早发型败血症的预测方法及系统
文献发布时间:2023-06-19 11:42:32
技术领域
本发明涉及医疗领域,尤其涉及早发型败血症的预测方法及系统。
背景技术
早发型败血症(Neonatal Early Onset Sepsis,EOS)是造成围产期新生儿死亡的重要原因。EOS是指出生7天内发生的侵袭性感染,总体发生率约为1-2‰,足月儿和极低出生体重儿死亡率约为3%和16%。造成新生儿EOS的病原菌来至于母体,其中母亲生殖道细菌上行感染是引起新生儿EOS的主要原因。鉴于新生儿败血症的严重损害后果,目前国际上现有指南均推荐根据母亲高危因素的情况,对无症状新生儿进行预防性抗生素应用。这种抗生素应用策略缺乏精准性,大大增加了新生儿期的抗生素暴露。
抗生素暴露可增加早产儿发生坏死性小肠结肠炎、晚发型败血症及死亡的风险。预防性抗生素应用必然增加医疗费用、造成母婴分离,影响母乳喂养以及诱导细菌耐药等。新生儿期抗生素暴露导致的远期不良后果近年来也得到了广泛关注。瑞典出生队列研究发现,新生儿期抗生素暴露增加儿童期喘息的风险。同样,荷兰出生队列研究表明,新生儿期抗生素暴露与肠道菌群改变相关,且增加婴儿特应性皮炎的发生有关。动物研究亦证明,新生期抗生素暴露明显影响成年期肠道菌群以及喘息等呼吸系统疾病的发生。因此,对具有感染高危因素、无症状新生儿进行精准、规范化管理,是一个非常重要的临床问题。
综上所述,目前对新生儿的早发型败血症的预防治疗策略精准性低,存在增加新生儿期抗生素暴露的缺陷。
发明内容
针对目前无法精准预测新生儿的早发型败血症的风险问题,现提供一种旨在可提高预测新生儿的早发型败血症的准确性,降低新生儿期抗生素暴露概率的早发型败血症的预测方法及系统。
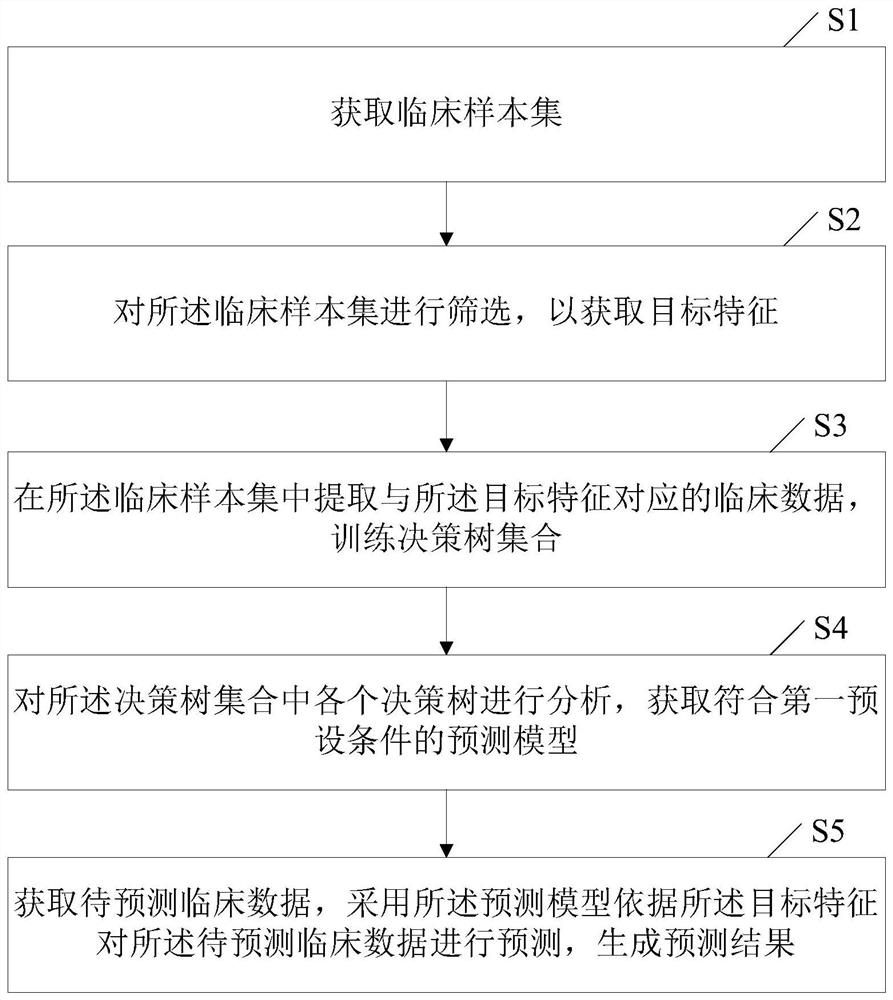
本发明提供了一种早发型败血症的预测方法,包括:
获取临床样本集;
对所述临床样本集进行筛选,以获取目标特征;
在所述临床样本集中提取与所述目标特征对应的临床数据,训练决策树集合;
对所述决策树集合中各个决策树进行分析,获取符合第一预设条件的预测模型;
获取待预测临床数据,采用所述预测模型依据所述目标特征对所述待预测临床数据进行预测,生成预测结果。
可选的,所述临床样本集中包括多个患者的临床数据,每个所述患者的临床数据中包括多个临床特征;
对所述临床样本集进行筛选,以获取目标特征,包括:
对所述临床样本集中各个所述患者的所述临床特征进行分类,以获取分类变量和连续变量;
采用卡方检验法和费希尔精确检验法分析所述分类变量与患早发型败血症的概率关系,将概率值符合第二预设条件的分类变量所对应的临床特征作为所述目标特征;
采用t检测法和Mann-Whitney U检测法分析所述连续变量与患早发型败血症的概率关系将概率值符合第二预设条件的连续变量所对应的临床特征作为所述目标特征。
可选的,对所述决策树集合中各个决策树进行分析,获取符合第一预设条件的预测模型,包括:
计算所述决策树集合中每一个决策树的性能系数;
提取所述性能系数符合第三预设条件的所述决策树;
采用预设评价策略对所述决策树进行评估,以确定预测模型。
可选的,所述预设评价策略为采用PR曲线对所述决策树进行评估。
可选的,所述目标特征包括:母亲分娩前最高体温、母亲分娩时孕周、母亲分娩前最后一个血常规中白细胞计数、母亲分娩前最后一个血常规中的中性粒细胞比例、母亲分娩前最后一个血常规中的血小板计数和破膜时间。
本发明还提供了一种早发型败血症的预测系统,包括:
获取单元,用于获取临床样本集;
筛选单元,用于对所述临床样本集进行筛选,以获取目标特征;
