用于手势识别的数据增强方法、装置、计算机设备及存储介质
文献发布时间:2023-06-19 10:08:35
技术领域
本发明涉及计算机技术领域,具体涉及一种用于手势识别的数据增强方法、装置、计算机设备及存储介质。
背景技术
手势是人类之间交流的一种自然形式,手势识别也是人机交互的重要研究方向之一。在训练手势识别模型的过程中,训练数据的质量和数量对最终手势识别的结果起到十分重要的作用。为了让模型在实际使用中能发挥更好的性能,在采集数据的过程中,倾向于数据的数量越多、数据涵盖的场景越广越好。由于采集数据是一项耗时耗力的过程,采集到数据往往可能不够全面,比如,在采集手势数据的过程中,大部分人都习惯性的用右手执行手势,从而使得最终的数据集中,右手的手势数据在总的数据中占比过高,而用左手执行的手势数据占比较低。将用这种数据训练出来的模型用在实际的场景中,会发现在检测左手手势时,其准确率往往低于右手手势。
所以为了提高模型的准确度,可以采用数据增强的方法来使得训练数据更丰富,从而提高手势识别的准确度。
发明内容
基于此,有必要针对上述问题,提出一种可以丰富训练数据的用于手势识别的数据增强方法、装置、计算机设备及存储介质。
一种用于手势识别的数据增强方法,包括:
获取第一手势视频数据,所述第一手势视频数据包括:第一手势视频和所述第一手势视频对应的标签;
将所述第一手势视频中每一视频帧图像进行水平镜像翻转,得到第二手势视频;
根据所述第一手势视频对应的标签确定所述第二手势视频对应的标签;
将所述第二手势视频和所述第二手势视频对应的标签进行关联存储,得到第二手势视频数据;
将所述第一手势视频数据和所述第二手势视频数据都作为手势识别模型的训练数据。
一种用于手势识别的数据增强装置,包括:
第一获取模块,用于获取第一手势视频数据,所述第一手势视频数据包括:第一手势视频和所述第一手势视频对应的标签;
翻转模块,用于将所述第一手势视频中每一视频帧对应的手势图像进行水平镜像翻转,得到第二手势视频;
确定模块,用于根据所述第一手势视频对应的标签确定所述第二手势视频对应的标签;
关联模块,用于将所述第二手势视频和所述第二手势视频对应的标签进行关联存储,得到第二手势视频数据;
训练模块,用于将所述第一手势视频数据和所述第二手势视频数据一起作为手势识别模型的训练数据。
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:
获取第一手势视频数据,所述第一手势视频数据包括:第一手势视频和所述第一手势视频对应的标签;
将所述第一手势视频中每一视频帧图像进行水平镜像翻转,得到第二手势视频;
根据所述第一手势视频对应的标签确定所述第二手势视频对应的标签;
将所述第二手势视频和所述第二手势视频对应的标签进行关联存储,得到第二手势视频数据;
将所述第一手势视频数据和所述第二手势视频数据都作为手势识别模型的训练数据。
一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行以下步骤:
获取第一手势视频数据,所述第一手势视频数据包括:第一手势视频和所述第一手势视频对应的标签;
将所述第一手势视频中每一视频帧图像进行水平镜像翻转,得到第二手势视频;
根据所述第一手势视频对应的标签确定所述第二手势视频对应的标签;
将所述第二手势视频和所述第二手势视频对应的标签进行关联存储,得到第二手势视频数据;
将所述第一手势视频数据和所述第二手势视频数据都作为手势识别模型的训练数据。
