一种基于FPGA并行度自适应的卷积神经网络加速器
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及数字集成电路、电子信息与深度学习领域,特别是一种基于FPGA并行度自适应的卷积神经网络加速器。
背景技术
随着深度学习技术在科研、生活、生产和国防军事领域的突破,卷积神经网络(CNN)模型已经取得了巨大的成功。卷积模型中各个卷积层的尺寸相差过大是限制加速器性能提升的原因之一。由于CNN中前层的输入通道过小,典型的用于图像识别的VGG-16的第0层只有3个输入通道,具有较大并行度的加速器无法在CNN中的前层达到应有运算性能。稀疏感知加速器由于需要更大的控制粒度在这方面表现更差。如果使矩阵式运算单元的运算更为灵活,即可在保证运算效率前提下提升稀疏感知加速器的运算并行度。
发明内容
本发明针对现有技术利用神经网络加速器方案对运算并行度的展开不灵活,造成运算循环无法在运算单元上完全平铺的问题,提出了一种基于FPGA并行度自适应的卷积神经网络加速器,该加速器在完成稀疏激活感知的基础上拓展了并行化平铺的维度,可以在线控制三个并行度的大小,使得加速器可以在卷积层尺寸较小的时候仍有较高的计算单元利用率。
本发明为实现上述技术目的,所实施的技术方案为:
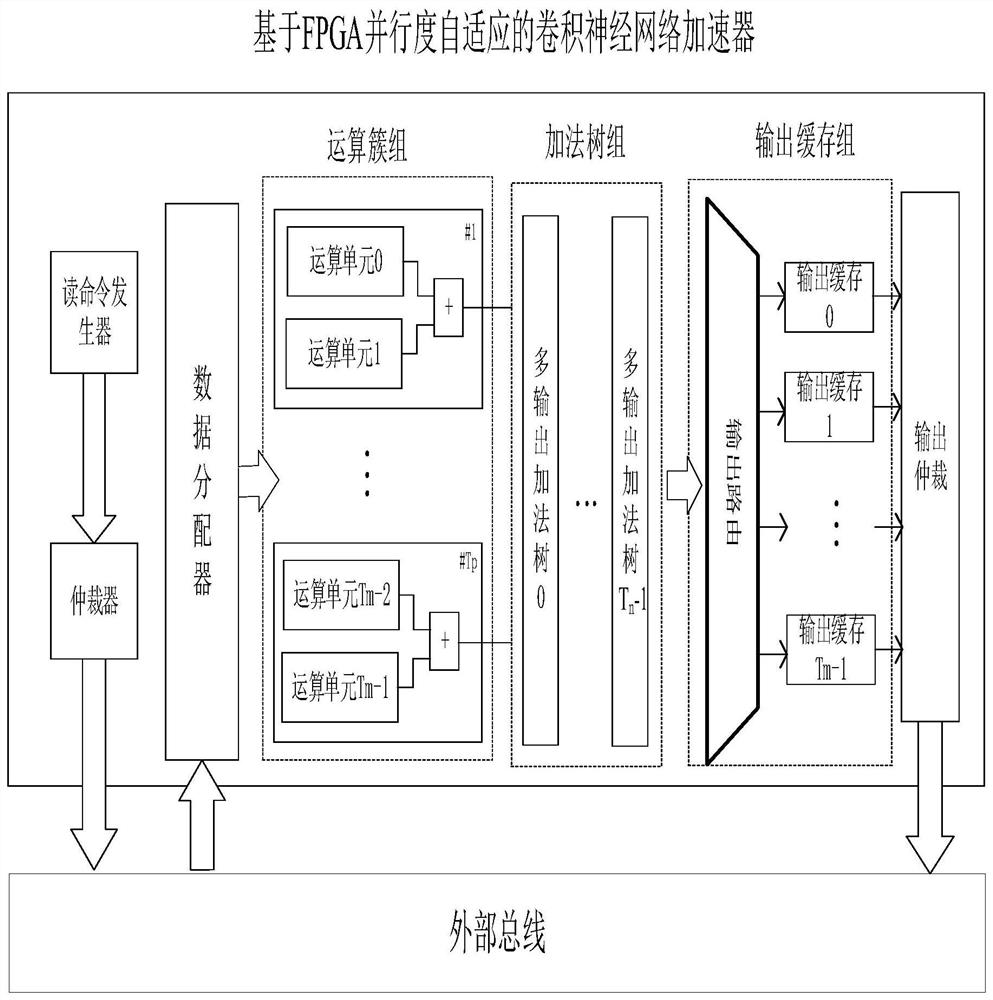
一种基于FPGA并行度自适应的卷积神经网络加速器,包括:读命令发生器、数据分配器、运算簇组、加法树组、输出缓存组和输出仲裁器。
所述基于FPGA并行度自适应的深度卷积神经网络加速器的运行方式为:首先外部向配置寄存器写入加速器的运行参数,这些参数被广播至每一个运算簇中。命令发生器产生激活和权重的读请求,它们采用两个独立的数据通道进行数据传输;由仲裁器动态地向外部总线发送数据的读请求指令;片外存储器中数据通过外部总线读入到数据分配器中,数据分配其将其分配给不同的运算簇中,运算簇进行卷积运算。根多输出加法树选择加法隔离方式和有效输出的数量,其数量与输出激活并行度相同。数据路由模块将根据并行度设置不同的输出缓存连接方式,其连接方式保证每个输出激活并行运算都连接到一个输出缓存。最后由一个输出仲裁器将不同的输出缓存写回片外存储器。
所述输出仲裁器选择从哪个输出缓存中输出数据,其根据输出缓存的请求级别输出数据,在输出缓存具有突发长度一半的数据量时,会触发低级别请求,具有突发长度的数据量时,会触发高级别请求。仲裁器中不存在高请求级别时,将低级别请求的数据输出;存在较高请求级别时,输出较高请求级别所对应的数据。
可选地,所述数据分配器根据运算簇中的数据一致性进行数据单播或广播。当不同的运算簇运算不同输出激活的时候,数据分配器进行对权重和最后(k-stride)*w_in的激活同时广播至不同的运算簇中,其中,k为卷积核大小,stride为跨步大小,win为输入特征图宽度;当不同的运算簇运算同一输出激活的不同输入通道的时候,数据分配器进行单播,将权重和激活数据依次传输到对应运算簇中。
