用于虚拟无线基站的编排器和互连结构映射器
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及无线通信,并且更具体地涉及启用虚拟无线基站的系统和组件。
背景技术
诸如LTE或5G网络的无线通信网络通常由无线电接入网、核心网络和与因特网的接口组成。手机和其他用户装置,通常称为“用户设备”(UE),通过无线电接入网(RAN)交换消息和数据包,所述消息和数据包构成用户的电话、电子邮件、文本和网页浏览。无线电接入网包括多个基站,每个基站通过无线电远程单元联接到一个或多个天线。基站中的每一个基站以规定的频率和编码方案生成和接收无线信号,无线信号范围内的UE可以通过所述无线信号连接到因特网并与因特网通信。这些基站在每个UE和核心网络之间提供复杂的信令,以使得与UE中的每一个UE维持适当的连接。这样做时,使用动态确定的频率、调制方案和多输入多输出(MIMO)层进行传输,以将数据通信资源最佳地分配给每个UE。
常规的无线电接入网及其组成的基站具有以下缺点。常规基站被单独设计为适应无线通信装置及其相应连接的预期峰值并发数量,并且因此被过度设计以满足固定的峰值容量水平。高峰并发使用通常在任何给定的一天或一周内仅出现一小段时间,并且使用模式通常从一个无线覆盖区域到另一个区域变化很大。例如,商业商务区中的办公大楼内的高峰并发使用可能在下午2:00发生,而住宅社区中的公寓大楼内的高峰并发使用可能在晚间8:00发生,并且体育场内的高峰并发使用只能每几个星期一次发生几个小时。在体育场的情况下,名义上的低需求与高峰需求之间的对比可能是500个和100,000个活跃连接用户之间的差异。结果是形成了这样的基站的网络,即,所述基站以导致显著高于每个单独基站以及共同的整个无线通信系统所需的成本的固定的峰值容量水平被单独进行过度设计。
因此,需要虚拟化基站,其可以扩展和收缩其容量以满足给定覆盖区域中对连接的当前需求,并且在满足类似于LTE和5G的电信标准的严格时延要求的同时做到这一点。
发明内容
本发明的一方面涉及一种经编码具有指令的非暂时性机器可读存储器,所述指令在由一个或多个处理器执行时引起所述一个或多个处理器执行包括如下的过程:确定对与无线通信接入网络的连接的需求;基于所述对连接的需求,确定组件模块的组合,所述组件模块的组合包括至少一个基带模块;确定所述至少一个基带模块与所述组件模块的组合内的其他组件模块之间的多个互连通道;实例化在所述组件模块的组合内的每个组件模块;将所述至少一个基带模块连接到至少一个外部网络组件;以及将所述至少一个基带模块连接到至少一个用户设备(UE)。
本发明的另一方面涉及一种经编码具有指令的非暂时性机器可读存储器,所述指令在由一个或多个处理器执行时引起所述一个或多个处理器执行包括如下的方法:确定对与无线通信接入网络的连接的需求,所述无线通信接入网络具有至少一个基带模块;确定对应于所述至少一个基带模块的容量是否足以满足所述需求;实例化至少一个附加基带模块;将所述至少一个附加基带模块连接到至少一个外部网络组件;以及指示所述多个基带模块中的至少一个基带模块将一个或多个UE切换到所述至少一个附加基带模块。
本发明的另一方面涉及一种经编码具有指令的非暂时性机器可读存储器,所述指令在由一个或多个处理器执行时引起所述一个或多个处理器执行包括如下的方法:确定对无线通信接入网络内的连接的需求,所述无线通信接入网络具有多个基带模块;基于所述对连接的需求,将所述多个基带模块中的一个基带模块指定为未充分利用的虚拟基带模块;指示所述未充分利用的基带模块将多个连接的UE切换到所述多个基带模块内的接收者基带模块,所述接收者基带模块对应于相邻蜂窝组;以及关闭所述未充分利用的基带模块。
本发明的另一方面涉及一种虚拟无线基站,包括:多个路由装置;多个基带处理装置;编排装置;联接在所述多个路由装置和所述多个基带处理装置之间的用于低延迟交换的交换装置;以及用于结构映射的映射装置,所述用于结构映射的映射装置联接到所述编排装置和所述用于低延迟交换的交换装置。
另一种经编码具有指令的非暂时性机器可读存储器,所述指令在由一个或多个处理器执行时引起所述一个或多个处理器执行用于减轻两个蜂窝组之间的蜂窝间干扰的过程,所述两个蜂窝组中的每一个蜂窝组具有对应的基带模块,其中每个基带模块联接到低延迟交换结构,所述过程包括:在所述两个蜂窝组的公共覆盖区域内标识与至少一个UE发生蜂窝间干扰的两个基带模块;标识对应于所述蜂窝间干扰的频带;实例化协调器模块,其中所述协调器模块联接到所述低延迟交换结构;经由所述低延迟交换结构将所述协调器模块联接到所述基带模块;以及在所述两个基带模块之间执行帧内协调。
本发明的另一方面涉及一种无线基站。所述无线基站包括:多个蜂窝组,每个蜂窝组具有对应的基带模块,所述基带模块中的每一个基带模块联接到低延迟交换结构;以及硬件计算环境,所述硬件计算环境具有被编码以执行过程的非暂时性机器可读介质指令。所述过程包括:在所述两个蜂窝组的公共覆盖区域内标识与至少一个UE发生蜂窝间干扰的两个基带模块;标识对应于所述蜂窝间干扰的频带;实例化协调器模块;将所述协调器模块联接到所述低延迟交换结构;经由所述低延迟交换结构将所述协调器模块联接到所述基带模块;以及在所述两个基带模块之间执行帧内协调。
附图说明
图1示出了根据本公开的示例性虚拟基站系统。
图2示出了根据本公开的示例性基带处理模块。
图3示出了根据本公开的用于启动和初始化虚拟基站的示例性过程。
图4示出了根据本公开的用于分配组件模块以满足对连接的当前和近期需求的示例性过程。
图5示出了根据本公开的用于虚拟化基站的操作的示例性方法。
图6示出了根据本公开的用于执行蜂窝间干扰减轻的示例性方法。
图7示出了在低连接性需求场景期间的示例性构型。
图8示出了在高连接性需求场景期间的示例性构型。
具体实施方式
公开了虚拟基站托管环境和体系结构,其使得能够将一个或多个无线基站(例如,一个或多个eNodeB)划分为虚拟化的组件,所述虚拟化的组件可以被单独且动态地创建、重新配置和关闭。
通过虚拟实现,基站组件可以动态创建、重新配置和关闭,以响应需求波动。此外,通过使用商用的现成服务器硬件,可以节省大量成本。然而,虚拟基站的部署提出了技术挑战。例如,鉴于管理诸如LTE和5G的电信标准的严格延迟要求,虚拟化组件之间的任务间通信对常规计算机硬件提出特别的要求,尤其是如果这些虚拟化组件响应于需求波动而动态创建、重新配置和关闭。
在LTE的情况下,根据本公开,可以对虚拟基站或eNodeB进行划分,以使得其S1、X2、GTP和M2M接口功能分别封装在单独的软件对象(以下称为“接口/路由器”组件)中,所述软件对象可以在几个虚拟基带处理器之间共享。这样做时,例如,独立的基于软件的S1接口可以充当多个基于软件的基带处理器与核心网络内的一个或多个MME之间的路由器。此外,虚拟基带处理器可以在其协议栈层之间进行划分,以使得可以将瓶颈协议栈功能并行化为多个组件或进程线程,以实现更高的速度。这使得能够创建具有可能容易协调的许多蜂窝的一个或多个基带处理器。这可以简化通过S1接口与MME的通信,因为可能存在更少的基带处理器,每个基带处理器具有更大的容量。如果两个干扰蜂窝在不同的虚拟基带处理器下,则可以将两个干扰蜂窝迁移到单个运行基带处理器中,以使得所有组成UE可以由单个调度程序调度,或者可以创建新的基带处理器来托管两个干扰蜂窝。