上述手势识别的数据增强方法、装置、计算机设备及存储介质,通过对第一手势视频中的视频帧图像进行水平镜像翻转,得到第二手势视频,并根据第一手势视频的标签确定第二手势视频对应的标签,将第二手势视频和第二手势视频对应的标签进行关联存储,得到第二视频手势数据,将第一手势视频数据和第二手势视频数据都作为手势识别模型的训练数据。上述手势识别的数据增强方法,根据第一手势视频数据得到第二手势视频数据,然后将第一手势视频数据和第二手势视频数据一起作为训练数据,可以使得训练数据更加全面,从而使得训练得到的模型不仅能够准确预测出第一手势,而且能够准确预测出第二手势。
一种用于手势识别的数据增强方法,包括:
获取第一手势图像数据,所述第一手势图像数据包括:第一手势图像和所述第一手势图像对应的标签;
将所述第一手势图像进行水平镜像翻转,得到第二手势图像;
根据所述第一手势图像对应的标签确定所述第二手势图像对应的标签;
将所述第二手势图像和所述第二手势图像对应的标签进行关联存储,得到第二手势图像数据;
将所述第一手势图像数据和所述第二手势图像数据都作为手势识别模型的训练数据。
一种用于手势识别的数据增强装置,包括:
图像获取模块,用于获取第一手势图像数据,所述第一手势图像数据包括:第一手势图像和所述第一手势图像对应的标签;
图像翻转模块,用于将所述第一手势图像进行水平镜像翻转,得到第二手势图像;
标签确定模块,用于根据所述第一手势图像对应的标签确定所述第二手势图像对应的标签;
图像标签关联模块,用于将所述第二手势图像和所述第二手势图像对应的标签进行关联存储,得到第二手势图像数据;
模型数据模块,用于将所述第一手势图像数据和所述第二手势图像数据都作为手势识别模型的训练数据。
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:
获取第一手势图像数据,所述第一手势图像数据包括:第一手势图像和所述第一手势图像对应的标签;
将所述第一手势图像进行水平镜像翻转,得到第二手势图像;
根据所述第一手势图像对应的标签确定所述第二手势图像对应的标签;
将所述第二手势图像和所述第二手势图像对应的标签进行关联存储,得到第二手势图像数据;
将所述第一手势图像数据和所述第二手势图像数据都作为手势识别模型的训练数据。
一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行以下步骤:
获取第一手势图像数据,所述第一手势图像数据包括:第一手势图像和所述第一手势图像对应的标签;
将所述第一手势图像进行水平镜像翻转,得到第二手势图像;
根据所述第一手势图像对应的标签确定所述第二手势图像对应的标签;
将所述第二手势图像和所述第二手势图像对应的标签进行关联存储,得到第二手势图像数据;
将所述第一手势图像数据和所述第二手势图像数据都作为手势识别模型的训练数据。
上述手势识别的数据增强方法、装置、计算机设备及存储介质,通过对第一手势图像进行水平镜像翻转,得到第二手势图像,并根据第一手势图像的标签确定第二手势图像对应的标签,将第二手势图像和第二手势图像对应的标签进行关联存储,得到第二手势数据,将第一手势数据和第二手势数据都作为手势识别模型的训练数据。上述手势识别的数据增强方法,根据第一手势数据得到第二手势数据,然后将第一手势数据和第二手势数据一起作为训练数据,可以使得训练数据更加全面,从而使得训练得到的模型不仅能够准确预测出第一手势,而且能够准确预测出第二手势。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
其中:
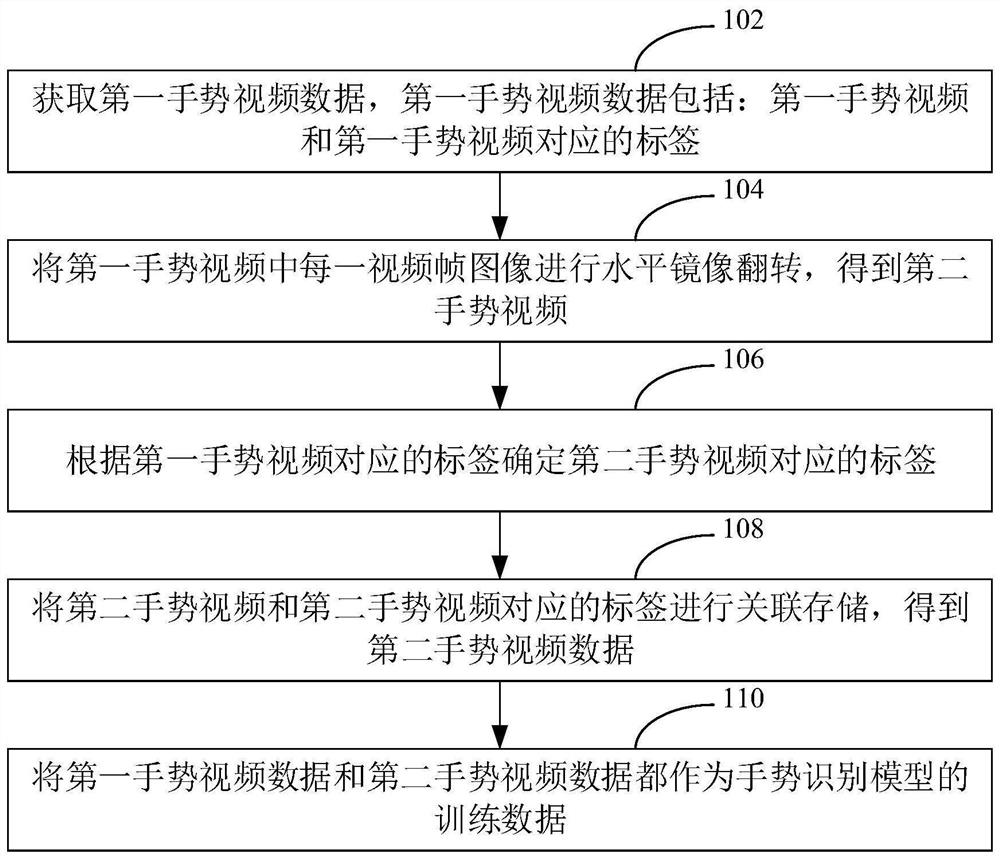
图1是一个实施例中用于手势识别的数据增强方法的流程图;
图2是一个实施例中手势视频帧图像的示意图;
图3是另一个实施例中用于手势识别的数据增强方法的流程图;
图4是一个实施例中对视频帧图像进行边缘扩增前后的示意图;
图5是又一个实施例中用于手势识别的数据增强方法的流程图;
