表格识别方法、设备及计算机可读存储介质
文献发布时间:2023-06-19 11:54:11
技术领域
本发明涉及金融科技领域,尤其涉及一种表格识别方法、设备及计算机可读存储介质。
背景技术
随着互联网信息技术的高速发展,企业凭借建设的信息系统逐渐实现业务流程的信息化。而如银行等金融机构由于其自身业务的需要,在业务流程中往往会产生大量的纸质单据和报表,当下游业务系统需要用到纸质表单中的数据时,通常需要业务人员手工录入,然而,人工录入表单数据的方式,显然无法满足爆炸式增长的需求,从而影响下游业务对数据的使用和工作效率,因此需要将纸质表单录入到信息化系统中以实现持久化存储,同时方便下游业务对数据的调用。
现有的将纸质单据表格转化到信息系统中存储的方法中,大多是通过人工配置模板进行匹配来获取表格特定位置的感兴趣区域,进而对纸质单据进行实时处理,或者是利用深度学习网络模型对表格图像的表格线进行定位,进而确定表格图像中各单元格的位置信息。在实际应用中,海量纸质表格的格式和内容千差万别,如果通过人工配置模板的方法进行识别,用于配置模板的工作量并不亚于手工录入表单,且工作内容更为繁琐与沉重,对表格图像的识别准确率过于依赖配置模板的精准度;如果利用深度学习网络模型进行识别,在构建深度学习模型识别网络时需要大量时间,而且构建的识别模型在对单元格的定位上存在较大偏差,从而造成整个表格识别准确率很低。
发明内容
本发明的主要目的在于提供一种表格识别方法、设备及计算机可读存储介质,旨在解决现有表格识别方法识别准确率低的技术问题。
此外,为实现上述目的,本发明还提供一种表格识别方法,所述表格识别方法包括以下步骤:
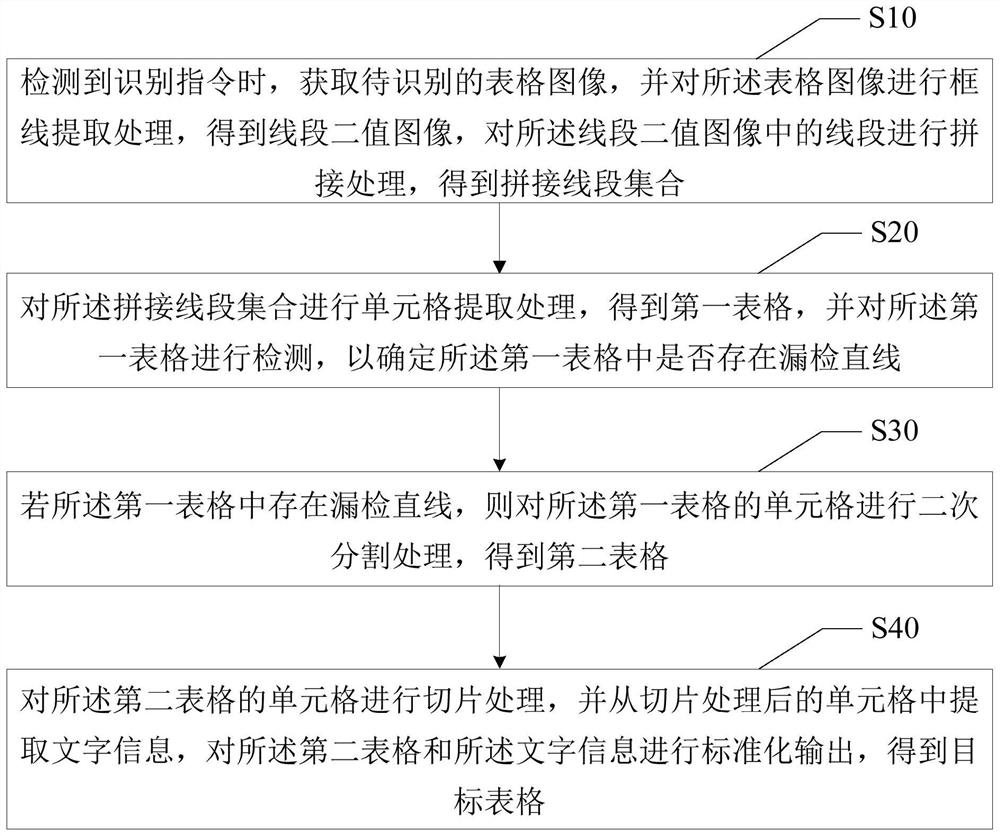
检测到识别指令时,获取待识别的表格图像,并对所述表格图像进行框线提取处理,得到线段二值图像,对所述线段二值图像中的线段进行拼接处理,得到拼接线段集合;
对所述拼接线段集合进行单元格提取处理,得到第一表格,并对所述第一表格进行检测,以确定所述第一表格中是否存在漏检直线;
若所述第一表格中存在漏检直线,则对所述第一表格的单元格进行二次分割处理,得到第二表格;
对所述第二表格的单元格进行切片处理,并从切片处理后的单元格中提取文字信息,对所述第二表格和所述文字信息进行标准化输出,得到目标表格。
可选地,所述对所述表格图像进行框线提取处理之前的步骤,包括:
对所述表格图像进行干扰检测,以确定是否对所述表格图像进行预处理;
若需要对所述表格图像进行预处理,则对所述表格图像进行矫正和/或去干扰处理;
其中,对所述表格图像进行矫正处理的步骤包括:
对所述表格图像进行二值化处理,得到二值化图像,并对所述二值化图像进行变换处理,以对所述二值化图像的线段进行检测并计算所述表格图像中的表格的倾斜角;
根据所述倾斜角对所述表格图像进行矫正处理;
对所述表格图像进行去干扰处理的步骤包括:
对所述表格图像进行二值化处理,以对所述表格图像进行特征统计,得到干扰信息的特征信息;
根据所述特征信息,对所述表格图像中除所述干扰信息之外的有效信息进行滤波处理,并对被所述干扰信息遮挡的区域进行增强处理,以从所述表格图像中去除所述干扰信息。
可选地,所述对所述表格图像进行框线提取处理,得到线段二值图像的步骤,包括:
对所述表格图像进行灰度处理,得到目标灰度图像;
对所述目标灰度图像进行腐蚀和膨胀处理,得到第一目标图像;
对所述第一目标图像进行高斯和二值化处理,得到第二目标图像;
获取结构元素,并根据所述结构元素对所述第二目标图像进行开运算,得到线段二值图像。
可选地,所述对所述线段二值图像中的线段进行拼接处理,得到拼接线段集合的步骤,包括:
对所述线段二值图像进行霍夫变换处理,得到第一线段集合;
建立直角坐标系并根据建立的直角坐标系,对所述第一线段集合中的线段进行排序,获取排序后的线段的位置信息和线段之间的空间位置关系;
根据所述位置信息和所述空间位置关系进行路径搜索,以确定所述第一线段集合中待拼接的目标线段;
对所述目标线段进行拼接,得到拼接线段集合。
可选地,所述拼接线段集合包括横线集合和竖线集合,所述对所述拼接线段集合进行单元格提取处理,得到第一表格的步骤,包括:
根据所述直角坐标系,对所述拼接线段集合中的横线集合和竖线集合进行合并,得到第一单元格;
对所述第一单元格进行腐蚀和膨胀处理,以对所述第一单元格进行断裂修复,得到第二单元格;
获取所述第二单元格中各单元格之间的拓扑关系,根据所述拓扑关系构建所述第二单元格的结构模型;
根据所述结构模型确定需要保留的目标单元格,并根据所述直角坐标系对所述目标单元格进行堆栈存储,得到第一表格。
可选地,所述对所述第一表格进行检测,以确定所述第一表格中是否存在漏检直线的步骤,包括:
