一种代码补全方法、系统、存储介质及计算机程序产品
文献发布时间:2023-06-19 13:46:35
技术领域
本发明涉及软件开发技术领域,特别是一种代码补全方法、系统、存储介质及计算机程序产品。
背景技术
智能代码补全是下一代智能化IDE研发的必备组件。在IDE中,代码补全组件根据开发者已经编写的代码和当前光标的位置提供下一个可能的标识符选项。在智能化的浪潮下,现有的智能代码补全方法纷纷转向基于神经语言模型的方法。这种基于统计学习的方法,由Hindle等人等研究启发,将编程语言视为一种语言,然后通过大量的代码语料训练语言模型。然而,这种基于语言模型的方法,无法处理OOV(out of vocabulary)问题。在代码中,由于新词汇和稀有词汇的比例远远高于自然语言,导致OOV问题在代码补全中对模型性能的影响更大,限制了这些模型在代码补全上的能力。
现有的匿名化过程是基于整个语料的匿名化,通过统计语料中各个词语出现的次数,按出现频率从大到小排序,然后依次分配一个匿名化的ID。全局语料由于词表大小的限制,无法容纳全部的词汇,因此对新词汇无法进行预测。而对稀有词汇,全局语料由于计算效率的限制,只能考虑在全局的高频词,无法把所有的词汇纳入到计算范围,但某些稀有词汇是局部的高频词、全局的稀有词,因此全局语料无法有效的处理稀有词汇。
发明内容
本发明所要解决的技术问题是,针对现有技术不足,提供一种代码补全方法、系统、存储介质及计算机程序产品,有效的处理稀有词汇。
为解决上述技术问题,本发明所采用的技术方案是:一种代码补全方法,包括以下步骤:
S1、对代码化片段进行预处理,将预处理后的代码化片段作为非匿名化模型的输入,得到第一预测结果;判断所述第一预测结果是否为标识符UNK,若否,则结束;否则,进入S2;
S2、将匿名化的代码作为匿名化模型的输入,得到第二预测结果。
本发明设置了匿名化的过程,从而可以有效处理OOV词(稀有词汇),提高了预测准确率。
步骤S1中,所述非匿名化模型的训练过程包括:
1)搜集代码Code_o;
2)对代码Code_o进行预处理,得到训练用的语料Code_c;
3)将所述训练用的语料Code_c作为代码补全模型的输入,得到所述非匿名化模型。
非匿名化模型的训练具有语料好获取,模型易训练的特点。
步骤S1中,所述第一预测结果的获取过程包括:
A)对已有的代码片段Code_s进行预处理,得到预处理后的代码片段Code_n;
B)将处理后的代码Code_n作为非匿名化模型的输入,将非匿名化模型输出的概率最高的结果作为第一预测结果。
本发明的非匿名化模型可以使用任意现有的代码补全模型,保持框架的先进性。
步骤S2中,匿名化模型的训练过程包括:
c)搜集代码,并对搜集的代码进行预处理,得到训练语料;
d)利用所述训练语料训练补全代码模型,得到匿名化模型。
匿名化模型是针对OOV问题特地设计和训练的模型,首先它和非匿名化模型的最大不同是,模型的训练数据有一个匿名化的处理。这个处理使得我们训练的模型可以较好的学习到代码的结构,便于对OOV词的预测。
步骤S2中,所述第二预测结果的获取过程包括:
i)将已有的代码片段进行匿名化,得到匿名化的代码;建立匿名化词表,保存从匿名化ID到原始标识符的映射;将所述匿名化的代码作为所述预测模型的输入,将得到的概率最高的结果作为第二预测结果;
ii)判断所述第二预测结果是否在匿名化词表中,若是,则根据匿名化词表查找原始标识符,并输出原始标识符,否则,输出标识符UNK。
本发明中,匿名化模型建立了一个动态变化的词表,实时更新遇到的新词汇,及时预测遇到的词汇。将词表由传统模型的静态词表升级到动态词表,极大的方便了处理代码中的新词汇,也解决了传统模型中无法处理OOV词汇的问题。
本发明还提供了一种代码补全系统,其包括计算机设备;所述计算机设备被配置或编程为用于执行上述方法的步骤。
作为一个发明构思,本发明还提供了一种计算机可读存储介质,其包括运行于计算机设备内的程序;所述程序被配置或编程为用于执行上述方法的步骤。
与现有技术相比,本发明所具有的有益效果为:本发明充分利用了代码的特性——代码的功能不变性,来解决代码补全中的OOV问题。本发明的代码补全方法通过匿名化和建立动态的词表能够高效的处理OOV词中的稀有词和新词,本发明的方法通用性强,可以在如LSTM,Transformer等基于深度语言模型的方法上使用。
附图说明
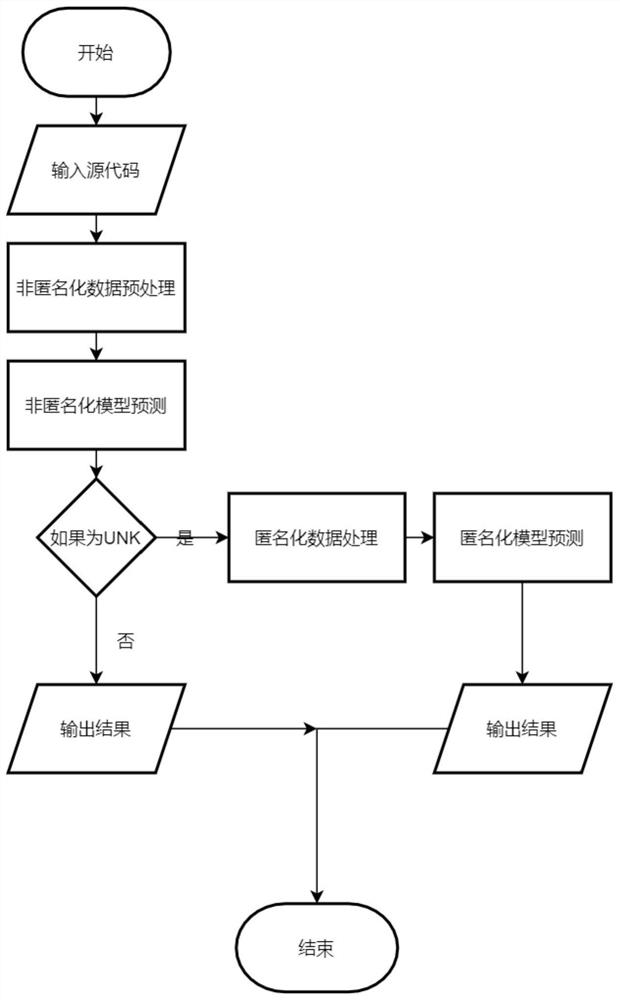
图1为本发明实施例方法原理框图;
图2为本发明实施例稀有词的预测过程。
具体实施方式
