一种基于深度学习的语义地图构建方法
文献发布时间:2023-06-19 10:00:31
技术领域
本发明属于人工智能技术领域,具体涉及一种基于深度学习的语义地图构建方法。
背景技术
随着机器人、计算机、传感器、自动化控制、人工智能等技术的高速发展,自主移动机器人构建语义地图的技术已经成为科技发展最前沿的领域之一。
传统SLAM技术中,移动机器人常用的场景感知传感器有光学类传感器、雷达类传感器两大类。雷达类传感器体积较大且价格昂贵,易受烟尘的影响发生散射,影响识别精度,对场景认知能力局限于轮廓特征,不能充分利用场景丰富的语义特征。相反,光学类传感器体积小、重量轻、性价比高,能够充分利用场景丰富的语义特征,是理想的识别媒介。
但随着视觉信息的越丰富,识别的场景越来越复杂,场景中图像的全局和局部特征相互很杂,再加上运动过程中需要同时完成图像处理,实时性要求高,给传统的室内精准导航和建图任务带来了挑战。深度学习的出现为图像的描述提供了新的思路,应用深度学习对建图,环境感知算法的改进研究,利用语义信息提高SLAM的精度,鲁棒性。目前,国内在这方面尚无成熟技术。
发明内容
本发明的目的是提供一种基于深度学习的语义地图构建方法,解决了现有技术中的SLAM建图方法误差大的问题。
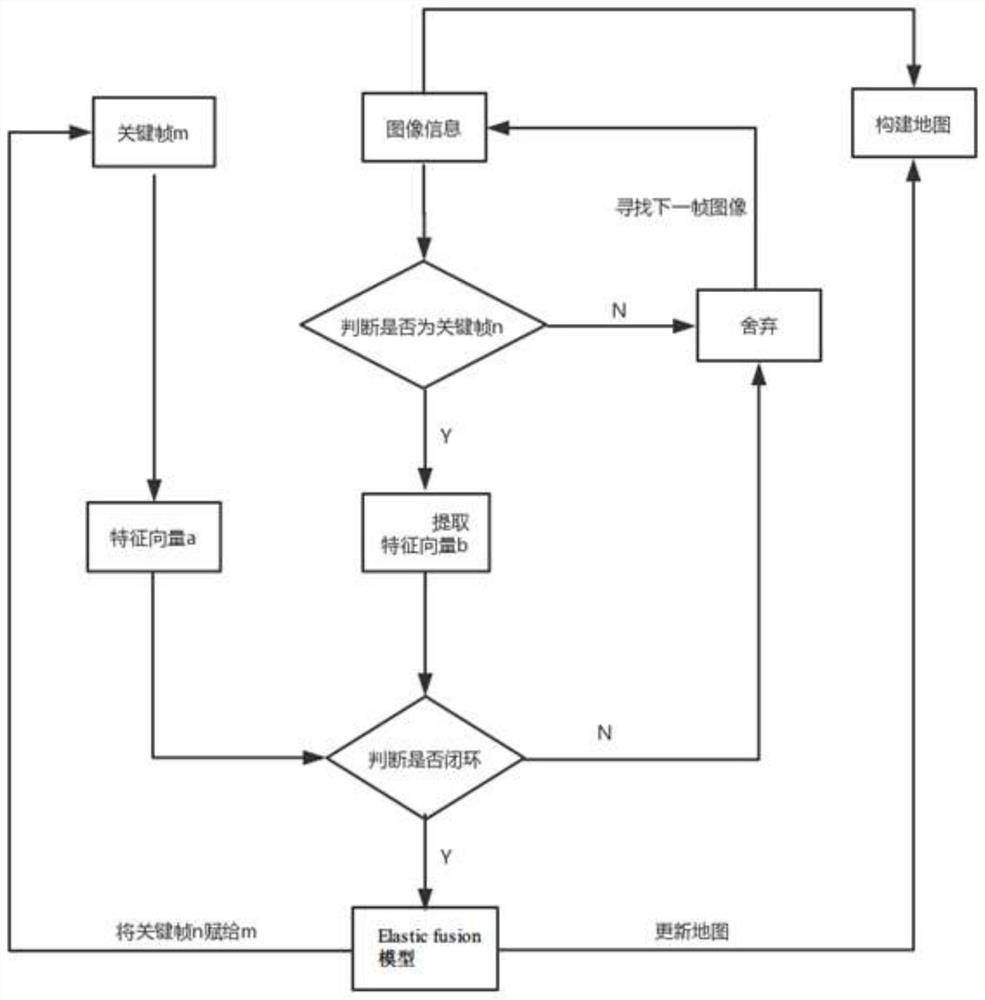
本发明所采用的技术方案是,一种基于深度学习的语义地图构建方法,具体包括如下步骤:
步骤1:对安装在机器人上方的深度摄像头进行标定,通过RGBD图像配准计算位姿,根据输入点云利用ICP算法求解位姿;
步骤2:在步骤1计算出位姿后,同时深度相机实时采集周围环境图像信息,使用openGL将当前帧的点云和已重建的部分进行融合,进行三维地图的建立;
步骤3:将RGBD相机获取到的当前时刻图像和前一个关键帧的特征进行匹配,判断当前时刻图像是否为关键帧;
假设不是关键帧,则查找新的图片,确定新的关键帧;
假设是关键帧,则将关键帧送入改进的PSP-Net模型中进行二维语义信息的提取,获得实时图像的二维语义信息,再进行闭环检测,得到闭环结果;
步骤4:将步骤2中建立的三维地图作为输入,和步骤3中二维图像语义分割结果送入Elastic fusion模型进行三维语义分割地图的重建。
本发明的特征还在于,
步骤1中,根据输入点云利用ICP算法求解位姿的具体过程如下;
步骤1.1:对RGBD深度相机获取的两幅深度图像做3层抽样,再对于抽样后的两幅深度图像做滤波,点云配准以coarse-to-fine的方式进行迭代;
步骤1.2:在给定深度图像内参情况下,通过原始未抽样的深度图像计算点的三维点云坐标,用于点云的配准和融合,对于滤波后的两幅深度图像也计算三维点云坐标,用于计算法向量;
步骤1.3:根据步骤1.2中求得的两幅深度图像点云坐标,通过投影算法计算一幅图像在另一幅图像中的投影像素坐标;
步骤1.4:根据步骤1.3中的计算的匹配点,再计算匹配点的极小化点到平面距离计算位姿,使得目标函数误差小于设定的最小值时,或者到达设置的迭代次数停止迭代,否则进入步骤1.3。
步骤1.3中,投影像素坐标函数表达式如下:
k(u
其中,k(u
p
T
K:相机内参数,
(u
步骤1.4中,极小化点到平面距离计算位姿算法流程如下:
(1)设置目标函数如下:
上式表达式中旋转矩阵R和平移矩阵t是待求解的位姿,R与t可通过以下公式来表示:
t=[t
其中α、β、γ分别表示沿x、y、z轴的旋转角度,在每次迭代时实际是值很小的R的变化值ΔR和t的变化值Δt,p