启用这些功能需要服务器硬件计算环境,所述环境具有通过高速交换结构互连的多个多处理器板。一个示例将包括多个服务器板,每个服务器板都配备有无限带宽技术PCIe适配器,所述适配器通过无限带宽技术交换机(例如36端口100Gbps交换机)在服务器之间连接以100Gbps或200Gbps的速度运行。无限带宽技术组件在足以实现高性能群集的带宽的情况下允许非常低的延迟(PCIe卡上的600nsec以下、在交换机上90nsec端口到端口)。不同的虚拟基带处理器和接口/路由器组件可以经由RDMA(远程直接内存访问)直接通过单个板内的共享存储器或通过板之间的互连通道(诸如无限带宽技术)进行通信。此外,低延迟交换结构的使用可以通过合并诸如DPDK(数据平面开发套件)的数据平面改进技术来增强,这实现数据包处理工作负荷加速。将理解的是,可对该硬件计算环境进行改变,并且在本公开的范围内。
为了正确使用该硬件平台并托管多个分区的基带处理器连同集中的S1/X2/GTP/M2M接口模块,需要如下所述的两个软件实体:编排器和模块间通道映射器(以下称为“结构映射器”)。
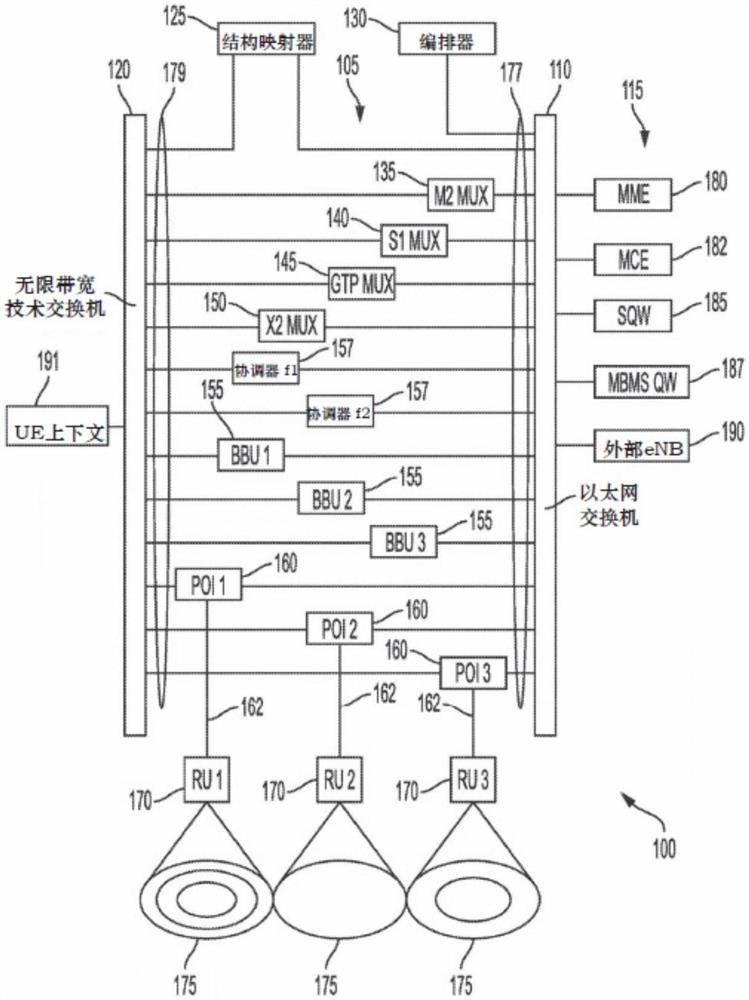
图1示出了根据本公开的示例性虚拟基站系统100。系统100包括多个组件模块105。组件模块105中的每一个经由以太网连接177联接到以太网交换机110,并联接到高带宽低延迟交换结构120。合适的高带宽低延迟交换结构120的示例可以包括如上所述的无限带宽技术交换机,但是可以使用其他交换技术(诸如Omni-Path或以太网),如果它们可以满足延迟要求的话。在所示的示例性系统100中,组件模块105包括三个基带处理器单元(BBU)模块155,和四个接口/路由器组件模块:M2Mux 135;S1Mux 140;GTPMux 145和X2Mux 150。BBU模块155中的每一个可以经由在低延迟交换结构120内建立的专用互连通道联接到四个接口/路由器组件模块中的每一个。
联接到以太网交换机110的是标准外部网络组件115。在基于LTE的示例性实施方式中,外部组件115可以包括:MME(移动性管理实体)180;MCE(多单元/多播协调实体)182;SGW(服务网关)185;MBMS GW(多媒体广播多播服务网关);以及一个或多个外部eNodeB190。这些外部网络组件中的每一个根据其相应的接口协议(例如,MME 180和S1Mux 140之间的SCTP、SGW 185和GTPMux 145之间以及MBMS GW 187和GTPMux 145之间的GTP、MCE 182和M2Mux 135之间的M2和一个或多个外部eNodeB 190和X2Mux 150之间的X2)经由以太网交换机110联接到其相应的接口/路由器组件模块。
三个所示的BBU 155中的每一个可以经由低延迟交换结构120联接到对应的POI/DAS(多系统接入平台/分布式天线系统)组件模块160。此外,每个POI/DAS组件模块160可以经由CPRI(通用公共无线接口)连接162联接到无线电远程单元170,并且远程单元170可以经由RF分布连接联接到一个或多个天线(未示出)。每个CPRI连接162可以用专用PCIe CPRI卡实现,所述PCIe CPRI卡可以安装在托管系统100的服务器板中的一个或多个上。尽管系统100被示为具有单独的专用CPRI连接162,但应理解的是,这些可以用CPRI交换机(未示出)实现,所述CPRI交换机可以在POI/DAS组件模块160和远程单元170之间路由CPRI流量。在进一步的变型中,CPRI连接162可以使用诸如无限带宽技术交换机的低延迟交换结构120来实现,其中远程单元170可以直接联接到低延迟交换结构120。在另一变型中,BBU模块155中的一个或多个可以经由CPRI连接162直接联接到一个或多个远程单元170,其中不存在中间的POI/DAS模块160。另外,鉴于延迟要求,CPRI连接162中的一个或多个可以替代地用以太网连接来实现。将理解的是,此类变型是可能的,并且在本公开的范围内。
在另一个变型中,一个或多个BBU模块155可以是专用协议栈,诸如用于专门服务于带宽受限的NB-IoT UE,而不是具有标准LTE协议栈实施方式。在某些情况下,可以为该专用BBU模块155分配其自己的频谱,并独立于其他BBU模块155进行操作。在这种情况下,专用BBU模块155可以联接到专用远程单元170。在变型中,NB-IoT BBU模块155可以以单独的标准LTE BBU模块155的频带内的保护带频率操作。在这种情况下,专用BBU模块155可以联接到与标准LTE BBU模块155共享的远程单元170,在这种情况下,它们对应的RF信号合并在远程单元170内。在其他情况下,可能需要在给定频带中进行协调,其中专用BBU模块155和标准LTE BBU模块155可以在给定LTE帧内共享一组资源块,其中协调由协调器模块157处理。这将在下面进一步描述。
每个无线电远程单元170及其对应的天线(未示出)可以覆盖给定的蜂窝组175。如本文所用,蜂窝组175可以被认为是标度系统100中的粒度的基线单元。蜂窝组175可以至少被定义为覆盖由该给定天线/远程组合(包括在给定时间存在的所有MIMO层)处理的所有频带的单个天线范围。在多个频带的情况下,该蜂窝组内的任何给定UE可以以可用频带的任何组合进行发送和接收,并且对应的BBU模块155使用载波聚合方法独立地调度给定蜂窝组175内的所有UE。最多,蜂窝组175可以包括多个天线增益模式、每个增益模式内的多个频带、以及在给定的时间点可用的所有MIMO层。在这种情况下,对应的BBU模块155可以与多个POI/DAS模块160和多个对应的远程单元170进行通信,以独立地调度范围内的所有UE。在这些情况范围的每一个中,单个BBU模块155处理单个蜂窝组175,并且蜂窝组的大小和复杂性可以变化。
可存在对远程单元170的变型,并且在本公开的范围内。例如,远程单元170可以是用于DAS系统的常规远程无线电头、有源天线系统或高级远程单元诸如Cell Hub单元(由JMA Wireless提供)。尽管示例性系统100被示出为具有三个POI/DAS(接口点/分布式天线系统)160,但是将容易理解的是,可存在变化。例如,它们中的任一个可以替代地是宏蜂窝、小蜂窝等,并且这些的任何组合是可能的并且在本公开的范围内。此外,尽管示出了三个BBU 155和POI/DAS 165,但是将理解的是(如下文进一步公开),更多或更少是可能的并且在本公开的范围内。
系统100还具有下面所述的编排器模块130、结构映射器模块125以及一个或多个协调器模块157。
