一种基于气象信息和深度学习算法的多步日径流预报方法
文献发布时间:2023-06-19 12:13:22
技术领域
本发明涉及水文预报领域,特别涉及一种基于气象信息和深度学习算法的多步日径流预报方法。
背景技术
径流预报是水库优化调度的基础,在水库管理和运行中起着至关重要的作用。随着我国大江大河上梯级水电站的大规模投产,庞大的水电系统面临着非常复杂的调度问题,调度不当极易产生弃水现象,因此调度过程中对水库径流预报的精度要求较高。然而,目前日径流预报精度明显不足,特别对于我国南方地区。由于台风等强对流天气影响,我国南方地区强降雨通常集中在几天之内,低精度的径流预报容易导致水电站在灾害发生7-15天无法制定合理的发电计划,造成不必要的弃水,带来巨大的经济损失。另一方面,受到气候变化和人类活动的影响,流域产流特性和来水特征经常发生变化,往往需要频繁重新建立日径流预报模型,并根据近期实际径流和气象资料对模型参数进行重新计算和校正。这也给水库日径流预报带来了困难。
径流由于其高度的复杂性、非平稳性、动态性和非线性而难以被准确预测,尽管目前已经对径流产生的客观规律有较为深刻地认识,但是受限于监测手段,计算能力和计算尺度,想要建立一个近似地能够描述产汇流全过程的动力学方程却极其困难,目前随着水文模型、天气预报模型和陆气耦合模型的发展,很多方法被提出实施径流预报,主要被分为三大类:传统统计模型、人工智能模型和概念模型。其中,传统的统计方法主要包括自回归模型(autoregressive model,AR)、自回归移动平均模型(autoregressive movingaverage model,ARMA)等。冯国章等人在文献《多元自回归模型在枯水径流预报中的应用》中采用多元自回归模型进行径流预报,基于时间序列分析的理论,模型结构清晰,输入输出关系简单且易于理解。然而实际的径流序列是复杂的、非线性的和混沌的,传统统计方法集中于挖掘径流序列本身的一些特性对其进行预报,对外生变量的挖掘较少。人工智能模型例如人工神经网络(artificial neural network,ANN)、(multiple linear regression)MLR和支持向量回归(support vector regression,SVR),具有容易陷入局部最优值和过拟合的缺点,并且人工智能模型的超参数的确定也是非常困难和计算密集的。概念模型例如新安江模型、水文变量渗透能力(variable infiltration capacity,VIC)模型等,对边界条件和输入数据的精度和连续性要求很高,主要用于洪水预报,预见期较短。因此,由于以上径流预报问题的复杂性和各种预报方法本身的限制,当下并没有一种有效的预报方法。梯度提升回归树(gradient boosting regression trees,GBRT)是一种基于提升策略和决策树的非参数机器学习方法,已成功应用于交通、环保等领域,并取得了较好的效果。与ANN和SVR相比,GBRT还有两个优点:(1)GBRT可以对模型的输入进行排序,这对于解释模型机理和降低模型的复杂度具有重要意义(2)GBRT是一个白盒模型,易于解释,且目前GBRT尚没有用于日径流预测研究中。因此,本发明选取GBRT进行日径流预测。
