基于机器学习和分子模拟的用于增强结合和活性预测的方法
文献发布时间:2023-06-19 09:29:07
相关申请的交叉引用
本申请基于35U.S.C§119(e)要求于2018年3月5日提交的名称为“基于机器学习和分子模拟的用于增强结合和活性预测的方法”的美国临时专利申请号62/638,805的优先权。由此,美国临时专利申请号62/638,805的公开内容通过引用整体并入本文用于所有目的。
技术领域
本发明总体上涉及机器学习方法,并且更具体地涉及机器学习在分子模拟中的用途。
背景技术
一类蛋白质,即G-蛋白质偶联受体(GPCR),包含所有FDA批准药物中超过三分之一的靶标。一种这样的GPCR,即μ阿片类受体(μOR),体现了现有GPCR药物的优缺点。阿片类慢性止痛药(例如吗啡和氢可酮)是μOR激动剂,可达到止痛的主要治疗目的,但会引起严重的副作用,例如呼吸抑制和成瘾。
2015年,超过3万美国人死于阿片类药物过量,高于五年前的仅2万。在过去的一个世纪中,药物化学家力求合成没有依赖性问题的阿片类镇痛药,然而却是徒劳的。
发明内容
本发明示出了根据本发明的实施方案的用于分子模拟的系统和方法。一个实施方案包括用于预测配体与受体之间的关系的方法。该方法包括以下步骤:鉴定受体的多种构象;计算该多种构象中的每一种与一组一种或多种配体的对接评分;以及预测该组一种或多种配体与该受体的多种构象之间的关系。
在进一步的实施方案中,多种构象包括至少一种非结晶状态。
在另一个实施方案中,鉴定多种构象包括通过模拟受体与配体的相互作用来产生模拟数据。
在又进一步的实施方案中,鉴定多种构象还包括对模拟数据执行聚类操作以鉴定所述多种构象。
在又一个实施方案中,聚类操作是小批量k均值聚类(minibatch k-meansclustering)操作。
在又进一步的实施方案中,鉴定多种构象还包括对模拟数据执行降维操作。
在另一个附加实施方案中,鉴定多种构象包括鉴定用于多种构象中的每一种构象的一组反应坐标。
在进一步的附加实施方案中,计算对接评分包括模拟配体组和多种构象中的每一种的对接。
再次在另一个实施方案中,计算对接评分包括建立对接评分的特征矩阵,其中预测关系包括将特征矩阵输入到机器学习模型中。
再次在进一步的实施方案中,机器学习模型包括随机森林模型。
在又一个实施方案中,随机森林的pIC50截止值为8.0(10nM)。
在进一步的实施方案中,随机森林是第一随机森林模型,其中机器学习模型还包括第二随机森林模型。
在另一个附加实施方案中,第一随机森林模型用于结合,第二随机森林模型用于激动。
在进一步附加的实施方案中,将第一随机森林模型和第二随机森林模型应用于库配体,以便分别从第一随机森林模型和第二随机森林模型两者生成最终评分。
再次在又一个实施方案中,该方法还包括用于用来自具有已知药理性质的配体的数据库的配体训练机器学习模型的步骤。
再次在进一步的实施方案中,预测该关系包括确定配体是否为受体的激动剂。
在另一个附加的实施方案中,该方法进一步包括以下步骤:基于预测的关系鉴定一组一种或多种候选配体,并物理测试该组候选配体与受体的反应。
在进一步附加的实施方案中,预测该关系包括预测该组配体与多种构象中的每一种构象的关系,并基于对多种构象预测的关系预测该组配体与受体的聚集关系。
附加的实施方案和特征部分地在随后的描述中阐述,并且部分地在阅读说明书时对于本领域技术人员将变得显而易见,或者可以通过实施本发明而获悉。通过参考构成本公开的一部分的说明书和附图的其余部分,可以实现对本发明的本质和优点的进一步理解。
附图说明
专利或申请文件包含至少一个彩色的附图。专利局将依请求和支付必要的费用提供带有彩色附图的本专利或专利申请公开的副本。
参考以下附图和数据图,将更全面地理解说明书和权利要求,这些附图和数据图被呈现为本发明的示例性实施方案,并且不应被解释为对本发明范围的完整阐述。
图1示出了μOR的各种状态的实例。
图2示出了μOR的自由能态的可视化。
图3示出了根据本发明一些实施方案的提供配体发现的系统的实例。
图4示出了根据本发明的几个实施方案的配体发现元件的实例。
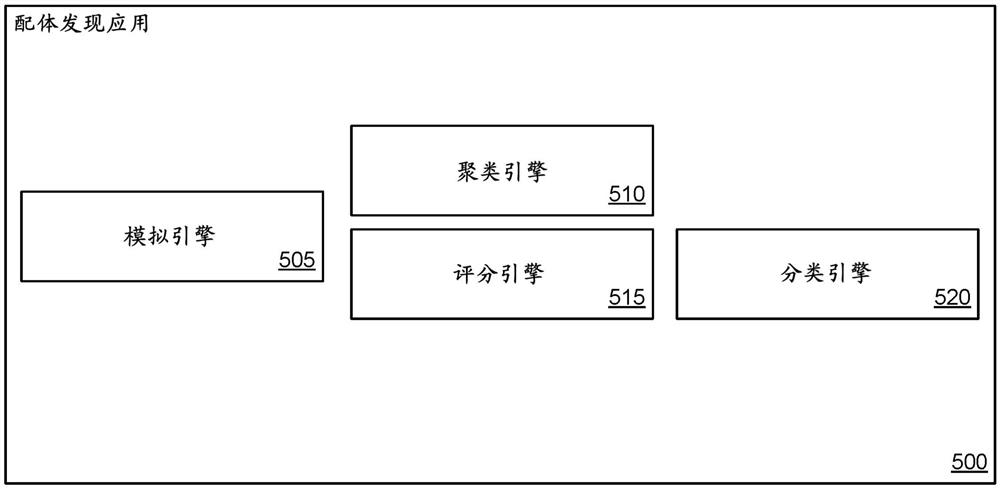
图5示出了根据本发明的实施方案的用于鉴定候选配体的配体发现应用的实例。
图6概念性地示出了根据本发明的实施方案的用于配体发现的流程方法的流程图。
图7示出了根据本发明的实施方案的MOR-1结合物的筛选的实例。
图8A-8D示出了FMP1-FMP32的结构和分子量。
图9示出了根据本发明的实施方案,在来自CHO细胞的膜中用FMP4抗125I-IBNtxA(0.1nM)的竞争研究。
具体实施方式
