一种基于大数据集成的业务信息分类归纳系统
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及信息分类领域,尤其涉及一种基于大数据集成的业务信息分类归纳系统。
背景技术
业务信息分类归纳系统是一个用于整理和分类业务信息的工具;它的主要目的是帮助用户更好地组织和查找不同类型的业务信息;这个系统使用一套明确的分类标准,将业务信息分成不同的类别,从而使用户能够更方便地访问他们所需的信息;用户可以通过输入关键词或浏览分类目录来查找特定的业务信息;此外,系统还提供了分类统计功能,可以显示每个类别中包含的信息数量,帮助用户了解不同类别的数据量和重要性;这个系统还支持多用户登录,每个用户可以创建和管理自己的业务信息库;用户可以将信息加入收藏夹或创建自己的分类标签,以便更好地组织和管理自己的业务信息;总而言之,业务信息分类归纳系统是一个简单高效的工具,能够帮助用户更好地管理和利用业务信息;采用人工神经网络算法对数据进行处理,具有很强的非线性映射能力及自学习、并行性、抗噪能力和容错能力,但是在处理数据时,神经网络算法存在着学习时间较长、表达的知识隐藏且难理解等固有缺陷,如基于蚁群算法的神经网络算法,在对数据进行处理时,需要消耗大量的计算资源,且计算处理时间长。
发明内容
为了克服采用人工神经网络算法对数据进行处理,具有很强的非线性映射能力及自学习、并行性、抗噪能力和容错能力,但是在处理数据时,神经网络存在着学习时间较长、表达的知识隐藏且难理解等固有缺陷,如基于蚁群算法的神经网络算法,在对数据进行处理时,需要消耗大量的计算资源,且计算处理时间长的问题。
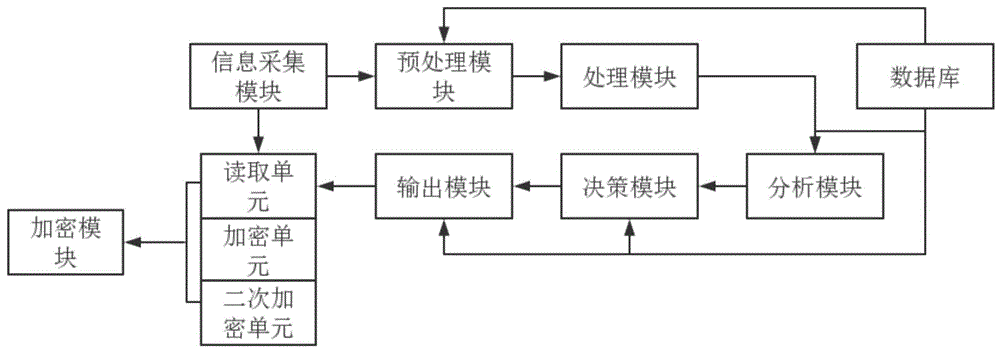
本发明的技术方案为:一种基于大数据集成的业务信息分类归纳系统,包括有:
信息采集模块,用于收集用户所输入的信息,并对收集到的信息进行整理;
预处理模块,用于对收集到的信息进行预处理,去除信息内的非必要信号;
处理模块,用于对经过预处理后的信息进行处理,提取信息内的关键词;
数据库,用于储存用户预输入的信息和含有相关词语及其相近词及释义的词典;
分析模块,用于将处理模块与数据库内的信息进行对比分析,得出各种相关指数;
决策模块,用于根据分析模块得出的相关指数进行判断,将用户输入的信息进行分类;
输出模块,用于根据决策模块的信息进行整合,将结果显示给用户。
优选的,通过对采集到的信息进行预处理,减少信息内的非必要信号,可以提前将信息内的无用数据进行剔除,减少处理模块的工作量,从而增加系统的运行速度,且可以防止分析模块受到无用信息的干扰,导致分类错误,通过处理模块可以通过简单的计算方法将信息中的关键词及关键词的相关信息进行提取,从而可以利用分析模块通过简单的分析方法利用提取出的信息对数据库内的相关历史信息进行搜索和选择,从而可以减少决策模块的工作量,从而增加系统的运行速度。
作为优选,预处理模块在对收集到的信息进行预处理时,包括以下步骤:
S1:将收集到的信息内的所有内容进行分解,并将分解的内容归为含有全部词语的词语集;
S2:将词语集内的无用信息去除,其中,无用信息包括:停用词、中性词、标点符号及量词;
S3:利用数据库内的词典对词语集内的所有词语的含义进行分析,并将具有相近含义的词语进行整合,使词语集内的词语标准化。
作为优选,处理模块在对经过预处理后的信息进行处理时,包括以下步骤:
S1:将标题或者抬头内的关键词单独提取出来;
S2:将词语集内不同词语的出现频率进行统计并排序,并根据频率对关键词进行提取,形成关键词组,其中,默认提取出现频率前十五的词语,且当排序在出现频率十五之后的词语出现频率大于百分之三时,将所有出现频率大于百分之三的词语列入关键词组,且标题和抬头内的关键词默认出现频率加百分之一。
作为优选,数据库内用户预输入的信息包括业务信息分类的历史数据及其经过预处理模块和处理模块处理后的关键词组、关键词组内各个关键词在该业务信息数据内的权重占比、业务分派的信息、业务分派的代码和加密文件所需要的秘钥。
