人流量统计方法及相关产品
文献发布时间:2023-06-19 11:39:06
技术领域
本申请图像处理技术领域,具体涉及一种人流量统计方法及相关产品。
背景技术
行人计数是用于评价人防安全的重要指标之一,在商场,机场,地铁和火车站有对人流量统计的需求。目前,主要基于传统图像处理的方法如使用adaboost(迭代算法)方式或者基于人脸检测的方法,但是,传统图像及处理方式鲁棒性较差,而基于人脸检测的方法对于人流量大、人脸密集或者人脸遮挡严重的场景的检测不准确,从而导致人流量的统计不够准确。
发明内容
本申请实施例提供了一种人流量统计方法及相关产品,有利于提高人流量统计效率。
本申请实施例第一方面提供了一种人流量统计方法,包括:
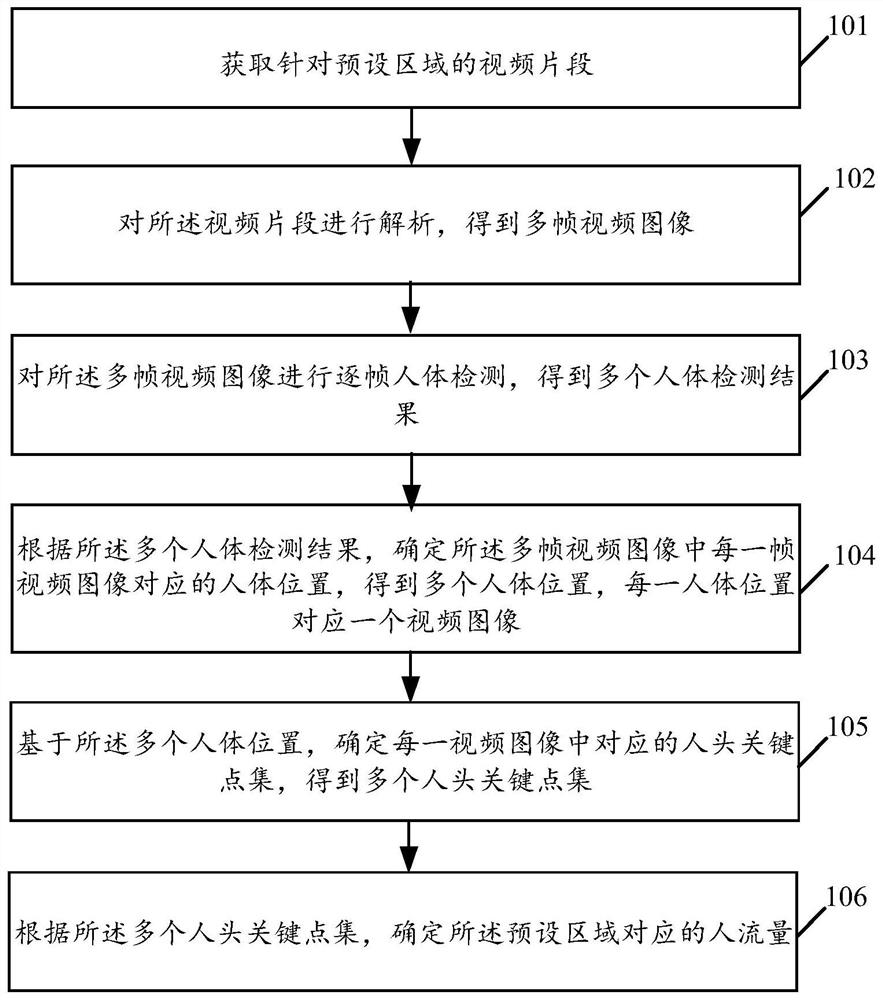
获取针对预设区域的视频片段;
对所述视频片段进行解析,得到多帧视频图像;
对所述多帧视频图像进行逐帧人体检测,得到多个人体检测结果;
根据所述多个人体检测结果,确定所述多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像;
基于所述多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集;
根据所述多个人头关键点集,确定所述预设区域对应的人流量。
本申请实施例第二方面提供了一种人流量统计装置,包括:获取单元、解析单元、检测单元和确定单元,其中,
所述获取单元,用于获取针对预设区域的视频片段;
所述解析单元,用于对所述视频片段进行解析,得到多帧视频图像;
所述检测单元,用于对所述多帧视频图像进行逐帧人体检测,得到多个人体检测结果;
所述确定单元,用于根据所述多个人体检测结果,确定所述多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像;
所述确定单元,还用于基于所述多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集;
所述确定单元,还用于根据所述多个人头关键点集,确定所述预设区域对应的人流量。
本申请第三方面提供了一种服务器,包括:处理器和存储器;以及一个或多个程序,所述一个或多个程序被存储在所述存储器中,并且被配置成由所述处理器执行,所述程序包括用于如第一方面中所描述的部分或全部步骤的指令。
第四方面,本申请实施例提供了一种计算机可读存储介质,其中,所述计算机可读存储介质用于存储计算机程序,其中,所述计算机程序使得计算机执行如本申请实施例第一方面中所描述的部分或全部步骤的指令。
第五方面,本申请实施例提供了一种计算机程序产品,其中,所述计算机程序产品包括存储了计算机程序的非瞬时性计算机可读存储介质,所述计算机程序可操作来使计算机执行如本申请实施例第一方面中所描述的部分或全部步骤。该计算机程序产品可以为一个软件安装包。
实施本申请实施例,具有如下有益效果:
可以看出,通过本申请实施例所描述的人流量统计方法及相关产品,应用于服务器,可获取针对预设区域的视频片段,对视频片段进行解析,得到多帧视频图像,对多帧视频图像进行逐帧人体检测,得到多个人体检测结果,根据多个人体检测结果,确定多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像,基于多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集,根据多个人头关键点集,确定预设区域对应的人流量,如此,可先检测人体,再确定人头关键点集,通过上述两个维度的信息,确定预设区域对应的人流量,有利于提高人流量的统计效率。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1A是本申请实施例提供的一种人流量统计方法的实施例流程示意图;
图1B是本申请实施例提供的一种特征图的裁剪方法的结构示意图;
图1C是本申请实施例提供的一种人头检测方法的系统结构示意图;
图2是本申请实施例提供的一种人流量统计方法的实施例流程示意图;
图3是本申请实施例提供的一种人流量统计装置的实施例结构示意图;
图4是本申请实施例提供的一种服务器的实施例结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请的说明书和权利要求书及所述附图中的术语“第一”、“第二”、“第三”和“第四”等是用于区别不同对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置展示该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