根据本发明的某些实施方案的系统和方法可以帮助转化研究人员鉴定新的G-蛋白偶联受体(GPCR)药物骨架。尽管在合成现有化学型衍生物的药物化学方面做出了巨大努力,但目前FDA批准的阿片类药物仍然存在严重的副作用,限制了其在治疗急性和慢性疼痛中的效用。根据本发明的几个实施方案的方法利用晶体学和分子建模以及机器学习来探索在μ阿片类受体(μOR)上具有活性的分子的先前未知的化学空间。尽管参考μOR描述了许多实例,但是本领域技术人员将容易理解,根据本发明的几个实施方案的方法可以容易地应用于期望具有任何种类的构象可塑性的任何受体,包括其他蛋白质、酶、GPCR、激酶、离子通道和核受体。
目前已知的阿片类物质的很大一部分是两种骨架(吗啡和芬太尼)之一的类似物。目前已知的绝大多数阿片类物质都集中在叔胺氮基序上。不同于这种具有百年历史的产生衍生物的策略,根据本发明的一些实施方案的系统和方法可以用于打开化学空间的全新区域来开发新型的μ阿片类物质。在一些实施方案中,本公开提供了可用于开发用于GPCR、激酶、离子通道和核受体的新型配体的系统和方法。
从根本上开发新分子需要创造性的方法来发现它们。几十年来,研究人员使用三种主要的药物发现方法:结构生物学(例如晶体学)、分子模拟(例如分子动力学,对接)和机器学习(例如定量结构-活性关系(Quantitative Structure-Activity Relationship,QSAR),随机森林等)。但是,这些方法被独立使用,因为还没有可以综合这些看似正交的方法的方案。在一些实施方案中,新颖的流程方法利用所有这些手段,以大大提高我们在药物设计中的预测能力。该方案的成功更广泛地支持了蛋白质功能的一个关键假设:蛋白质受体在其功能职责上代表了一个复杂的构象图景。
计算化学家通常通过针对蛋白质的晶体结构虚拟筛选化合物来分析候选药物,尽管事实是某些靶标(例如μ阿片类受体和GPCR家族的其他成员)跨越了许多非晶体状态。本发明的一些实施方案提供了一种用于发现蛋白质(例如μOR)的新构象状态的方法,所述方法利用分子动力学模拟,然后使用机器学习来学习配体-结构关系从而预测配体功能。根据本发明的几个实施方案的方法通过机器学习利用蛋白质的构象可塑性来系统地发现新的活性先导分子。使用这些模板作为起点采用经典药物化学方法进行结构-活性研究可能会产生对受体的亲和力更高的化合物。
与其他GPCR一样,μOR不是二进制转变,而是,生物物理实验表明,一般而言,GPCR,尤其是μOR,遍历一系列构象态。μOR采样(sample)了多种功能相关和药理预测状态。如此多种状态是当前的药物发现科学家无法达到的。根据本发明的许多实施方案的流程方法提供了新颖的计算方法,其使用空前的毫秒级分子动力学模拟来鉴定和合并这些状态,既在活性预测中产生增加的AUC,又使发现新的化学骨架成为可能。具体而言,在此实例中,鉴定两个晶体结构以外的重要μOR状态可提高预测受体上配体活性的能力。该方法适用于可能与受体结合的其他目标分子(或单个分子)。
在一些实施方案中,该方法的关键要素是估计每种配体对受体的几种构象中每一种的亲和力。与仅基于配体衍生的特征来预测的许多先前的虚拟筛选方法相反,根据本发明的一些实施方案的流程方法基于给定配体对每种受体构象的亲和力。在某些实施方案中,这些构象可以在单个MD模拟的预先步骤中获得,并跨越受体功能的结构基础集。相反,诱导拟合对接采样不同的构象,以估计蛋白质的单个对接(亲和力)评分。构象采样在时空上受到限制,仅延伸到结合口袋,必须针对每个配体重复,并且通过输出与亲和力相关的单个数字,它本质目的并不是预测激动作用。
进行了目标蛋白质(在本实例中为μOR)的长期分子动力学(MD)模拟,该蛋白质未带配体或与几种配体之一结合。在这个实例中,模拟结合到以下几种激动剂之一:BU72,舒芬太尼(Sufentanil),TRV130和IBNtxA。根据本发明的多个实施方案的MD模拟可以提供蛋白质(例如,μOR)可以采用的异构但全面的构象谱。该数据集扩展了以前的工作,这些工作侧重于受体的构象动力学。为了系统地处理大型平行MD数据集(例如,由史无前例的1.1毫秒的μOR模拟组成),可以应用根据多个实施方案的动力学驱动的机器学习方法,其中(1)使用多种方法例如(但不限于)最先进的稀疏时间结构独立成分分析(tICA)算法鉴定受体(例如μOR)最显著的反应坐标(在这种情况下,最慢动力学模式),以及(2)使用聚类方法,例如(但不限于)小批量K均值聚类(Minibatch K-Means clustering)定义了离散的受体状态。在一些实施方案中,(1)可以利用稀疏时间结构独立成分分析、时间结构独立成分分析、主成分分析(PCA)和/或独立成分分析(ICA)。在一些实施方案中,(2)可以利用小批量K均值聚类、K-均值聚类、随机梯度下降(SGD)K-均值、k-medoids、高斯混合建模、Jenks自然断裂优化、模糊C-均值聚类、k-均值++、X均值聚类、G均值聚类、内部聚类评估和/或Minkowski加权k均值。
在一些实施方案中,当候选配体的计算模拟结合至受体时,可以对接配体。在一些实施方案中,结合可以是两个或更多个分子之间的有吸引力的相互作用,其导致稳定的缔合,其中分子彼此紧邻。在一些实施方案中,结合可以是非共价的。在一些实施方案中,结合可以是可逆的共价的。在一些实施方案中,结合可以是不可逆的共价的。在一些实施方案中,结合可涉及化学键合。