可选地,所述运算簇组包含Tp个由运算单元和加法器所组成的运算簇,每个运算单元包含片上激活和权重缓存、地址发生器、应答器、稀疏感知器、非0缓存和Tn个乘累加器。每个乘累加器运算Tn个输出通道的激活,同一个运算簇中不同运算单元的乘累加器结果由加法器进行相加,作为运算簇的输出。运算簇组共包含Tm个运算单元,它们被平均分配给每个运算簇。其中,Tm为Tp的整数倍。所述Tm、Tp和Tn为硬件配置参数,其配置方案为Tm×Tn小于FPGA中DSP的数量,Tp最小为2,最大为Tm,为2的整数次幂。所述运算簇组可以并行运算同一个卷积层的不同输出通道与不同输入通道(或不同输出激活)对应的卷积运算。设卷积层的输入通道数为Chin,当Chin≥Tm×Tn时,每个运算簇运算ceil(Chin/Tp)个输入通道的卷积,其中“ceil()”为向上取整函数。Chin 可选地,所述加法树组具有多节点输出功能,且由Tn个多段加法树构成。每级加法器的输入端口有先入先出存储器,用以将不同加法器的运算隔离。每级加法器输入端连接到一个运算簇上,其输入值为来自不同输入通道的卷积部分和,每级加法器的输出值均作为一个独立输出,其输出值为不同的输出激活,在Tu不为0时链接不同输出激活缓存,否则只有最后一级输出有效,其他的舍弃。 可选地,所述输出缓存组的存储深度与外部总线的突发长度一致,且与运算簇一一对应,其输入端连接到多段加法数组的每一个加法器上。所述输出缓存组具有数据路由模块,它由Tm/Tp个多路器组成,输入端连接到加法树中的每一个加法器和上一个多路器的输出,输出端连接到下一个多路器的输入端,多路器的数据选择方式为每2 一种基于FPGA的单运算多任务数据流,将卷积运算的输出激活以行方向将一次卷积运算分解为Tu份独立运行的任务,每一个任务中的数据流相同且在不同运算簇中并行流动互不干扰。所述任务中的数据流依次以卷积循环的输出通道、输入通道、卷积窗口进行展开,所述任务进行Tn个输出通道和Tm×Tu的输入通道的卷积并行运算。 本发明所采用的技术方案具有的优点和有益效果是: 实现了稀疏激活加速器灵活的并行度展开架构,该架构拓展了并行化平铺的维度,可以在线控制三个并行度的大小。当卷积层输入通道量不足时,加速器将原本的输入通道展开运算单元用于展开输出激活并行度,由此提升运算单元利用率,实现较高的吞吐率。有效跳过0激活所参与的运算可以在不影响运算结果的前提下减少运算负载。数据分配器使用广播形式传输重复的片上数据可以大幅度减少片外冗余数据的读取,降低加速器对带宽的依赖 附图说明 图1为本发明的结构示意图; 图2为运算簇的结构示意图; 图3为数据路由结构示意图; 具体实施方式 如图1所示的结构,本实施例涉及一种基于FPGA并行度自适应的深度卷积神经网络加速器,包括:读命令发生器、数据分配器、运算簇组、加法树组、输出缓存组和输出仲裁器。 所述基于FPGA并行度自适应的深度卷积神经网络加速器的运行方式为:首先外部向配置寄存器写入加速器的运行参数,这些参数被广播至每一个运算簇中。命令发生器产生激活和权重的读请求,它们采用两个独立的数据通道进行数据传输;由仲裁器动态地向外部总线发送数据的读请求指令;片外存储器中数据通过外部总线读入到数据分配器中,数据分配其将其分配给不同的运算簇中,运算簇进行卷积运算。