训练单元,用于在所述临床样本集中提取与所述目标特征对应的临床数据,训练决策树集合;
分析单元,用于对所述决策树集合中各个决策树进行分析,获取符合第一预设条件的预测模型;
预测单元,用于获取待预测临床数据,采用所述预测模型依据所述目标特征对所述待预测临床数据进行预测,生成预测结果。
可选的,所述临床样本集中包括多个患者的临床数据,每个所述患者的临床数据中包括多个临床特征;
所述筛选单元包括:
分类模块,用于对所述临床样本集中各个所述患者的所述临床特征进行分类,以获取分类变量和连续变量;
第一检验模块,用于采用卡方检验法和费希尔精确检验法分析所述分类变量与患早发型败血症的概率关系,将概率值符合第二预设条件的分类变量所对应的临床特征作为所述目标特征;
第二检验模块,采用t检测法和Mann-Whitney U检测法分析所述连续变量与患早发型败血症的概率关系将概率值符合第二预设条件的连续变量所对应的临床特征作为所述目标特征。
可选的,所述分析单元包括:
计算模块,用于计算所述决策树集合中每一个决策树的性能系数;
提取模块,用于提取所述性能系数符合第三预设条件的所述决策树;
评估模块,用于采用预设评价策略对所述决策树进行评估,以确定预测模型。
可选的,所述预设评价策略为采用PR曲线对所述决策树进行评估。
可选的,所述目标特征包括:母亲分娩前最高体温、母亲分娩时孕周、母亲分娩前最后一个血常规中白细胞计数、母亲分娩前最后一个血常规中的中性粒细胞比例、母亲分娩前最后一个血常规中的血小板计数和破膜时间。
上述技术方案的有益效果:
本技术方案中,早发型败血症的预测方法及系统主要用于预测新生儿的早发型败血症概率。通过对临床样本集进行筛选,以确定与患有早发型败血症有重要关联的目标特征;在临床样本集中提取与目标特征对应的临床数据,训练决策树集合,对决策树集合中各个决策树进行分析,获取符合第一预设条件的预测效果最优的预测模型;当需要对患者的早发型败血症概率进行预测时,可采用预测模型依据目标特征对待预测临床数据进行预测,根据预测结果了解患者的患病概率,以便于降低新生儿期抗生素暴露概率。
附图说明
图1为本发明所述的早发型败血症的预测方法的一种实施例的流程图;
图2为对临床样本集进行筛选获取目标特征的一种实施例的流程图;
图3为对决策树集合中各个决策树进行分析的一种实施例的流程图;
图4为本发明所述的早发型败血症的预测系统的一种实施例的模块图;
图5为本发明筛选单元的一种实施例内部模块图;
图6为本发明分析单元的一种实施例内部模块图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
实施例一
参阅图1,本实施例提供了一种早发型败血症的预测方法,包括以下步骤:
S1.获取临床样本集。
本实施例中,所述临床样本集中包括多个患者的临床数据,每个所述患者的临床数据中包括多个临床特征。
本实施例的早发型败血症的预测方法用于预测新生儿的早发型败血症概率。在实际应用中,临床样本集可包括由产妇的人口学统计数据、产前化验指标以及新生儿出生后5min内指标等临床数据,、以便于根据上述临床数据更加精准的筛选患儿,避免不必要的预防性抗生素的使用。
S2.对所述临床样本集进行筛选,以获取目标特征。
需要说明的是:本实施例中的所述目标特征可包括:母亲分娩前最高体温、母亲分娩时孕周、母亲分娩前最后一个血常规中白细胞计数、母亲分娩前最后一个血常规中的中性粒细胞比例、母亲分娩前最后一个血常规中的血小板计数和破膜时间(胎膜破裂时间与分娩时间之间的差值)。
在本实施例中,通过对各个临床特征进行筛选,以找到单因素显著的目标特征,以便于在训练决策树之前,减少变量数量,提升计算精度。