获取对所述第一表格进行二值化处理的阈值范围和梯度值,并基于所述阈值范围和所述梯度值,对所述第一表格进行阈值梯度变换的二值化处理,得到第三目标图像;
对所述第三目标图像进行开运算,以确定所述第一表格中是否存在漏检直线。
可选地,所述对所述第一表格的单元格进行二次分割处理,得到第二表格的步骤,包括:
对所述第一表格的轮廓进行矩形检测,以获取所述第一表格对应的矩形集合;
从所述矩形集合中确定存在交集的第一矩形集合,并从所述第一矩形集合中剔除存在包含关系的第二矩形集合,得到存在交集的第三矩形集合;
从所述第三矩形集合中,获取存在交集的目标矩形的交集面积,并判断所述交集面积是否超过预设阈值;
若所述交集面积超过预设阈值,则从所述第一表格中对所述目标矩形进行去交集处理,得到第二表格。
可选地,所述对所述第二表格和所述文字信息进行标准化输出,得到目标表格之后的步骤,包括:
获取对所述目标表格进行编辑的操作指令;
根据所述操作指令,对所述目标表格的单元格中的文字信息进行编辑,并对所述目标表格的样式进行设置。
此外,为实现上述目的,本发明还提供一种表格识别设备,所述表格识别设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的表格识别程序,所述表格识别程序被所述处理器执行时实现如上述的表格识别方法的步骤。
此外,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有表格识别程序,所述表格识别程序被处理器执行时实现如上述的表格识别方法的步骤。
本发明实施例提出的一种表格识别方法、设备及计算机可读存储介质。与现有技术中,对表格识别的准确率低相比,本发明实施例中,检测到识别指令时,获取待识别的表格图像,并对所述表格图像进行框线提取处理,得到线段二值图像,对所述线段二值图像中的线段进行拼接处理,得到拼接线段集合;对所述拼接线段集合进行单元格提取处理,得到第一表格,并对所述第一表格进行检测,以确定所述第一表格中是否存在漏检直线;若所述第一表格中存在漏检直线,则对所述第一表格的单元格进行二次分割处理,得到第二表格;对所述第二表格的单元格进行切片处理,并从切片处理后的单元格中提取文字信息,对所述第二表格和所述文字信息进行标准化输出,得到目标表格。通过提取表格框线对表格图像中的单元格进行定位和提取,能够对不同版式的表格进行识别,且通过对提取的单元格进行直线漏检检测和二次分割处理,提高了表格识别的准确率。
附图说明
图1为本发明实施例提供的表格识别设备一种实施方式的硬件结构示意图;
图2为本发明表格识别方法第一实施例的流程示意图;
图3为本发明表格识别方法第一实施例的腐蚀和膨胀处理的效果示意图;
图4为本发明表格识别方法第一实施例的线段二值图像示意图;
图5为本发明表格识别方法第一实施例的横线段的空间位置关系示意图;
图6为本发明表格识别方法第一实施例的拼接线段集合示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
在后续的描述中,使用用于表示元件的诸如“模块”、“部件”或“单元”的后缀仅为了有利于本发明的说明,其本身没有特定的意义。因此,“模块”、“部件”或“单元”可以混合地使用。
本发明实施例表格识别设备(又叫终端、设备或者终端设备)可以是PC,也可以是智能手机、平板电脑和便携计算机等具有数据处理和显示功能的可移动式终端设备。
如图1所示,该终端可以包括:处理器1001,例如CPU,网络接口1004,用户接口1003,存储器1005,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(Display)、输入单元比如键盘(Keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如WI-FI接口)。存储器1005可以是高速RAM存储器,也可以是稳定的存储器(non-volatile memory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
可选地,终端还可以包括摄像头、RF(Radio Frequency,射频)电路,传感器、音频电路、WiFi模块等等。其中,传感器比如光传感器、运动传感器以及其他传感器。具体地,光传感器可包括环境光传感器及接近传感器,其中,环境光传感器可根据环境光线的明暗来调节显示屏的亮度,接近传感器可在移动终端移动到耳边时,关闭显示屏和/或背光。作为运动传感器的一种,重力加速度传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,可用于识别移动终端姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;当然,移动终端还可配置陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