本发明提出使用名称为AOOV的框架来解决代码补全中的OOV问题。AOOV中的A指的是匿名化。AOOV框架主要由3个部分组成:非匿名化模型,匿名化模型以及匿名化和非匿名化模型的融合算法。整体过程如图1所示。本发明将源码分别输入到非匿名化模型和匿名化模型中,各自得到各自的结果,然后用融合算法获取最终的结果。在AOOV中,所有的组件都是可替换的。
非匿名化模型和匿名化模型的主要区别是对代码的处理方式不同,这两种模型可以用同样的语言模型,也可以用不同的语言模型。非匿名化模型通过统计代码中标识符的个数,制作词表,再作为语言模型的输入。匿名化模型将原有代码中标识符匿名化后,制作词表,再作为语言模型的输入。由于非匿名化的语言模型和匿名化的语言模型不共享词表,各自预测的结果对方也无法理解。因此,需要在这两种模型之间构建一个桥梁,让这两种模型可以沟通和交流。这个桥梁即匿名化和非匿名化语言模型的融合算法。非匿名化模型是已有的代码补全模型,因此,本发明只专注于匿名化模型。
考虑如下的三个代码文件
#File 1
class Person:
def__init__(self,name,age,gender):
self.name=name
self.age=age
self.gender=gender
#File 2
class DataIterator:
def__init__(self,data_stream,request_iterator,as_dict):
self.data_stream=data_stream
self.request_iterator=request_iterator
self.as_dict=as_dict
#File 3
Class Modle:
def__init__(self,input_data,hp,flags):
self.input_data=input_data
self.hp=hp
self.flags=flags
这三个文件的代码都阐述了同一个事情,即定义一个类,其构造函数传入的参数作为类成员变量。假设我们采用现有的方法进行预测,则预测过程如下:首先,统计每个标识符出现的次数。如果统计完成后结果如表1所示。接着,对每个标识符按照出现的次数排序,依次分配ID。然而,在实际的模型中,考虑到计算效率,不得不放弃出现次数较低词。假设模型中的词表使用的词都是语料中出现的次数超过10次的,于是得到了新的词汇表,这种情况下就没有办法预测hp等词。表1到表3展示了原数据的情况。如果采用匿名化的方法,我们先对每个文件进行匿名化出现,然后给每个文件建立一个匿名化的词表。表4到表6展示了匿名化后数据的情况。
表1统计后的详细信息
表2赋予ID后的详细信息
表3丢弃稀有词后的详细信息
表4文件1的匿名化词表
表5文件2的匿名化词表
表6文件3的匿名化词表
#文件1匿名化后
class var1:
def__init__(self,var2,var3,var4):
self.var2=var3
self.var3=var3
self.var4=var4
#文件2匿名化后
class var1:
def__init__(self,var2,var3,var4):
self.var2=var3
self.var3=var3
self.var4=var4
#文件3匿名化后
class var1:
def__init__(self,var2,var3,var4):
self.var2=var3
self.var3=var3
self.var4=var4
匿名化完成后,3个文件的内容就一样了。对模型而言,3个文件的输入一样,预测结果也会是一样的。最后,我们只需要从匿名化ID还原回原标识符,即完成了整个预测过程。
图2以文件2为例,完整的展示了本发明实施例稀有词的预测过程。
匿名化模型训练流程如下:
1.从GitHub搜集代码Code
2.对代码进行预处理,得到模型的训练语料Code
3.训练匿名化模型,该模型可以是现有的任意代码补全模型(如LSTM,Transformer),得到模型Model
匿名化模型预测流程如下:
1.将已有的代码片段Code
2.将匿名化的代码Code
3.预测会得到多个项,不同的项有不同的概率,将匿名化模型概率最高的项作为预测结果Ret
4.如果预测结果Ret
5.否则输出UNK;
非匿名化模型的训练流程如下:
1.从GitHub搜集代码Code_o;
