一种大数据的数据筛选模型及方法
文献发布时间:2023-06-19 11:16:08
技术领域
本发明属于大数据技术领域,具体涉及一种大数据的数据筛选模型及方法。
背景技术
大数据,IT行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
但是目前市场上的大数据数据筛选方法无法及时更新,筛选模型反馈的准确性和效率较低。
发明内容
本发明的目的在于提供一种大数据的数据筛选模型及方法,以解决上述背景技术中提出的无法及时更新,筛选模型反馈的准确性和效率较低的问题。
为实现上述目的,本发明提供如下技术方案:一种大数据的数据筛选方法,包括如下步骤:
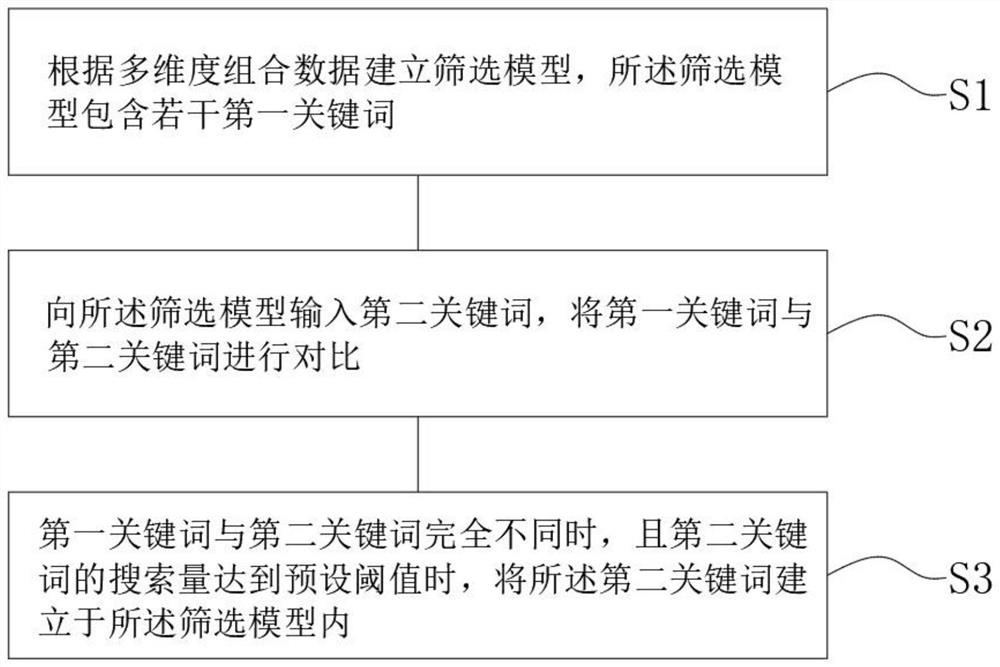
S1.根据多维度组合数据建立筛选模型,所述筛选模型包含若干第一关键词;
S2.向所述筛选模型输入第二关键词,将第一关键词与第二关键词进行对比;
S3.当第一关键词与第二关键词完全不同时,且第二关键词的搜索量达到预设阈值时,将所述第二关键词建立于所述筛选模型内。
优选的,所述的向所述筛选模型输入第二关键词,将第一关键词与第二关键词进行对比之后还包括步骤:
S21.当第一关键词与第二关键词局部不同时,且第二关键词的搜索量达到预设阈值时,将所述第二关键词与第一关键词的差异词建立于所述筛选模型内。
优选的,所述的向所述筛选模型输入第二关键词,将第一关键词与第二关键词进行对比之后还包括步骤:
S22.当第一关键词与第二关键词相同时,向所述第一关键词输出对应的目标。
优选的,所述的根据多维度组合数据建立筛选模型,所述筛选模型包含若干第一关键词之前还包括步骤:
S11.建立第一关键词与目标的映射关系。
优选的,所述的当第一关键词与第二关键词完全不同时,且第二关键词的搜索量达到预设阈值时,将所述第二关键词建立于所述筛选模型内之前还包括步骤:
S31.设置搜索量阈值。
优选的,所述多维度组合数据包括铁路系统平台中乘车旅客总人数、列车发车总趟数、铁路站点数目、运行列车运行时长以及运行列车运行站点。
优选的,所述筛选模型包括:
获取单元,获取所有样本中的样本数据;
建立单元,用于建立筛选模型。
优选的,所述筛选模型还包括:
输入单元:用于输入关键词;
对比单元:用于对比关键词。
优选的,所述筛选模型还包括:
处理单元:用于处理关键词;
映射单元:用于映射关键词与目标。
优选的,所述筛选模型还包括:
添加单元:用于添加关键词至筛选模型内部。
与现有技术相比,本发明的有益效果是:
本发明通过对比搜索关键词和筛选模型内关键词进行对比,从而让筛选模型可以及时反馈,并且可以将差异词及时添加与筛选模型内,让筛选模型内的关键词可以及时更新,提高了筛选模型反馈的准确性和效率。
附图说明
图1为本发明的流程图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1所示,本发明提供如下技术方案:实施例一:一种大数据的数据筛选方法,包括如下步骤:
S1.根据多维度组合数据建立筛选模型,所述筛选模型包含若干第一关键词;
S2.向所述筛选模型输入第二关键词,将第一关键词与第二关键词进行对比;
S3.当第一关键词与第二关键词完全不同时,且第二关键词的搜索量达到预设阈值时,将所述第二关键词建立于所述筛选模型内。
进一步的,所述的向所述筛选模型输入第二关键词,将第一关键词与第二关键词进行对比之后还包括步骤:
S21.当第一关键词与第二关键词局部不同时,且第二关键词的搜索量达到预设阈值时,将所述第二关键词与第一关键词的差异词建立于所述筛选模型内。
进一步的,所述的向所述筛选模型输入第二关键词,将第一关键词与第二关键词进行对比之后还包括步骤:
S22.当第一关键词与第二关键词相同时,向所述第一关键词输出对应的目标。
进一步的,所述的根据多维度组合数据建立筛选模型,所述筛选模型包含若干第一关键词之前还包括步骤:
S11.建立第一关键词与目标的映射关系。
进一步的,所述的当第一关键词与第二关键词完全不同时,且第二关键词的搜索量达到预设阈值时,将所述第二关键词建立于所述筛选模型内之前还包括步骤:
S31.设置搜索量阈值。
进一步的,所述多维度组合数据包括铁路系统平台中乘车旅客总人数、列车发车总趟数、铁路站点数目、运行列车运行时长以及运行列车运行站点。
进一步的,所述筛选模型包括:
获取单元,获取所有样本中的样本数据;
建立单元,用于建立筛选模型。
进一步的,所述筛选模型还包括:
输入单元:用于输入关键词;
对比单元:用于对比关键词。
进一步的,所述筛选模型还包括:
处理单元:用于处理关键词;
映射单元:用于映射关键词与目标。
更进一步的,所述筛选模型还包括:
添加单元:用于添加关键词至筛选模型内部。
实施例二:所述多维度组合数据包括目标人群籍贯、目标人群年龄、目标人群民族。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种大数据的数据筛选模型及方法
- 一种应用于业务大数据的数据处理方法及大数据服务器