图6是再一个实施例中用于手势识别的数据增强方法的流程图;
图7是一个实施例中用于动态手势识别的数据增强装置的结构框图;
图8是另一个实施例中用于动态手势识别的数据增强装置的结构框图;
图9是又一个实施例中用于动态手势识别的数据增强装置的结构框图;
图10是一个实施例中计算机设备的内部结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,提出了一种用于手势识别的数据增强方法,该用于手势识别的数据增强方法可以应用于终端,也可以应用于服务器,本实施例以应用于终端举例说明。该用于手势识别的数据增强方法具体包括以下步骤:
步骤102,获取第一手势视频数据,第一手势视频数据包括:第一手势视频和第一手势视频对应的标签。
其中,第一手势视频数据为右手手势视频数据。由于大部分人都习惯于用右手,所以在采集动态手势数据时,出现了右手的手势数据比左手的手势数据多很多的情况。而如果重新进行左手的手势数据的采集需要一个很大的工程,耗时耗力。基于此,提出了一种用于动态手势识别的数据增强方法,该方法不需要对数据进行重新采集,只需要对已有的数据进行增强处理即可。
每个手势视频都对应有相应的标签。比如,手势标签为:手向左摆动或手向上移动等。每个手势视频都是有多个视频帧图像组成的。
步骤104,将第一手势视频中每一视频帧图像进行水平镜像翻转,得到第二手势视频。
其中,为了将右手手势视频转换为左手手势视频,需要将每一视频帧图像进行水平镜像翻转处理。如图2所示,为手势视频帧图像的示意图。图2中的2a部分的三张图为右手手势视频帧图像,图2中2b部分的三张图分别为右手手势视频帧图像进行水平镜像翻转之后得到的左手手势图像。将水平镜像翻转之后的视频帧按照原来的顺序组合到一起就得到了左手手势视频。
步骤106,根据第一手势视频对应的标签确定第二手势视频对应的标签。
其中,由于手势进行了水平镜像翻转,所以对应的标签就需要进行适应性改变,比如,参考图2,第一手势视频对应的标签为:手的无名指和食指同时向左摆动,那么进行转换得到的第二手势视频对应的标签应该为:手的无名指和食指同时向右摆动。
步骤108,将第二手势视频和第二手势视频对应的标签进行关联存储,得到第二手势视频数据。
其中,将得到的第二手势视频和相应的标签进行关联存储,这样就得到了第二手势视频数据,即第二手势视频数据包括:第二手势视频和对应的标签。
步骤110,将第一手势视频数据和第二手势视频数据都作为手势识别模型的训练数据。
其中,最后在训练手势识别模型时,将第一手势数据和第二手势数据都作为训练数据对该模型进行训练,即通过数据增强后的训练数据对模型进行训练,有利于提高模型对于第二手势识别的准确度。该训练得到手势识别模型可以用于对动态手势的识别。
上述手势识别的数据增强方法,通过对第一手势视频中的视频帧图像进行水平镜像翻转,得到第二手势视频,并根据第一手势视频的标签确定第二手势视频对应的标签,将第二手势视频和第二手势视频对应的标签进行关联存储,得到第二视频手势数据,将第一手势视频数据和第二手势视频数据都作为手势识别模型的训练数据。上述手势识别的数据增强方法,根据第一手势视频数据得到第二手势视频数据,然后将第一手势视频数据和第二手势视频数据一起作为训练数据,可以使得训练数据更加全面,从而使得训练得到的模型不仅能够准确预测出第一手势,而且能够准确预测出第二手势。
在数据采集过程中手距离摄像头的距离越近,手在画面中的占比就会越大,反之,手距离摄像头的距离越远,手在画面中的占比就会越小。若采集数据的时候,手的占比都比较大,而实际应用的的过程中,存在手距离摄像头的距离较远的情况,此时,将用画面占比大的动态手势数据训练出的模型应用于占比小的动态手势上,会导致结果不准。为了提高对占比小的动态手势的识别,将已有的训练数据进行增强处理,通过扩增图像边缘的方法缩小手在画面中的占比。