(2)将R线性化,当相邻两帧之间位姿变化较小时,有以下近似:
sin(θ)=θ,cos(θ)=1 (5)
(3)在三个方向上R的旋转角为r=(α,β,γ)对于
Rp
(4)以上目标函数对6个维度位姿参数求导并且令导数为0,得到Ax+b=0,其中:A的表达式为:
b的表达式为:
未知参量x表达式为:
x=(α,β,γ,t
通过计算求解Ax+b=0就能够求出R与t,即计算出的位姿矩阵。
步骤3中,将关键帧送入改进的PSP-Net模型中进行二维语义信息的提取的过程具体如下:
(1)通过融合不同区域的上下文信息并整合不同区域的上下文信息,构建金字塔汇集模块(Pyramid pooling module,PPM),赋予模型分析全局先验知识的能力,使得模型具有理解全局上下文信息的能力;
为了充分利用PSP-Net编码器部分包含的多尺度特征,在PSP-Net中增加了多条自底向上的路径,首先,在自底向上的路径和跳层连接的作用下,将编码器中各层的特征逐步整合,得到具有多尺度语义信息的特征,然后,该特征被发送到解码器用于下一个卷积操作;
(2)改进的PSP-Net网络的编码网络如下算法表达:
f
其中:I表示输入图片;C
(3)将深层特征图代入浅层特征图中的融合过程如下数学表达式阐述:
f'
其中f
(4)将得到的多层级的特征图融合在一起的过程如下数学表达式阐述:
D={P
其中P是对特征图的细化操作;D表示对所有的特征图做融合操作得到最后的二维图像语义信息。
本发明的有益效果是:本发明一种基于深度学习的语义地图构建方法,依据移动机器人的视觉SLAM原理,搭建移动机器人软硬件平台,通过RGBD图像配准计算位姿,根据输入点云利用ICP算法求解位姿,使用openGL将当前帧的点云和已重建的部分进行融合,进行三维地图的构建,通过判断关键帧的方式,利用改进的PSP-Net模型对场景图像进行语义特征的提取,最后将图像语义特征信息与三维重建算法融合得到全局语义分割地图。本发明一种基于深度学习的语义地图构建方法能够应用视觉快速、准确地构建地图,使得移动机器人的自主导航更加精确。
附图说明
图1是本发明一种基于深度学习的语义地图构建方法的流程图;
图2是本发明方法中点到平面距离示意图;
图3是本发明方法中基于深度学习的改进的PSP-Net语义分割模型的示意图;
图4是本发明方法中通过RGBD传感器采集到的图像包括RGB二维图像以及深度图像。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于深度学习的语义地图构建方法,如图1所示,具体包括如下步骤:
步骤1:对安装在机器人上方的深度摄像头进行标定,通过RGBD图像配准计算位姿,根据输入点云利用ICP算法求解位姿;
步骤1中,根据输入点云利用ICP算法求解位姿的具体过程如下;
步骤1.1:对RGBD深度相机获取的两幅深度图像做3层抽样,再对于抽样后的两幅深度图像做滤波,点云配准以coarse-to-fine的方式进行迭代;
步骤1.2:在给定深度图像内参情况下,通过原始未抽样的深度图像计算点的三维点云坐标,用于点云的配准和融合,对于滤波后的两幅深度图像也计算三维点云坐标,用于计算法向量;
步骤1.3:根据步骤1.2中求得的两幅深度图像点云坐标,通过投影算法计算一幅图像在另一幅图像中的投影像素坐标;
如图2所示的点到平面距离示意图,投影法计算匹配点,由于两帧图像间位姿变换比较小,采用投影算法计算匹配点,投影算法计算匹配点比基于kd-tree的匹配算法速度快,对于一幅深度图像三维点坐标p
k(u
其中,k(u
p
T
K:相机内参数,