2.对代码进行预处理(即对代码进行词法分析,语法分析,建成抽象语法树,最后将树展平,得到一个序列,见Li J,Wang Y,Lyu M R,et al.Code completion with neuralattention and pointer networks[J].arXiv preprint arXiv:1711.09573,2017.;LiuF,Li G,Wei B,et al.A self-attentional neural architecture for code completionwith multi-task learning[C]//Proceedings of the 28th International Conferenceon Program Comprehension.2020:37-47.),得到训练用的语料Code_c;
3.训练非匿名化模型,该模型可以是现有的任意代码补全模型(如LSTM,Transformer),得到模型Model_n。
非匿名化模型的预测流程如下:
1.对已有的代码片段Code_s进行预处理,得到Code_n,处理方式同训练过程中的预处理;
2.将处理后的代码Code_n作为非匿名化模型Model_n的输入,用非匿名化模型进行预测;
3.预测会得到多个项,不同的项有不同的概率,将非匿名化模型概率最高的项作为预测结果Identifier
4.输出Identifier
本发明实施例AOOV-POFA预测流程如下:
1.已有代码片段Code_s,经过处理后得到非匿名化模型的输入Code_in,匿名化模型的输入Code_ia,处理方式同模型各自预处理方式;
2.使用非匿名化模型Model
3.如果预测结果不为UNK,输出Identifier
4.否则,使用匿名化模型Model
OOV问题主要由两个原因引起,稀有词汇和新词汇。稀有词汇的问题正如刚刚3个文件的例子中所说的,匿名化屏蔽了词汇的差异,让在预料库级别的低频词汇变成了源码级别的高频词汇。新词汇的问题,假设我们已经用之前的语料训练好了匿名化模型,如果来了新的代码片段,如
#文件4
class Foo:
def__init__(self,bar,new_word_1,new_word_2):
self.bar=bar
self.new_word_1=new_word_1
self.new_word_2=new_word_2
假设新词汇是new_word_1,new_word_2,如果用传统的神经语言模型,是无法对这两个词进行预测的。但是,如果采用匿名化的模型,就有可能预测出来。本发明首先对上面的代码做匿名化。
#匿名化后的文件4
class var1:
def__init__(self,var2,var3,var4):
self.var2=var3
self.var3=var3
self.var4=var4
这样,源码就变成和之前的文件一样了。在这种情况下,模型就非常容易进行预测。然后本发明把预测出来的词汇进行还原,最终新词汇就被预测出来了。
关于无效预测问题:
在使用匿名化模型的时候,匿名词表是动态建立的。但是,在模型训练的时候,词表是固定大小的,由此产生无效预测的问题。考虑如下的例子,当我们写到
#文件5
class Foo:
def__init__(self,bar,___???___
这时,匿名词表为表7所示。
表7匿名词表
然而,此时模型是可以预测出`var3`的。由于词表中没有`var3`,无法还原出其真实的标识符是什么。因此,这样的预测就无意义,无法对代码补全提供实质性的建议。
为了融合处理匿名化语言模型和非匿名化语言模型的预测结果,我们提出了一个简单直接的融合算法POFA,具体实现过程包括:
1.使用非匿名化的语言模型进行预测;
2.如果预测的结果是非UNK,结束;
3.如果预测的结果是UNK,使用匿名化的语言模型进行预测;
4.输出预测结果,结束。
当预测OOV词request_iterator时,首先匿名化模型和非匿名化模型各自得到他们的预测结果。然后本发明基于非匿名化模型的预测结果选择最终的预测结果。如果非匿名化模型的预测结果是UNK,本发明选择匿名化模型的结果。否则,本发明采用非匿名化模型的结果。通过这样的一个融合的方式,本发明可以同时结合匿名化模型和非匿名化模型的优点。
本发明实施例对比实验如下。
本发明实施例基于LSTM和Transformer这两大类深度学习模型做了对比实验,实验结果如表8和表9所示。
实验1分别用不同的深度学习模型替换方法中的非匿名化模型和匿名化模型。从实验结果可以看出,无论是哪种模型,对OOV词的预测效果都不错。
表8实验1结果
实验2对比其他的OOV预测方法
本发明方法和Pointer Mixture Network的方法进行对比,其他方法是一种基于复制方法。从实验结果可以看到,在Python和JavaScript两个数据集上,本发明的方法都远远好于基于复制的方法。
表9实验2结果