目前国内相关成果和文献报道的许多方法中,尚没有考虑气象信息和深度学习算法的高精度多步日径流预报方法。本发明成果依托于国家自然科学基金项目(51979023)和中央高校基本科研业务费专项资金资助项目(DUT20JC16),以水库多步日径流预报为研究背景,以云南省澜沧江流域下游的小湾水电站作为研究对象,着手构建了一个基于气象信息和深度学习算法的多步日径流预测框架。首先,采用最大信息系数(maximalinformation coefficient,MIC)对气象数据集进行特征选择作为模型的候选输入;其次,采用GBRT-MIC进行日径流预测。最后,选择广泛使用的六个评价标准对模型比较和预报结果评估,即均方根误差(root mean squared error,RMSE)、平均绝对误差(mean absoluteerror,MAE)、皮逊相关系数(Pearson correlation coefficient,CORR)、克林-古普塔效率得分(Kling–Gupta efficiency scores,KGE),流量历时曲线高段累积的百分比偏差(BHV)和一致性指数(the index of agreement,IA)。对比现有技术,本发明所开发的综合GBRT,MIC和再分析数据的多步日径流预报框架,可以获得更准确可靠的径流预报,为水库调度提供可靠的径流预报结果,对减少梯级水库弃水、增加发电效益、提高水电科学调度水平具有重要意义。
发明内容
本发明要解决的技术问题是针对水库优化调度过程的径流预测准确性不足的问题提出了一种基于气象信息和深度学习算法的多步日径流预报方法,从输入选择、预报模型构建和预报与结果评估三个步骤进行着手构建了一个日径流预测框架。为避免单一指标的评估偏差导致预测结果评估不准确,选择广泛使用的六个评估指标,即MAE,RMSE,CORR,KGE,BHV和IA对本发明提出框架和对比模型进行预报结果评估,以云南省澜沧江流域下游的小湾电站为研究区域进行模型验证。
本发明的技术方案为:
一种基于气象信息和深度学习算法的多步日径流预报方法,包括三阶段,第一阶段利用最大互信息系数MIC方法对气象数据集进行特征选择作为模型的预测因子候选输入,采用互相关函数CCF(cross correlation function)和偏自相关函数PACF(partialautocorrelation function)对观测径流和降雨量的历史滞后数据进行选择作为模型的预测因子候选输入;第二阶段先对选定的预测因子进行数据尺度缩放,然后将数据集划分为训练集、验证集和测试集。第三阶段先通过网格搜索算法率定GBRT模型参数,然后使用优选的参数在测试集上实施预报。框架所有的阶段都是基于Python语言和scikit-learn模块实现。具体可分为步骤1-3:
步骤1.应用MIC、CCF和PACF进行GBRT-MIC模型的输入选择。
输入数据集主要包含两部分:气象数据集和观测数据集的历史数据。针对气象数据集,先计算径流数据与根据经验选择的多个气象数据变量的MIC。然后根据MIC的计算结果对气象变量进行降序排列。针对观测数据集,先计算径流变量与滞后一个或多个时段的历史径流变量的PACF,比较PACF与其95%的置信区间,如果某个滞后时段的径流的PACF没有落入置信区间,则将这个滞后时段的数据作为输入,然后计算径流变量与滞后一个或多个时段的历史降雨观测变量的CCF,比较CCF与其95%的置信区间,如果某个滞后时段的降雨的CCF没有落入置信区间,则将这个滞后时段的数据作为输入。若CCF递减且多阶滞后仍然没有落入95%的置信区间,则将第一时段滞后的降雨数据变量单独构成一个输入集合、第一时段滞后和第二时段滞后的降雨数据变量构成第二个输入集合,以此类推组成多个输入集合,再在每个集合中添加PACF选择的滞后一个或多个时段的历史径流观测变量。最后,PACF选择的滞后一个或多个时段的历史径流观测变量再单独作为一个输入集合,将所有输入集合按照试算方法得到一个最优的观测值输入集合,记为obs。
然后,根据MIC降序排列的多个气象变量中的第一个气象变量单独构成一个输入集合,第一个和第二个气象变量构成第二个输入集合,第一个、第二个和第三个气象变量构成第三个输入集合,以此类推,可以得到多个输入集合。得到的多个输入集合均和最优的观测值输入集合obs相加得到新的多个输入集合。将新的多个输入集合通过试算方法得到最优输入集合,作为GBRT-MIC模型的输入结构。