作为优选,业务分派的代码与业务分派的信息一一对应,加密文件所需要的秘钥与业务分派的代码一一对应,且加密文件所需要的秘钥包括业务员手动输入的密码和系统随机生成的秘钥代码,其中业务员手动输入的密码组成为:M+N,其中M的取值范围为20-50,N为任意字符,系统随机生成的秘钥代码为随机的二进制代码串。
作为优选,分析模块在将处理模块与数据库内的信息进行对比分析时,包括以下步骤:
S1:将用户输入业务信息的关键词组内的所有关键词在数据库内进行搜索,并将数据库内的业务信息分类的历史数据及其经过预处理模块和处理模块处理后的关键词组和关键词组内各个关键词在该业务信息数据内的权重占比进行提取;
S2:将提取出来用户输入业务信息的关键词组与历史业务的关键词组进行比对,并将与用户输入业务信息的关键词组重复度在百分之二十以下的历史业务相关信息文档进行剔除;
S3:根据用户输入业务信息的关键词组中出现频率权重占比最高的关键词与历史业务信息分类的关键词组进行分析,输出期望值P;
S4:将用户输入业务信息的关键词组、经过S2剔除之后的历史业务相关信息和S3中计算出来的期望值P发送至决策模块。
作为优选,根据用户输入业务信息的关键词组中出现频率权重占比最高的关键词与历史业务信息分类的关键词组进行分析,输出期望值P时,通过以下公式计算期望值P:
作为优选,决策模块在进行判断时,包括以下步骤:
S1:根据期望值P对经过剔除之后的历史业务相关信息进行排序;
S2:统计所有期望值大于
S3:利用公式
作为优选,还包括加密模块,加密模块用于根据业务分派的信息、业务分派的代码和加密文件所需要的秘钥对用户输入的业务信息进行加密处理,加密模块包括用于读取用户输入的读取单元、向系统文件内输入加密代码的加密单元和将文件进行二次加密的二次加密单元。
作为优选,输出模块在对决策模块输出的信息进行整合时,首先将对应的历史业务信息的所属领域在数据库中进行搜索并读取,并根据业务分派信息进行业务分派代码的匹配,匹配完成后将业务分派代码和对应的加密用的秘钥进行整合,并发送给加密模块。
作为优选,加密模块在对用户输入的信息进行加密时,包括以下步骤:
S1:读取单元读取用户所输入的业务信息数据,并发送给加密单元;
S2:加密单元输出模块所传输的加密文件所需要的秘钥对用户所输入的业务信息数据进行加密,其中加密方式为:在文档中相隔M个字节插入一组字符串N;
S3:二次加密单元对加密后的数据的每个字符进行镜像处理,形成加密文件;
S4:根据业务分派代码将加密文件发送给对应代码的业务员。
本发明的有益效果:
1、相对于现有技术采用人工神经网络算法对数据进行处理,具有很强的非线性映射能力及自学习、并行性、抗噪能力和容错能力,但是在处理数据时,神经网络存在着学习时间较长、表达的知识隐藏且难理解等固有缺陷,如基于蚁群算法的神经网络算法,在对数据进行处理时,需要消耗大量的计算资源,且计算处理时间长,该分类归纳系统通过对采集到的信息进行预处理,减少信息内的非必要信号,可以提前将信息内的无用数据进行剔除,减少处理模块的工作量,从而增加系统的运行速度,且可以防止分析模块受到无用信息的干扰,导致分类错误,通过处理模块可以通过简单的计算方法将信息中的关键词及关键词的相关信息进行提取,从而可以利用分析模块通过简单的分析方法利用提取出的信息对数据库内的相关历史信息进行搜索和选择,从而可以减少决策模块的工作量,从而增加系统的运行速度;
2、通过对标题和抬头的关键词进行单独加频率权重,可以符合标题重要性大于内容的事实,从而可以增加处理结果的准确性,且通过设置关键词最少为十五个,可以防止分类过于单一,导致非必要关键词影响决策结果,且通过将出现频率大于百分之三的关键词全部保留,可以防止将关键词遗漏,增加系统的准确性,通过期望值P,一方面可以强调关键词的重复数量,另一方面可以根据关键词在信息内的权重控制该关键词的数量,计算简单且有效,通过对期望值进行比对,可以根据期望值P对相干度较低的文档进行识别并剔除,减小决策模块的决策难度,且可以减小下一步计算的工作量,通过计算匹配度,可以根据单组关键词对信息进行检索,从而在期望值相近的时候进行二次判断,从而可以进行决策,增加系统的可靠度;