如图3所示,在一个实施例中,提出一种用于动态手势识别的数据增强方法还包括:
步骤302,获取待扩增的手势视频,手势视频中包括多个视频帧图像。
其中,待扩增的手势视频是指待扩增边缘的手势视频,包含有多个待扩增边缘的视频帧图像。
步骤304,对手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,边缘扩增后的手势视频中手势的占比减少。
其中,边缘扩增即对视频帧图像的四个边以添加边框的形式来增大视频帧图像,从而使得手势视频中的手势占比减少。如图4所示,为一个实施例中,对视频帧图像进行边缘扩增前后的示意图。左边为边缘扩增前的图像,右边为边缘扩增后的图像。
步骤306,将扩增前的手势视频和扩增后的手势视频都作为手势识别模型的训练数据。
其中,为了提高手势识别模型对手占比小的手势识别的准确度,通过对已有的手势视频进行边缘扩增处理,得到边缘扩增后的手势视频。通过将扩增前的手势视频和扩增后的手势视频一起作为手势识别模型的训练数据对模型进行训练,提高了对占比小的动态手势的识别。
在一个实施例中,对手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,包括:根据视频帧图像边缘的像素值确定对应的扩增边缘的扩增颜色。根据扩增颜色按照预设的扩增宽度对视频帧图像的边缘进行扩增,得到扩增后的视频帧图像。
其中,为了使得添加的扩增边缘的扩增颜色更加接近背景色,根据视频帧图像边缘的像素值来确定对应的扩增颜色。具体地,一个视频帧图像包括上、下、左、右四条边。然后针对每条边都计算出一个RGB颜色值,为了尽量与原来的背景色接近,可以根据每条边的边缘像素值来计算得到扩增边缘的扩增颜色。在一个实施例中,获取每个边的最靠近边缘的一行或一列像素值,然后将该一行或一列像素值的平均值作为扩增边缘的扩增颜色。
在确定了扩增颜色后,按照预设的扩增宽度对视频帧图像的边缘进行扩增,比如,将扩增宽度设为图像高度的五分之一,上下左右四个边可以都增加同样的宽度,假设原来的图像高为100,计算得到对应的扩增宽度为20,那么,若原来图像宽:高为150:100,则上下左右各扩增高度的五分之一后,得到的图像宽:高为190:140。
在一个实施例中,根据视频帧图像边缘的像素值确定对应的扩增边缘的扩增颜色,包括:获取视频帧图像边缘预设位置的像素值,将预设位置的像素值作为相应的扩增边缘的扩增颜色。
其中,预设位置是指预先选取的位置,在选取用于扩增边缘部分的扩增颜色时,需要尽可能选择接近背景的颜色,而不是人的身体部分的颜色,从而实现扩大背景色的目的。通过观察数据集中的图像,得知人在做动作时,大多数情况下,身体都处于画面中央位置,因此,在为每条边选取扩增颜色时,避免选取中间部分的颜色,可以选择靠近边缘外侧的颜色,比如,选取每条边最外侧四分之一处的颜色作为扩增颜色。当然,也可以设置选取最外侧八分之一处的颜色作为扩增颜色。具体选择的位置可以根据实际场景需要自定义设置。
在一个具体的实施例中,假设RGB图像是由工具openv读取为数组的形式,数组命名为Image,Image的大小为(row,col,3),分别表示数组的行数、列数和通道数,数组中的值对应的即是图像某个像素的RGB值。设图像的上、下、左、右四条边分别为top、bottom、left和right。则计算top对应的扩增颜色color_top时,用到的公式如下:
color_top=Image[0:1,int(col/3):int(col/3)+1] (1)
公式(1)表示的含义为取原始图像第一行的三分之一列处像素的RGB值,作为top边的扩增颜色。同理,计算bottom对应的扩增颜色color_bottom时,用到的公式如下:
color_bottom=Image[row-1:row,int(col/3):int(col/3)+1] (2)
公式(2)表示的含义为取原始图像最后一行的三分之一列处像素的RGB值,作为bottom边的扩增颜色。计算left和right对应的扩增颜色color_left和color_right时,用到的公式如(3)和(4)所示:
color_left=Image[int(row/3):int(row/3)+1,0:1] (3)
color_right=Imageim[int(row/3):int(row/3)+1,col-1:col] (4)
公式(3)表示取原始图像第一列三分之一行处像素的RGB值,作为left边的扩增颜色,公式(4)表示取原始图像最后一列三分之一行处像素的RGB值,作为right边的扩增颜色。每一条边扩增后的部分都与原来的边颜色相近。在本发明中,row/3和col/3中的3为一个设置的参数,可根据实际情况修改为其他值。
在一个实施例中,对手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,包括:获取手势视频中的第一视频帧图像;根据第一视频帧图像中每个边缘的像素值确定相应扩增边缘的像素值,得到第一视频帧图像中四个边缘分别对应的扩增像素值;根据第一视频帧图像中四个边缘分别对应的扩增像素值和预设的扩充宽度确定第一视频帧图像的四个扩增边缘;将手势视频中的其他视频帧图像的四个边缘都扩增为与第一视频帧图像相同的扩增边缘。
其中,考虑到每个手势视频抽帧后会得到多张图像,在计算扩增的边框(即扩增边缘)时候,对于一个动态手势的若干个图像,只根据第一帧的图像计算出四条边对应的颜色,并将计算出的颜色直接应用在后续的多个帧中。原因是在做动作的过程中,背景颜色或亮度会有一些微小变化,比如,可能最初的时候手并未出现在画面中,而是随着动作的进行,手逐渐出现,此时如果每一帧都计算一次,那么每一帧计算出来的RGB颜色值会有所不同,从而导致扩增之后的边框在帧与帧之间存在较大的跳动变化,导致与实际场景差距很大。
上述实施例中的数据增强方法主要应用于动态手势识别,下面的方法可以用于静态手势识别。此外,在一个实施例中,训练得到的手势识别模型既可以用于对动态手势的识别,也可以用于对静态手势的识别。
如图5所示,在一个实施例中,提出了一种用于手势识别的数据增强方法,包括:
步骤502,获取第一手势图像数据,第一手势图像数据包括:第一手势图像和第一手势图像对应的标签。
步骤504,将第一手势图像进行水平镜像翻转,得到第二手势图像。
步骤506,根据第一手势图像对应的标签确定第二手势图像对应的标签。
步骤508,将第二手势图像和第二手势图像对应的标签进行关联存储,得到第二手势图像数据。
步骤510,将第一手势图像数据和第二手势图像数据都作为手势识别模型的训练数据。
上述数据增强方法可以应用于静态手势识别,通过将第一手势图像进行水平镜像翻转,可以得到第二手势图像,并根据第一手势图像对应的标签来设置第二手势图像对应的标签,比如,第一手势图像的标签为:右手拳头,第二手势图像的标签为:右手拳头,从而得到第二手势数据,进而将第二手势数据也作为识别模型的训练数据。该训练得到手势识别模型可以用于对静态手势的识别。
上述手势识别的数据增强方法、装置、计算机设备及存储介质,通过对第一手势图像进行水平镜像翻转,得到第二手势图像,并根据第一手势图像的标签确定第二手势图像对应的标签,将第二手势图像和第二手势图像对应的标签进行关联存储,得到第二手势数据,将第一手势数据和第二手势数据都作为静态手势识别模型的训练数据。上述手势识别的数据增强方法,根据第一手势数据得到第二手势数据,然后将第一手势数据和第二手势数据一起作为训练数据,可以使得训练数据更加全面,从而使得训练得到的模型不仅能够准确预测出第一手势,而且能够准确预测出第二手势。