本领域技术人员可以理解,图1中示出的终端结构并不构成对终端的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种计算机可读存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及表格识别程序。
在图1所示的终端中,网络接口1004主要用于连接后台服务器,与后台服务器进行数据通信;用户接口1003主要用于连接客户端(用户端),与客户端进行数据通信;而处理器1001可以用于调用存储器1005中存储的表格识别程序,所述表格识别程序被处理器执行时实现下述实施例提供的表格识别方法中的操作。
基于上述设备硬件结构,提出了本发明表格识别方法的实施例。
参照图2,在本发明表格识别方法的第一实施例中,所述表格识别方法包括:
步骤S10,检测到识别指令时,获取待识别的表格图像,并对所述表格图像进行框线提取处理,得到线段二值图像,对所述线段二值图像中的线段进行拼接处理,得到拼接线段集合;
本发明所述的表格识别方法可以应用于个人电脑等具有数据处理功能和显示功能的终端设备,且在本发明所述的表格识别方法中,设置有表格识别系统(以下简称系统),系统的应用场景包括但不限于银行等存在大量纸质表格单据的金融机构,以下以银行为系统的应用场景为例进行说明。当检测到识别指令时,获取待识别的表格图像,该识别指令可以是用户触发的,例如,在系统中设置有识别按钮,当用户按下识别按钮时,触发相应的识别指令。根据识别指令获取对应的待识别的表格图像,待识别的表格图像可以是通过对纸质的表格单据进行扫描或拍摄得到的。对获取的表格图像进行框线提取处理,得到线段二值图像,并对所述线段二值图像中的线段进行拼接处理,得到拼接线段集合。
进一步地,在对表格图像中的表格进行框线提取处理时,基于数学形态学原理,对表格框线中的横线和竖线进行提取处理,在进行框线提取处理时,首先对获取的表格图像进行二值化处理,从经过处理得到的二值化图像中,把组成表格的横线和竖线分别提取出来,得到对应的线段二值图像。然后对提取的横线和竖线分别进行拼接,从而得到拼接的线段集合。
具体地,在步骤S10中,对所述表格图像进行框线提取处理,得到线段二值图像的细化,包括步骤A1-A4:
步骤A1,对所述表格图像进行灰度处理,得到目标灰度图像;
步骤A2,对所述目标灰度图像进行腐蚀和膨胀处理,得到第一目标图像;
步骤A3,对所述第一目标图像进行高斯和二值化处理,得到第二目标图像;
步骤A4,获取结构元素,并根据所述结构元素对所述第二目标图像进行开运算,得到线段二值图像。
在对表格图像进行框线提取处理时,首先对表格图像进行灰度处理,得到对应的目标灰度图像,然后对得到的灰度图像进行腐蚀和膨胀处理,得到对应的第一目标图像,如图3所示,图3为对图像进行腐蚀和膨胀处理的效果示意图,由图3可知,经过腐蚀处理的图像背景中较亮的区域减少,黑的区域增加,而经过膨胀处理的图像效果相反,图像背景中较亮的区域增加,黑的区域减少,经过腐蚀和膨胀处理的灰度图像中,表格框线的变化较为明显。对灰度图像进行腐蚀操作的目的为:对灰度图像的一些高亮度的关键细节进行剔除;对灰度图像进行膨胀操作的目的为:对灰度图像的一些低亮度的关键细节进行剔除。再对经过膨胀和腐蚀处理的灰度图像进行高斯处理,减少图像噪声,对经过高斯处理的图像进行二值化处理,得到对应的二值化图像,一种优选的进行二值化处理算法为OpenCV二值化算法,可以自适应设置二值化阈值,根据图像中各个不同亮度的区域自行调整二值化的阈值,使得图像的每个不同亮度的区域都能清晰地被识别出来;若使用单一的二值化阈值对图像进行二值化,可能会造成图像中某些亮度过小或过大的区域,无法清晰地被识别出来。二值化算法的调用可以是在系统中预先设置OpenCV模型库,从模型库中直接调用相应的算法模型,对图像进行二值化处理,得到的对应的第二目标图像。然后获取定义的结构元素,在本实施例中,提取的表格的单元格为矩形,因此,获取的结构元素可以是矩形元素。在本实施例中,对于表格框线中的横线,结构元素是长为30(像素)宽为1(像素)的矩形元素,对于表格框线中的竖线,结构元素是长为1(像素)宽为30(像素)的矩形元素,利用定义的结构元素对得到的第二目标图像进行开运算,从第二目标图像中提取表格框线,提取的框线为不连续的横线段和竖线段,得到对应的线段二值图像,经过框线提取处理得到的线段二值图像中,包括只包含横线段的横线二值图像和只包含竖线段的竖线二值图像。其中,开运算是一个基于几何运算的滤波器,能够除去图像中孤立的小点、毛刺和小桥,而使图像中的线段总体的位置和形状不变。不同大小和/或形状的结构元素会对图像进行不同的分割,即提取出不同的特征,从而达到不同的滤波效果,因此上述矩形元素仅为本发明实施例的一种优选结构元素,并不对本发明构成限定。可以参照图4,图4为本实施例中,对灰度图像进行框线提取处理后得到的线段二值图像,在图4中,左图为横线二值图像,右图为竖线二值图像。
