一种突发事件信息相关度的无监督学习分析方法及系统
文献发布时间:2023-06-19 09:24:30
技术领域
本发明涉及自然语言处理技术领域,特别是涉及一种突发事件信息相关度的无监督学习分析方法及系统。
背景技术
对于文章与主题的相关度,目前一般采用分类算法,将文章分到相关的主题中。
目前的分类算法中,各个分类一般是互斥的,即只能计算出该文章属于哪个分类的概率最高。但是,有时一篇文章中,可能包含了多个主题,比如一篇突发事件如暴雨的文章,可能还包含了暴雨、内涝、滑坡、泥石流等相关的主题。因此,使用分类算法,并不能很好的计算出文章,与多个主题的相关度,而且,目前的分类算法一般是有监督的,需要人工对每篇文章做标注,然后进行模型训练,因此,需要的工作量和时间都比较高。
发明内容
为克服上述现有技术存在的不足,本发明之目的在于提供一种突发事件信息相关度的无监督学习分析方法及系统,以便能够方便、快捷的分析出文章与主题的相关度,为文章打上相关的主题标签,并且多个主题之间是彼此独立的,不存在互斥关系。
为达上述及其它目的,本发明提出一种突发事件信息相关度的无监督学习分析方法,包括如下步骤:
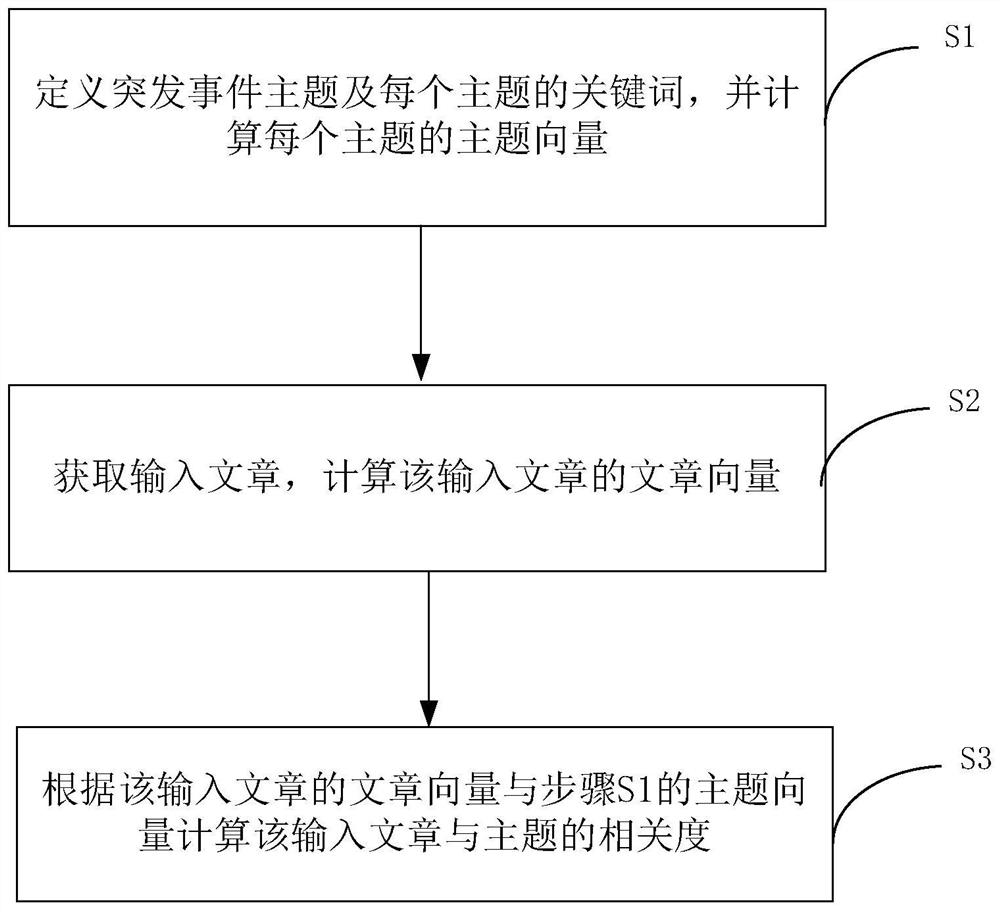
步骤S1,定义突发事件主题及每个主题的关键词,并计算每个主题的主题向量;
步骤S2,获取输入文章,计算该输入文章的文章向量;
步骤S3,根据该输入文章的文章向量与步骤S1的主题向量计算该输入文章与主题的相关度。
优选地,步骤S1进一步包括:
步骤S100,定义突发事件若干主题,并为每个主题定义相应的关键词;
步骤S101,根据定义的关键词利用词向量模型计算每个主题的主题向量。
优选地,于步骤S101中,每个主题的主题向量等于其每个关键词的词向量的加和。
优选地,步骤S2进一步包括:
步骤S200,获取输入文章的正文,对文章正文进行中文分词;
步骤S201,计算分词后每个词的TF-IDF权重;
步骤S202,根据步骤S201获得的每个词的TF-IDF权重计算出该输入文章的文章向量。
优选地,于步骤S202中,每个词的TF-IDF权重采用下式获得:
Wt=该词在文章中出现的次数*该词的IDF权重
优选地,于步骤S203中,该输入文章的文章向量等于其每个词的词向量与其TF-IDF权重的乘积的加和。
优选地,该输入文章的文章向量采用下式获得:
其中,Vd为文章向量,Vk为每个词的词向量,Wk为每个词的TF-IDF权重。
优选地,于步骤S3中,该输入文章与主题的相关度为其主题向量与该输入文章的文章向量的余弦距离。
优选地,所述输入文章与主题的相关度通过如下公式计算获得:
其中,A、B分别表示主题向量与该输入文章的文章向量。
为达到上述目的,本发明还提供一种突发事件信息相关度的无监督学习分析装置,包括:
主题定义单元,用于定义突发事件主题及每个主题的关键词,并计算每个主题的主题向量;
文章向量分析单元,用于获取输入文章,计算该输入文章的文章向量;
相关度分析单元,用于根据该输入文章的文章向量与所述主题定义单元获得的主题向量计算该输入文章与主题的相关度。