如图6所示,在一个实施例中,提出了一种用于手势识别的数据增强方法,包括:
步骤602,获取待扩增的手势图像。
步骤604,对手势图像进行边缘扩增,得到边缘扩增后的手势图像,边缘扩增后的手势图像中手势的占比减少。
步骤606,将扩增前的手势图像和扩增后的手势图像都作为手势识别模型的训练数据。
其中,针对单张的手势图像进行边缘扩增,得到扩增后的手势图像,该扩增后的手势图像中手势的占比较少,从而可以提高对于占比较少的手势的识别。
在一个实施例中,对手势图像进行边缘扩增,得到边缘扩增后的手势图像,包括:根据手势图像边缘的像素值确定对应的扩增边缘的扩增颜色;根据扩增颜色按照预设的扩增宽度对手势图像的边缘进行扩增,得到扩增后的手势图像。
在一个实施例中,根据手势图像边缘的像素值确定对应的扩增边缘的扩增颜色,包括:获取手势图像边缘预设位置的像素值,将预设位置的像素值作为相应的扩增边缘的扩增颜色。
如图7所示,在一个实施例中,提出了一种用于手势识别的数据增强装置,包括:
第一获取模块702,用于获取第一手势视频数据,所述第一手势视频数据包括:第一手势视频和所述第一手势视频对应的标签。
翻转模块704,用于将所述第一手势视频中每一视频帧对应的手势图像进行水平镜像翻转,得到第二手势视频。
确定模块706,用于根据所述第一手势视频对应的标签确定所述第二手势视频对应的标签。
关联模块708,用于将所述第二手势视频和所述第二手势视频对应的标签进行关联存储,得到第二手势视频数据。
训练模块710,用于将所述第一手势视频数据和所述第二手势视频数据一起作为动态手势识别模型的训练数据。
如图8所示,在一个实施例中,上述装置还包括:
第二获取模块712,用于获取待扩增的手势视频,所述手势视频中包括多个视频帧图像;
扩增模块714,用于对所述手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,所述边缘扩增后的手势视频中手势的占比减少;
训练模块710还用于将扩增前的手势视频和所述扩增后的手势视频都作为动态手势识别模型的训练数据。
在一个实施例中,扩增模块714还用于根据所述视频帧图像边缘的像素值确定对应的扩增边缘的扩增颜色;根据所述扩增颜色按照预设的扩增宽度对所述视频帧图像的边缘进行扩增,得到扩增后的视频帧图像。
在一个实施例中,扩增模块714还用于获取所述视频帧图像边缘预设位置的像素值,将所述预设位置的像素值作为相应的扩增边缘的扩增颜色。
在一个实施例中,扩增模块714还用于获取所述手势视频中的第一视频帧图像;根据所述第一视频帧图像中每个边缘的像素值确定相应扩增边缘的像素值,得到所述第一视频帧图像中四个边缘分别对应的扩增像素值;根据所述第一视频帧图像中四个边缘分别对应的扩增像素值和预设的扩充宽度确定所述第一视频帧图像的四个扩增边缘;将所述手势视频中的其他视频帧图像的四个边缘都扩增为与所述第一视频帧图像相同的扩增边缘。
如图9所示,在一个实施例中,提出了一种用于手势识别的数据增强装置,包括:
图像获取模块902,用于获取第一手势图像数据,所述第一手势图像数据包括:第一手势图像和所述第一手势图像对应的标签;
图像翻转模块904,用于将所述第一手势图像进行水平镜像翻转,得到第二手势图像;
标签确定模块906,用于根据所述第一手势图像对应的标签确定所述第二手势图像对应的标签;
图像标签关联模块908,用于将所述第二手势图像和所述第二手势图像对应的标签进行关联存储,得到第二手势图像数据;
模型数据模块910,用于将所述第一手势图像数据和所述第二手势图像数据都作为手势识别模型的训练数据。