为了更好的理解本申请实施例提供的一种人流量统计方法及相关产品,下面先对本申请实施例适用的人流量统计方法的系统构架进行描述。
本申请实施例所描述服务器可以包括但不限于后台服务器、组件服务器、客流量统计系统服务器或客流量统计软件服务器等,上述仅是举例,而非穷举,包含但不限于上述装置。
需要说明的是,上述服务器可与多个摄像头连接,每一摄像头均可用于抓拍视频图像,每一摄像头均可有一个与之对应的位置标记,或者,可有一个与之对应的编号。通常情况下,摄像头可设置在公共场所,公共场所可以为以下至少一种:学校、博物馆、十字路口、步行街、街道、写字楼、车库、机场、医院、地铁站、车站、公交站台、超市、酒店、娱乐场所等等。摄像头在拍摄到视频图像后,可将该视频图像保存到服务器的存储器中。存储器中可存储有多个图像库,每一图像库可包含不同区域的不同视频图像,当然,每一图像库还可以用于存储一个区域的视频图像或者某个指定摄像头拍摄的视频图像。
请参阅图1A,为本申请实施例提供的一种人流量统计方法的实施例的流程示意图。本实施例中所描述的人流量统计方法,应用于服务器,可包括以下步骤:
101、获取针对预设区域的视频片段。
其中,上述预设区域可为用户自行设置或者系统默认,在此不作限定,上述预设区域可包括以下至少一种:学校、博物馆、十字路口、步行街、写字楼、车库、机场、医院等等,在此不作限定;上述预设区域内可包括至少一个摄像头,服务器可获取至少一个摄像头中的任意一个指定摄像头在预设时段内拍摄的视频片段。
102、对所述视频片段进行解析,得到多帧视频图像。
其中,服务器可对上述摄像头拍摄得到的视频片段进行解析,得到多帧视频图像,具体实现中,可读取上述视频片段中的每一帧,并转换为视频图像输出,得到多帧视频图像。
103、对所述多帧视频图像进行逐帧人体检测,得到多个人体检测结果。
其中,由于上述多帧视频图像中可能包括人头、人脸或者人体图像,但是在有些情况下,人脸部位会被遮挡或者未拍入视频片段中,而且,并非每帧视频图像中均包括人体图像,因此,可针对上述多帧视频图像中每一帧视频图像逐帧进行人体检测,从而,得到上述多帧视频图像中每一视频图像对应的人体检测结果,得到多个人体检测结果,该人体检测结果可指图像中包括人体的视频图像。
在一种可能的示例中,上述步骤103,对所述多帧视频图像进行逐帧人体检测,得到多个人体检测结果,可包括如下步骤:
31、对所述多帧视频图像中每一视频图像进行特征提取,得到多个特征图,其中,每一视频图像对应一个特征图;
32、将所述多个特征图输入预设第一神经网络模型中进行人体检测,得到多个人体检测结果。
其中,可针对不同的目的预设不同的神经网络模型,可预设第二神经网络模型,该预设第二神经网络模型可用于进行图像特征提取,可针对上述多帧视频图像中每一帧视频图像分别在上述预设第一神经网络模型中进行特征提取,以提取每一帧视频图像中的图像信息,上述人体图像中可包括人脸图像、人头图像、肢体图像等等,如此,可得到多个特征图,每一特征图可对应一帧视频图像,举例来说,若预设的第二神经网络模型为卷积神经网络,则上述特征图可由特征提取时的卷积神经网络中由视频图像按照预设方式映射得到的,因此,特征图对应的每层卷积得到的图像特征之间的联系会更紧密,同时得到的图像特征也会更加的清晰。
进一步地,上述预设第一神经网络模型可为用户自行设置或者系统默认,在此不作限定,例如,上述预设神经网络模型可为卷积神经网络模型,该预设第一神经网络模型不同于上述预设第二神经网络模型,该预设第一神经网络模型的目的可进行人体检测,由于上述特征图中的图像信息可能包括人体图像、景色图像等等,因此,可将上述多个特征图输入上述预设第一神经网络模型中进行人体检测,从而得到多个人体检测结果,如此,可基于不同特征的提取预设不同功能的神经网络模型,以提高人体检测的准确性。
其中,上述特征提取的方法可包括以下至少一种:线性预测分析(LinearPrediction Coefficients,LPC)、感知线性预测系数(Perceptual Linear Predictive,PLP)、Tandem特征和Bottleneck特征、基于滤波器组的Fbank特征(Filterbank)、线性预测倒谱系数(Linear Predictive Cepstral Coefficient,LPCC)、梅尔频率倒谱系数(MelFrequency Cepstral Coefficent,MFCC)等等,在此不作限定。
104、根据所述多个人体检测结果,确定所述多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像。