在一些实施方案中,该无监督的步骤揭示了μOR的关键构象,其由在与晶体结构不同的非标准状态之间的中间体以及与晶体结构不同的非标准状态组成。μOR的各种状态的示例如图1所示。该图显示了活性晶体结构(PDB:5C1M)105,MD状态3 110和FMP4对MD状态3115的对接姿态。FMP4是已通过根据本发明的许多实施方案的流程方法鉴定的分子,其对μOR具有亲和力,并且也是受体的激动剂。实线箭头表示晶体结构的MD变化。虚线表示FMP4和μOR结合口袋残基之间的非共价相互作用。注意FMP4将与活性晶体中的残基M151和H297在空间上发生冲突,可能是由于其对该结构的对接评分非常低。M151和H297的运动使得能够在配体的非张力构象(non-strained conformation)中实现有利的非共价配体-蛋白质相互作用。与吗啡喃苯酚(morphinan phenol)不同,FMP4的苯环与具有π-T芳族相互作用的关键活化残基W293接合。
通过枚举μOR的状态空间,人们可以查询受体的构象以使用全原子结构信息来激发合理的设计。不可避免的大量数据源于MD,仅从庞大的模拟数据集中获得可操作的知识是重大的数据科学挑战。以每纳秒一帧的速度保存的一毫秒MD将包含一百万个构象,远超专家肉眼所能观察的。相反,通过追求动力学驱动的统计方法,根据本发明的许多实施方案的方法使得有可能在易于处理的范围内发现受体的关键构象。
在图2中示出了μOR的自由能态的可视化。具体地说,在此实例中,μOR的自由能态被投射到其两个最慢的整体自由度(collective degrees of freedom)上。tICA坐标1分开了活性和非活性(PDB:4DKL)晶体结构,而tICA坐标2是正交自由度,定义了几个非晶体学的非活性状态和类活性状态。这些状态包括状态3,状态3对于FMP4与受体接合的能力至关重要。
根据最近的研究,这些结构可以是潜在的可药物化状态,可以直接用于丰富对于μOR的合理药物发现活动。为了实现这种潜力,根据本发明的一些实施方案的流程方法训练有监督的机器学习模型以证明在两个二进制分类器任务中的显著改进:(1)区分激动剂和拮抗剂的能力,以及(2)区分在受体处的结合物和非结合物的能力。
在一些实施方案中,部署随机森林以将结构与功能相联系。本领域技术人员将认识到,在不脱离本发明的情况下,可以采用其他机器学习方法(例如但不限于支持向量机、决策树和人工神经网络)。具有已知药理性质的配体(例如阿片类物质)的数据库可以对接于晶体结构以及每种状态的一组一种或多种代表性构象。根据本发明的各种实施方案的不同构象可包括受体的非晶体状态或其他构象。可以通过多种方法来鉴定根据本发明某些实施方案的构象,所述方法包括(但不限于)实验(例如但不限于晶体学、核磁共振(NMR)、冷冻电子显微镜(cryoEM)等)和/或通过计算(例如但不限于分子动力学模拟、蒙特卡洛模拟、深度神经网络驱动的构象生成等)。
在某些实施方案中,每种配体对每种MD构象的对接评分可以然后用作二元分类器模型的输入或特征矩阵,以用于在感兴趣受体处的激动和结合。在许多实施方案中,特征矩阵是这样的结构,使得每一行是配体,每一列是特征(对每个MD状态和对每个晶体结构的对接评分)。在各种实施方案中,特征矩阵中的元素(i,j)是第i个配体与第j个构象状态的对接评分。可以使用对接评分来确定相对于彼此的等级顺序,即用于一组配体。对接评分可以将分子的结合亲和力与蛋白质的整体或该蛋白质的给定状态相关联。该矩阵可用于对接评分上的不同功能,以生成一个更好地预测/关联整体亲和力的数字。在一些实施方案中,其中具有关于N个配体的结合亲和力或激动性的先验信息,通过关于N个配体中每一个针对K个构象状态中的每一个的对接评分,可以获得将K个对接评分集映射到结合亲和力的函数。
这种来自晶体学和MD的双重无监督和有监督的基于ML的结构信息合成在两个任务上产生统计学上显著的富集。在一个实例中,根据本发明的一些实施方案的方法(除了晶体结构之外还包括对接至MD状态),与单独的晶体结构相比,在激动和结合方面实现了中位曲线下面积(AUC)改善。在一些实施方案中,激动的中位AUC改善为约0.11。在一些实施方案中,激动的中位AUC改善为0.01至0.5。在一些实施方案中,激动的中位AUC改善为0.5至1.0。在一些实施方案中,激动的中位AUC改善为0.1至0.3。在一些实施方案中,激动的中位AUC改善为0.3至0.6。在一些实施方案中,激动的中位AUC改善为0.6至0.9。在一些实施方案中,结合的中位AUC改善为约0.15。在一些实施方案中,结合的中位AUC改善为0.01至0.5。在一些实施方案中,结合的中位AUC改善为0.5至1.0。在一些实施方案中,结合的中位AUC改善为0.1至0.3。在一些实施方案中,结合的中位AUC改善为0.3至0.6。在一些实施方案中,结合的中位AUC改善为0.6至0.9。