在一个实施例中,提出了一种用于手势识别的数据增强装置还包括:
扩增模块,用于获取待扩增的手势图像,对所述手势图像进行边缘扩增,得到边缘扩增后的手势图像,所述边缘扩增后的手势图像中手势的占比减少;将扩增前的手势图像和所述扩增后的手势图像都作为手势识别模型的训练数据。
图10示出了一个实施例中计算机设备的内部结构图。该计算机设备具体可以是终端,也可以是服务器。如图10所示,该计算机设备包括通过系统总线连接的处理器、存储器和网络接口。其中,存储器包括非易失性存储介质和内存储器。该计算机设备的非易失性存储介质存储有操作系统,还可存储有计算机程序,该计算机程序被处理器执行时,可使得处理器实现上述的用于动态手势识别的数据增强方法。该内存储器中也可储存有计算机程序,该计算机程序被处理器执行时,可使得处理器执行上述的用于动态手势识别的数据增强方法。本领域技术人员可以理解,图10中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
在一个实施例中,提出了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:获取第一手势视频数据,所述第一手势视频数据包括:第一手势视频和所述第一手势视频对应的标签;将所述第一手势视频中每一视频帧图像进行水平镜像翻转,得到第二手势视频;根据所述第一手势视频对应的标签确定所述第二手势视频对应的标签;将所述第二手势视频和所述第二手势视频对应的标签进行关联存储,得到第二手势视频数据;将所述第一手势视频数据和所述第二手势视频数据都作为动态手势识别模型的训练数据。
在一个实施例中,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:获取待扩增的手势视频,所述手势视频中包括多个视频帧图像;对所述手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,所述边缘扩增后的手势视频中手势的占比减少;将扩增前的手势视频和所述扩增后的手势视频都作为动态手势识别模型的训练数据。
在一个实施例中,所述对所述手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,包括:根据所述视频帧图像边缘的像素值确定对应的扩增边缘的扩增颜色;根据所述扩增颜色按照预设的扩增宽度对所述视频帧图像的边缘进行扩增,得到扩增后的视频帧图像。
在一个实施例中,所述根据所述视频帧图像边缘的像素值确定对应的扩增边缘的扩增颜色,包括:获取所述视频帧图像边缘预设位置的像素值,将所述预设位置的像素值作为相应的扩增边缘的扩增颜色。
在一个实施例中,所述对所述手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,包括:获取所述手势视频中的第一视频帧图像;根据所述第一视频帧图像中每个边缘的像素值确定相应扩增边缘的像素值,得到所述第一视频帧图像中四个边缘分别对应的扩增像素值;根据所述第一视频帧图像中四个边缘分别对应的扩增像素值和预设的扩充宽度确定所述第一视频帧图像的四个扩增边缘;将所述手势视频中的其他视频帧图像的四个边缘都扩增为与所述第一视频帧图像相同的扩增边缘。
在一个实施例中,提出了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:获取第一手势图像数据,所述第一手势图像数据包括:第一手势图像和所述第一手势图像对应的标签;将所述第一手势图像进行水平镜像翻转,得到第二手势图像;根据所述第一手势图像对应的标签确定所述第二手势图像对应的标签;将所述第二手势图像和所述第二手势图像对应的标签进行关联存储,得到第二手势图像数据;将所述第一手势图像数据和所述第二手势图像数据都作为手势识别模型的训练数据。