四个接口/路由器模块中的每一个包含常规上由单个eNodeB执行的功能。根据本公开,这些接口功能已经从BBU功能中划分,并且封装在可以为多于一个的BBU 155(根据系统100的示例性实施例包括三个BBU 155,但是更多或更少的BBU 155是可能的,并且在本公开的范围内)服务的单独组件中。因此,系统100可以被认为具有三个eNodeB,其中给定的eNodeB包括BBU 155,并且其相应的接口功能由接口/路由器组件模块执行。
所有组件模块105可以包括机器可读指令,所述指令在一个或多个非暂时性存储装置内编码,并且在联接到以太网连接110和低延迟交换结构120的一个或多个处理器上执行。如本文所用,术语“非暂时性存储器”可以是指任何有形的存储介质(与电磁或光信号相反),并且是指介质本身,而不是对数据存储的限制(例如,RAM对ROM)。例如,非暂时性介质可以是指经编码而具有指令的嵌入式存储器,其中在重启之后可能必须用适当的机器可读指令重新加载存储器。根据上述硬件计算环境,组件模块105中的每一个可以托管在一个或多个多处理器服务器板上。可以改变组件模块105在硬件计算环境上的部署方式。例如,在一种变型中,相同的服务器板上的组件模块105可以经由共享存储器进行通信,并且不同服务器板上的组件模块可以通过经由低延迟交换结构120的互连通道进行通信。在另一变型中,基站组件模块105的整个套件可以使用共享服务器板的基站组件模块之间的RDMA、并且使用在不同服务器板上的基站组件模块之间的低延迟交换矩阵120内的互连通道上的RDMA而部署在物理机顶部的虚拟机或容器内。在另一变型中,组件模块105可以部署在物理机顶部的虚拟机或容器中,其中所有组件模块105经由低延迟交换结构120经由虚拟寻址进行通信,而不管任何给定的一对组件模块105的基础物理实例是否共享物理节点(服务器板)。示例性软件容器可以包括Docker容器或rkt pod,或实现应用容器化的任何类似软件包。此外,容器、VM和进程的混合可以在裸金属上运行。然而,容器化的优点包括以下事实:由于它们封装最少的OS组件,因此它们可以非常快速地加快自旋,并且在尺寸方面非常轻便。然而,一个或多个VM的优势是它们允许持久的内存使用和状态驱动的操作。将理解的是,此类示例性变型是可能的,并且在本公开的范围内。
联接到以太网连接110的是编排器130。编排器130可以是软件模块,其包括编码在诸如非暂时性存储器的存储器中的机器可读指令,其中当由一个或多个处理器执行时,不以特定顺序执行以下功能。首先,编排器130确定在启动时、以及在系统100运行期间对系统100的当前和近期流量需求。第二,编排器130通过测量每个BBU模块155的性能和/或从每个BBU模块155接收测量报告来监视系统100的性能,并响应于所监视的性能以及需求的变化来调整系统100的容量。编排器130可以通过执行包括以下功能的特定功能来调整系统100的容量:创建新的BBU 155;关闭不必要的BBU 155;以及合并或划分蜂窝组,从而调整给定的BBU模块155的容量。第三,编排器130可以通过协调蜂窝175到对应的BBU 155的分配来改善系统100的性能。在两个蜂窝组的范围内存在多个UE的情况下,并且为了最小化具有两个BBU模块155的复杂性,所述两个BBU模块155必须协调两个重叠天线范围内的多个UE的调度,编排器130可以将两个现有的蜂窝组175合并到单个蜂窝组175中,以使得单个BBU模块130内的单个调度器可以处理更大覆盖区域的调度。可替代地,编排器130可以实例化一个或多个协调器模块157,所述一个或多个协调器模块157可以协助以给定的服务频率(下面进一步描述)在两个干扰BBU 155之间进行调度的协调。可替代地,编排器130可以执行指令以创建新的BBU 155,并且将两个共同干扰蜂窝175迁移到新的BBU 155。编排器130可以经由以太网连接110联接到每个组件,以发布命令和接收状态信息等。
编排器130的另一功能是命令建立结构映射器125,修改和关闭低延迟交换结构120内的互连通道,以使得组件模块105可以以最小的延迟和足够的带宽彼此通信。
编排器130可以使用容器编排引擎(COE)(诸如Kubernetes)或为管理程序/容器运行时提供附加功能的另一个软件套件来实现。编排器130可以将某些功能(例如,组件模块105的健康检查、按需部署等)委托给COE。
如上所述,四个接口/路由器组件M2Mux 135、S1Mux 140、GTPMux 145和X2Mux 150中的每一个在每个BBU模块155和其对应的外部网络组件115之间执行标准通信。S1Mux 140充当BBU 155中的每一个和MME 180之间的接口和路由器。S1Mux 140可以具有两个端口:使用SCTP连接到以太网交换机110的一个端口,和连接到低延迟交换结构120的一个端口。从S1Mux 140到低延迟交换结构120的连接可以是以无限带宽技术分组的形式打包的S1-AP消息的形式。对于来自MME 180的DL(下行链路)通信,S1Mux 140执行指令以拦截来自MME 180的SCTP格式的消息,从消息中检索eNodeB标识符,从消息中剥离与SCTP相关的信息以将其转换为S1-AP消息,并将消息路由到无限带宽技术交换机110内的互连通道,所述互连通道对应于预期BBU 155的eNodeB标识符。这样做时,S1Mux 140可以执行指令以执行例如经由低延迟交换结构120内的专用互连通道分配给目标组件模块的RDMA存储器写入存储器。在从给定的BBU 155到MME 180的UL(上行链路)通信的情况下,S1Mux140经由低延迟交换结构120内的BBU的专用互连通道从BBU 155接收消息,将S1-AP消息转换为SCTP格式,并经由以太网连接110将消息发送到MME180。其他接口/路由器组件的结构和功能可能基本上相似,主要区别在于转换特定接口协议数据结构,以在基于以太网的协议与用于通过低延迟交换结构120进行中继的格式之间转换消息的细节。
GTPMux 145主要充当SGW 185与BBU模块155中的每一个之间的路由器。GTPMux145可以具有以下端口:用于经由以太网交换机110与SGW 185通信的以太网端口;以及一个或多个第二端口,用于通过低延迟交换结构120与BBU模块155中的每一个通信的一个端口。如所描述的,GTPMux 145的端口是双向的。与S1Mux 140一样,GTPMux 145可以被配置成使得SGW 185不会意识到其正在直接与中间接口/路由器组件模块通信,而不是像与常规eNodeB一样直接与每个BBU模块155通信。M2Mux 135以类似于GTPMux 145的方式充当路由器,但是处理从MBMS GW 184到BBU模块155中的每一个的MBMS(多媒体广播多播服务)流量。