具体地,参阅图2步骤S2可包括以下步骤:
S21.对所述临床样本集中各个所述患者的所述临床特征进行分类,以获取分类变量和连续变量。
S22.采用卡方检验法和费希尔精确检验法分析所述分类变量与患早发型败血症的概率关系,将概率值符合第二预设条件的分类变量所对应的临床特征作为所述目标特征。
卡方检验法或称χ2检验(chi-square test)是一种假设检验方法。可以采用成组比较(不配对资料)和个别比较(配对,或同一对象两种处理的比较)两种方式对分类变量进行检验。费希尔精确检验法(Fisher's exact test)是用于分析列联表(contingencytables)统计显著性检验方法,它可用于检验两个分类的关联(association)性。在本实施例中,根据分类变量的分布,将满足卡方检验法的变量采用卡方检验法进行检验分析,将不满足卡方检验法的变量采用费希尔精确检验法进行检验分析。
作为举例而非限定,第二预设条件可以是概率值p<0.05,符合该条件表示具有统计学意义。将概率值p<0.05的分类变量所对应的临床特征作为所述目标特征。
S23.采用t检测法和Mann-Whitney U检测法分析所述连续变量与患早发型败血症的概率关系将概率值符合第二预设条件的连续变量所对应的临床特征作为所述目标特征。
Mann-Whitney U检验法是两独立样本秩和检验方法。简单的说,该检验是与独立样本t检验相对应的方法,当正态分布、方差齐性等不能达到t检验的要求时,可以使用该检验。其假设基础是:若两个样本有差异,则他们的中心位置将不同。
在本实施例中,根据连续变量的分布,将满足t检测法的变量采用t检测法进行检验分析,将不满足t检测法的变量采用Mann-Whitney U检验法进行检验分析。
作为举例而非限定,第二预设条件可以是概率值p<0.05,符合该条件表示具有统计学意义。将概率值p<0.05的连续变量所对应的临床特征作为所述目标特征。
S3.在所述临床样本集中提取与所述目标特征对应的临床数据,训练决策树集合。
在本实施例中,可采用随机森林(RF)训练决策树集合。随机森林是一种高度灵活的机器学习算法。与其他机器学习方法(例如神经网络或支持向量机)不同,随机森林是一种集成算法,可使模型的结果具有较高的精确度和泛化性能。
作为举例而非限定,可利用Scikit-learn(是针对Python编程语言的免费软件机器学习库)使用Bootstraping方法(指的就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布的新样本)随机有放回采样取出样本集,将由目标特征构成的数据集中70%的数据用于训练50棵决策树。最后集成50棵弱决策树(每棵决策树之间是相互独立的),取所有决策树的平均值作为分类器的最终概率。每棵决策树的最大深度(maxdepth)设为5,每棵决策树可用的最大特征数(maxfeatures)为特征总数的平方根;叶子节点的最小样本数(min samples leaf)设为2,内部节点再划分所需最小样本数(minsamplessplit)为3,其余参数都为缺省值(Default)。在50棵决策树中,每个特征x
其中,K表示结局的分类,p
S4.对所述决策树集合中各个决策树进行分析,获取符合第一预设条件的预测模型。
具体地,参与图3步骤S4可包括以下步骤:
S41.计算所述决策树集合中每一个决策树的性能系数。
S42.提取所述性能系数符合第三预设条件的所述决策树。
本实施例中,将每棵树中由x
作为举例而非限定,可分别用全部临床特征、单因素显著的目标特征和特征重要性排序,依据目标特征和性能系数建立RF32、RF16和RF15预测模型。