所述的试算方法按照如下方式开展将多个输入集合分别作为GBRT模型的输入:GBRT模型的参数使用Python语言中scikit-learn模块的默认参数,然后使用默认评估指标,对每个输入集合作为输入GBRT模型得到的径流预报值进行评估,通过对比评估结果,选择多个输入集合中的最优输入集合即obs,试算完成;整个试算过程需要保证选择过程中使用的参数和评估指标一致。
步骤2.数据尺度缩放与数据集划分。
对于步骤1选择的输入,先将每一个变量按照下式进行数据缩放,将每个变量的数量级缩放到相同量级。
式中:x
然后将缩放后的序列按照比例划分为训练集、测试集和验证集。
步骤3.率定GBRT参数并实施预报。
GBRT是一个集成预测模型,包含两个算法:决策树算法和增强算法。决策树算法需要进行优化的参数包含树的最大深度(max_depth)、分割内部节点所需的最小样本数(min_samples_spli)、一个叶子节点上最小样本数(min_samples_leaf)和最大叶子节点数(max_leaf_nodes)等4个参数,增强算法包含学习率(learning_rate)和弱学习器的数量(n_estimators)等2个参数。因此,该步骤需要优化的参数有6个参数。
为了尽快得到最优的参数组合,分两步对所有参数进行优化。首先,n_estimators和learning_rate分别使用默认参数或者根据经验选择。max_leaf_nodes,min_samples_leaf,max_depth和min_samples_split等4个调整参数根据经验确定离散取值空间然后进行交叉网格取值构成参数组合,在每个预见期生成多种个参数组合。其次,在确定树参数后,将学习率修正为更小的值,将n_estimators取值多个更大的值,然后进行优化确定最优的n_estimators。为了减轻计算压力,所有模型都进行并行计算,scikit-learn模块提供并行的实现。
将优化得到的参数在训练集上进行训练,然后使用训练的GBRT-MIC模型在测试集和验证集上实施预报,并对径流预报结果进行评估。
本发明对比现有技术有如下有益效果:本发明针对水库优化调度过程的径流预测准确性不足的问题提出了一种基于气象信息和深度学习算法的多步日径流预报方法。该方法采用三阶段建模,第一阶段以MIC选取的再分析资料选取的气象信息作为模型的预测因子对候选输入进行选择。第二阶段采用GBRT-MIC预测来水。对比现有技术,本发明所开发的综合GBRT,MIC和再分析数据的多步日径流预报框架,能够在预见期内很好地进行较精准的径流预测。本发明的方法对协助电厂提前制定发电计划,减少雷电灾害和洪涝灾害具有重要意义。
附图说明
图1是决策树模型的结构示意图;
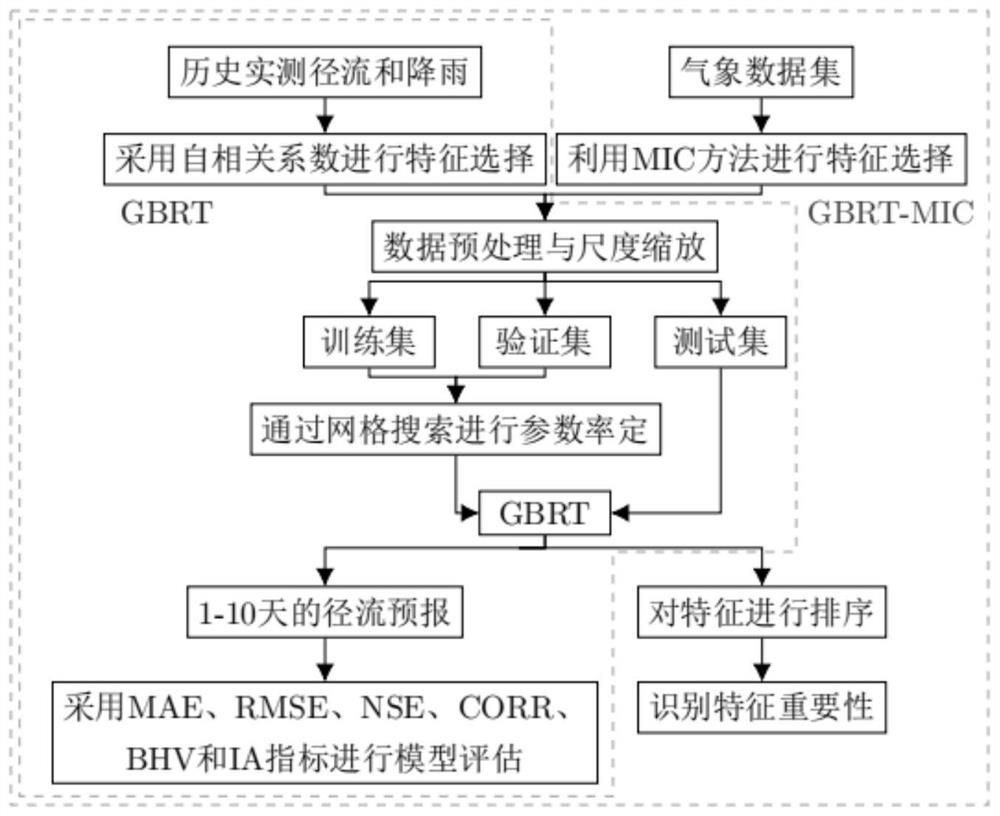
图2是径流预报技术路线图;
图3是小湾水电站日径流序列示意图;
图4是小湾水库的控制流域示意图;
图5(a)和图5(b)分别是小湾日径流的偏自相关图和小湾降雨径流的交叉相关系数图;
图6是13个输入结构观测数据的试验结果示意图;
图7是再分析数据26个输入结构的试验结果示意图;
图8(a)和图8(b)是依据MAE对人工神经网络中激活函数和隐含层节点数的灵敏度分析示意图,阴影部是通过50次试验的bootstrap得到的95%置信区间,其中图8(a)为一天预见期,图8(b)为十天预见期;
图9(a)~图9(f)是GBRT和GBRT-MIC在测试集(2017-2018)六个指标上的表现示意图,(a)MAE(b)RMSE(c)CORR(d)KGE(e)BHV(f)IA;