图2示出了BBU模块155的示例性实施方式。如本文所用,术语基带处理器或BBU可以是指软件实现的垂直LTE或5G协议栈,其接口功能被接口/路由器模块中的一个划分和处理。每个BBU模块155可以是具有机器可读指令的软件模块,其被编码在系统100的硬件计算环境内的一个或多个非暂时性存储器组件中,以使得当由系统100的硬件计算环境内的一个或多个处理器执行时,每个BBU 155执行协议栈和调度功能。如图2所示,示例性BBU 155可以包括:PDCP(分组数据汇聚协议)组件210;RLC(无线电链路控制)组件220;MAC(媒体访问控制)组件230;以及PHY(物理层)组件250。每个BBU模块155如上所述经由其对应的接口/路由器组件与外部网络组件115中的每一个通信。每个BBU模块155还联接到CPRI连接160,用于在BBU模块155及其对应的POI/DAS 165之间双向发送I/Q(同相/正交)信号数据。这是其中每个BBU模块115可以经由CPRI连接直接联接到POI/DAS模块160的变型。
如图2所示,对于每个BBU模块155,其PDCP模块210可以联接到低延迟交换结构120,以与GTPMux 145中继上行链路/下行链路数据流量。PDCP模块210和RLC模块220可以通过上行链路/下行链路连接215进行链接,所述上行链路/下行链路连接215可以分别经由共享存储器或经由通过低延迟交换结构120的互连通道来实现。类似的实现方式可以用于RLC层220和MAC层230之间的上行链路/下行链路连接225。上行链路/下行链路连接215和225可以是基于承载的,这意味着一旦UE已经连接到BBU模块155,就通过这些连接来发送数据,并且上行链路/下行链路连接215和225上的流量范围是活跃承载的数量的函数。
调度器模块230和MAC模块240(可以是调度器230的子组件)可以执行BBU模块155的调度器功能和控制平面信令的大部分。MAC模块240可以合并附加功能,以经由一个或多个协调器157与其他BBU模块155协调调度,以从编排器130和结构映射器125接收配置信息,并且向编排器130提供测量报告和状态信息。为了适应这些功能,MAC模块240可以具有到以太网交换机110的以太网连接232,其可以通过所述以太网连接232与这些其他组件模块通信。MAC模块240也可以联接到低延迟交换结构120,用于向/从S1Mux 140传送S1-AP信令消息。
PHY模块250执行在LTE或5G实施方式中期望的PHY层功能。PHY模块250可以用作单独的组件或线程,每个载波一个线程,以及每个载波每个MIMO层一个线程,以及用于上行链路的一个线程和用于下行链路的一个线程。PHY模块250中的每一个可以经由PHY链路235与MAC模块240通信。PHY链路235可以具有用于每个PHY模块线程250的专用通信链路。这些链路可以通过共享存储器,或者可以通过经由低延迟交换结构120的专用互连通道。每个PHY模块线程250还可以具有通过低延迟交换结构120到指定POI/DAS模块160的专用互连通道。可替代地,每个PHY模块线程250可以通过高速链路(例如,PCIe)联接到CPRI卡,所述CPRI卡进而通过CPRI连接162联接到远程单元170。
返回到图1,结构映射器模块125可以是软件模块,其包括编码在诸如非暂时性存储器的存储器中的机器可读指令,其中当由一个或多个处理器执行时,执行以下功能。其为基站组件模块105之间的每个互连通道建立(例如)低延迟交换结构120内的互连通道。例如,结构映射器125可以在每个BBU 155与每个相应的接口/路由器组件之间建立多个互连通道(例如,用于每个LTE承载的一个互连通道),以使得每个互连通道可以在两个组件之间提供RDMA访问,使得对于每个BBU,数据可以用足够的带宽和足够低的延迟来交换以在给定电信标准(例如,LTE)要求内提供基站功能。取决于互连的性质(什么连接到什么),延迟和带宽要求可能有所不同。为了适应这一点,结构映射器125可以包括对应于每个互连通道组合(例如,BBU/S1Mux、BBU/GTPMux、经由X2Mux的BBU1/BBU2等)的延迟和带宽要求的配置数据表,并且适当地分配互连通道(例如,分配给RDMA的内存范围等)。在每个BBU进一步划分为协议子组件的情况下,结构映射器125可以在它们之间(例如,在给定的BBU 155MAC模块240和其对应的PHY模块250之间)建立互连通道。
取决于编排器130如何为每个基站组件模块提供资源,结构映射器125确定通过低延迟交换结构120的路径,以在组件模块之间创建互连通道。一旦结构映射器125已经确定了互连通道,其就将相关的互连通道信息(例如,存储器地址、端口号等)传送到其他模块组件中的每一个。
取决于两个组件模块105之间的预期带宽要求,结构映射器125可以为低延迟交换结构120内的其专用互连通道建立在两个组件模块之间共享的内存阵列。
结构映射器125与编排器130一起使用,以使得如果给定的BBU模块155操作失灵,编排器130可以执行指令以实例化替换BBU模块155,并为结构映射器125提供相关的地址信息,使得结构映射器125可以执行指令以映射低延迟交换结构120内的一组新的互连通道,并为新的替换BBU 155提供与该组新的互连通道有关的信息。这样做时,作为其功能的一部分,结构映射器125可以充当无限带宽技术子网管理器(或与无限带宽技术子网管理器结合)。
结构映射器125还可以提供冗余以增强系统100的稳健性。例如,编排器130可以确定流量的实质性增加可能有待解决(例如,在用于覆盖体育场的特许权区域的一组蜂窝175的足球场的中场休息)。考虑到这一点,编排器130可以执行指令以通知结构映射器125对额外资源的需求。作为响应,结构映射器125可以执行指令以抢先映射用于附加的BBU模块155的互连通道,并在需要时将它们维持在互连通道池中以便快速部署。
低延迟交换结构120可以包括一个或多个硬件组件,所述组件互连单个服务器板内的处理器以及分布在多个服务器板上的互连处理器。在低延迟交换结构120是无限带宽技术交换机的示例中,根据无限带宽技术规范,实际的硬件连接可以包括光纤、电路板迹线、双绞线有线连接等。实现特定无限带宽技术功能的相关软件可以存储在低延迟交换结构120硬件组件上并在其中运行。
尽管本公开描述了使用无限带宽技术组件的互连通道和硬件计算环境,但是应理解,其他互连结构技术也是可能的并且在本公开的范围内,前提是它们为基站组件模块之间的任务间通信启用足够高的带宽和足够低的延迟,以使得它们符合LTE和/或5G规范。
启动和配置
图3示出了根据本公开的用于启动和配置虚拟基站100的示例性过程。
在步骤305中,编排器130执行指令以确定对其中部署虚拟基站100的无线网络的当前需求、近期需求和需求波动。这样做时,编排器130可以从配置文件或其他信息源检索信息。在示例性实施例中,编排器130可以经由类似于标题为SYSTEM AND METHOD FORADAPTIVELY TRACKING AND ALLOCATING CAPACITY IN A BROADLY-DISPERSED WIRELESSNETWORK的美国专利申请序列号15/918,799中所公开的ACCS(自适应连接控制系统)来获得当前需求、近期需求和需求波动,所述专利申请通过引用并入,如同本文完全公开一样。无论怎样获得,信息都可能包括以下内容:(a)对连接的当前需求的估计,其可以包括活跃连接装置(例如,处于LTE RRC连接状态)的数量和系统100将部署在其中的附近空闲装置(例如,处于RRC空闲状态)的数量、这些装置的装置种类(例如,Cat 0-8、Cat M等)以及与连接的UE相关联的承载的预期QCI(服务质量等级指示符);(b)与对连接的所估计的近期需求有关的趋势信息,其可以包括最近趋势数据的推断或基于历史数据的估计;以及(c)对连接的需求的波动,其可以包括在有限的时间范围内预期的需求偏差。高波动的示例可能包括地铁站附近的城市中心,其中在高峰时段,当每辆地铁列车让乘客下车时,周期性的行人涌入和离开给定蜂窝组175的覆盖范围。波动的另一个示例可能包括诸如体育场馆的场所,在所述场所中,如果正在进行的比赛暂停,大量观众可能突然从一个区域移动到另一个区域。在这些示例中的每一个中,除了对连接的任何稳态需求之外,不同装置种类的装置的需求可能存在一段时间的激增和下降。编排器130可以获得该数据并将其用于适当地配置将要部署的系统100。