其中,上述人体检测的目的是为了确定每一帧视频图像中人体的位置,因此,可基于上述多个人体检测结果,确定多帧视频图像中每一帧视频图像的人体位置,得到多个人体位置,每一人体位置可对应一个视频图像,每一视频图像中可包括至少一个人体位置。
可选地,上述根据所述多个人体检测结果,确定所述多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置的步骤可包括以下方法:可基于上述多个人体检测结果,将上述多帧视频图像中每一帧视频图像划分为至少一个人体区域图像,得到多个人体区域图像,其中,每一视频图像可对应至少一个人体区域图像,基于上述多个人体区域图像,确定每一人体区域图像对应的图像坐标,得到多个图像坐标集,每一人体区域图像对应一个图像坐标集,基于上述多个图像坐标集,确定上述多帧视频图像中每一帧视频图像的人体位置,得到多个人体位置。
其中,在得到多帧视频图像对应的多个人体检测结果以后,可初步从多帧视频图像中定位人体的位置,则可基于上述多个人体检测结果,对上述多帧视频图像中每一帧视频图像中的人体区域图形进行标定,也就是划分出多个人体区域图像,如此,可进一步的精确定位到人体的具体位置,可确定每一人体区域图像对应的图像坐标,该图像坐标可为图像像素坐标或者可预设图像坐标系,以得到人体中每一像素的位置,从而得到每一帧视频图像中人体对应的人体位置,得到多个人体位置,如此,有利于精确定位人体的位置。
105、基于所述多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集。
其中,通常情况下,当视频图像中包括人体图像时,一般也包括人头图像,因此,可在确定了上述多帧视频图像对应的多个人体图像以后,基于上述多个人体位置,确定每一帧视频图像中对应的人头关键点集,每一帧视频图像可对应一个人头关键点集,从而得到多个人头关键点集。
在一种可能的示例中,上述步骤105,基于所述多个人体位置,确定每一视频图像中对应的人头关键点集,可包括如下步骤:
51、基于所述多个人体位置,在所述多个特征图中确定所述多个人体位置对应的多个目标位置,其中,每一人体位置对应一个特征图中的一个目标位置;
52、基于所述多个目标位置,对所述多个特征图中每一特征图进行裁剪,得到多个子特征图集,每一子特征图集中包括所述多个目标位置分别对应的多个子特征图;
53、对所述多个子特征图集中每一子特征图集进行图像融合,得到多个目标特征图,每一目标特征图对应一个子特征图集;
54、对所述多个目标特征图中每一目标特征图进行人头关键点提取,得到每一视频图像对应的人头关键点集。
其中,在确定多帧视频图像中的多个人体位置以后,服务器可基于上述多个人体位置,确定上述多帧视频图像中的人头信息,也就是人头关键点,具体实现中,可基于上述多帧视频图像对应的多个人体位置,确定上述多个特征图中每一人体位置对应的目标位置,得到多个目标位置,如此,可基于多个视频图像中的多个人体位置,确定在多个特征图中的多个人体位置对应的多个目标位置。
进一步地,由于上述多个特征图中包括人体图像和背景图像等等,因此,为了得到每一特征图中确切的人体位置,可基于上述多个特征图中对应的多个人体位置对应的多个目标位置,对上述多个特征图中每一特征图进行裁剪,得到多个子特征图,如此,可得到多个特征图对应的多个子特征图集,每一子特征图中至少包括一个人体图像,每一子特征图集中包括一个特征图所对应的多个子特征图。
再进一步地,可对上述多个子特征图集中的每一子特征图集中的子特征图进行图像融合,得到图像融合以后的多个目标特征图,每一目标特征图对应一个子特征图集,如此,可去除视频图像中的冗余信息,以得到只包括人体图像信息的多个目标特征图,该目标特征图中的特征信息会更加的清楚直接。
最后,由于每一人体图像中可能都存在人头图像,因此,可针对上述多个目标特征图中的每一目标特征图进行人头关键点提取,以得到每一视频图像对应的人头关键点集,上述人头关键点提取的方法可包括以下至少一种:关键点提取的方法可包括以下至少一种:加速稳健特征(Speeded Up Robust Feature,SURF)、尺度不变特征转换(ScaleInvariant Feature Transform,SIFT)、加速分割测试获得特征(Features fromAccelerated Segment Test,FAST)、Harris角点法等等,在此不作限定。