图10(a)~图10(c)是GBRT和GBRT-MIC在测试集上五天预见期的径流预测结果示意图(2017-2018,730天),其中,图10(a)是观测和预测径流量,图10(b)是测试集预测误差直方图,图10(c)是实测流量与预测流量的比较;
图11(a)~图11(f)是GBRT-MIC、SVR-MIC、ANN-MIC和MLR-MIC在测试集(2017-2018)六项指标上的表现示意图;(a)MAE(b)RMSE(c)CORR(d)KGE(e)BHV(f)IA。
具体实施方式
下面结合附图和实施案例对本发明作进一步的描述。
本发明的总体结构框架为GBRT-MIC模型。GBRT-MIC方法采用三阶段建模,首先,第一阶段利用最大互信息系数MIC对气象数据集进行特征选择作为模型的预测因子候选输入,采用CCF和PACF对观测径流和降雨量的历史滞后数据进行选择作为模型的预测因子候选输入;第二阶段先对选定的预测因子进行数据尺度缩放,然后将数据集划分为训练集、验证集和测试集。第三阶段先通过网格搜索算法率定GBRT模型参数,然后使用优选的参数在测试集上实施预报和结果评估。下面对具体流程进行详细阐述。
(I)第一阶段:应用MIC、CCF和PACF进行输入选择
输入数据集主要包含两部分:气象数据集和观测数据集的历史数据。针对气象数据集,先计算径流数据与根据经验选择的26个气象数据变量的MIC,详细的变量介绍参考表1。
MIC的计算是基于互信息(MI)的概念。对于径流变量X,X的熵被定义为:
式中:p(x)是X=x的概率密度函数。进一步,对于另外一个气象数据变量Y,给定Y的X的条件熵能够用式(3)进行估计:
式中:H(X|Y)是先验知识下X的不确定性,p(x,y)和p(x|y)分别是X=x和Y=y时的联合概率密度和条件概率。原来的X的不确定性由于Y的先验知识的减少量被称为MI,被定义为:
MIC的计算可以分为三部分。考虑对于给定的气象数据集D,包含变量X和Y,变量中样本的数量为n。首先绘制X和Y的散点图,绘制格网进行划分区域,这个格网叫做x-by-y格网。D|G被定义为D被x-by-y格网中的一个G划分后的分布。MI*(D,x,y)=maxMI(D|G),式中MI(D|G)是D|G的互信息。第二步,特征矩阵被定义为:
最后,MIC作为特征矩阵的最大值被引入,即
针对观测数据集,先计算径流序列与1-12阶滞后的历史值PACF,比较PACF与95%的置信区间,选择没有落入置信区间的滞后值作为输入,然后计算径流序列与1-12阶滞后的降雨观测序列的CCF,比较CCF与95%的置信区间,选择没有落入置信区间的滞后值作为输入。若CCF递减且12阶滞后仍然没有落入置信区间,则将降雨数据按照1阶滞后、1阶和2阶滞后、1,2和3阶滞后、组成12个集合,再在每个集合中添加PACF选择的径流滞后,PACF选择的径流滞后单独作为一个集合,形成13个输入结构,详细结果可参考表2。
输入选择结果显示图5(a)和图5(b)显示观测径流序列从滞后1阶到滞后12阶的偏自相关图、交叉相关图和相应的95%的置信区间。偏自相关图分别在滞后1阶和滞后4阶显示出显著的自相关性,因此,选择径流序列滞后1阶和滞后4阶作为模型的输入。随着滞后阶数的增加,径流和降雨之间的相关系数缓慢下降但没有落入95%的置信区间内(图5(b))。因此,需要采用模型试算法确定滞后降雨序列的最优滞后阶数,试算的详细信息在第三阶段介绍。
(II)第二阶段:数据尺度缩放与数据集划分
由于地面观测站点数量稀缺、监测时间短和数据保密等原因,实测资料往往较为难以获得,同时,地面观测资料的监测变量数量有限,因此引入欧洲中期再分析(ERA-interim)资料代替实际监测站点资料实施径流预报。所使用的资料为地表的分析资料,空间分辨率为0.25°,时间分辨率为12h。时间范围为2011.1.1-2018.12.31,获取自https://apps.ecmwf.int/datasets/data/interim-full-daily/levtype=sfc/。根据已有的文献研究,从再分析数据中选择近地表26个变量作为径流预报的潜在输入因子,表1列出了这些因子。