在确定当前需求和近期需求时,编排器130可以(独立地或通过前述的ACCS)执行指令,以在对应于系统100的位置处获得或检索与对连接的需求有关的历史信息。这可以包括一天中的一个小时、一周中的一天、一个月、给定事件的发生(例如,体育赛事、假日、音乐会、极端天气的预测等)。考虑到该信息,编排器130可以实施前瞻算法来确定当前需求和近期需求。将理解的是,步骤305的变型是可能的,并且在本公开的范围内。
在步骤310中,编排器130执行指令以确定组件模块105的适当分配,以正确满足在步骤305中确定的需求和波动。
图4示出了编排器130可以通过其执行步骤310的示例性过程。
在步骤405中,编排器130执行指令以按照装置种类及其预期能力将在步骤305中确定的需求分解为多个预期UE。
在步骤410中,编排器130执行指令以按照系统100的覆盖区域内的物理位置和面积确定需求集中度。这样做时,编排器130可以从需求数据(在步骤305中获得)检索与处于连接状态和空闲状态两者的UE相对应的蜂窝标识符信息,并且与对应于蜂窝标识符的物理位置信息相关。其结果是由系统100所覆盖的区域和对应于预期需求的UE的预期位置和集中度以及对应于这些集中度和分布的可能预期时间的地图状表示。
在步骤415中,编排器130执行指令以分配蜂窝组175以按照物理位置和面积适应预期需求集中度。这可能取决于远程单元170及其对应天线的特定配置。例如,某些远程单元170和天线可以支持不同的频带,从而允许更多或更少的载波聚合机会。此外,编排器130可以访问对应于系统100和每个蜂窝组175的物理RF环境的历史数据。例如,给定的蜂窝组175可以处于已被证明比其他蜂窝组175的位置更适合更多MIMO机会的物理位置。例如,远程单元170的天线方向图可以位于具有很多反射表面的建筑物之中,从而提供许多MIMO机会。这些MIMO机会可能是频带的函数。例如,给定远程单元170的天线方向图的给定RF环境可以具有许多反射表面,但是具有许多树木和其他树叶,这可以在较低的频带中提供丰富的反射环境(因此,具有更大的MIMO机会),但在毫米波频带中提供更大的衰减。
在这种情况下,取决于预期需求和已知的RF环境,编排器130如果支持更多频带或具有更有利的天线增益模式,则可以在另一个相邻或重叠的远程单元170上选择一个远程单元170。步骤415的结果是要激活的一组选定的远程单元170,以及用于每个对应的POI/DAS模块160和BBU模块155的预期计算资源。例如,对于支持许多频带(更大的载波聚合机会)并且预期支持许多MIMO层(基于已知的RF环境)的远程单元170,编排器130可以预先确定对每个BBU模块155的各个计算资源要求:PHY模块250线程的数量、调度器230的复杂性等。
返回到图3,在步骤315中,编排器130执行指令以分配用于每个BBU模块155的共享存储器,所述共享存储器用于存储UE上下文数据191、覆盖所有必要配置的公共数据集和给定UE的装置特定信息。由编排器130创建的UE上下文数据191阵列应位于共享存储器中,方便地访问对应的BBU模块155。UE上下文数据191模板可以是所有UE共有的,其可以包括UE信息,诸如最大可允许的比特率和频带能力。因此,假设对连接的预期需求由编排器130在步骤305中确定,UE上下文数据191的大小可以是单个UE上下文数据模板的大小的整数倍。每个UE上下文数据模板将由连接到BBU模块155的UE填入,并且每个填入的UE上下文数据模板将需要由以下BBU模块子组件访问:PDCP(分组数据汇聚协议)组件210、RLC(无线电链路控制)组件220、MAC(媒体访问控制)组件230、以及PHY(物理层)组件250。这些子组件中的每一个可能只需要访问已填入的UE上下文数据模板内的特定信息。因此,编排器130可以实例化并配置每个BBU模块155,以使得其组成子组件被配置为仅访问其所需要的UE上下文数据模板内的那些存储区域。关于这一点,编排器130可以向其他BBU模块155和/或一个或多个任选协调器模块157提供对给定BBU模块的UE上下文数据191的访问。向其他BBU模块提供访问实现协调,诸如协作多点(COMP)和蜂窝间干扰协调(ICIC)。
在步骤320中,结构映射器125执行指令以确定低延迟交换结构120内的一组适当的互连通道,以满足集体组的组件模块105的需求,并且然后建立互连通道。每个BBU模块155将需要与以下接口/路由器模块中的每一个的多个互连通道(例如,在某些情况下,每个承载一个互连通道):用于与MME 180通信的S1Mux 140;用于与MCE 182通信的M2Mux 135;用于与MBMS GW 187和SGW 185通信的GTPMux 145;以及用于与一个或多个外部eNodeB 190通信的X2Mux 150。在X2接口的情况下,还可能知道多少个X2连接将与每个BBU155建立。可以假定BBU模块155中的每一个将具有与其对应的BBU模块155中的每一个的X2连接,这将为X2Mux 150提供基准数量的X2互连通道。然而,不太可能知道将需要到一个或多个外部eNodeB 190的多少个互连通道。因此,结构映射器125可以在流量需求改变时在操作上动态地创建和关闭给定的BBU模块155和外部eNodeB 190之间的互连通道。此外,取决于每个BBU155如何联接到其相应的CPRI连接160,每个BBU可以具有经由低延迟交换结构120到CPRI板的互连通道。
进一步到步骤320,结构映射器125可以将专用存储器的阵列分配给每个互连通道,一个互连通道用于两个组件模块之间的每个通信方向。这些可以是静态共享数据结构,其可以实现为给定处理器板内的共享存储器,或者可以实现为用于无限带宽技术链路上的RDMA通信的数据结构。考虑到固定阵列的静态性质,结构映射器125可以分配它们的大小,使得它们具有适当大小,所述适当大小不能被超过,但是不那么大以至于消除了为当编排器在可能出现需要时实例化附加组件模块105时可能需要的附加互连通道动态分配附加阵列的灵活性。