如图1B所示,为一种特征图的裁剪方法的结构示意图,如图中所示,为一张视频图像的特征图的裁剪方法的结构示意图,可针对人体检测结果,确定人体在视频图像中的多个人体位置,进而,根据上述多个人体位置,确定人体在特征图中的多个目标位置,基于特征图中的多个目标位置,将特征图中的人体图像进行裁剪,得到多个子特征图,每一子特征图中可包括人体图像,其中,上述特征图由上述人体检测得到,在上述人体检测的过程中,得到的特征图实则包括了人头检测的初级特征,因此,可使用人体检测得到的特征图进一步的进行人头检测,有利于节省计算量。
106、根据所述多个人头关键点集,确定所述预设区域对应的人流量。
其中,上述人体检测的目的是为了筛选出多帧视频图像中包括人体的图像,该人体图像中也包括人脸图像和人头图像,但是,若基于人脸检测的方法不能处理背向摄像头的人流量统计,因此,可基于上述每一帧视频图像中对应的人头关键点集,确定上述预设区域内的人流量,从而,有利于提高人流量统计的准确性以及效率。
如图1C所示,为一种人头检测方法的系统结构示意图,如图中所示,该图中包括三个预设神经网络模型,分别为预设第一神经网络模型、预设第二神经网络模型和预设第三神经网络模型,上述三种预设神经网络模型的作用是不同的,该结构示意图中仅展示了一张视频图像对应的人头检测方法,多帧视频图像的处理方式与上述一帧视频图像的处理方式相同,在此不再赘述。
具体地,可将视频图像输入预设第二神经网络模型,进行特征提取,以得到该帧视频图像对应的特征图,再通过预设第一神经网络模型进行人体检测,得到人体检测结果,进而,确定视频图像中对应的人体位置,并基于人体检测结果,在上述特征图中确定多个人体位置中每一人体位置对应的目标位置,得到多个目标位置,并基于多个目标位置,将上述特征图进行裁剪,得到多个子特征图,如此,可去除视频图像中不必要的信息,从而去除视频图像中除人体信息以外的冗余信息,再进一步地,可将上述多个子特征图进行图像融合,得到目标特征图,最后经过预设第三神经网络模型对该目标特征图进行人头检测,也就是人头关键点提取,以得到上述特征图对应的人头关键点集,如此,由于上述特征图由上述人体检测得到,在上述人体检测的过程中,得到的特征图实则包括了人头检测的初级特征,因此,可使用人体检测得到的特征图进一步的进行人头检测,有利于节省计算量,并且,有利于提高人头检测的效率,有利于后续的人流量统计的准确性。
在一种可能的示例中,上述步骤106,根据所述多个人头关键点集,确定所述预设区域对应的人流量,可包括如下步骤:
61、根据所述多个人头关键点集,确定所述多帧视频图像中对应的多个目标对象;
62、按照预设标识分配方法,对所述多个目标对象中每一目标对象进行标识分配,得到多个标识信息;
63、基于所述多个标识信息,对所述多个目标对象进行目标跟踪,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹;
64、基于所述多个目标运动轨迹,确定所述预设区域的人流量。
其中,由于上述多个人头关键点集中可能包括多个人对应的人头图像,因此,可基于上述多个人头关键点集,确定多帧视频图像中对应的多个目标对象,每一目标对象唯一,又由于上述多个目标对象出入上述预设区域的时间、次数等等可能不同,因此,可对上述目标对象按照预设标识分配方法进行标识分配,以区分每一目标对象。
此外,上述预设标识分配方法可为用户自行设定或者系统默认,由于出入该预设区域内的目标对象可能是背对或者侧对上述指定摄像头,因此,为了区分每一目标对象,可对每一目标对象进行标识信息分配,得到多个标识信息,如表1所述,为一种标识分配方法。
表1一种标识分配方法
进一步地,可基于上述多个标识信息,对上述多个目标对象进行目标跟踪,目标跟踪的目的是为了确定该目标对象对应的运动轨迹,运动轨迹体现了该目标对象在预设区域内的活动动态情况,因此,可在区分每一目标对象的同时,确定上述多个目标对象对应的多个目标运动轨迹,最后,可基于多个目标运动轨迹,确定上述预设区域内对应的人流量。
在一种可能的示例中,上述步骤61,根据所述多个人头关键点集,确定所述多帧视频图像中对应的多个目标对象,可包括如下步骤:
611、将视频图像i对应的人头关键点集i与视频图像j人头关键点集j进行匹配,得到多个匹配值,其中,每一匹配值对应一帧视频图像,所述视频图像i和所述视频图像j为所述多帧视频图像中任意两帧视频图像;
612、计算所述多个匹配值的均值;
613、若所述均值超过预设阈值,则确定所述人头关键点集i和所述人头关键点集j对应同一个目标对象。
其中,由于在上述多帧视频图像中,可能同一个目标对象会出现于多帧视频图像中,因此,可对上述多帧图像进行去重,得到多个目标对象;上述预设阈值可为用户自行设置或者系统默认,可将每两帧视频图像分别对应的人头关键点集进行两两相互匹配,可得到多组匹配值,根据多组匹配值,得到多个目标对象。