作为对激动的鲁棒性的进一步测试,采用了骨架拆分(scaffold split)。具体而言,对一系列模型进行了训练,其中从训练数据中删除了美沙酮或芬太尼的类似物,并将这些类似物放置在留出测试集(held-out test set)中。换句话说,这些模型都不具有美沙酮(或备选地,芬太尼)类似物的先验知识。然而,该模型成功地将美沙酮-和芬太尼-衍生的激动剂与随机拮抗剂组区分开。为结合预测任务定义了类似的骨架拆分,在AUC中产生了可比的增益。因此,由于根据本发明的许多实施方案的方法没有明确地掺入配体的化学组成,因此除了现有的衍生物之外,它们还可以被更好地装备以发现新的阿片类活性骨架。基于这些结果,通过结合单独的晶体学无法预测的、并在模拟中被配体稳定的构象状态,丰富了根据本发明多个实施方案的阿片类物质预测。
用于配体建模和预测的系统和方法
图3中示出了根据本发明的一些实施方案的提供建模和预测的系统。网络300包括通信网络360。通信网络360是诸如互联网的网络,该网络允许连接到网络360的设备与其他连接的设备进行通信。服务器系统310、340和370连接到网络360。服务器系统310、340和370中的每个是一组经由内部网络互相通信连接的一个或多个服务器计算机系统,所述内部网络执行通过网络360向用户提供云服务的流程。出于本讨论的目的,云服务是由一个或多个服务器系统执行以向网络上的设备提供数据和/或可执行应用的一个或多个应用。示出服务器系统310、340和370,每个服务器系统具有经由内部网络连接的三个服务器。然而,服务器系统310、340和370可以包括任何数量的服务器,并且任何其他数量的服务器系统可以连接到网络360以提供云服务(包括但不限于虚拟服务器系统)。根据本发明的各个实施方案,用于建模和预测配体性质的流程方法由在单个服务器系统和/或通过网络360通信的一组服务器系统上执行的一个或多个软件应用程序提供。
根据本发明的各种实施方案,用户可以使用连接到网络360的个人设备380和320来执行用于建模和预测配体性质的流程方法。在所示的实施方案中,个人设备380被示为经由常规的“有线”连接连接到网络360的台式计算机。然而,个人设备380可以是台式计算机、笔记本计算机、智能电视、娱乐游戏控制台或通过“有线”或“无线”网络连接连接到网络360的任何其他设备。移动设备320使用无线连接连接到网络360。无线连接是使用射频(RF)信号、红外信号或任何其他形式的无线信号传导以连接到网络360的连接。在图3中,移动设备320是移动电话。但是,移动设备320可以是移动电话、个人数字助理(PDA)、平板电脑(tablet)、智能手机、虚拟现实头戴式视图器、增强现实头戴式视图器、混合现实头戴式视图器或任何其他类型的不背离本发明情况下通过无线连接连接到网络360的设备。根据本发明的一些实施方案,用于建模和预测配体性质的流程方法由用户设备执行。
如将容易理解的,用于建模和预测配体性质的特定计算系统很大程度上取决于给定应用的要求,并且不应被视为限于任何特定计算系统实施。
在图4中示出了根据本发明的几个实施方案的配体发现元件。根据本发明的许多实施方案的配体发现元件可以包括(但不限于)一个或多个移动设备、计算机、服务器和云服务。配体发现元件400包括处理器410、通信接口420和存储器430。
本领域技术人员将认识到,在不背离本发明的情况下,特定的配体发现元件可包括为简洁起见而省略的其他组分。处理器410可以包括(但不限于)处理器、微处理器、控制器或处理器、微处理器和/或控制器的组合,其执行存储在存储器430中的指令以操纵存储在存储器中的数据。处理器指令可以设置处理器410以执行根据本发明某些实施方案的方法。通信接口420允许训练元件400依据处理器410执行的指令通过网络传送和接收数据。
存储器430包括配体发现应用程序432、受体数据434、配体数据436和模型数据438。根据本发明的几个实施方案的配体发现应用用于分析配体并鉴定可以测试与受体的相互作用的候选配体。在几个实施方案中,配体发现应用可以使用受体数据和/或配体数据,所述受体数据和/或配体数据包括从各种来源产生的数据,所述来源包括(但不限于)分子对接模拟和/或具有已知药理性质的阿片类物质数据库。根据本发明的各种实施方案的模型数据438可包括可用于各种目的的无监督和有监督模型的数据,例如(但不限于)聚类以鉴定离散的构象状态,将配体分类为激动剂/拮抗剂,和/或将配体分类为结合/非结合。
尽管在图4中示出了配体发现元件400的特定实例,但是,在适合根据本发明的实施方案的特定应用的要求时,各种训练元件中的任何一种都可以被用来执行类似于本文所述的流程方法。
在图5中示出了根据本发明的一个实施方案的用于鉴定候选配体的配体发现应用。配体发现应用500包括模拟引擎505、聚类引擎510、评分引擎515和分类引擎520。根据本发明的许多实施方案的配体发现应用可以分析配体和受体数据以鉴定与受体有关的各种用途的候选配体。