将缩放后的序列按照2:1:1的比例划分为训练集、测试集和验证集,例如如果数据序列的长度为2011-2018年,训练集的数据为2011-2014年,测试集和验证集的数据分别为2015-2016年和2017-2018年。
图3展示了每日径流系列,分别使用2011.1.1-2014.12.31(1461天,约占整个数据集50%)、2015.1.1-2016.12.31(731天,约占整个数据集的25%和2017.1.1-2018.12.31(730天,约占整个数据集的25%)的数据作为训练集、验证集和测试集。再分析数据集中的累积变量取日累积变量、瞬时变量和日最值变量也均取日内的平均瞬时变量和日内最值变量。图4显示了小湾水库的控制流域,红色的点为监测点,控制面积内共26个监测点,用到的气象数据序列是红色监测点数据的算术平均值序列。为了消除量纲的影响并将数据的数量级转为相同水平,输入因子序列都需要进行标准化出处理。通过下式将数据范围进行归一化。
式中:x
(III)第三阶段:率定GBRT参数并实施预报
GBRT是一个集成预测模型,具有很强的非线性捕捉能力,能够在较长的预见期内更充分地捕捉输入和输出之间的非线性关系。主要包含两个算法:决策树算法和增强(boosting)算法。决策树对输入因子表现出很强的鲁棒性被用作基础模型,采用boosting算法作为集成规则,提高了模型用于径流预测的准确性。
A:决策树
本发明中的决策树是指计算机科学中的决策树学习,它是机器学习中的预测建模方法之一。决策树由分支节点(树结构)和叶节点(树输出)组成。假设一个训练数据集在一个有N个特征,每个特征有n个样本,{(X
式中:
式中:y
B:Boosting算法
梯度提升的思想起源于Breiman的观测,可以解释为一种基于适当代价函数的优化算法。随后开发出了显式回归梯度提升算法。这里对所使用的boosting算法进行介绍。假设一个训练数据集有n个样本,{(X
GBRT算法的核心是用残差法训练决策的迭代过程。具有M个决策树的GBRT迭代训练过程如下:
1)初始化
2)对于m-th(m=1,2,...,M)决策树:
(a)操作i-th(i=1,2,...,n)样本点。用损失函数的负梯度代替当前模型中的残差
(b)用{(x
(c)对于每一个叶区域t=1,2,...,T,最好的拟合值通过
(d)通过使用
3)最后给出了一种强学习方法
根据以上对GBRT的介绍,GBRT的参数可以分为两类:boosting参数和树参数。boosting参数包括学习率和弱学习器的数量(learning_rate和n_estimators)。设置学习率用于减少梯度步长。学习率影响训练的总时间,学习率越小,训练所需的迭代次数越多。有四个树参数:max_leaf_nodes,min_samples_leaf,min_samples_split和max_depth。因此,GBRT具有六个参数控制模型复杂性,使用试算法对参数进行了调整。
在参数调整前,使用Python中scikit-learn模块的默认参数的GBRT模型对第一阶段选择的输入结构进行试算,首先对表2列出的从观测数据中确定的13种输入结构,并对每种输入结构进行了50次试验,结合评估指标的优劣选择最优的输入结构记为obs。然后根据表3列出的从气象数据中确定的26中输入结构,同样对每种输入结构进行了50次试验,结合评估指标的优劣选择最优的输入结构作为模型最终的输入结构,表4列出了最终选择的模型的输入结构,参数调整和模型预测都是基于该输入结构。
