一种基于唇形同步的智能动画生成方法及系统
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及智能动画生成领域,具体涉及一种基于唇形同步的智能动画生成方法及系统。
背景技术
唇型同步也称为口形同步(简称唇同步),是通过讲、唱歌和口语的人声嘴唇动作从而匹配的技术,而音频输入驱动面部的表情一直是计算机视觉和图形学的重要研究兴趣,随着人工智能和神经网络的发展,当前的主流方法是利用人脸识别的关键点定位方法对人物的面部状态进行定位,即通过输入的音频驱动嘴部的关键点运动,在确定关键点后通过使用3D建模或神经网络生成模型等方法进行对应嘴部状态的重建,从而达到音频驱动唇形同步的效果。
目前,完成一部动画的制作,需要制作人有比较专业的动画制作技能,同时需要人工把制作的意图写成文字剧本,再通过专业人员把剧本的元素通过制作工具串联起来,达到动画制作的目的,因此通常会使用到其一:基于数据驱动的方法,基于数据驱动的方法在建立模型的训练阶段需要大量的原始数据,最后生成的动画的生动性跟数据量的大小有密切的关系,由于数据量大,这也导致在提取特征的途中需要较大的数据存储空间和计算,所以对于硬件的要求也非常高,且收集数据的环境要求也非常高,需要一定的灯光条件和摄像条件,其二:基于模型参数的方法,与数据驱动不同的是不需要大量的数据支撑,通过音频数据和参数模型之间的参数变化进行提取相应的特征,但其提取时数据的不全面导致提取的特征存在不准确的现象,影响动画的真实感,因此需要对其唇形同步的智能动画生成进行改进。
发明内容
本发明的目的是解决以上缺陷,提供一种基于唇形同步的智能动画生成方法及系统,以解决上述背景技术中提到的问题。
本发明的目的是通过以下方式实现的:
一种基于唇形同步的智能动画生成方法,包括以下步骤:
步骤1:根据声韵母的嘴型发音规则,统概出十个常用口型,将获取的发音口型输入第一获取单元,将嘴唇动作的音频帧和口型帧对齐,根据中文发音习惯将嘴唇动作产生的声韵母产生的发音通过接收单元输入对应的第一获取单元,并对多帧的发音口型进行预处理;
步骤2:将获取的发音口型进行建模,将发音口型结合MAYA的软件进行建模,通过MAYA软件内部的变形器使其实现对应的修改,从而得到相应特有的表情基BlendShape;
步骤3:获取中文在音频数列之间的时间节点,通过检索单元分析对应的音频帧中文字符,得到“对应的声波”,并通过深度分析将声波对应的拼音中产生的声母和韵母相关的时间节点进行标识,得到对应时间序列;
步骤4:结合时间节点和发音口型对应的表情基BlendShape,通过驱动模块进行驱动后得到相应的驱动模型数据;
步骤5:计算驱动模型数据,将驱动模型数据通过渲染引擎模块进行计算后得到对应的动画效果。
上述说明中进一步的,所述步骤1中,发音口型为嘴唇动作产生的声韵母,将声韵母划分为十个等级:
声母第一类:['b','p','m']、声母第二类:['f']、声母第三类:['d','t','n','l']、声母第四类:['zh','sh','ch','r']、声母第五类:['y','j','q','x','z','c','s']、声母第六类:['g','k','h']、韵母第一类:
['iang','uang','iao','ian','uai','uan','van','ang','ia','ai','ao','an','ua','a']、韵母第二类:
['w','iong','ueng','iou','ong','ve','ou','uo','ui','un','iu','u','v','o']、韵母第三类:['uei','uen','eng','er','ei','en','e']、韵母第四类:['ing','ie','in','i']。
上述说明中进一步的,所述步骤2中,通过MAYA的建模统筹分析将发音口型制作得到对应的十个模型形变形态。
上述说明中进一步的,所述步骤3中,通过对音频数列的分析,即根据声波,每个字的中间均存在一个比较短暂的静音段,通过静音段的切分从而生成“对应的声波”。
上述说明中进一步的,所述步骤3中,将声波对应拼音的声母韵母的时间节点进行标识,标识的时间节点得到对应的时间序列,时间序列控制为60hz,通过时间序列60hz作为时间戳进行切分。
上述说明中进一步的,所述声母韵母的时间节点分别设置为一和二,即可得到带标识的声母序列和韵母序列,还包括其他时间点为零。
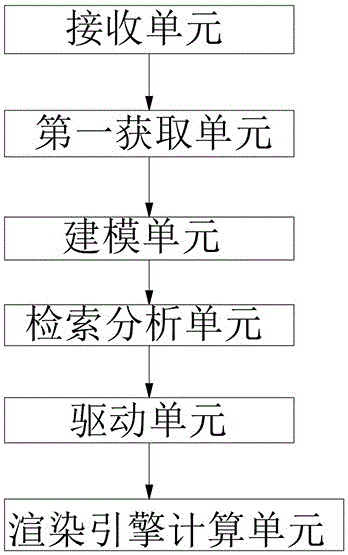
一种基于唇形同步的智能动画生成系统,该系统应用于所述的一种基于唇形同步的智能动画生成方法,该系统包括接收单元、第一获取单元、检索分析单元和渲染引擎计算单元,通过接收单元接收人们发送的发音口型内容,通过第一获取单元识别获取相应的发音口型,将获取的发音口型通过建模单元进行建模,建模后通过检索分析单元,结合发音口型的进行智能检索后生成相对应的时间序列。
上述说明中进一步的,所述检索后的时间序列和口型类别通过驱动模块驱动后,渲染引擎计算单元进行计算相应的动画效果。
上述说明中进一步的,所述接收单元包括语音数据、视频数据或文本数据中的一种或多种。