进一步地,在步骤S10中,得到线段二值化图像后,对线段二值化图像中的线段进行拼接处理,得到拼接线段集合包括步骤A5-A8:
步骤A5,对所述线段二值图像进行霍夫变换处理,得到第一线段集合;
步骤A6,建立直角坐标系并根据建立的直角坐标系,对所述第一线段集合中的线段进行排序,获取排序后的线段的位置信息和线段之间的空间位置关系;
步骤A7,根据所述位置信息和所述空间位置关系进行路径搜索,以确定所述第一线段集合中待拼接的目标线段;
步骤A8,对所述目标线段进行拼接,得到拼接线段集合。
对线段二值图像中的横线二值图和竖线二值图分别进行拼接处理。首先,对横线二值图像和竖线二值图像进行霍夫变换处理,得到包括若干断裂和出现偏移的线段集合,即第一线段集合,并识别线段集合中每个线段的端点。然后建立直角坐标系,在建立直角坐标时,需要以一个确定的参考点为原点建立,该原点可以是表格外框左上角的顶点,也可以是整个图像的左上角的顶点,在此不作具体限定,以下以图像的左上角顶点为原点建立直角坐标系为例进行说明,在确定直角坐标系的原点后,以与表格框线中的横线平行的方向为横轴,与横线垂直的方向为纵轴建立直角坐标系,一种优选的坐标系的构建方式可以是借助系统中预设的OpenCV模型库中的HoughLinesP(霍夫找线)函数直接建立。
根据建立的直角坐标系,对第一线段集合中的线段进行排序,在排序时,对于横线段,按照从左至右的方式确定横线段的起点以及起点坐标,根据横线段起点的横坐标的大小,对横线段进行排序,同样地,对于竖线段,按照从上至下的方式确定竖线段的起点和起点坐标,根据竖线段起点坐标的纵坐标的大小进行排序,并获取排序后的线段的位置信息和线段之间的空间位置关系。其中,线段的位置信息可以通过两个端点的坐标表示,而线段之间的空间位置关系通过线段端点的坐标可以获取,具体可以参照图5,图5本实施例中,对横线段之间的空间位置关系进行总结,抽象出来的横线段在位置上的几种情形,在图5中,横线段之间的空间位置关系主要有交叠、包含、间隙、分离、倾斜以及其中一条为短线段等。
根据线段的位置信息以及线段之间的空间位置关系,采用路径搜索法,确定大概率属于同一行或同一列的线段进行拼接,在拼接时,横线段与竖线段采用的方式基本相同,因此,仅以横线段为例进行说明。在对横线段进行路径搜索时,设置一个坐标极限值,假设坐标极限值为12(像素),则相邻的两个横线段之间的纵坐标相差小于12(像素)时,则认为这两个线段在表格中是属于同一条横线上的线段,采用该方式对线段集合中相邻的横线段逐一进行对比,将在同一横线上的目标线段进行拼接。具体在确定需要拼接的目标线段时,以图4所示的横线段之前的空间位置关系为例,针对图5所示的情形1、情形2和情形3,线段存在交叠、包含关系或间隙较小的情况下,则认为该线段为需要拼接的目标线段,对该线段进行拼接;针对情形4所示的线段位置较远的情况,认为两个线段是相互独立的短线,不作拼接,针对情形5和情形6所示的线段存在倾斜或其中一条线段为短线的情况,则认为倾斜线段和短线会对线段的拼接产生影响,因此,需要从线段集合中进行剔除,对需要拼接的目标短线进行拼接后,得到拼接线段集合,如图6所示的拼接线段集合示意图,该集合是对图4所示的线段二值图像进行拼接处理得到的,图6中的左图为横线段的拼接线段集合,右图为竖线段的拼接线段集合。
步骤S20,对所述拼接线段集合进行单元格提取处理,得到第一表格,并对所述第一表格进行检测,以确定所述第一表格中是否存在漏检直线;
对经过拼接处理得到的拼接线段集合中的线段进行单元格提取处理,得到对应的表格,可知地,当根据线段的坐标位置信息,将图6所示的拼接线段集合中的横线拼接线段和竖线拼接线段合并到一起后,即可形成表格的单元格,进而得到一个大致的表格轮廓,对得到的表格轮廓进行检测,确定单元格或直线是否存在直线漏检,进而造成单元格的断裂不连续。
具体地,单元格提取处理的步骤,包括步骤B1-B4:
步骤B1,根据所述直角坐标系,对所述拼接线段集合中的横线集合和竖线集合进行合并,得到第一单元格;
步骤B2,对所述第一单元格进行腐蚀和膨胀处理,以对所述第一单元格进行断裂修复,得到第二单元格;