为了尽快得到最优的参数组合,分两步对所有参数进行优化。首先,n_estimators和learning_rate分别固定为100和0.1。max_leaf_nodes,min_samples_leaf,max_depth和min_samples_split等4个调整参数按照表6的交叉网格取值构成参数组合,在每个预见期生成40000个参数组合。其次,在确定树参数后,将学习率修正为0.01,按照说明书表6将n_estimators取值为40个组合,然后进行优化确定最优的n_estimators。为了减轻计算压力,所有模型都进行并行计算,scikit-learn模块提供并行的实现。
GBRT和GBRT-MIC的模型分别结构如下:
式中:
根据上述流程优化得到的参数在训练集上进行训练,然后使用训练的模型在测试集和验证集上实施预报,并对预报结果进行评估。
对比评价:根据历史观测数据选择合适的评估准则评估模型精度至关重要,避免单一指标的评估偏差导致评估不准确。引入六种广泛使用的评价指标用以评判模型结果和预测效果。具体如下:
均方根误差(root mean squared error,RMSE)和平均绝对误差(mean absoluteerror,MAE)是预报模型性能评估最常用的标准可分别通过式(11)和(12)进行计算。
式中:
皮尔逊相关系数(Pearson correlation coefficient,CORR)是评估预测值序列和观测值序列之间相关程度。它可以通过式(13)进行计算。
式中:
克林-古普塔效率得分(Kling–Gupta efficiency scores,KGE)也是被广泛使用的评估指标。它能够通过式(14)和(15)进行计算得到。
式中:σ是观测值序列的标准差,
流量历时曲线高段累积的百分比偏差(BHV)也被提出用来估计径流序列峰值的预测性能。它能够通过式(16)进行计算获得。
式中:h=1,2,...,H为超标概率小于0.02的径流的索引。根据历史径流数据给出了超越概率为0.02的径流阈值为1722m
一致性指数(the index of agreement,IA)在评价观测值序列与径流预测序列的吻合程度方面起着重要的作用。与CORR相似,它的范围在0-1之间,使用式(17)定义:
图2说明了本发明框架的总体结构。这种结构由两个主要模型组成:GBRT和GBRT-MIC。在GBRT中,通过MIC可以从大量显著影响径流的气象因子识别有效特征子集,PACF和CCF评估了不同滞后阶数的实际观测径流和降雨量与预报时段径流的相关性,并通过假设检验和试算选择适当的滞后阶数作为模型的预测因子。然后,对选定的预测因子进行数据预处理和特征缩放。接下来,根据预先指定的每个数据集的长度,将数据集划分为训练集、验证集和测试集。网格搜索算法是一种穷举搜索所有候选参数组合的方法,通过评估每个预见期的验证集来指导优化模型参数。GBRT是一种集成决策树的预测模型,具有很强的非线性捕捉能力,能够在较长的预见期内更充分地捕捉输入和输出之间的非线性关系,与GBRT相比,GBRT-MIC增加了通过MIC选择的气象数据因子作为模型的输入。采用GBRT-MIC预测来水。最后,针对不同的模型预测结果进行评价。
案例分析
现以我国云南省澜沧江下游的小湾水电站被选择作为计算实例。澜沧江水头落差大,水能资源丰富,在我国境内规划了“两库十三级”梯级水电开发,是我国十三大水电基地之一,目前已经在运行的巨型水电站11座。澜沧江干流全长约2000公里,小湾水电站上游流域面积113300平方公里。澜沧江又称湄公河,发源于青藏高原,流经中国、缅甸、老挝、泰国、柬埔寨和越南。澜沧江的主要水源来自青藏高原融雪。小湾水电站是澜沧江的控制性水电站,以小湾水电站为例进行研究具有十分重要的意义。