3、通过对信息进行分解,可以将信息内容进行简单的归类,以便于系统对信息内容的理解,且通过对词语集内的无用信息进行去除,一方面可以减少后续工作的工作量,增加系统的反馈速度,另一方面可以将干扰信息剔除,方盒子干扰信息对分析模块和决策模块造成干扰,增加系统的准确性。
附图说明
图1展现的为本发明的一种基于大数据集成的业务信息分类归纳系统的构造示意图;
图2展现的为本发明的一种基于大数据集成的业务信息分类归纳系统中预处理步骤的流程构造示意图;
图3展现的为本发明的一种基于大数据集成的业务信息分类归纳系统中分析模块的工作流程示意图。
具体实施方式
下面结合附图和实施例对本发明进一步地进行说明。
请参阅图1,本发明提供一种实施例:一种基于大数据集成的业务信息分类归纳系统,包括有:
信息采集模块,用于收集用户所输入的信息,并对收集到的信息进行整理;
预处理模块,用于对收集到的信息进行预处理,去除信息内的非必要信号;
处理模块,用于对经过预处理后的信息进行处理,提取信息内的关键词;
数据库,用于储存用户预输入的信息和含有相关词语及其相近词及释义的词典;
分析模块,用于将处理模块与数据库内的信息进行对比分析,得出各种相关指数;
决策模块,用于根据分析模块得出的相关指数进行判断,将用户输入的信息进行分类;
输出模块,用于根据决策模块的信息进行整合,将结果显示给用户。
具体的,现有技术采用人工神经网络算法对数据进行处理,具有很强的非线性映射能力及自学习、并行性、抗噪能力和容错能力,但是在处理数据时,神经网络存在着学习时间较长、表达的知识隐藏且难理解等固有缺陷,如基于蚁群算法的神经网络算法,在对数据进行处理时,需要消耗大量的计算资源,且计算处理时间长,该分类归纳系统通过对采集到的信息进行预处理,减少信息内的非必要信号,可以提前将信息内的无用数据进行剔除,减少处理模块的工作量,从而增加系统的运行速度,且可以防止分析模块受到无用信息的干扰,导致分类错误,通过处理模块可以通过简单的计算方法将信息中的关键词及关键词的相关信息进行提取,从而可以利用分析模块通过简单的分析方法利用提取出的信息对数据库内的相关历史信息进行搜索和选择,从而可以减少决策模块的工作量,从而增加系统的运行速度。
请参阅图2,本发明提供一种实施例:一种基于大数据集成的业务信息分类归纳系统,预处理模块在对收集到的信息进行预处理时,包括以下步骤:
S1:将收集到的信息内的所有内容进行分解,并将分解的内容归为含有全部词语的词语集;
S2:将词语集内的无用信息去除,其中,无用信息包括:停用词、中性词、标点符号及量词;
S3:利用数据库内的词典对词语集内的所有词语的含义进行分析,并将具有相近含义的词语进行整合,使词语集内的词语标准化。
具体的,通过对信息进行分解,可以将信息内容进行简单的归类,以便于系统对信息内容的理解,且通过对词语集内的无用信息进行去除,一方面可以减少后续工作的工作量,增加系统的反馈速度,另一方面可以将干扰信息剔除,方盒子干扰信息对分析模块和决策模块造成干扰,增加系统的准确性。
进一步的,处理模块在对经过预处理后的信息进行处理时,包括以下步骤:
S1:将标题或者抬头内的关键词单独提取出来;
S2:将词语集内不同词语的出现频率进行统计并排序,并根据频率对关键词进行提取,形成关键词组,其中,默认提取出现频率前十五的词语,且当排序在出现频率十五之后的词语出现频率大于百分之三时,将所有出现频率大于百分之三的词语列入关键词组,且标题和抬头内的关键词默认出现频率加百分之一。
具体的,通过对标题和抬头的关键词进行单独加频率权重,可以符合标题重要性大于内容的事实,从而可以增加处理结果的准确性,且通过设置关键词最少为十五个,可以防止分类过于单一,导致非必要关键词影响决策结果,且通过将出现频率大于百分之三的关键词全部保留,可以防止将关键词遗漏,增加系统的准确性。
进一步的,数据库内用户预输入的信息包括业务信息分类的历史数据及其经过预处理模块和处理模块处理后的关键词组、关键词组内各个关键词在该业务信息数据内的权重占比、业务分派的信息、业务分派的代码和加密文件所需要的秘钥。
