总体架构示意图。
图2为本发明实施例一提供的基于深度学习的当前帧运算示意图。
图3为本发明实施例一提供的基于深度学习的单目标快速检测方法的算法流程图。
具体实施方式
为使本领域的技术人员更好地理解本发明的技术方案,下面结合附图对本发明提供的基于深度学习的单目标快速检测方法进行详细描述。
实施例一
图1为本发明实施例一提供的基于深度学习的单目标快速检测方法的总体架构示意图。如图1所示,本实施例提出一种基于深度学习的单目标快速检测方法,由于原始图像较大,在检测过程中大多区域不包含目标信息,这部分区域可以不送入神经网络进行运算,本算法在在原始图像的基础上,选择高价值的窗口,送入神经网络进行运算,能有效提高算法的实时性。
本实施例对视频序列进行检测,在初始状态或上一帧未检测出目标位置的情况下,采用滑动窗口的方法,对整个图像进行遍历,将每个窗口的图像送入神经网络进行计算,直到检测出目标位置信息,然后开始进行下一帧图像检测。
图2为本发明实施例一提供的基于深度学习的当前帧运算示意图,图3为本发明实施例一提供的基于深度学习的单目标快速检测方法的算法流程图。如图2和图3所示,由于目标的运动是连续的过程,前后两帧图像中位置之差在一定范围。当上一帧(k-1帧)图像中目标位置信息(x
本实施例提供的基于深度学习的单目标快速检测方法,主要的意义在于提升了单目标检测算法的速度,通过控制输入大小,使得小规模的神经网络能够完成目标检测任务并具有较高的精度。
本发明提供的基于深度学习的单目标快速检测方法,对视频序列进行检测,在初始状态或者上一帧未检测出目标位置的情况下,使用滑动窗口的方法,对整个图像进行遍历,将每个窗口的图像送入卷积神经网络进行计算,直到检测出目标位置信息,然后开始进行下一帧图像检测。由于目标的运动是连续的过程,前后两帧图像的位置之差在预设的范围内。当上一帧图像中目标位置信息(x
本实施例对原始图像进行窗口选择,降低了网络的输入大小,加速了网络计算速度,提高了算法的实时性。在相邻图像帧的检测过程中,后一帧利用前一帧的目标位置信息,根据目标位置信息生成图像窗口,降低了运算总量。另外,本实施例提供的技术方案通过窗口选择高价值区域,有效屏蔽了图像中低价值区域的干扰,提升了目标检测的精度。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 一种基于深度学习的单目标快速检测方法
- 一种基于深度学习的单类目标检测方法、设备及存储介质