试验结果如图6所示。结果表明,第7种输入因子的组合的性能最好。在此基础上,选取滞后1-6天的降雨序列作为模型的输入。尝试了26种输入结构(表3),每个输入结构进行了50次试验,
结果如图7所示。结果表明,第8种输入结构组合获得了最佳性能,因此表3中编号1-8的变量被选择作为模型输入。最后,共选择16个变量(包括8个观测变量和8个再分析变量)作为模型输入。如表4所示,第9-18号为再分析变量,所选再分析变量的MIC范围为0.643-0.847。此外,9号和13-16号是与温度有关的变量。土壤温度等级3(9号)是第3层土壤的温度(28-100cm,表面为0cm)。雪层的温度(13号)给出了从地面到雪-空气界面的雪层温度。10-12号是与大气含水量有关的变量。2米露点温度(10号)是空气湿度的量度。结合温度和压力,可以计算相对湿度。总柱水汽(11号)只是水蒸气的总量,它是总柱水汽的一部分。总水柱(12号)是水蒸气、液态水、云冰、雨和雪在一个从地球表面延伸到大气层顶部的水柱的总和。第1层土壤水分体积(19号)是第1层土壤水分的体积。总的来看,所有选定的预测值都是可解释的,并且与径流有很好的物理联系。
超参数优化:采用网格搜索方法对GBRT、GBRT-MIC、ANN-MIC和SVR-MIC的超参数进行优化,采用拟牛顿法族中的一个优化器L-BFGS作为神经网络的训练算法,隐含层数固定为3。通过网格搜索从2-2个神经元和四种常用ANN的激活函数(Logistic、Tanh、Identity、Relu)选择合适的参数。为了减轻随机初始化权值的影响,每个参数组合训练50个神经网络模型。依据每个预见期的验证集的最小MAE来确定最优激活函数和隐藏层的节点数。试验结果表明,tanh和logistic函数是两个更稳健的激活函数(图8(a)和图8(b))而节点数较少的人工神经网络更倾向于获得较低的误差。
每个预见期的最优参数组合如表5所示。可以看出,最优节点数为2、3或4,最优激活函数为tanh函数或logistic函数。对于SVR,根据Lin等和Dibike等,径向基函数(Radialbasis function,RBF)在径流模拟中的表现优于其它核函数,因此本发明采用RBF作为核函数。有三个参数需要调整。首先,通过试算法确定合适的参数调整范围。然后,通过网格搜索,利用MAE最小的试算准则对参数进行优化,以找到最优的参数。SVR的最佳参数调整范围如表5所示。如前所述,对于GBRT,有六个参数需要调整。为了尽快得到最优的参数组合,分两步对所有参数进行优化。首先,n_estimators和learning_rate分别固定为100和0.1。max_leaf_nodes,min_samples_leaf,max_depth和min_samples_split,,四个调整参数在每个预见期生成40000个模型。其次,在确定树参数后,将学习率修正为0.01,并通过网格搜索确定n_estimators。为了减轻计算压力,所有模型都分布在大约12个中央处理器(CPU)中,对于GBRT-MIC和GBRT,运行的总时间约为7小时。表6列出了GBRT和GBRT-MIC的最佳参数组合。
输入比较:图9(a)~图9(f)说明了GBRT和GBRT-MIC在测试集(2017/01/01-2018/12/31)上1-10天预见期的性能指标。很明显,MIC选择的再分析数据对GBRT短预见期和长预见期的预报都有很大的改进。特别是对于较长的预见期,GBRT-MIC的预测结果显著优于GBRT。从图9(a)可以看出,与GBRT相比,GBRT-MIC的MAE从175下降到172,两天预见期下降了1.74%,十天预见期从273下降到237,下降了13.18%。从图9(b)可以看出,与GBRT相比,GBRT-MIC的两天和十天预报的RMSE分别降低了1.4%和10.6%。从图9(c),图9(d)和图9(f)可以看出,GBRT-MIC的CORR、KGE和IA的两天预报结果分别增加0.2%、2.2%、1.0%,十天预报结果分别增加3.4%、7.8%和2.2%。图9(e)比较了GBRT和GBRT-MIC的BHV,表明再分析数据可以提高极值的预测能力。