进一步的,业务分派的代码与业务分派的信息一一对应,加密文件所需要的秘钥与业务分派的代码一一对应,且加密文件所需要的秘钥包括业务员手动输入的密码和系统随机生成的秘钥代码,其中业务员手动输入的密码组成为:M+N,其中M的取值范围为20-50,N为任意字符,系统随机生成的秘钥代码为随机的二进制代码串。
具体的,利用业务分派的信息可以根据业务分类结果知晓业务分派的代码,从而可以匹配到指定的秘钥信息。
请参阅图3,本发明提供一种实施例:一种基于大数据集成的业务信息分类归纳系统,分析模块在将处理模块与数据库内的信息进行对比分析时,包括以下步骤:
S1:将用户输入业务信息的关键词组内的所有关键词在数据库内进行搜索,并将数据库内的业务信息分类的历史数据,及其经过预处理模块和处理模块处理后的关键词组和关键词组内各个关键词在该业务信息数据内的权重占比进行提取;
S2:将提取出来用户输入业务信息的关键词组与历史业务的关键词组进行比对,并将与用户输入业务信息的关键词组重复度在百分之二十以下的历史业务相关信息文档进行剔除;
S3:根据用户输入业务信息的关键词组中出现频率权重占比最高的关键词与历史业务信息分类的关键词组进行分析,输出期望值P;
S4:将用户输入业务信息的关键词组、经过S2剔除之后的历史业务相关信息和S3中计算出来的期望值P发送至决策模块。
具体的,通过先将重复度较低的内容进行直接剔除,可以降低不相干文档的数量,从而减小系统的工作量,增加系统的反馈速度。
进一步的,根据用户输入业务信息的关键词组中出现频率权重占比最高的关键词与历史业务信息分类的关键词组进行分析,输出期望值P时,通过以下公式计算期望值P:
具体的,通过期望值P,一方面可以强调关键词的重复数量,另一方面可以根据关键词在信息内的权重控制该关键词的数量,计算简单且有效。
进一步的,决策模块在进行判断时,包括以下步骤:
S1:根据期望值P对经过剔除之后的历史业务相关信息进行排序;
S2:统计所有期望值大于
S3:利用公式
具体的,通过对期望值进行比对,可以根据期望值P对相干度较低的文档进行识别并剔除,减小决策模块的决策难度,且可以减小下一步计算的工作量,通过计算匹配度,可以根据单组关键词对信息进行检索,从而在期望值相近的时候进行二次判断,从而可以进行决策,增加系统的可靠度。
进一步的,还包括加密模块,加密模块用于根据业务分派的信息、业务分派的代码和加密文件所需要的秘钥对用户输入的业务信息进行加密处理,加密模块包括用于读取用户输入的读取单元、向系统文件内输入加密代码的加密单元和将文件进行二次加密的二次加密单元。
进一步的,输出模块在对决策模块输出的信息进行整合时,首先将对应的历史业务信息的所属领域在数据库中进行搜索并读取,并根据业务分派信息进行业务分派代码的匹配,匹配完成后将业务分派代码和对应的加密用的秘钥进行整合,并发送给加密模块。
进一步的,加密模块在对用户输入的信息进行加密时,包括以下步骤:
S1:读取单元读取用户所输入的业务信息数据,并发送给加密单元;
S2:加密单元输出模块所传输的加密文件所需要的秘钥对用户所输入的业务信息数据进行加密,其中加密方式为:在文档中相隔M个字节插入一组字符串N;
S3:二次加密单元对加密后的数据的每个字符进行镜像处理,形成加密文件;
S4:根据业务分派代码将加密文件发送给对应代码的业务员。
具体的,通过对读取单元对用户输入的业务信息进行直接读取,可以减少业务信息在网络上流通的次数,从而可以减少信息泄露的可能性,且可以配合加密单元和二次加密单元保证只有加密后的信息在网络上流通,从而可以增加信息的保密程度。
通过上述步骤,实现通过对采集到的信息进行预处理,减少信息内的非必要信号,可以提前将信息内的无用数据进行剔除,减少处理模块的工作量,从而增加系统的运行速度,且可以防止分析模块受到无用信息的干扰,导致分类错误,通过处理模块可以通过简单的计算方法将信息中的关键词及关键词的相关信息进行提取,从而可以利用分析模块通过简单的分析方法利用提取出的信息对数据库内的相关历史信息进行搜索和选择,从而可以减少决策模块的工作量,从而增加系统的运行速度。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。