在使用无限带宽技术的示例中,结构映射器125可以通过定义多个QP(队列对)来创建一组互连通道,每个QP定义互连通道的一对端点(例如BBU1/S1Mux;BBU2/S1Mux;BBU1/GTPMux;等),并确定对应的发送和接收队列(例如,面向连接与数据报;可靠与不可靠;等)的服务类型、服务级别、链路比特率(例如,xl、x4和x12(即注入速率控制))和结构分区的分配。这可以取决于与给定的承载相对应的装置种类和QCI,结构映射器125正在为其创建和分配QP。此外,取决于每个BBU 155如何联接到其相应的CPRI连接160的性质,结构映射器125可以为每个BBU和集成CPRI板的专用端口定义多个QP。这将与系统100的配置保持一致。
结构映射器125通过执行指令以利用低延迟交换结构120(在该示例中为无限带宽技术交换机)调用适当的无限带宽技术定义的动词来建立适当的QP。更具体地,结构映射器125利用每个无限带宽技术主机通道适配器调用适当的动词,并将每个组件模块105建立为无限带宽技术消费者,每个消费者具有多个QP。
一旦结构映射器125确定了适当的一组互连通道,它则执行指令以在低延迟交换结构120内创建那些互连通道,并将互连通道分配给相应对的组件模块105。
在步骤325中,编排器130执行指令以实例化系统100满足估计需求所需的组件模块105。在这样做时,编排器130可以基于从以上关于图4描述的步骤310得到的配置数据来实例化适当的接口/路由器组件(M2Mux、S1Mux、GTPMux和X2Mux)以及一个或多个BBU模块155。
在分配和实例化BBU模块155时要考虑的因素涉及每个BBU模块155实例化的复杂性与系统100的硬件计算环境的多线程机会之间的平衡。例如,可能有机会用单个大蜂窝组175或两个或更多个小蜂窝组175覆盖系统100内的某个区域。在前一种情况下,更大且更复杂的BBU模块155所需的计算资源可能太大,以致系统100的硬件计算环境的操作系统可能无法有效地协调其线程连同其他组件模块105的其他竞争线程的处理。换句话说,存在过多的单个BBU模块155线程可能降低多处理器板(具有多核处理器)的计算效率。在这种情况下,它可以提供更高效的计算,以具有更小、更多且更易管理(从OS多任务处理角度而言)的BBU模块155。
进一步到步骤325,每个实例化的BBU 155可以具有专用的CPRI连接162,其中每个实例化被配置为与一个或多个端口地址联接到作为系统100的计算硬件环境的一部分的硬件CPRI板。可替代地,每个BBU 155可以被实例化,以使得其具有经由低延迟交换结构120与集成CPRI板的一个或多个专用互连通道。
在系统100的变型中,编排器130可以以用于BBU的协议栈中的每一层的单独组件模块的形式实例化每个BBU 155。因此,代替实例化BBU 155,编排器可以实例化一个PDCP模块210、一个RLC模块220、一个调度器230和MAC模块240以及具有多个线程或具有多于一个PHY模块250的一个PHY模块250。在该变型中,结构映射器125可以确定、创建和分配互连通道以用于在它们之间进行通信,因为它们将集成为BBU进行通信。在这种情况下,BBU 155实际上将是在协议栈的每层间具有无限带宽技术互连通道的BBU。
进一步到步骤325,编排器130可以实例化不同的组件模块105,以使得它们共享硬件节点(在相同的服务器板上)或在不同的服务器板上,这取决于给定组件模块105的计算能力要求以及对两个或更多个组件模块105之间的通信的延迟和带宽要求的严格性。例如,编排器130可以执行指令以实例化PCIe CPRI卡位于其上的相同服务器板上的POI/DAS模块160,以最小化POI/DAS模块160与远程单元170之间的延迟。
进一步到步骤325,每个实例化的组件模块105可以向结构映射器125注册自身,以使得结构映射器125可以为每个组件模块105供应用于其互连通道的指定地址和配置信息。每个组件模块105可以通过其相应的以太网连接177和以太网交换机110与结构映射器通信。以这种方式,每个组件模块105可以经由以太网交换机110与其他组件模块105建立连接。例如,每个BBU模块155可以执行指令以向接口/路由器组件模块注册自身:S1Mux 140、GTPMux 145、X2Mux 150和M2Mux 135。然后,接口/路由器组件模块中的每一个可以分别配置自身,以使得对应于每个BBU模块155的相关蜂窝ID和其他配置信息被存储并与用于对应于该BBU模块155的互连通道的适当端口地址和配置信息(由结构映射器125提供)相关联。
在步骤325结束时,所有组件模块105连同为UE上下文数据191保留的存储空间一起被实例化,并且跨低延迟交换结构120的所有所需的互连通道被建立。
在步骤330中,POI/DAS 160模块中的每一个执行指令以与其指定的远程单元170建立连接。在其中每个POI/DAS模块160经由中间CPRI驱动器联接到其相应的远程单元170的示例性实施例中,每个POI/DAS模块160可以执行指令以建立和激活用于与远程单元170进行双向通信的数据端口。这可以通过每个POI/DAS-远程单元对之间的单个独立的CPRI连接来完成。可替代地,系统100可以包括CPRI交换机(未示出),所述CPRI交换机可以用作每个POI/DAS模块160与每个远程单元170之间的路由器。根据另一个示例性实施例,每个POI/DAS模块160与其指定的远程单元170之间的通信可以通过低延迟交换结构120(诸如无限带宽技术交换机),每个POI/DAS模块160和对应的远程单元170可以跨专用互连通道双向发送I/Q(同相/正交)数据,而不是可以包括从低延迟交换结构120到远程单元170的光纤连接。这可以使用CPRI标准或基于包的以太网协议来完成。在一个或多个BBU模块155直接联接到一个或多个远程单元170的变型中,在步骤330中,如上所述,这些BBU模块155中的每一个可以与其指定的远程单元170建立连接。
在步骤335中,每个BBU模块155建立其与外部网络组件115和更大核心网络的相应的连接。例如,每个BBU模块155可以执行LTE特定的功能以与一个或多个MME 180建立S1连接,以经由S1Mux 140经由在低延迟交换结构120内建立的互连通道与MME 180建立控制平面通信。取决于S1Mux 140如何配置,可能是每个BBU模块155不知道S1Mux 140的存在,所述S1Mux 140透明地充当其与MME 180之间的中介结构。一旦在每个BBU模块155和MME 180之间建立了S1控制平面通信,MME 180和给定的BBU模块155就可以协作继续经由GTPMux 145和M2Mux 135将每个BBU模块155连接到外部网络组件115的过程。
进一步到步骤335,X2Mux模块150可以执行指令以在BBU模块150中的每一个间建立X2连接。当UE连接到每个BBU模块155并标识系统100的其他BBU模块155中的一个或多个以进行潜在切换时,这可以在系统100的操作期间动态发生。可替代地,可以在启动时建立X2接口,其中当其连接到核心网络中的操作支持系统(OSS)(未示出)并从OSS接收配置数据时,每个BBU模块155可以知道其他BBU模块155并获得其他BBU模块155的IP地址。将理解的是,此类变型是可能的,并且在本公开的范围内。