具体实现中,可将视频图像i对应的人头关键点集i与视频图像j人头关键点集j进行匹配,得到多个匹配值,然后,由于每个人头区域图像中的特征点的数目是不同的,为了提高匹配的准确率,因此,可计算上述多个匹配值的均值,若该均值超过预设阈值,则表明其对应的两个视频图像中的人头为同一人,也就是同一目标对象,如此,将每两帧灰度图像分别对应的多个视频图像对应的人头关键点集进行相互匹配,可筛除重复的人头特征点,以得到多个不相同的目标对象。
在一种可能的示例中,上述步骤63,基于所述多个标识信息,对所述多个目标对象进行目标跟踪,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹,可包括如下步骤:
631、基于所述多个标识信息,对所述多帧视频图像中每一帧视频图像进行目标检测,确定每一所述标识信息在所述多帧视频图像中的出现时刻集,得到多个出现时刻集;
632、基于所述多个出现时刻集,确定所述多个标识信息中每一标识信息对应的轨迹状态信息集,得到多个轨迹状态信息集,其中,每一轨迹状态信息集中包括每一标识信息在所述多帧视频图像中对应的多个轨迹状态信息;
633、基于所述多个轨迹状态信息集,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹。
其中,上述轨迹状态信息可包括以下至少一种:高度、速度、位置、纵横比等等,在此不作限定,该轨迹状态信息体现了目标对象对应的标识信息在由多帧视频图像对应的图像坐标系中的轨迹信息,可进一步的说明该目标对象的运动状态。
具体实现中,可针对每一帧视频图像进行多个标识信息的目标检测,以得到每一标识信息在多帧视频图像中对应的出现时刻集,每一出现时刻集中包括多个标识信息其中的一个标识信息在多帧视频图像中的出现时刻,进一步地,可针对上述多帧视频图像构造图像坐标系,并基于上述多个出现时刻集,确定每一标识信息对应的轨迹状态信息集,每一轨迹状态信息集中包括上述标识信息在多帧视频图像中对应的多个轨迹状态信息,如此,可得到多个标识信息对应的多个轨迹状态信息集。
最后,可基于可采用上述轨迹状态信息集中的多个维度的参数去表示上述多个标识信息中每一标识信息对应的目标运动轨迹,以得到多个目标运动轨迹,如此,可根据上述多个出现时刻集去确定每一标识信息对应的多个轨迹状态参数,从而,确定标识信息在多个出现时刻对应的轨迹状态,最终,以得到多个目标运动轨迹,有利于提高运动轨迹确定的准确性。
另外,上述目标检测方法可包括以下至少一种:物体检测(Single Shot Multi-Box Detector,SSD)算法、基于多任务卷积神经网络(Multi-task Convolutional NeuralNetwork,MTCNN)的算法等等,在此不作限定;
可以看出,通过本申请实施例所提供的人流量统计方法,应用于服务器,可获取针对预设区域的视频片段,对视频片段进行解析,得到多帧视频图像,对多帧视频图像进行逐帧人体检测,得到多个人体检测结果,根据多个人体检测结果,确定多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像,基于多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集,根据多个人头关键点集,确定预设区域对应的人流量,如此,可先检测人体,再确定人头关键点集,通过上述两个维度的信息,确定预设区域对应的人流量,有利于提高人流量的统计效率。
与上述一致地,请参阅图2,为本申请实施例提供的一种人流量统计方法的实施例流程示意图。本实施例中所描述的人流量统计方法,包括以下步骤:
201、获取针对预设区域的视频片段。
202、对所述视频片段进行解析,得到多帧视频图像。
203、对所述多帧视频图像中每一视频图像进行特征提取,得到多个特征图,其中,每一视频图像对应一个特征图。
204、将所述多个特征图输入预设第一神经网络模型中进行人体检测,得到多个人体检测结果。
205、根据所述多个人体检测结果,确定所述多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像。
206、基于所述多个人体位置,在所述多个特征图中确定所述多个人体位置对应的多个目标位置,其中,每一人体位置对应一个特征图中的一个目标位置。
207、基于所述多个目标位置,对所述多个特征图中每一特征图进行裁剪,得到多个子特征图集,每一子特征图集中包括所述多个目标位置分别对应的多个子特征图。
208、对所述多个子特征图集中每一子特征图集进行图像融合,得到多个目标特征图,每一目标特征图对应一个子特征图集。