(u
步骤1.4:根据步骤1.3中的计算的匹配点,再计算匹配点的极小化点到平面距离计算位姿,使得目标函数误差小于设定的最小值时,或者到达设置的迭代次数停止迭代,否则进入步骤1.3;
步骤1.4中,极小化点到平面距离计算位姿算法流程如下:
(1)设置目标函数如下:
上式表达式中旋转矩阵R和平移矩阵t是待求解的位姿,R与t可通过以下公式来表示:
t=[t
其中α、β、γ分别表示沿x、y、z轴的旋转角度,在每次迭代时实际是值很小的R的变化值ΔR和t的变化值Δt,p
(2)由于旋转矩阵R是非线性的,从而目标函数也是非线性,这里将R线性化,当相邻两帧之间位姿变化较小时,有以下近似:
sin(θ)=θ,cos(θ)=1 (5)
(3)在三个方向上R的旋转角为r=(α,β,γ)对于Rp
(4)以上目标函数对6个维度位姿参数求导并且令导数为0,得到Ax+b=0,其中:A的表达式为:
b的表达式为:
未知参量x表达式为:
x=(α,β,γ,t
通过计算求解Ax+b=0就能够求出R与t,即计算出的位姿矩阵。
步骤2:在步骤1计算出位姿矩阵的R和t后,同时深度相机实时采集周围环境图像信息,使用openGL将当前帧的点云和已重建的部分进行融合,进行三维地图的建立;
步骤3:将RGBD相机获取到的当前时刻图像和前一个关键帧的特征进行匹配,判断当前时刻图像是否为关键帧;
假设不是关键帧,则查找新的图片,确定新的关键帧;
假设是关键帧,则将关键帧送入改进的PSP-Net模型中进行二维语义信息的提取,获得实时图像的二维语义信息,再进行闭环检测,得到闭环结果;
步骤3中,将关键帧送入改进的PSP-Net模型中进行二维语义信息的提取的过程具体如下:
如图3所示,基于深度学习的改进的PSP-Net语义分割模型。模型分为编码与解码两个部分,图中的f1、f2、f3、f4和f5分别是编码网络中输入图像的1/2、1/4、1/8、1/16和1/32尺寸的特征图。在改进模型中,使用1/8、1/16和1/32大小的特征图将特征与解码网络中的特定层融合,然后进行金字塔池化,最终再输出语义分割结果。
(1)通过融合不同区域的上下文信息并整合不同区域的上下文信息,构建金字塔汇集模块(Pyramid pooling module,PPM),赋予模型分析全局先验知识的能力,使得模型具有理解全局上下文信息的能力;
为了充分利用PSP-Net编码器部分包含的多尺度特征,在PSP-Net中增加了多条自底向上的路径,首先,在自底向上的路径和跳层连接的作用下,将编码器中各层的特征逐步整合,得到具有多尺度语义信息的特征,然后,该特征被发送到解码器用于下一个卷积操作;
(2)改进的PSP-Net网络的编码网络如下算法表达:
f
其中:I表示输入图片;C
(3)将深层特征图代入浅层特征图中的融合过程如下数学表达式阐述:
f'
其中f
(4)将得到的多层级的特征图融合在一起的过程如下数学表达式阐述:
D={P
其中P是对特征图的细化操作;D表示对所有的特征图做融合操作得到最后的二维图像语义信息。
步骤4:将步骤2中建立的三维地图作为输入,和步骤3中二维图像语义分割结果送入Elastic fusion模型进行三维语义分割地图的重建。
如图4所示,通过RGBD传感器采集到的图像包括RGB二维图像以及深度图像。对于RGB图像,经过改进的PSP-Net模型得到精确的二维图像分割图。然后将二维分割图像和深度图像送入Elastic fusion模型进行三维语义地图重建。
- 一种基于深度学习与激光雷达的点云语义地图构建方法
- 一种基于深度学习的语义地图构建方法