根据并行度的不同,多输出加法树选择加法隔离方式和有效输出的数量,其数量与输出激活并行度相同。为了充分利用输出缓存,数据路由模块将根据并行度设置不同的输出缓存连接方式,其连接方式保证每个输出激活并行运算都连接到一个输出转存。最后由一个仲裁器将不同的输出缓存写回片外存储器,为了使多输出激活并行运算重新耦合成单运算,仲裁器将根据不同输出激活运算所在的运算簇的物理位置配置输出地址。 所述读命令发生器用于向外部总线发送读请求寻址片外存储器存储的激活和权重数据,其读请求按照Tn个输入通道的激活和权重为单位进行,读取顺序为:特征图从宽度到高度再到输入通道深度;权重从宽度到高度,再从输入通道深度到输出通道深度。 所述运算簇中的数据流相同且并行流动互不干扰,其数据流依次以卷积循环的输出通道、输入通道、卷积窗口展开。 所述运算簇组包含Tp个由运算单元和加法器所组成的运算簇,每个运算单元包含片上激活和权重缓存、地址发生器、应答器、稀疏感知器、非0缓存和Tn个乘累加器。每个乘累加器运算Tn个输出通道的激活,同一个运算簇中不同运算单元的乘累加器结果由加法器进行相加,作为运算簇的输出。所述运算簇可以被灵活配置为输入通道的运算或者输出激活的运算。运算簇组共包含Tm个运算单元,它们被平均分配给每个运算簇。其中,Tm为Tp的整数倍。所述Tm、Tp和Tn为硬件配置参数,可以根据FPGA的运算资源和目标网络进行离线配置。 所述运算簇的结构如图2所示,它可以并行运算同一个卷积层的不同输出通道与不同输入通道或者不同输出激活对应的卷积运算。在卷积层的输入通道数Chin≥Tm×Tn时,每个运算簇运算ceil(Chin/Tp)个输入通道的卷积,其中“ceil()”是向上取整函数。Chin 所述数据分配器根据运算簇中的数据一致性进行数据的单播或广播。在运算簇组运算同一个卷积层的不同输出通道与不同输出激活对应的卷积运算时,取Tu作为满足Chin<2 所述加法树组的加法树具有多节点输出功能,每级加法器的值均作为一个独立输出,其输出值为不同的输出激活,在Tu不为1时对应不同输出激活缓存,否则只有最后一级输出有效,其他的舍弃。以如图3所示的8个运算簇结构为例,每个输出经过由多个多路器所组成的数据路由结构,其中AL_a_b代表来自第a级加法树的第b个加法器的输出,OB_c代表第c个输出缓存的数据。每个多路器负责一个输出缓存的数据路由,根据Tu值将加法树的输出结果送至相应输出缓存。除了第一个多路器,其它均有来自上一个输出缓存的输入端口。由此,在Tu较小时即可把多个输出缓存重新链接成一个较大缓存。 所述输出缓存的存储深度与外部总线的突发长度一致,其向输出仲裁器有2个请求级别,在输出缓存具有突发长度一半的数据量时,会触发低级别请求,具有突发长度的数据量时,会触发高级别请求。仲裁器中不存在高请求级别时,将低级别请求的数据输出;存在较高请求级别时,输出较高请求级别所对应的数据。
- 一种基于FPGA并行度自适应的卷积神经网络加速器
- 一种基于FPGA的Policy卷积神经网络加速器