步骤B3,获取所述第二单元格中各单元格之间的拓扑关系,根据所述拓扑关系构建所述第二单元格的结构模型;
步骤B4,根据所述结构模型确定需要保留的目标单元格,并根据所述直角坐标系对所述目标单元格进行堆栈存储,得到第一表格。
在进行单元格提取时,首先根据建立的直角坐标系,将拼接好的横线段和竖线段绘制到同一张图像上,对合并后得到的表格单元格进行腐蚀和膨胀处理,从而对合并后的线段进行断裂修复,获取经过断裂修复后的单元格之间的逻辑拓扑关系,并基于获取的拓扑关系生成单元格之间的结构模型。该结构模型可以是逻辑树结构模型,具体地,通过研究单元格之间的逻辑拓扑关系,将其抽象成为节点的“父子”逻辑树结构模型,然后,检测图像中单元格的轮廓数组,每一个单元格轮廓用一个定义点的point类型的vector(矢量)表示,其中,point类型的数据是可储存坐标点的结构体变量。每个单元格轮廓标记为contours[i]分别对应该单元格的后一个单元格轮廓,前一个单元格轮廓,父单元格轮廓,和内嵌单元格轮廓的索引编号hierachy[i][0]、hierachy[i][1]、hierachy[i][2]、hierachy[i][3],通过单元格轮廓对应的四个元素,实现对单元格的前后定位以及“父子”逻辑关系的确定,若该单元格对应的某个元素不存在则其索引编号为负数,以此构建出单元格之间的“父子”逻辑树结构模型。
进一步地,可以调用系统中预设的OpenCV库中的findContours函数,获取单元格的轮廓集合,遍历轮廓集合,若某个单元格轮廓无前后同级节点和父子节点,则认为是由于噪声产生的孤立节点,对该单元格进行剔除;若到单元格轮廓含有包含的子集或者该轮廓为某个单元格的父集,则认为该单元格轮廓为非单元格最小拆解单元,对该单元格进行剔除;对于单元格轮廓面积较小的,若小于预设阈值则直接进行剔除,此处可以量阈值设置为100;若不存在上述需要剔除单元格的情况,则记录该单元格轮廓的前后定位,并获取该单元格轮廓的外接矩形,保留其坐标信息;以此确定需要保留的所有的单元格,以完成对单元格的提取处理,将需要保留的单元格进行堆栈存储,在进行堆栈存储时,根据各个单元格的坐标信息,确定该单元格在表格中所在的行和列,根据表格中单元格的行和列信息进行堆栈存储,得到对应的表格。而各个单元格的坐标信息,由组成该单元格的横线段和竖线段的坐标信息确定。
进一步地,在进行单元格提取处理得到对应的表格后,考虑到二值化处理可能对直线检测产生影响,为了避免直线漏检情况的发生,需要对表格进行直线探测,该探测可以是基于轮廓的矩形检测方法,通过梯度阈值二值化处理,进行直接框线的查漏补缺。
对表格进行检测的步骤包括C1-C2:
步骤C1,获取对所述第一表格进行二值化处理的阈值范围和梯度值,并基于所述阈值范围和所述梯度值,对所述第一表格进行阈值梯度变换的二值化处理,得到第三目标图像;
步骤C2,对所述第三目标图像进行开运算,以确定所述第一表格中是否存在漏检直线。
首先,获取二值化处理的阈值范围和梯度值,以梯度值为6(像素),阈值范围[30,150]为例,从阈值为30(像素)开始对图像进行二值化处理,得到对应的二值化图像,对二值化图像进行检测后,再增加一个梯度,以阈值为36(像素)对图像二值化和检测处理,以此类推,直到完成对二值化处理的阈值为150(像素)的二值化图像的检测,对得到的二值化图像进行检测,主要是通过对二值化图像进行开运算,以此确定得到的表格是否存在漏检直线。
步骤S30,若所述第一表格中存在漏检直线,则对所述第一表格的单元格进行二次分割处理,得到第二表格;
进一步地,若表格中存在漏检直线,则对表格进行二次分割处理,得到新的表格。
二次分割处理的具体过程包括步骤D1-D4:
步骤D1,对所述第一表格的轮廓进行矩形检测,以获取所述第一表格对应的矩形集合;
步骤D2,从所述矩形集合中确定存在交集的第一矩形集合,并从所述第一矩形集合中剔除存在包含关系的第二矩形集合,得到存在交集的第三矩形集合;
步骤D3,从所述第三矩形集合中,获取存在交集的目标矩形的交集面积,并判断所述交集面积是否超过预设阈值;
步骤D4,若所述交集面积超过预设阈值,则从所述第一表格中对所述目标矩形进行去交集处理,得到第二表格。