本发明的有益效果:因为本发明结合了中文的发音规则,通过中文特有的发音口型,使得不需要大量数据来提取人类发音的口型特征,只需要分析中文和对应的音频之间的关系,既可以得到驱动脸部参数模型的数据,加上现有的3d模型技术的改进,现有的很多软件均自带模型驱动引擎,只需要建立一个基础模型和相应的表情基规则,把相应的驱动数据放进相应的引擎中即可渲染出精美的动画,这样在保证动画生动形象的同时,解决了基于数据驱动的方法需要大量数据的问题。
附图说明
图1为本发明一种基于唇形同步的智能动画生成系统的流程图;
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述。
本实施例,参照图1,其具体实施的一种基于唇形同步的智能动画生成方法,包括以下步骤:
步骤1:根据声韵母的嘴型发音规则,统概出十个常用口型,将获取的发音口型输入第一获取单元,将嘴唇动作的音频帧和口型帧对齐,根据中文发音习惯将嘴唇动作产生的声韵母产生的发音通过接收单元输入对应的第一获取单元,并对多帧的发音口型进行预处理,发音口型为嘴唇动作产生的声韵母,将声韵母划分为十个等级:声母第一类:['b','p','m']、声母第二类:['f']、声母第三类:['d','t','n','l']、声母第四类:['zh','sh','ch','r']、声母第五类:['y','j','q','x','z','c','s']、声母第六类:['g','k','h']、韵母第一类:['iang','uang','iao','ian','uai','uan','van','ang','ia','ai','ao','an','ua','a']、韵母第二类:['w','iong','ueng','iou','ong','ve','ou','uo','ui','un','iu','u','v','o']、韵母第三类:['uei','uen','eng','er','ei','en','e']、韵母第四类:['ing','ie','in','i'];
步骤2:将获取的发音口型进行建模,将发音口型结合MAYA的软件进行建模,通过MAYA软件内部的变形器使其实现对应的修改,从而得到相应特有的表情基BlendShape,通过MAYA的建模统筹分析将发音口型制作得到对应的十个模型形变形态;
步骤3:获取中文在音频数列之间的时间节点,通过检索单元分析对应的音频帧中文字符,通过对音频数列的分析,即根据声波,每个字的中间均存在一个比较短暂的静音段,通过静音段的切分从而生成“对应的声波”,并通过深度分析将声波对应的拼音中产生的声母和韵母相关的时间节点进行标识,得到对应时间序列,音频数列分为声母序列和韵母序列,步骤3中,将声波对应拼音的声母韵母的时间节点进行标识,标识的时间节点得到对应的时间序列,时间序列控制为60hz,通过时间序列60hz作为时间戳进行切分,切分后声母韵母的时间节点分别设置为一和二,即可得到带标识的声母序列和韵母序列,还包括其他时间点为零;
步骤4:结合时间节点和发音口型对应的表情基BlendShape,通过驱动模块进行驱动后得到相应的驱动模型数据;
步骤5:计算驱动模型数据,将驱动模型数据通过渲染引擎模块进行计算后得到对应的动画效果。
一种基于唇形同步的智能动画生成系统,该系统应用于所述的一种基于唇形同步的智能动画生成方法,该系统包括接收单元、第一获取单元、检索分析单元和渲染引擎计算单元,通过接收单元接收人们发送的发音口型内容,通过第一获取单元识别获取相应的发音口型,将获取的发音口型通过建模单元进行建模,建模后通过检索分析单元,结合发音口型的进行智能检索后生成相对应的时间序列。
检索后的时间序列和口型类别通过驱动模块驱动后,渲染引擎计算单元进行计算相应的动画效果,接收单元包括语音数据、视频数据或文本数据中的一种或多种。
因为本发明结合了中文的发音规则,根据中文特有的发音口型,统概出十个常用口型,通过目前兴起的3d建模软件MAYA,建立模型的同时根据本发明提供的表情基建模规则构建人脸,即可得到特有的表情参数化模型,然后通过中文发音的特征,提取出十种中文发音口型,然后通过提取音频序列的特征和所对应的中文,得到相应的声韵母时间节点的时间序列,便可把相应的BlendShape代入到时间序列中,然后对其进行均值滤波,便可得到相应的驱动BlendShape的数据,计算出音频所对应的驱动模型的参数,最后通过模型渲染引擎,即可得出相应的动画,只需要建立一个基础模型和相应的表情基规则,把相应的驱动数据放进相应的引擎中即可渲染出精美的动画,这样在保证动画生动形象的同时,解决了基于数据驱动的方法需要大量数据的问题,后续通过输入相应的中文句子和对应的音频数据既可以得到相应的动画。
以上所述,仅是本发明较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明以较佳实施例公开如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当利用上述揭示的技术内容作出些许变更或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案内容,依据本发明技术是指对以上实施例所作的任何简单修改、等同变化与修饰,均属于本发明技术方案的范围内。