进一步到步骤335,每个BBU模块155可以执行指令以与一个或多个外部eNodeB190建立X2连接。这可以在启动时自动执行,其中编排器130向每个BBU 155发出命令来执行指令以建立自动邻居关系(如以上关于其他BBU模块155所述)。可替代地,它可以稍后在系统100的操作期间发生,其中每个BBU模块155可以被连接的UE提示与外部eNodeB 190建立X2接口,其中连接的UE指示来自外部eNodeB 190的强信号。这可以根据3GPP TS 36.300来完成。
在步骤340中,每个BBU模块155在其对应的一个或多个蜂窝组175的覆盖范围内与UE建立连接。利用经由S1Mux 140在每个BBU 155和MME 180之间建立的S1接口,每个BBU模块155执行指令以生成其将其格式化为广播信号的MIB(主信息块)和SIB(系统信息块)信息。然后,每个BBU 155经由低延迟交换结构120将对应的I/Q数据发送到其对应的POI/DAS模块160,所述POI/DAS模块160进而将I/Q数据发送到适当的远程单元170,所述远程单元170进而向其蜂窝组175范围内的UE广播MIB和SIB信息。
进一步到步骤340,每个范围内的UE可以接收由给定BBU模块155广播的MIB和SIB信息,并且进而向BBU模块155发出RRC连接请求,所述BBU模块155可以进而发出RRC连接建立消息等,从而导致与每个BBU模块155处于连接状态的明显多个UE。当每个UE与外部网络组件115连接并经由外部网络组件115建立服务时,UE之间的所有对应通信(经由其BBU模块155)通过适当的接口/路由器组件发生。
例如,给定的BBU模块155和SGW 185之间的通信通过GTPMux 145发生。在低延迟交换结构120是无限带宽技术交换机的示例中,可以通过可靠的RDMA QP来中继用于给定承载的数据,其中BBU模块155和GTPMux 145可以各自通过无限带宽技术通道适配器从由结构映射器125分配的另一个中的相应的存储扇区中写入(或读取)数据。其与常规LTE通信之间的显著区别在于,这里存在充当用于多个BBU模块155的路由器的单个GTP接口(GTPMux 145)。
当每个UE将其自身连接到给定的BBU模块155时,BBU模块155内的调度器模块230可以检索从UE获取的UE上下文数据191,并且用所检索的数据填入UE上下文数据模板。结果是,UE上下文数据共享存储对象将成为填入的UE上下文数据模板的阵列,每个连接的UE一个UE上下文数据模板,其中BBU模块子组件PDCP(分组数据汇聚协议)组件210、RLC(无线电链路控制)组件220、MAC(媒体访问控制)组件230、以及PHY(物理层)组件250中的每一个将访问UE上下文数据模板内的它们各自所需的数据。可以通过低延迟交换结构120内的专用互连通道进行访问,尽管考虑到对这种类型的数据访问的延迟要求不是那么严格,这可能不是必需的。
操作
图5示出了系统100通过其进行操作的示例性过程500,其中其执行虚拟基站的功能,同时动态地预期和响应于对连接的需求的变化。
在步骤505中,编排器130执行指令以确定系统100的对连接的当前需求和近期需求。步骤505可以与示例性过程300的步骤305基本上相似。另外,考虑到系统100已经在步骤505的任何给定迭代上运行,编排器130自启动以来(自启动过程300的执行以来)可能已经积累了关于系统100的连接需求以及响应能力和性能的历史数据。编排器130还可以定期监视每个BBU模块155的性能。考虑到该历史和性能数据,编排器130可以实施前瞻算法以确定近期需求和波动,并将其与系统100的当前容量进行比较。
在步骤510中,编排器130可以如下执行指令以监视系统100(和每个BBU模块155)的性能。每个BBU模块155提供对应于系统100内的每个蜂窝的PM(性能测量)。PM包括低水平计数器信息:例如,UE连接尝试和成功的次数、尝试和成功的初始上下文建立请求和响应的次数。每个BBU模块155可以执行指令以将这些PM提供给编排器130。
编排器130可以使用报告的PM数据来标识正变得过载的任何BBU模块155,以及在PM中正显示一致模式以指示其具有过多容量并可能关闭的任何BBU模块155。在后一种情况下,并且存在过剩容量的实例,过程500前进到分支515,其中编排器可以决定关闭未充分利用的BBU模块155以及可能的其对应的POI/DAS模块160和远程单元170,它们共同组成蜂窝组175。
在步骤520中,编排器130执行指令以通过确定哪个基带模块155和对应的蜂窝组175未被充分利用来确定哪个蜂窝组175被关闭。这可以包括确定当前由未被充分利用的蜂窝组175服务的UE是否足够接近另一个蜂窝组175的范围内,以实现切换而不会丢失覆盖范围。如果这是这种情况,则过程500行进到步骤525。
在步骤525中,要终止的蜂窝组175的BBU模块115执行指令以进行LTE内切换到其余蜂窝组175。它可以使用X2切换过程来做到这一点。在这种情况下,源BBU模块155经由X2Mux 150将适当的30条消息发送到目的地BBU模块155。一旦切换在源(将被关闭)BBU模块155和目的地(其余)BBU模块155之间协调,目的地BBU模块155就执行指令以通过经由S1Mux140在其与MME 180之间并且经由GTPMux 145在其与SGW 185之间交换适当的信令来完成切换。
在步骤530中,编排器130可以执行指令以提高已经接受了从将被关闭的未充分利用的蜂窝组175移交的UE的其余蜂窝组175的功率。这在诸如体育场馆的场所中可能是必要的,在所述场所中,与其余蜂窝组175连接的UE可以在物理上广泛地分散。可替代地,将被关闭的蜂窝组175的远程单元170可以同步并移交给其余蜂窝组175,以使得其余BBU模块155可以控制其原始的远程单元170和要被关闭的蜂窝组175的远程单元170两者。这可以导致由单个BBU模块155调度的更大的蜂窝组175,所述单个BBU模块155由两个或更多个远程单元170供电。
图7示出了系统100的容量减小的配置700。在图7中仅示出了相关的组件模块,尽管将理解存在接口/路由器组件模块和外部组件,但是未示出。在容量减少的配置700中,几个蜂窝组175合并为更大的蜂窝组705,所述更大的蜂窝组705由单个BBU模块155和POI/DAS模块160驱动。还示出了高需求蜂窝组710,其具有其自己的专用BBU模块155和POI/DAS模块160。尽管没有以这种方式示出,但是更大的蜂窝组705可以由单个(或更少)远程单元170驱动,所述单个远程单元170已经增加了其功率以补偿其更广泛的覆盖区域。将理解的是,此类变型是可能的,并且在本公开的范围内。在这种情况下,未使用的远程单元170可以被关闭。此外,将显而易见的是,节能可以通过减少系统100中的组件模块105的数量和复杂性来实现。
返回到图5,如果编排器130在步骤510中确定系统100的容量不足以满足当前需求或近期需求,则过程500行进到分支540,其中编排器130执行指令以向系统100增加容量。