在进行二次分割处理时,首先对表格轮廓进行矩形探测,获取表格中的单元格的矩形轮廓集合,例如,与单元格提取处理相同,同样调用OpenCV模型库中的findContours函数,对表格进行矩形探测,获取表格中单元格的矩形集合,对获取的矩形集合求取交集,以确定表格中,存在交集的单元格,并从存在交集的矩形中去除存在包含关系的矩形,对剩余的存有交集的目标矩形,根据矩形间的相交区域的大小,确定是否对其进行保留。具体地,可以将矩形的相交宽度阈值设置为30(像素),相交高度阈值设置为20(像素),若是两个矩形相交的宽度和高度大于对应的阈值,则对存在交集的矩形进行去交集处理,阈值的设置可以根据单元格的大小进行自定义设置。去交集处理是指,将存在交集的两个矩形中的一个剔除,只保留其中一个。也即,当两个矩形交集面积过大,超过一定的阈值,则认为该两个矩形实际上对应的是同一个单元格,因此,只保留其中一个,若相交区域的大小没有超过设置的阈值,则可以以两个矩形相交区域的中线作为两个矩形的交线,对相交区域的线段进行擦除,从而对两个矩形的交集产生的矩形进行剔除。或者,若矩形相交区域的大小没有超过设置的阈值,将矩形相交的线段进行平移,直到两个矩形之间不存在交集,成为相互独立的两个矩形单元格为止。同时,保留经过去交集处理后得到的矩形的位置信息。
步骤S40,对所述第二表格的单元格进行切片处理,并从切片处理后的单元格中提取文字信息,对所述第二表格和所述文字信息进行标准化输出,得到目标表格。
当对存在漏检直线的表格进行二次分割处理,得到对应的表格后,对表格的单元格进行切片处理,并从切片处理后的单元格中,提取文字信息,对提取的文字信息和表格进行标准化输出,得到目标表格。可知地,当经过单元格提取处理后得到的表格中,不存在漏检直线时,则不需要对表格进行二次分割处理,直接对表格进行切片处理,从而得到对应的目标表格即可。
需要说明的是,由于表格样式的多样性,不排除存在表格中有的单元格中存在斜线对单元格进行划分的情况,该情况下,在进行框线提取处理时,将单元格作为一个整体,提取的是单元格的轮廓框线,将单元格中的文字信息等内容作为一个整体,不对单元格中的内容进行处理。即使单元格中的斜线可能被误提取,根据线段之间的空间位置关系,在进行线段拼接时,斜线也会被剔除掉。而在文字识别阶段,将单元格中存在的斜线等线段作为特殊的文字符号进行提取,从而保留表格图像中原始表格的版式和样式信息。在对文字进行识别时,为防止表格框线对文字识别造成干扰,需要先对表格进行切片处理,将表格的每一个单元格都切片处理成独立的文本,然后输入到系统中预设的文字识别模型中进行OCR识别(Optical Character Recognition,光学字符识别)和提取,并将提取出的文字信息与经过切片处理的单元格进行关联,从而确定从该单元格中提取的文字在即将输出的表格中对应的位置,最后对提取的文字信息和表格进行标准化输出。其中,对表格单元格进行切片处理时,同样可以采用上述线段拼接处理步骤中的霍夫变换和路径搜索相结合的方法,通过表格框线对表格中的每个单元格进行序列化定位与切片处理,并将经过切片处理的单元格发送到对应的文字识别模型中进行OCR识别处理,能有效提高对表格单元格定位和切片处理的准确性,进而提高表格识别的准确率。
在对提取的文字信息和表格进行标准化输出时,输出信息主要包括表格顺序信息、表格行信息和列信息、矩形块(单元格)位置信息、提取的各个单元格中的文字信息。其中,单元格的位置信息包括单元格的高度和宽度以及坐标信息,单元格的坐标信息可以是单元格的某个顶点在上述建立的直角坐标系中的坐标,例如,以单元格左上角的顶点坐标对单元格进行定位,当确定了单元格左上角的坐标后,结合单元格的高度和宽度等信息,就可以确定单元格的大小和位置。
如果被识别的表格图像中包含印章等信息,在标准化输出的表格中,还可以插入获取的原始的表格图像,便于数据使用人员对识别出的数据进行校对,考虑到一般表单产生的原因在于表格中的数据需要经过签章审批,因此,下游业务在使用数据时,需要确定系统识别出来的表单里的数据是经过审批的合法数据,从而不会对下游使用表格数据的业务造成影响。目前来说,由于信息系统的可靠性可能未达到百分百,事实上,几乎没有信息系统的可靠性能够达到百分之百,因此,在对表格图像进行识别和标准化输出时,在输出的表格中插入原始的表格图像,也有利于使用表格数据的业务人员进一步确认识别出的表格数据是否正确,在数据调用阶段对表格识别存在的误差进行人工校正,从而弥补系统的不足,提高表格识别数据的准确性。
进一步地,在对表格进行标准化输出后,输出的是可以编辑的表格,当系统检测到表格被调用时,获取调用表格的用户触发的操作指令,根据用户的操作指令,对表格进行编辑,具体包括步骤E1-E2:
步骤E1,获取对所述目标表格进行编辑的操作指令;
步骤E2,根据所述操作指令,对所述目标表格的单元格中的文字信息进行编辑,并对所述目标表格的样式进行设置。
系统在对表格图像进行识别并输出可编辑的表格后,获取对表格进行编辑的操作指令,根据获取的操作指令,对表格进行编辑,编辑内容包括表格单元格中的文字信息,例如,对单元格中的文字信息进行更改、删除、添加等,可知地,如果单元格中的文字信息是数字,还可以插入公式对单元格中的数字进行计算。进一步地,还可以根据用户的操作指令对表格样式进行设置,例如,对表格中的单元格进行填充、更改文字信息的字体样式等,进而可以满足不同用户的个性化设置。