作为举例而非限定,第三预设条件为性能系数达到预设阈值。
S43.采用预设评价策略对所述决策树进行评估,以确定预测模型。
进一步地,所述预设评价策略为采用PR(Precision-Recall)曲线对所述决策树进行评估。
作为举例而非限定,将由目标特征构成的数据集中剩余的30%的数据用于内部验证以评估预测模型的稳定性,在该数据集上对比所有模型和临床实践及AAP指南。具体如下:
采用Precision-Recall(PR)曲线作为评价模型预测能力的重要指标,由于数据的高度不平衡性,还可结合受试者工作特征曲线(Receiver Operating Characteristiccurve,ROC)评价指标。PR曲线中的横、纵坐标分别为查全率Recall和查准率Precision参阅(公式1)。基于经验的临床实践参阅(公式2)使用抗生素的查准率Precision和查全率Recall分别为30%和12%,基于AAP指南参阅(公式3)使用抗生素的查准率Precision和查全率Recall分别为20.7%和6.5%。
公式1:Precision=TP/(TP+FP);Recall=TP/(TP+FN)
其中,其中TP表示被模型正确预测为感染的新生儿,FP表示被模型错误预测为感染的新生儿,FN表示被模型错误预测为未感染的新生儿;
公式2:Precision=实际打预防性抗生素的感染新生儿/所有感染新生儿=68/227=30%;Recall=实际打预防性抗生素的感染新生儿/所有使用抗生素的新生儿=68/565=12%;
公式3:Precision=基于AAP指南的指征需要打预防性抗生素的感染新生儿/所有感染新生儿=47/227=20.7%;Recall=基于AAP指南的指征需要打预防性抗生素的感染新生儿/所有使用抗生素的新生儿=47/724=6.5%。
在本实施例中,基于查全率Recall和查准率Precision判断预测模型在临床中使用的量化效果,从而确定最终的预测模型。
基于某医院出生队列母儿临床数据库,利用本实施例的早发型败血症的预测方法,采用机器学习技术建立了高危因素新生儿预测模型。该模型纳入了母亲的产前体温、孕周、血常规中白细胞计数、中性粒细胞比例及血小板计数及破膜时间等六个临床特征,使用非线性的随机森林算法建模,选择使训练集召回率达到100%的截断点(cutoff)0.03388应用模型,其敏感性73.2%,特异性82.4%,阳性预测值10.4%,阴性预测值99.1%,ROC_AUC0.842,得到预测模式。基于本实施例的预测模型可知:只有30%的高危人群需要预防性抗生素应用,剩余的70%的患者只需加强临床观察及完善实验室检查,大大减少了抗生素的暴露,且其阴性预测值极高,0.9%的患者可以通过后续的临床严密监测被发现并给予及时的干预。
S5.获取待预测临床数据,采用所述预测模型依据所述目标特征对所述待预测临床数据进行预测,生成预测结果。
在本实施例中,早发型败血症的预测方法通过对临床样本集进行筛选,以确定与患有早发型败血症有重要关联的目标特征;在临床样本集中提取与目标特征对应的临床数据,训练决策树集合,对决策树集合中各个决策树进行分析,获取符合第一预设条件的预测效果最优的预测模型;当需要对患者的早发型败血症概率进行预测时,可采用预测模型依据目标特征对待预测临床数据进行预测,根据预测结果了解患者的患病概率,以便于降低新生儿期抗生素暴露概率。
实施例二
参阅图4,本实施例提供了一种早发型败血症的预测系统1,包括:获取单元11、筛选单元12、训练单元13、分析单元14和预测单元15。