在步骤545中,编排器130执行指令以确定经历对连接的增加需求的位置。这样做时,编排器130通过标识从其所报告的性能测量中报告过多需求的BBU模块155来标识过载的蜂窝组175。利用该信息,编排器130通过将未使用的远程单元170定位在当时可以关闭的那个覆盖区域内来标识潜在的附加蜂窝组175。编排器130可以通过执行指令以查询数据库或配置文件来这样做,所述数据库或配置文件列出可用的远程单元170、其对应的天线(未示出)以及这些天线的覆盖区域。此外,情况可能是,系统100可以在容量减少的配置700中操作,在所述配置700中,在经历需求增加的区域的覆盖区域内的两个或更多个远程单元170可以冗余地操作,如图7所示。在这种情况下,这些远程单元170中的一个或多个可以用于在经历需求增加的区域内形成一个或多个新的蜂窝组175。
在步骤550中,编排器130执行指令以实例化一个或多个BBU模块155和对应的POI/DAS模块160,以形成一个或多个新的蜂窝组175。这样做的过程可以基本上类似于以上公开的步骤320-335。步骤550的结果是系统100,其具有一个或多个附加BBU模块155和POI/DAS模块160、用于期望数量的附加UE的UE上下文数据191的共享存储器的阵列、以及新BBU模块155、POI/DAS模块160和接口/路由器模块之间的互连通道、以及经由X2Mux 150到其他BBU模块155的X2连接。
在步骤555中,编排器130可以执行指令以使BBU模块155经历不断增长的需求,以使其一定数量的UE执行X2切换到一个或多个新BBU模块155及其对应的蜂窝组175,从而在合格的蜂窝组175之间分配负载。
图8示出了系统100的最大容量配置800,其中所有蜂窝组175被分布,使得每个蜂窝组175具有最小的覆盖区域,因为每个蜂窝组都经历高需求水平。每个蜂窝组175具有专用的远程单元170,所述远程单元170进而具有专用POI/DAS模块160和对应的专用BBU模块155。
返回到图5,在步骤560中,编排器130可以将以下信号发送到适当的网络运营商的核心网络:系统100响应于需求的变化已经增加或减小了其容量。这可能是有用的信息,因为网络运营商随后可以有机会响应于变化而适当地向/从系统100重新分配网络资源。
干扰缓解
位于两个蜂窝组175的覆盖区域内的UE之间可能会出现蜂窝间干扰。考虑到用以非常低的延迟进行通信的能力实现虚拟BBU模块155,系统100为ICIC
(蜂窝间干扰协调)提供机会。
图6示出了示例性过程600,通过所述过程,编排器130可以为相邻蜂窝组175提供增强的ICIC,每个蜂窝组以相同的频率在给定的TTI(发送时间间隔)中发送唯一的数据帧,
在步骤605中,编排器130执行指令以标识以给定的服务频率彼此干扰的两个蜂窝。这可以进行,其中两个或更多个BBU模块155可以提供性能测量(如步骤510所示),或者其中编排器130在其他方面从一个或多个BBU模块155接收它们正在以给定频率受到蜂窝间干扰的指示。在步骤610中,协调器标识哪些蜂窝组175正在受到干扰以及在哪个频带处受到干扰。
在步骤615中,编排器130确定与两个或更多个干扰蜂窝共同通信的连接UE的数量。如果连接UE的总数足够低于会使集体蜂窝组过载的数量,则编排器130可以执行指令以将干扰蜂窝组175合并为更大的主蜂窝组175。这可以类似于以上参考过程500的步骤520-530所描述的那样进行。这将导致单个BBU模块155(以及因此单个调度器)处理正在受到蜂窝间干扰的所有UE。
返回到步骤615,如果干扰蜂窝组175内的连接UE的总数使得将它们合并为单个蜂窝组175是不可行的,则过程600可以行进到步骤625,在所述步骤625中编排器130执行指令以实例化一个或多个协调器模块157。每个协调器模块157被分配给其中发生蜂窝间干扰的服务频率。此外,每个协调器模块157包括一组机器可读指令,所述机器可读指令在由一个或多个处理器执行时以由编排器130在步骤610中所标识的服务频率提供两个或更多个干扰BBU模块155之间的协调,并实现协调的两种形式中的一种:蜂窝间协调和帧内协调。在示例性实施例中,可以使用诸如Kubernetes的COE来实现每个协调器模块157。可替代地,单个Kubernetes实例可以编排一组协调器模块157的创建、操作和关闭。
在蜂窝间协调中,两个BBU模块155可以协调与UE靠近在一起的重叠覆盖区域中的UE的通信,两者UE相对靠近一个蜂窝组175的天线并且相对远离第二蜂窝组175的天线。在蜂窝间干扰协调下,这些UE两者可以以相同的频率使用相同的资源块。在这种情况下,一个UE与附近的蜂窝组175通信,并且另一个与相对较远的蜂窝组175通信。由于它们之间的延迟时间的差异,它们能够以相同的频率使用相同的资源块。两个UE都不会同时看到相同的资源块。因此,没有蜂窝间干扰。在这种情况下,两个BBU模块155可以协调重叠覆盖区域内的UE的处理。在这种情况下,协调器模块157可以在指定哪些UE要与哪个蜂窝组175通信以实现该协调中充当中介器。此外,协调器模块157可以在两个干扰蜂窝组175之间分配资源块,以使得一个蜂窝组将被分配其覆盖区域的外边缘的时间相关的覆盖范围,而另一个蜂窝组175将被优先分配其内部覆盖区域。
步骤630是步骤625的替代方案,因为在步骤630中,协调器模块157执行指令以实现帧内协调。在这种情况下,协调器模块157经由互连通道与干扰BBU模块155中的每一个的调度器模块230通信。在低延迟交换结构120中使用互连通道可以使得两个不同的调度器230能够在TTI的基础上为会在其他方面引起蜂窝间干扰的那些UE共享给定帧。这可以根据服务频率(例如,频谱的10MHz数据块)独立地进行,以使得可能存在几个协调器模块157,每个协调器模块157处理不同的10MHz频带。在步骤630的变型中,两个不同的调度器(BBU模块155)可以共享给定帧,其中BBU模块155中的一个可以实现标准LTE协议栈,并且另一个可以是用于诸如CatM或NB-IoT的IoT装置的专用调度器。在这种情况下,协调器模块157可以将特定一组资源块保留给专用调度器,以使得由两个调度器(标准LTE BBU模块155和专用IoTBBU模块155)服务的UE的相对优先级被维持。这可以防止以下情况:IoT特定调度器可能在其他方面在子帧序列上保留资源块,以实现覆盖增强用途,其中可以为覆盖范围较差的单个IoT UE抢先分配过多数量的资源块以允许与HARQ相关的重传(例如,覆盖增强)。在这种情况下,协调器157还可以充当仲裁器,以确保公共LTE帧的资源块正确地设置在LTE BBU模块155和专用BBU模块155之间。
尽管以上示例将系统100描述为使用低延迟交换结构120来提供组件模块105之间的通信,但是应理解,这是示例,并且其他进程间通信技术、标准或技术可以在它们为数据通信提供足够的带宽、足够低的延迟,并且优选地没有内核参与的情况下被采用,是可能的,并且在本公开的范围内。
- 用于虚拟无线基站的编排器和互连结构映射器
- 用于互连基于控制器的虚拟网络和基于协议的虚拟网络的技术