在本实施例中,检测到识别指令时,获取待识别的表格图像,并对所述表格图像进行框线提取处理,得到线段二值图像,对所述线段二值图像中的线段进行拼接处理,得到拼接线段集合;对所述拼接线段集合进行单元格提取处理,得到第一表格,并对所述第一表格进行检测,以确定所述第一表格中是否存在漏检直线;若所述第一表格中存在漏检直线,则对所述第一表格的单元格进行二次分割处理,得到第二表格;对所述第二表格的单元格进行切片处理,并从切片处理后的单元格中提取文字信息,对所述第二表格和所述文字信息进行标准化输出,得到目标表格。通过提取表格框线对表格图像中的单元格进行定位和提取,能够对不同版式的表格进行识别,且通过对提取的单元格进行直线漏检检测和二次分割处理,提高了表格识别的准确率。
进一步地,在本发明上述实施例的基础上,提出了本发明表格识别方法的第二实施例。
本实施例是第一实施例中步骤S10中,对表格图像进行框线提取处理之前的步骤,包括步骤F1-F2:
步骤F1,对所述表格图像进行检测,以确定是否对所述表格图像进行预处理;
步骤F2,若需要对所述表格图像进行预处理,则对所述表格图像进行矫正和/或去干扰处理;
以上述实施例所述的系统为例,系统获取的待识别的表格图像可以是通过扫描或拍摄得到的,一般地,在对纸质单据进行扫描或拍摄时,可能会存在倾斜现象,且纸质单据中可能还存在影响表格识别的干扰信息,从而影响后续处理的准确性,因此,需要对表格图像进行矫正并对其中的干扰信息进行去除。进一步地,如果获取的表格图像是压缩文件,且文件的格式不符合系统识别的要求,还需要对解压后的表格图像进行格式转换。具体地,对获取的表格图像进行检测包括对表格图像的解压、格式转换和归一化等处理,在对获取的表格图像进行检测时,如果获取的表格图像需要进行解压、格式转换、归一化处理中的至少一种,则先进行相应的处理,对处理后的表格图像进行检测,进而进一步地确定在对表格图像进行识别处理之前,是否需要对其进行预处理,预处理的过程主要包括矫正处理和去干扰处理。其中,解压、格式转换、归一化等处理是将系统获取的表格图像作为整体进行处理的,而矫正、去干扰等处理是将表格图像中的每个图像作为独立个体进行处理的,对表格图像进行检测主要包括角度检测和干扰检测,以确定表格图像中的表格是否存在角度倾斜和/或印章等干扰信息,若存在,则对表格图像进行预处理。
其中,当检测到表格图像中的表格存在倾斜时,需要对表格图像进行矫正处理,矫正处理主要包括步骤F21-F22:
步骤F21,对所述表格图像进行二值化处理,得到二值化图像,并对所述二值化图像进行变换处理,以对所述二值化图像的线段进行检测并计算所述表格图像中的表格的倾斜角;
步骤F22,根据所述倾斜角对所述表格图像进行矫正处理;
当检测到表格图像中的表格存在倾斜,需要对表格图像进行矫正处理时,首先,对表格图像进行二值化处理,得到对应的二值化图像,便于对表格的框线进行检测,进而确定表格的倾斜程度。本实施例中,与上述实施例中的根据二值化阈值梯度进行二值化处理不同,这里对表格图像进行二值化处理主要是为了便于对表格框线进行检测,因此可以采用最大类间方差法,按照图像灰度特性,分量表格图像的前景和背景,求取表格图像中的类间方差最大的点作为二值化阈值的分割点,对表格图像进行二值化处理,得到对应的二值化图像。
在对得到的二值化图像进行框线检测之前,需要对图像进行变换处理,该变换处理也可以是上述实施例中所述的霍夫变换,利用霍夫变换,可以检测到表格框线中的线段和线段的端点,通过线段端点计算线段的倾斜角,从而计算出表格的倾斜角。在对二值化图像中的线段进行检测时,可以只检测横线或竖线中的一种,以检测横线为例,对二值化图像中的横线段进行检测,获取所有横线的倾斜角,然后计算所有横线倾斜角的均值,或者,在所有横线的倾斜角中取众数或中位数等,进而确定表格在图像中的倾斜角。
进一步地,在计算出表格的倾斜角后,对表格图像中的表格进行矫正处理,该矫正可以是对表格进行旋转矫正,需要说明的是,对表格图像进行旋转矫正时,是根据表格框线在图像中的倾斜角对表格进行旋转,从而对表格图像中的表格进行矫正,得到对应的矫正图像,并非是对表格图像本身进行旋转。
当检测到表格图像中存在干扰信息时,则需要对表格图像进行去干扰处理,去干扰处理主要包括步骤F23-F24:
步骤F23,对所述表格图像进行二值化处理,以对所述表格图像进行特征统计,得到干扰信息的特征信息;
步骤F24,根据所述特征信息,对所述表格图像中除所述干扰信息之外的有效信息进行滤波处理,并对被所述干扰信息遮挡的区域进行增强处理,以从所述表格图像中去除所述干扰信息。