209、对所述多个目标特征图中每一目标特征图进行人头关键点提取,得到每一视频图像对应的人头关键点集得到多个人头关键点集。
210、根据所述多个人头关键点集,确定所述预设区域对应的人流量。
可选地,上述步骤201-步骤210的具体描述可参照图1A所描述的人流量统计方法的对应步骤,在此不再赘述。
可以看出,通过本申请实施例所提供的人流量统计方法,应用于服务器,获取针对预设区域的视频片段,对视频片段进行解析,得到多帧视频图像,对多帧视频图像中每一视频图像进行特征提取,得到多个特征图,其中,每一视频图像对应一个特征图,将多个特征图输入预设第一神经网络模型中进行人体检测,得到多个人体检测结果,根据多个人体检测结果,确定多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像,基于多个人体位置,在多个特征图中确定多个人体位置对应的多个目标位置,其中,每一人体位置对应一个特征图中的一个目标位置,基于多个目标位置,对多个特征图中每一特征图进行裁剪,得到多个子特征图集,每一子特征图集中包括多个目标位置分别对应的多个子特征图,对多个子特征图集中每一子特征图集进行图像融合,得到多个目标特征图,每一目标特征图对应一个子特征图集,对多个目标特征图中每一目标特征图进行人头关键点提取,得到每一视频图像对应的人头关键点集得到多个人头关键点集,根据多个人头关键点集,确定预设区域对应的人流量,如此,在上述人体检测的过程中,实则包括了人头检测的初级特征,因此,可使用人体检测得到的特征图进一步的进行人头检测,有利于节省计算量,最后通过人头和人体两个特征信息,确定预设区域内的人流量,有利于提高人流量的统计正确率。
与上述一致地,以下为实施上述人流量统计方法的装置,具体如下:
请参阅图3,为本申请实施例提供的一种人流量统计装置的实施例结构示意图。本实施例中所描述的人流量统计装置,包括:获取单元301、解析单元302、检测单元303和确定单元304,具体如下:
所述获取单元301,用于获取针对预设区域的视频片段;
所述解析单元302,用于对所述视频片段进行解析,得到多帧视频图像;
所述检测单元303,用于对所述多帧视频图像进行逐帧人体检测,得到多个人体检测结果;
所述确定单元304,用于根据所述多个人体检测结果,确定所述多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像;
所述确定单元304,还用于基于所述多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集;
所述确定单元304,还用于根据所述多个人头关键点集,确定所述预设区域对应的人流量。
其中,上述获取单元301可用于实现上述步骤101所描述的方法,解析单元302可用于实现上述步骤102所描述的方法,检测单元303可用于实现上述步骤103所描述的方法,确定单元304可用于实现上述步骤104、步骤105和步骤106所描述的方法,以下如此类推。
可以看出,通过本申请实施例所描述的人流量统计装置,可获取针对预设区域的视频片段,对视频片段进行解析,得到多帧视频图像,对多帧视频图像进行逐帧人体检测,得到多个人体检测结果,根据多个人体检测结果,确定多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像,基于多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集,根据多个人头关键点集,确定预设区域对应的人流量,如此,可先检测人体,再确定人头关键点集,通过上述两个维度的信息,确定预设区域对应的人流量,有利于提高人流量的统计效率。
在一个可能的示例中,在对所述多帧视频图像进行逐帧人体检测,得到多个人体检测结果方面,上述检测单元302具体用于:
对所述多帧视频图像中每一视频图像进行特征提取,得到多个特征图,其中,每一视频图像对应一个特征图;
将所述多个特征图输入预设第一神经网络模型中进行人体检测,得到多个人体检测结果。
在一个可能的示例中,在基于所述多个人体位置,确定每一视频图像中对应的人头关键点集方面,上述确定单元304具体用于:
基于所述多个人体位置,在所述多个特征图中确定所述多个人体位置对应的多个目标位置,其中,每一人体位置对应一个特征图中的一个目标位置;
基于所述多个目标位置,对所述多个特征图中每一特征图进行裁剪,得到多个子特征图集,每一子特征图集中包括所述多个目标位置分别对应的多个子特征图;
对所述多个子特征图集中每一子特征图集进行图像融合,得到多个目标特征图,每一目标特征图对应一个子特征图集;