在一个实施例中,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:获取待扩增的手势图像;对所述手势图像进行边缘扩增,得到边缘扩增后的手势图像,所述边缘扩增后的手势图像中手势的占比减少;将扩增前的手势图像和所述扩增后的手势图像都作为手势识别模型的训练数据。
在一个实施例中,提出了一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行以下步骤:获取第一手势视频数据,所述第一手势视频数据包括:第一手势视频和所述第一手势视频对应的标签;将所述第一手势视频中每一视频帧图像进行水平镜像翻转,得到第二手势视频;根据所述第一手势视频对应的标签确定所述第二手势视频对应的标签;将所述第二手势视频和所述第二手势视频对应的标签进行关联存储,得到第二手势视频数据;将所述第一手势视频数据和所述第二手势视频数据都作为动态手势识别模型的训练数据。
在一个实施例中,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:获取待扩增的手势视频,所述手势视频中包括多个视频帧图像;对所述手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,所述边缘扩增后的手势视频中手势的占比减少;将扩增前的手势视频和所述扩增后的手势视频都作为动态手势识别模型的训练数据。
在一个实施例中,所述对所述手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,包括:根据所述视频帧图像边缘的像素值确定对应的扩增边缘的扩增颜色;根据所述扩增颜色按照预设的扩增宽度对所述视频帧图像的边缘进行扩增,得到扩增后的视频帧图像。
在一个实施例中,所述根据所述视频帧图像边缘的像素值确定对应的扩增边缘的扩增颜色,包括:获取所述视频帧图像边缘预设位置的像素值,将所述预设位置的像素值作为相应的扩增边缘的扩增颜色。
在一个实施例中,所述对所述手势视频中每个视频帧图像进行边缘扩增,得到边缘扩增后的手势视频,包括:获取所述手势视频中的第一视频帧图像;根据所述第一视频帧图像中每个边缘的像素值确定相应扩增边缘的像素值,得到所述第一视频帧图像中四个边缘分别对应的扩增像素值;根据所述第一视频帧图像中四个边缘分别对应的扩增像素值和预设的扩充宽度确定所述第一视频帧图像的四个扩增边缘;将所述手势视频中的其他视频帧图像的四个边缘都扩增为与所述第一视频帧图像相同的扩增边缘。
在一个实施例中,提出了一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行以下步骤:获取第一手势图像数据,所述第一手势图像数据包括:第一手势图像和所述第一手势图像对应的标签;将所述第一手势图像进行水平镜像翻转,得到第二手势图像;根据所述第一手势图像对应的标签确定所述第二手势图像对应的标签;将所述第二手势图像和所述第二手势图像对应的标签进行关联存储,得到第二手势图像数据;将所述第一手势图像数据和所述第二手势图像数据都作为手势识别模型的训练数据。
在一个实施例中,所述计算机程序被所述处理器执行时,使得所述处理器执行以下步骤:获取待扩增的手势图像;对所述手势图像进行边缘扩增,得到边缘扩增后的手势图像,所述边缘扩增后的手势图像中手势的占比减少;将扩增前的手势图像和所述扩增后的手势图像都作为手势识别模型的训练数据。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 用于手势识别的数据增强方法、装置、计算机设备及存储介质
- 数据增强方法、装置、计算设备及计算机存储介质