获取单元11,用于获取临床样本集。
本实施例中,所述临床样本集中包括多个患者的临床数据,每个所述患者的临床数据中包括多个临床特征。
本实施例的早发型败血症的预测方法用于预测新生儿的早发型败血症概率。在实际应用中,临床样本集可包括由产妇的人口学统计数据、产前化验指标以及新生儿出生后5min内指标等临床数据,、以便于根据上述临床数据更加精准的筛选患儿,避免不必要的预防性抗生素的使用。筛选单元12,用于对所述临床样本集进行筛选,以获取目标特征。
需要说明的是:所述目标特征可包括:母亲分娩前最高体温、母亲分娩时孕周、母亲分娩前最后一个血常规中白细胞计数、母亲分娩前最后一个血常规中的中性粒细胞比例、母亲分娩前最后一个血常规中的血小板计数和破膜时间。
在本实施例中,通过对各个临床特征进行筛选,以找到单因素显著的目标特征,以便于在训练决策树之前,减少变量数量,提升计算精度。
具体地,参阅图5所述筛选单元12可包括:分类模块121、第一检验模块122和第二检验模块123。
分类模块121,用于对所述临床样本集中各个所述患者的所述临床特征进行分类,以获取分类变量和连续变量。
第一检验模块122,用于采用卡方检验法和费希尔精确检验法分析所述分类变量与患早发型败血症的概率关系,将概率值符合第二预设条件的分类变量所对应的临床特征作为所述目标特征。
第二预设条件可以是概率值p<0.05,符合该条件表示具有统计学意义。将概率值p<0.05的分类变量所对应的临床特征作为所述目标特征。
第二检验模块123,采用t检测法和Mann-Whitney U检测法分析所述连续变量与患早发型败血症的概率关系将概率值符合第二预设条件的连续变量所对应的临床特征作为所述目标特征。
第二预设条件可以是概率值p<0.05,符合该条件表示具有统计学意义。将概率值p<0.05的连续变量所对应的临床特征作为所述目标特征。
训练单元13,用于在所述临床样本集中提取与所述目标特征对应的临床数据,训练决策树集合。
分析单元14,用于对所述决策树集合中各个决策树进行分析,获取符合第一预设条件的预测模型。
具体地,参阅图6所述分析单元14可包括:计算模块141、提取模块142和评估模块143。
计算模块141,用于计算所述决策树集合中每一个决策树的性能系数。
提取模块142,用于提取所述性能系数符合第三预设条件的所述决策树。
本实施例中,将每棵树中由x
作为举例而非限定,第三预设条件为性能系数达到预设阈值。
评估模块143,用于采用预设评价策略对所述决策树进行评估,以确定预测模型。
进一步地,所述预设评价策略为采用PR曲线对所述决策树进行评估。
在本实施例中,基于查全率Recall和查准率Precision判断预测模型在临床中使用的量化效果,从而确定最终的预测模型。
预测单元15,用于获取待预测临床数据,采用所述预测模型依据所述目标特征对所述待预测临床数据进行预测,生成预测结果。
在本实施例中,早发型败血症的预测系统1采用筛选单元12对临床样本集进行筛选,以确定与患有早发型败血症有重要关联的目标特征;利用训练单元13在临床样本集中提取与目标特征对应的临床数据,训练决策树集合,通过分析单元14对决策树集合中各个决策树进行分析,获取符合第一预设条件的预测效果最优的预测模型;当需要对患者的早发型败血症概率进行预测时,预测单元15可采用预测模型依据目标特征对待预测临床数据进行预测,根据预测结果了解患者的患病概率,以便于降低新生儿期抗生素暴露概率。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 早发型败血症的预测方法及系统
- 败血症的预后的预测方法