对所述多个目标特征图中每一目标特征图进行人头关键点提取,得到每一视频图像对应的人头关键点集。
在一个可能的示例中,在根据所述多个人头关键点集,确定所述预设区域对应的人流量方面,上述确定单元304具体还用于:
根据所述多个人头关键点集,确定所述多帧视频图像中对应的多个目标对象;
按照预设标识分配方法,对所述多个目标对象中每一目标对象进行标识分配,得到多个标识信息;
基于所述多个标识信息,对所述多个目标对象进行目标跟踪,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹;
基于所述多个目标运动轨迹,确定所述预设区域的人流量。
在一个可能的示例中,在根据所述多个人头关键点集,确定所述多帧视频图像中对应的多个目标对象方面,上述确定单元304具体还用于:
将视频图像i对应的人头关键点集i与视频图像j人头关键点集j进行匹配,得到多个匹配值,其中,每一匹配值对应一帧视频图像,所述视频图像i和所述视频图像j为所述多帧视频图像中任意两帧视频图像;
计算所述多个匹配值的均值;
若所述均值超过预设阈值,则确定所述人头关键点集i和所述人头关键点集j对应同一个目标对象。
在一个可能的示例中,在基于所述多个标识信息,对所述多个目标对象进行目标跟踪,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹方面,上述确定单元304具体还用于:
基于所述多个标识信息,对所述多帧视频图像中每一帧视频图像进行目标检测,确定每一所述标识信息在所述多帧视频图像中的出现时刻集,得到多个出现时刻集;
基于所述多个出现时刻集,确定所述多个标识信息中每一标识信息对应的轨迹状态信息集,得到多个轨迹状态信息集,其中,每一轨迹状态信息集中包括每一标识信息在所述多帧视频图像中对应的多个轨迹状态信息;
基于所述多个轨迹状态信息集,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹。
可以理解的是,本实施例的人流量统计装置的各程序模块的功能可根据上述方法实施例中的方法具体实现,其具体实现过程可以参照上述方法实施例的相关描述,此处不再赘述。
与上述一致地,请参阅图4,为本申请实施例提供的一种服务器的实施例结构示意图。本实施例中所描述的服务器,包括:至少一个输入设备1000;至少一个输出设备2000;至少一个处理器3000,例如CPU;和存储器4000,上述输入设备1000、输出设备2000、处理器3000和存储器4000通过总线5000连接。
其中,上述输入设备1000具体可为触控面板、物理按键或者鼠标。
上述输出设备2000具体可为显示屏。
上述存储器4000可以是高速RAM存储器,也可为非易失存储器(non-volatilememory),例如磁盘存储器。上述存储器4000用于存储一组程序代码,上述输入设备1000、输出设备2000和处理器3000用于调用存储器4000中存储的程序代码,执行如下操作:
上述处理器3000,用于:
获取针对预设区域的视频片段;
对所述视频片段进行解析,得到多帧视频图像;
对所述多帧视频图像进行逐帧人体检测,得到多个人体检测结果;
根据所述多个人体检测结果,确定所述多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像;
基于所述多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集;
根据所述多个人头关键点集,确定所述预设区域对应的人流量。
可以看出,通过本申请实施例所描述的服务器,可获取针对预设区域的视频片段,对视频片段进行解析,得到多帧视频图像,对多帧视频图像进行逐帧人体检测,得到多个人体检测结果,根据多个人体检测结果,确定多帧视频图像中每一帧视频图像对应的人体位置,得到多个人体位置,每一人体位置对应一个视频图像,基于多个人体位置,确定每一视频图像中对应的人头关键点集,得到多个人头关键点集,根据多个人头关键点集,确定预设区域对应的人流量,如此,可先检测人体,再确定人头关键点集,通过上述两个维度的信息,确定预设区域对应的人流量,有利于提高人流量的统计效率。
在一个可能的示例中,在对所述多帧视频图像进行逐帧人体检测,得到多个人体检测结果方面,上述处理器3000还可用于:
对所述多帧视频图像中每一视频图像进行特征提取,得到多个特征图,其中,每一视频图像对应一个特征图;
将所述多个特征图输入预设第一神经网络模型中进行人体检测,得到多个人体检测结果。
在一个可能的示例中,在基于所述多个人体位置,确定每一视频图像中对应的人头关键点集方面,上述处理器3000还可用于:
基于所述多个人体位置,在所述多个特征图中确定所述多个人体位置对应的多个目标位置,其中,每一人体位置对应一个特征图中的一个目标位置;
基于所述多个目标位置,对所述多个特征图中每一特征图进行裁剪,得到多个子特征图集,每一子特征图集中包括所述多个目标位置分别对应的多个子特征图;
对所述多个子特征图集中每一子特征图集进行图像融合,得到多个目标特征图,每一目标特征图对应一个子特征图集;
对所述多个目标特征图中每一目标特征图进行人头关键点提取,得到每一视频图像对应的人头关键点集。
在一个可能的示例中,在根据所述多个人头关键点集,确定所述预设区域对应的人流量方面,上述处理器3000还可用于:
根据所述多个人头关键点集,确定所述多帧视频图像中对应的多个目标对象;
按照预设标识分配方法,对所述多个目标对象中每一目标对象进行标识分配,得到多个标识信息;
基于所述多个标识信息,对所述多个目标对象进行目标跟踪,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹;
基于所述多个目标运动轨迹,确定所述预设区域的人流量。
在一个可能的示例中,在根据所述多个人头关键点集,确定所述多帧视频图像中对应的多个目标对象方面,上述处理器3000还可用于:
将视频图像i对应的人头关键点集i与视频图像j人头关键点集j进行匹配,得到多个匹配值,其中,每一匹配值对应一帧视频图像,所述视频图像i和所述视频图像j为所述多帧视频图像中任意两帧视频图像;
计算所述多个匹配值的均值;
若所述均值超过预设阈值,则确定所述人头关键点集i和所述人头关键点集j对应同一个目标对象。
在一个可能的示例中,在基于所述多个标识信息,对所述多个目标对象进行目标跟踪,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹方面,上述处理器3000还可用于:
基于所述多个标识信息,对所述多帧视频图像中每一帧视频图像进行目标检测,确定每一所述标识信息在所述多帧视频图像中的出现时刻集,得到多个出现时刻集;
基于所述多个出现时刻集,确定所述多个标识信息中每一标识信息对应的轨迹状态信息集,得到多个轨迹状态信息集,其中,每一轨迹状态信息集中包括每一标识信息在所述多帧视频图像中对应的多个轨迹状态信息;
基于所述多个轨迹状态信息集,确定所述多个标识信息中每一标识信息对应的目标运动轨迹,得到多个目标运动轨迹。
本申请实施例还提供一种计算机存储介质,其中,该计算机存储介质可存储有程序,该程序执行时包括上述方法实施例中记载的任何一种人流量统计方法的部分或全部步骤。
尽管在此结合各实施例对本申请进行了描述,然而,在实施所要求保护的本申请过程中,本领域技术人员通过查看所述附图、公开内容、以及所附权利要求书,可理解并实现所述公开实施例的其他变化。在权利要求中,“包括”(comprising)一词不排除其他组成部分或步骤,“一”或“一个”不排除多个的情况。单个处理器或其他单元可以实现权利要求中列举的若干项功能。相互不同的从属权利要求中记载了某些措施,但这并不表示这些措施不能组合起来产生良好的效果。
本领域技术人员应明白,本申请的实施例可提供为方法、装置(设备)、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。计算机程序存储/分布在合适的介质中,与其它硬件一起提供或作为硬件的一部分,也可以采用其他分布形式,如通过Internet或其它有线或无线电信系统。
本申请是参照本申请实施例的方法、装置(设备)和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程人流量统计设备的处理器以产生一个机器,使得通过计算机或其他可编程人流量统计设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程人流量统计设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程人流量统计设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管结合具体特征及其实施例对本申请进行了描述,显而易见的,在不脱离本申请的精神和范围的情况下,可对其进行各种修改和组合。相应地,本说明书和附图仅仅是所附权利要求所界定的本申请的示例性说明,且视为已覆盖本申请范围内的任意和所有修改、变化、组合或等同物。显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 人流量统计方法及相关产品
- 一种基于深度学习人头检测的密集人流量统计方法