该干扰信息是指会对表格的识别以及表格中文字信息的提取产生干扰,或者会对后续处理的准确性产生影响的信息,如印章、水印等信息。当检测到经过矫正处理的图像中存在干扰信息时,则对表格图像进行二值化和滤波增强处理,从矫正图像中,对干扰信息进行去除,从而得到可以进一步进行识别处理的表格图像。在进行去干扰处理时,首先对表格图像进行二值化处理,得到对应的二值化图像,对二值化图像进行特征统计,从而提取干扰信息的特征信息,该特征信息可以是轮廓信息,也可以是二值化处理后的灰度值信息,在此不作具体限定。根据提取的特征信息,对干扰信息之外的有效信息进行滤波,并对被所述干扰信息遮挡的区域进行增强处理,以从所述表格图像中去除所述干扰信息。
由于干扰信息可能存在多种情形,例如,印章颜色通常可以是红色或者蓝色的,而经过复制的文件中的印章颜色可能是灰色的,因此,获取的待识别的表格图像中,可能存在红色印章、蓝色印章、灰色印章以及与灰色印章相似的水印等干扰信息,甚至还有可能存在更多其他类型的干扰信息。以上述实施例中的系统为例,具体应用时,根据业务表格中实际存在的干扰信息的类型,可以在系统中设置不同的模型或处理方式,对不同类型的干扰信息分别进行不同的处理。
首先,以去除红色和蓝色印章为例,从表格图像中分别提取红色分量和蓝色分量,并分别进行二值化处理,得到对应的二值化图像,对二值化图像进行颜色特征统计,以判断印章颜色,对图像中除印章之外的有效信息进行滤波,得到仅仅包含印章以及被印章遮挡区域的图像,对印章和字符进行有效分离和提取处理。在将印章和字符进行分离时,先对被印章遮挡的字符进行图像增强,使用该区域内的图像的平均背景灰度来消除印章干扰,最终合成的灰度图像可以有效地将印章滤除。上述印章红色和蓝色印章的去除方式对彩色的表格图像同样适用。
对于和表格中的文字信息灰度值相近的灰色印章和水印等干扰信息,可以在对表格图像进行二值化处理后,进行形状检测,当识别到特定形状的图案时,计算该原始表格图像中特定形状的图案区域的灰度值,对于印章覆盖字符的区域和未覆盖字符的区域,灰度值或多或少会存在差别,则可以取该特定形状区域内的灰度值众数,并在该特定形状的区域内对该众数对应的灰度值进行过滤后,再对该区域进行增强处理,从而可以有效去除印章或水印等干扰信息并保留文字信息。进一步地,对印章和水印信息的识别,还可以是通过设置灰度值阈值,当检测到灰度值相同的连续区域的面积超过一定的阈值,则可以将该连续区域判定为干扰信息,在这种情况下,当通过灰度值阈值检测干扰信息时,为了与表格框线进行区分以避免对干扰信息的误判,可以将面积阈值设置为宽度阈值和长度阈值,当区域宽度和长度同时超过对应阈值时,则认为该连续区域的面积超过了设置的阈值,从而将该区域判定为是干扰信息区域。对干扰区域进行滤波处理后,对被干扰信息遮挡区域的有效信息进行增强处理,从而去除干扰信息,得到无干扰信息的表格图像。
可知地,上述对表格图像进行预处理的步骤仅为本实施例中的一种优选的处理方式,在实际应用时,对表格图像进行预处理时,可以同时包括矫正处理和去干扰处理,也可以只包括其中的一种。当对表格图像进行预处理同时包括矫正处理和去干扰处理时,两者的处理过程并没有严格的顺序限制,可以先进行矫正处理,也可以先进行去干扰处理。具体地,可以通过对系统架构进行调整,或对系统中的模型和算法的设置进行调整,进而改变上述预处理的步骤,因此,上述实施例中的预处理步骤仅用于对本发明表格识别方法的实施例进行说明,并不对本发明构成限定。
在本实施例中,通过对获取的待识别的表格图像进行预处理,对表格图像中存在倾斜的表格进行旋转矫正,并对表格图像中的干扰信息进行去除,减少了表格倾斜和干扰信息对表格识别处理的影响,能够有效提高表格识别的准确率。
此外,本发明实施例还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有表格识别程序,所述表格识别程序被处理器执行时实现上述实施例提供的表格识别方法中的操作。
上述各程序模块所执行的方法可参照本发明方法各个实施例,此处不再赘述。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体/操作/对象与另一个实体/操作/对象区分开来,而不一定要求或者暗示这些实体/操作/对象之间存在任何这种实际的关系或者顺序;术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的表格识别方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 表格识别方法、设备及计算机可读存储介质
- 表格信息跨页识别方法、电子设备及计算机可读存储介质