在各种实施方案中,模拟引擎可以用来模拟各种受体构象。在许多实施方案中,模拟引擎可以计算配体和受体之间的对接评分。
根据本发明的多个实施方案的聚类引擎可以基于模拟数据来鉴定离散的受体构象状态。在几个实施方案中,聚类引擎使用诸如(但不限于)小批量k均值聚类和凝聚层次聚类(agglomerative hierarchical clustering)的聚类方法。
根据本发明的各种实施方案的评分引擎可以计算配体与受体的对接评分。在许多实施方案中,评分引擎可以评估来自模拟引擎的配体和受体的模拟。模拟可以包括配体与由聚类引擎鉴定的受体的几个离散构象的模拟。在许多实施方案中,评分引擎可以产生一组配体和受体的一组构象状态的对接评分的特征矩阵。
在各种实施方案中,分类引擎可用于分类或预测配体和受体之间的相互作用。在一些实施方案中,分类引擎可以是有监督的学习算法或无监督的学习算法,例如(但不限于)支持向量机、线性回归、逻辑回归、朴素贝叶斯(naive bayes)、线性判别分析、决策树、k最近邻算法(k-nearest neighbor algorithm)、神经网络和/或相似性学习(similaritylearning)。在一些实施方案中,有监督的学习可以是半监督学习、主动学习、结构预测和/或排序学习(learning to rank)。根据本发明一些实施方案的分类引擎可以实施分类器,例如(但不限于)完全连接的神经网络(FCNN)和/或随机森林。在各种实施方案中,分类引擎将由评分引擎生成的特征矩阵作为输入,并输出配体与受体具有特定关系(例如,结合/非结合、激动/拮抗等)的可能性。在一些实施方案中,通过以下等式从两个生成的最终分数的乘积计算对接评分:
P(结合物∩激动剂|模型)=P(结合物|模型
尽管在图5中示出了配体发现应用的具体实例,但是,在适合根据本发明的实施方案具体应用的要求时,可以将各种配体发现应用中的任何一种用于执行与本文所述的那些类似的流程方法。
图6中示出了根据本发明的一个实施方案的用于发现配体的流程方法的流程图。流程方法600鉴定(605)受体的多种构象。在许多实施方案中,不同的构象(或状态)是基于受体的长时间分子对接(MD)模拟。可以仅利用受体或基于受体与已知配体的相互作用来执行根据本发明几个实施方案的模拟。在几个实施方案中,基于鉴定由MD模拟生成的状态数据中的聚类的聚类方法来鉴定不同的构象。可以以各种方式来执行根据本发明的各种实施方案的聚类,包括(但不限于)小批量K均值聚类和凝聚层次聚类。根据本发明的多个实施方案的不同的离散构象可以代表受体的各种状态,包括(但不限于)晶体状态、晶体状态之间的中间体以及不同于晶体结构的非标准状态。
流程方法600计算(610)一组一种或多种配体和所鉴定构象中的每一种构象的对接评分。在许多实施方案中,可以使用分子对接模拟来计算对接评分,该分子对接模拟可以模拟一组配体与受体的每种构象之间的相互作用。可以在特征矩阵中提供根据本发明的多个实施方案的计算的对接评分,其中具有每个配体-构象组合的对接评分。
流程方法600预测(615)这组配体与受体之间的相互作用。在许多实施方案中,预测的相互作用可包括该组配体是否与受体结合。备选地或结合地,预测的相互作用可以包括该组配体是否是受体的激动剂。可以使用随机森林来进行根据本发明的许多实施方案的相互作用的预测,该随机森林已经过训练以将配体分类为特定受体的结合物或激动剂。在某些实施方案中,预测配体和受体之间的相互作用包括预测配体和受体的每种构象之间的相互作用,然后计算对于配体和受体整体之间的相互作用的聚集预测。在各种实施方案中,预测的相互作用用于鉴定一组一种或多种配体并物理测试鉴定的配体与受体的相互作用。
一方面,本公开提供了一种预测配体与受体之间的关系的方法,该方法包括:鉴定受体的多种构象;计算多种构象中的每一种和一组一种或多种配体的对接评分;并预测一组一种或多种配体与受体的多种构象之间的关系。
在一些实施方案中,多种构象包括单个受体的构象。在一些实施方案中,构象可以源自实验(晶体学,NMR,CryoEM等)或计算(分子动力学模拟,蒙特卡洛模拟,深度神经网络驱动的构象产生或其组合)。
在一些实施方案中,多种构型包括至少一种非晶体状态。
在各种实施方案中,鉴定多种构象包括通过模拟受体与配体的相互作用来产生模拟数据。
在几个实施式中,鉴定多种构象还包括对模拟数据执行聚类操作以鉴定多种构象。
在几个实施方案中,鉴定多种构型还包括对模拟数据执行降维操作。根据本发明的多个实施方案的降维操作可以包括(但不限于)tICA、稀疏tICA、ICA、PCA、t-SNE等以及它们的组合。
在各种实施方案中,鉴定多种构象包括针对所述多种构象中的每一种构象鉴定一组反应坐标。
在许多实施方案中,计算对接评分包括模拟该组配体与多种构象中的每一种的对接。
在几个实施方案中,计算对接评分包括建立对接评分的特征矩阵,其中预测关系包括将特征矩阵输入到机器学习模型中。在一些实施方案中,机器学习模型是随机森林。