与现有技术相比,本发明一种突发事件信息相关度的无监督学习分析方法及系统通过定义突发事件主题及每个主题的关键词,计算得到每个主题的主题向量,然后获取输入文章,计算该输入文章的文章向量,并根据该输入文章的文章向量与步骤S1的主题向量计算该输入文章与主题的相关度,以实现方便、快捷的分析出文章与主题的相关度,为文章打上相关的主题标签,并且本发明中多个主题之间是彼此独立的,不存在互斥关系。
附图说明
图1为本发明一种突发事件信息相关度的无监督学习分析方法的步骤流程图;
图2为本发明一种突发事件信息相关度的无监督学习分析装置的系统架构图;
图3为本发明实施例的分析结果示意图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图1为本发明一种突发事件信息相关度的无监督学习分析方法的步骤流程图。本发明一种突发事件信息相关度的无监督学习分析方法,包括如下步骤:
步骤S1,定义突发事件的主题以及每个主题的关键词,并计算每个主题的主题向量。
具体地,步骤S1进一步包括:
步骤S100,定义若干主题,并为每个主题定义相应的关键词。
也就是说,在本发明中,可预先定义突发事件的主题,并定义每个主题的关键词,例如,定义突发事件“暴雨”主题,其可以包含“暴雨”、“强降水”、“强降雨”等关键词。
步骤S101,利用词向量模型计算每个主题的主题向量。
在本发明中,主题向量等于每个关键词的词向量的加和。也就是说,对于每个主题,可利用词向量模型计算获得其每个关键词的词向量,该主题的主题向量则为其每个关键词的词向量的加和。在本发明具体实施例中,词向量模型可以使用开源的词向量模型,也可以自行训练词向量模型,本发明不以此为限。
步骤S2,获取输入文章,计算该输入文章的文章向量。
具体地,步骤S2进一步包括:
步骤S200,获取输入文章的正文,对文章正文进行中文分词。本发明中采用现有的中文分词系统,例如中国科学院计算技术研究所的汉语词法分析系统ICTCLAS,该系统在分词的同时还可以对词性进行标记,这样可以通过词性标记来去除无实际意义的词,例如助词、数词、语气词等等,从而保留能体现文章主题的词,如名词、动词、形容词。由于中文分词已是现有成熟技术,在此不予赘述。
步骤S201,计算分词后每个词的TF-IDF(Term Frequency-Inverse DocumentFrequency,词频-逆文档频率)权重。具体地,每个词的TF-IDF权重采用如下公式计算:
Wt=该词在文章中出现的次数*该词的IDF权重
在本发明中,根据现有的IDF模型来获得每个词的IDF权重,现有的IDF模型可以使用开源的模型,也可以使用公开的语料自己训练IDF模型,本发明不以此为限。
步骤S202,根据步骤S201获得的每个词的TF-IDF权重计算出该输入文章的文章向量。
具体地,该输入文章的文章向量等于其每个词的词向量与其TF-IDF权重的乘积的加和。例如,采用如下公式获得:
其中,Vd为文章向量,Vk为每个词的词向量,Wk为每个词的TF-IDF权重。每个词的词向量Vk可利用开源的词向量模型计算获得。
步骤S3,根据该输入文章的文章向量与步骤S1的主题向量计算该输入文章与主题的相关度。
在本发明具体实施例中,该输入文章与主题的相关度等于主题向量与文章向量的余弦距离。可采用如下公式计算获得:
其中,A、B分别表示主题向量与文章向量。
图2为本发明一种突发事件信息相关度的无监督学习分析装置的系统架构图。本发明一种突发事件信息相关度的无监督学习分析装置,包括:
主题定义单元201,用于定义突发事件的主题及每个主题的关键词,并计算每个主题的主题向量。
在本发明中,主题定义单元201具体用于:
为突发事件定义若干主题,并为每个主题定义相应的关键词。
也就是说,在本发明中,可预先定义突发事件的主题,并定义每个主题的关键词,例如,定义“暴雨”主题,其可以包含“暴雨”、“强降水”、“强降雨”等关键词。
利用词向量模型计算每个主题的主题向量。
在本发明中,主题向量等于每个关键词的词向量的加和。也就是说,对于每个主题,可利用词向量模型计算获得其每个关键词的词向量,该主题的主题向量则为其每个关键词的词向量的加和。在本发明具体实施例中,词向量模型可以使用开源的词向量模型,也可以自行训练词向量模型,本发明不以此为限。
文章向量分析单元202,用于获取输入文章,计算该输入文章的文章向量。
具体地,文章向量计算单元202进一步包括:
分词模块,用于获取输入文章的正文,对文章正文进行中文分词。本发明中采用现有的中文分词系统,例如中国科学院计算技术研究所的汉语词法分析系统ICTCLAS,该系统在分词的同时还可以对词性进行标记,这样可以通过词性标记来去除无实际意义的词,例如助词、数词、语气词等等,从而保留能体现文章主题的词,如名词、动词、形容词。由于中文分词已是现有成熟技术,在此不予赘述。
TF-IDF权重计算模块,用于计算分词后每个词的TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)权重。具体地,每个词的TF-IDF权重采用如下公式计算:
Wt=该词在文章中出现的次数*该词的IDF权重
文章向量计算模块,用于根据TF-IDF权重计算模块获得的每个词的TF-IDF权重计算出该输入文章的文章向量。
具体地,该输入文章的文章向量等于其每个词的词向量与其TF-IDF权重的乘积的加和。例如,采用如下公式获得:
其中,Vd为文章向量,Vk为每个词的词向量,Wk为每个词的TF-IDF权重。其中,每个词的词向量Vk可利用开源的词向量模型计算获得。
相关度分析单元203,用于根据该输入文章的文章向量与主题定义单元201获得的主题向量计算该输入文章与主题的相关度。
在本发明具体实施例中,该输入文章与主题的相关度等于主题向量与文章向量的余弦距离。可采用如下公式计算获得:
其中,A、B分别表示主题向量与文章向量。
在本实施例中,以“内涝”主题为例,其对应的关键词设置为“内涝”、“暴雨”、“强降水”、“强降雨”、“积水”。输入一篇文章,计算该篇文章与“内涝”主题的相关度,分析结果如图3所示。
综上所述,本发明一种突发事件信息相关度的无监督学习分析方法及系统通过定义突发事件主题及每个主题的关键词,计算得到每个主题的主题向量,然后获取输入文章,计算该输入文章的文章向量,并根据该输入文章的文章向量与步骤S1的主题向量计算该输入文章与主题的相关度,以实现方便、快捷的分析出文章与主题的相关度,为文章打上相关的主题标签,并且本发明中多个主题之间是彼此独立的,不存在互斥关系。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 一种突发事件信息相关度的无监督学习分析方法及系统
- 一种突发事件信息采集报送系统及其信息报送和提醒方法