图10(a)显示了GBRT-MIC和GBRT在测试集上的五天预报径流与观察径流。GBRT-MIC和GBRT拟合曲线的斜率分别为0.89和0.81,这也说明GBRT-MIC比GBRT能获得更准确的径流预报。图10(b)说明了GBRT和GBRT-MIC预测误差的分布。结果表明,两种模型的预测误差接近正态分布,GBRT-MIC模型的预测误差比GBRT模型包含的未提取信息少,预测径流误差集中在0左右。图10(c)提供了GBRT-MIC和GBRT在预见期为五天的预测径流时间序列(来自测试集)。可以看出,与GBRT相比,GBRT-MIC提供了很好的性能,特别是在极值预报上。这表明,通过结合MIC识别的再分析数据,可以缓解GBRT模型在降雨集中地区出现的极值预测不准确的问题。
模型比较:采用GBRT-MIC、SVR-MIC、ANN-MIC和获得的最优模型参数进行了1-10天的径流预报。训练集和测试集的结果分别如表7和表8所示。为了避免落入局部极小值的问题,每个预见期训练50个ANN-MIC模型,50个模型的预测结果的中值作为最终的评估结果。从表7中可以清楚地看到在1-10天预见期内的性能指标,GBRT-MIC模型在训练集中比其他模型更有效,说明GBRT-MIC模型具有很强的拟合能力。同时,所有的机器学习模型都比MLR-MIC模型有更好的预测效果,MLR-MIC模型不能捕捉非线性关系。值得注意的是,ANN-MIC在训练集中具有最佳的BHV。
如表8所示,GBRT-MIC在4-10天的预见期内对测试集的六项指标表现最好。在10天的预见期内,GBRT-MIC的KGE甚至达到0.8317。在1-3天的预见期内,三种机器学习模型的性能接近,但优于MLP-MIC。机器学习模型能够在较短的预见期(1-3天)内获得足够的信息进行预测。
这四个模型在测试集(2017-2018)中1-10天预见期的性能指标如图11(a)~图11(f)所示。结果表明,随着预见期的增加,这四种模型的性能都有所下降(MAE、RMSE和BHV较高,CORR、KGE和IA较低)。如前所述,这四个模型在1-3天的预测中表现同样出色,而当预见期超过3天时,它们的表现却有显著差异。结果表明,除了ANN-MIC的预测效果接近GBRT-MIC的预测效果外,GBRT对4-10天预报的CORR、KGE和IA的预测效果明显高于其他三种模型,MAE、RMSE和BHV的预测效果也明显低于GBRT-MIC。值得注意的是,根据BHV和KGE,SVR表现最差,这表明SVR不能兼顾极值的预报。相反,GBRT-MIC模型在1-10天的预见期内的BHV显著优于其他模型,这表明GBRT-MIC模型能够在开发的所有模型中获得较高精度的极值预报。
表1.选择的气象数据变量的描述和符号
表2.通过PACF和CCF选择的候选输入
表3.通过MIC选择的候选输入
注:obs表示从观测数据集中选定的最佳输入集obs={Q
表4.GBRT-MIC输入因子列表。输入因子有两种类型,观测变量和再分析变量。再分析变量可在每天00:00UTC和12:00UTC两次使用。累积变量(例如,总柱水)是两个监测周期的总和,瞬时变量(例如,2米露点温度)是两个监测周期的平均值。
表5.ANN-MIC和SVR-MIC的优化参数
注:参数代表一个集合,(min,max,step)表示
表6.GBRT和GBRT-MIC的优化参数
表7.训练集的性能指标
表8.测试集的性能指标
- 一种基于气象信息和深度学习算法的多步日径流预报方法
- 一种基于气象信息的中期径流预报系统