在许多实施方案中,用来自具有已知药理性质的配体的数据库的配体进一步训练机器学习模型。在一些实施方案中,分子可以是阿片类物质。
接下来,预测所述关系包括确定所述配体是否为所述受体的激动剂。
接下来,基于预测的关系鉴定一组一种或多种候选配体;并且对一组候选配体与受体的反应进行物理测试。
接下来,预测所述关系包括:预测所述一组配体与所述多种构象的每一种构象的关系;并且基于所述多种构象的预测关系,预测所述一组配体与受体的聚集关系。
在一些实施方案中,随机森林模型的pIC50截止值为8.0(10nM)。在各种实施方案中,预测关系包括预测亲和力或激动性的定量度量,例如(但不限于)IC50,EC50和/或Ki。备选地或相结合地,根据本发明的许多实施方案的预测关系可以包括对关系进行分类,诸如(但不限于)结合物相对于非结合物。在几个实施方案中,可以基于一些截止值或阈值,例如pIC50为8.0(10nM),对关系进行分类。
接下来,进一步包括第一随机森林模型和第二随机森林模型,其中两个模型都被训练。
接下来,其中第一随机森林模型用于结合,第二随机森林模型用于激动。
接下来,其中将第一随机森林模型和第二随机森林模型应用于库配体,以便分别从第一随机森林模型和第二随机森林模型两者生成最终分数。
在另一方面,本公开提供了一种用于预测配体与受体之间的关系的系统,该系统包括:一个或多个处理器,其被单独地或共同地设置为:鉴定受体的多种构象;计算多种构象中的每一种和一组一种或多种配体的对接评分;并预测一组一种或多种配体与受体的多种构象之间的关系。
在另一方面,本公开提供了用于药物发现的方法和系统。该方法可以包括通过机器学习从预测的分子特征中鉴定候选配体。在一些实施方案中,鉴定候选配体包括:选择受体的多种构象;计算多种构象中的每一种和一组一种或多种配体的对接评分;计算一组一种或多种配体与受体的多种构象之间的关系;以及从一组一种或多种配体与受体的多种构象之间的关系预测候选配体。在一些实施方案中,用于鉴定候选配体的系统包括一个或多个处理器,所述一个或多个处理器被单独或共同设置为:选择受体的多种构象;计算多种构象中的每一种和一组一种或多种配体的对接评分;计算一组一种或多种配体与受体的多种构象之间的关系;并从一组一种或多种配体与受体多种构象之间的关系预测候选配体。
上文描述了根据本发明实施方案的用于配体发现的具体流程方法;然而,本领域技术人员将认识到,当适合根据本发明的实施方案的特定应用的要求时,可以使用任何数量的流程方法。
尽管已经在某些特定方面描述了本发明,但是许多另外的修改和变化对于本领域技术人员将是显而易见的。因此,应当理解,在不脱离本发明的范围和精神的情况下,可以以不同于具体描述的方式来实践本发明。因此,本发明的实施方案在所有方面都应被认为是举例说明性的而非限制性的。
实施例
提供以下实施例以举例说明要求保护的发明,但不限制所要求保护的发明。
实施例1
提供以下实施例以举例说明要求保护的发明,但不限制所要求保护的发明。
实施例2
定义了骨架拆分,其中(1)将与芬太尼相比Tanimoto评分≤0.5的激动剂配体放入训练集中,(2)将与芬太尼相比Tanimoto评分≥0.7的激动剂配体放入测试集中,和(3)拮抗剂随机分布在训练集和测试集之间。
a)
芬太尼类似物配体(测试集):
['乙酰芬太尼','丙烯芬太尼','3-烯丙基芬太尼','α甲基硫代芬太尼','氮丙辛','β羟基芬太尼','β羟基硫代芬太尼','丁酰芬太尼','卡芬太尼','去甲普鲁丁','地恩丙胺','芬太尼','4-氟丁酰芬太尼','呋喃基芬太尼','洛芬太尼','4-甲氧基丁酰芬太尼','α-甲基乙酰芬太尼','3-甲基丁酰芬太尼','正甲基卡芬太尼','3-甲基芬太尼','β-甲基芬太尼','3-甲基硫代芬太尼','奥芬太尼','羟甲芬太尼','对氟芬太尼','pepap','非那丙胺','酚那利定','4-苯基芬太尼','普地立定','普鲁丁','普罗庚嗪','prosidol','r-30490','瑞芬太尼','舒芬太尼','硫代芬太尼','三甲利定','u-47700']
非芬太尼类似物激动剂(训练集):
['7-pet','阿利马多','阿法美沙多','叠氮吗啡','bdpc','倍他美沙朵','c-8813','西博帕多','氯吗啡','氯氧吗啡胺','环丙法多',“氯尼他秦','dadle','damgo','地索吗啡','二氢埃托啡','二氢吗啡','地美沙朵','地美庚醇','二甲基氨基新苯甲酮','伊卢多啉','内吗啡肽','内吗啡肽-1','14-乙氧基美托酮','依托尼秦','埃托啡','血吗肽-4','异可待因','氢吗啡醇','氢吗啡酮','ibntxa','氯胺酮','利非他明','左芬啡烷','左吗喃','14-甲氧基二氢吗啡酮','14-甲氧基美托酮','甲地索啡','甲二氢吗啡','6-亚甲基二氢脱氧吗啡','美托酮','mitragynine_pseudoindoxyl','6-单乙酰吗啡','吗啡','吗啡-6-葡糖苷酸','吗啡酮','mr-2096','奥利替丁','氧化吗啡','羟吗啡醇','羟吗啡酮','戊吗酮','非那佐辛','正苯乙基去甲地素吗啡','正苯乙基去甲吗啡','非诺啡烷','14-苯基丙氧基美托酮','哌西那多','pzm21','消旋啡烷','ro4-1539','sc-17599','司吗酮','噻吩诺啡','替利定','trimu_5','维米诺']
拮抗剂:
['左洛啡烷','6β-纳曲醇-d4','β-氯代纳屈胺','β-氟曲沙胺','阿维莫泮',
'at-076','axelopran','bevenopran','clocinnamox','cyclofoxy','cyprodime','依他佐辛','ly-255582','methocinnamox','甲基纳曲酮','methylsamidorphan','纳美芬','纳洛索酮','纳洛索醇(naloxegol)','naloxol','纳洛酮嗪','纳洛酮','纳曲唑酮','纳曲酮','奥昔啡烷','夸达佐辛','samidorphan']
定义了骨架拆分,其中(1)将与美沙酮相比Tanimoto评分≤0.5的激动剂配体放入训练集,(2)将与美沙酮相比Tanimoto评分≥0.7的激动剂配体放入测试集中,和(3)拮抗剂随机分布在训练集和测试集之间。
b)
美沙酮类似物配体(测试集)。
['醋美沙朵','阿醋美沙朵','阿法美沙多','倍醋美沙朵','倍他美沙朵','地匹哌酮','ic-26','异美沙酮','凯托米酮','左醋美沙朵','左美沙酮','美沙酮','甲基凯托米酮','诺美沙朵','苯吗庚酮','丙基凯托米酮','r4066']
非美沙酮类似物(训练集)。
['7-pet','阿利马多','叠氮吗啡','bdpc','c-8813','西博帕多','氯吗啡','氯氧吗啡胺','环丙法多',“氯尼他秦','dadle','damgo','地索吗啡','二氢埃托啡','二氢吗啡','地美沙朵','地美庚醇','二甲基氨基新苯甲酮','伊卢多啉','内吗啡肽','内吗啡肽-1','14-乙氧基美托酮','依托尼秦','埃托啡','血啡肽-4','异可待因','氢吗啡醇','氢吗啡酮','ibntxa','氯胺酮','利非他明','左芬啡烷','左吗喃','14-甲氧基二氢吗啡酮','14-甲氧基美托酮','甲地索啡','甲二氢吗啡','6-亚甲基二氢脱氧吗啡','甲氧基二氢吗啡酮','mitragynine_pseudoindoxyl','6-单乙酰吗啡','吗啡','吗啡-6-葡糖苷酸','吗啡酮','mr-2096','奥利替丁','羟吗啡酮','羟吗啡','羟吗啡酮','戊吗酮','非那佐辛','正苯乙基去甲吗啡','正苯乙基吗啡','非诺啡烷','14-苯基丙氧基美托酮','哌西那多','pzm21','消旋啡烷','ro4-1539','sc-17599','司吗酮','噻吩诺啡','替利定','trimu_5','维米诺']
拮抗剂:
['左洛啡烷','6β-纳曲醇-d4','β-氯代纳屈胺','β-氟曲沙胺','阿维莫泮','at-076','axelopran','bevenopran','clocinnamox','cyclofoxy','cyprodime','依他佐辛','ly-255582','methocinnamox','甲基纳曲酮','methylsamidorphan','纳美芬','纳洛索酮','纳洛索醇','naloxol','纳洛酮嗪','纳洛酮','纳曲唑酮','纳曲酮','奥昔啡烷','夸达佐辛','samidorphan']
实施例3
每个特征(MD状态,晶体结构)的随机森林平均基尼杂质减少量(Random Forestaverage Gini impurity reduction)(“重要性”)用于a)区分阿片类激动剂和拮抗剂,以及b)区分来自μOR的结合物和非结合物。
a)
b)
实施例4
与单独的晶体相比,对接至MD状态和晶体结构两者在统计学上显著提高了将μOR结合物与非结合物区分开的能力。下表显示了在对于不同拆分和模型类型的1,000个训练-验证拆分(train-valid splits)中,在验证集中的ROC曲线下面积(AUC)中位数表现。如果99%Wilson评分置信区间(CI)的下限大于0.5,则晶体单独法和晶体+MD结构方法之间的差异被认为具有统计学意义。值得注意的是,对于每个数据集,在晶体结构外结合MD衍生的结构在统计学上显著提高了对结合物和非结合物的区分能力(由AUC测得)。值得注意的是,当从训练集中删除芬太尼(或美沙酮)类似物时,模型仍能够区分芬太尼(或美沙酮)衍生物激动剂与随机拮抗剂组。这表明以这种方式拟合的模型除了能够发现现有的阿片类激动剂骨架衍生物之外,还能够发现新的阿片类激动剂骨架。
实施例5
与单独的晶体相比,对接至MD状态和晶体结构两者在统计学上显著提高了将μOR结合物与非结合物区分开的能力。下表显示了在对于不同拆分和模型类型的1,000个训练-验证拆分中,在验证集中的ROC曲线下面积(AUC)中位数表现。如果99%Wilson评分置信区间(CI)的下限大于0.5,则晶体单独法和晶体+MD结构方法之间的差异被认为具有统计学意义。请注意,对于每个数据集,在晶体结构外结合MD衍生的结构在统计学上显著提高了对结合物和非结合物的区分能力(由AUC测得)。值得注意的是,当从训练数据中删除具有相似骨架的分子(通过Tanimoto相似度评分>0.7进行测量)时,模型仍然能够区分结合物和非结合物。这表明以这种方式拟合的模型除了能够发现现有阿片类骨架的衍生物外,还能够发现新的阿片类骨架。
数据集由对μOR的结合亲和力具有实验已知值的化合物组成。称为“测得的Ki”的数据集仅包括那些具有实际数值的Ki值的化合物,称为“全部”的数据集还包括不具有列出的Ki但称为“非活性”的化合物。因此,“测量的Ki”数据集是“所有”系列数据集的子集。结合物被认为是pIC50大于某些截止值(列在“数据集”表中)的化合物,而非结合物的pIC50小于该截止值。例如,“全部,pIC50截止值=7.0”表示一个数据集,其中(a)可测量的pIC50<7.0的配体和列为“非活性”的配体都被认为是非结合物,(b)可测量的pIC50约7.0的配体和其他已知的激动剂和拮抗剂被认为是结合物。
实施例6
鉴定几种新的阿片类活性配体,FMP4
本文涉及的方法鉴定了新的配体FMP4。值得注意的是,FMP4没有合成阿片类物质的特征,因为它没有碱性叔胺或苯酚。
一组133,564个小分子与μOR的晶体结构和计算机模拟构象异构体对接,得到133,564行乘27列的特征矩阵,其中元素(i,j)是第i个配体与第j个构象状态的对接评分。将两个用于结合和激动的训练随机森林模型应用于每个库配体,得出由两个值的乘积计算得出的最终评分:
P(结合物∩激动剂|模型)=P(结合物|模型
命中的模型表现和骨架对为二进制分类器选择的pIC50截止值高度敏感。虽然具有较低结合亲和力阈值的模型通常具有较高的AUC,但最佳命中(top hits)显示出偏向于具有类似于已知骨架的叔碱性氮的化合物。pIC50截止值为8.0(10nM)的随机森林模型用于优化新型骨架的发现。在一些实施方案中,pIC50可以是至少3.0、4.0、5.0、6.0、7.0、8.0、9.0、10.0、11.0或更高。在一些实施方案中,pIC50可以是3.0至11.0,3.0至10.0,3.0至9.0,3.0至8.0,3.0至7.0,3.0至6.0,3.0至5.0,5.0至11.0,5.0至10.0,5.0至9.0,5.0至8.0、5.0至7.0、8.0至11.0或8.0至10.0。
实验测定了30种可获得的、评分最高的化合物。30个中有至少三个对μOR表现出微摩尔亲和力。一种化合物,即FMP4,具有独特的结构:无碱性胺或苯酚。在进一步的阿片类物质转染细胞系结合试验中,FMP4对MOR-1、KOR-1和DOR-1的结合亲和力分别为3217±153nM、2503±523nM和8143±1398nM。在[35S]GTPγS功能测定中,FMP4还是弱的MOR-1部分激动剂。FMP4与已知的阿片类激动剂和拮抗剂不同,与其他已知的μOR激动剂和拮抗剂相比,具有最高Tanimoto评分0.44。在结合试验中对同一数据集中的FMP4类化合物进行了表征,两种化合物FMP1和FMP16显示对MOR-1的亲和力<10μM。
图7显示了MOR-1结合物的筛选:以10μM浓度的单剂量进行对125IBNtxA特异性结合MOR-1的抑制。三种化合物FMP1、4和16(圆圈圈出)显示对MOR-1结合~30%的抑制(红色虚线表示显示~30%的抑制的化合物)。每个小组都是已被独立重复了至少三次的代表性实验。图8A-8D示出了FMP1-FMP32的结构和分子量。
实施例7
FMP4的分析和μOR的新型活性样状态的鉴定
建模预测FMP4以独特的方式结合并促进μOR的激活。FMP4对于MD状态3具有相对较高的对接评分,MD状态3据计算对激动和结合是重要的。图1表明,tIC.1(最慢的tICA反应坐标)联系了两个晶体状态。图2显示第二慢的tICA,即tIC.2,在动力学上与tIC.1正交,并定义了几种非晶体状态。
通过其沿tIC.1的进展和通过GPCR文献的传统度量标准(例如跨膜螺旋6的向外取向和NPxxY基序残基N332
图9示出了在稳定表达所指示的克隆的小鼠阿片类受体的CHO细胞的膜中进行的FMP4抗125I-IBNtxA(0.1nM)的竞争研究。每个图是已被独立重复了至少3次的代表性实验。误差棒代表一式三份样品的SEM。看不见的误差线小于符号的大小。FMP4对MOR-1、KOR-1和DOR-1的亲和力分别为3217±153nM、2503±523nM和8143±1398nM。
- 基于机器学习和分子模拟的用于增强结合和活性预测的方法
- 一种分子间的结合活性预测方法及装置