基于机器学习预测单重态裂分材料的三重态产率的方法
文献发布时间:2023-06-19 12:18:04
技术领域
本发明涉及单重态裂分材料的三重态产率预测技术领域,特别是一种基于机器学习预测单重态裂分材料的三重态产率的方法。
背景技术
截至2017年底,可再生资源中太阳能光伏电池为全球范围电能供应贡献约400GW,预计在2050年,将达到6000GW。开发低廉和高能量转化效率的太阳能光伏电池器件的需求不断增大。在硅基光伏器件中大约有50%的能量耗散来自于电荷载体的热化,当光伏电池吸收的能量大于它的能带隙时,就会产生“热”的电荷载体,能量将以热的形式耗散,克服这种热损失的方法有两种:载流子倍增和多结太阳能电池,多结太阳能电池发展成熟但成本较高。故研究者逐步将研究重点转移到开发利用高能量的光子产生多倍载流子的光伏材料,具有单重态激子裂分能力的材料就是一种可行的载流子倍增材料。单重态裂分现象早在1965年就被发现,因理论上能力转化效率有望突破单结太阳能电池能量转化效率理论上限的Shockley-Queisser(SQ)33%的极限而逐渐成为目前研究者的研究热点。
单线态裂分(SF)是指分子的一个单重态激子(S
S
该过程一般发生在最低单重激发态能级约为其三重激发态能级的两倍的有机物中,目前已经发现具有单重态裂分能力的有机化合物有并四苯,并五苯,苝二酰亚胺,1,3-二苯基异苯并呋喃等以及它们各自的衍生物。
衡量单重激发态裂分能力的一个重要指标就是三重态量子产率(Φ
基于目前太阳能电池能量损耗较大的现状,对高能量转换效率的太阳能电池材料的研发需求越来越大,缩短研发周期、降低实验成本就变得越来越重要。因此,亟待开发一种基于机器学习预测单重态裂分材料的三重态产率的方法。
发明内容
本发明的目的是要解决现有技术中存在的不足,提供一种基于机器学习预测单重态裂分材料的三重态产率的方法。
为达到上述目的,本发明是按照以下技术方案实施的:
一种基于机器学习预测单重态裂分材料的三重态产率的方法,包括以下步骤:
步骤一、从现有文献中收集13个苝二酰亚胺衍生物分子,苝二酰亚胺衍生物分子的三重态产率Φ
(1)10个分子的分子描述符作为训练集;
(2)3个分子的分子描述符作为测试集;
步骤二、筛选出3个分子描述符作为特征变量:水合能(HE),三重态LUMO轨道能量E
y=∑β
其中X是未知矢量,X
步骤三、对优化后的预测苝二酰亚胺衍生物的三重态产率Φ
步骤四、向训练后的预测苝二酰亚胺衍生物的三重态产率Φ
进一步地,所述步骤一中,苝二酰亚胺衍生物分子采用数据挖掘软件进行数据挖掘,然后采用分子力学程序MM+对苝二酰亚胺衍生物分子构象进行优化,最后根据分子构型和量子化学半经验算法PM3计算得到相应的分子描述符。
进一步地,所述步骤二中优化建模中的惩罚因子C、不敏感损失函数ε的方法为:采用LOOCV进行参数网格化搜索,以均方根误差RMSE最小为最优参数,参数优化的搜索范围和步长如下:设置惩罚因子C在1到100之间,步长为1;不敏感损失函数ε在0.01到0.1之间,步长为0.01;经计算得到的最优参数分别为惩罚因子C=7、不敏感损失函数ε=0.05,均方根误差RMSE为18.85。
与现有技术相比,本发明基于小样本集建模的支持向量回归算法模型的建立,有助于研究者快速,简便的筛选出高Φ
附图说明
图1为Φ
图2为用前n个描述符进行建模得到的模型相关系数和均方根误差。
图3为训练集的实验Φ
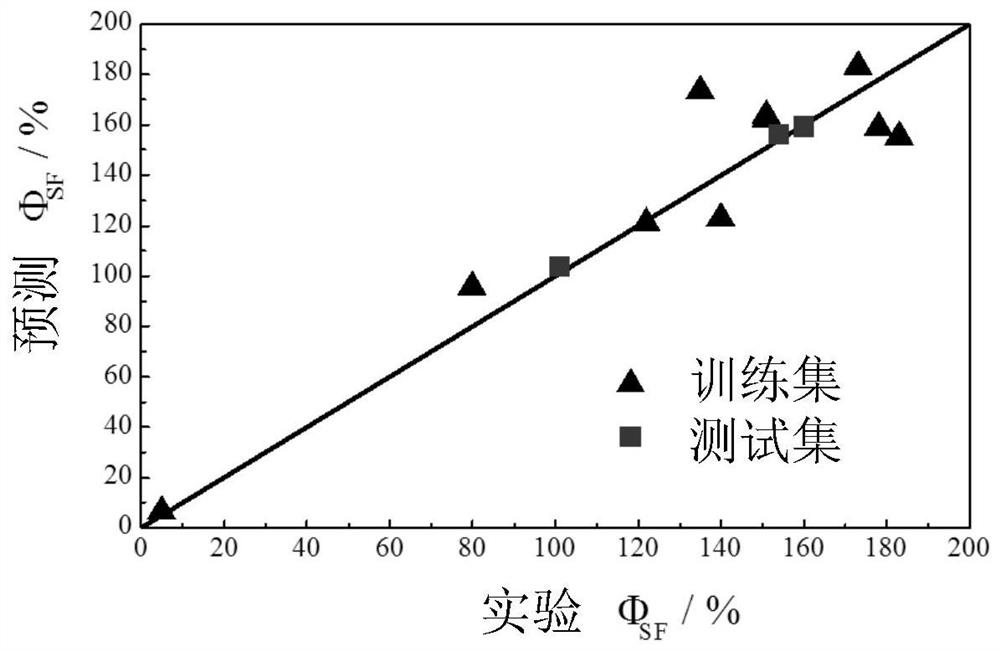
图4为训练集和测试集的实验Φ
图5为水合能(a,HE),三重态LUMO能级(b,E
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步的详细说明。此处所描述的具体实施例仅用于解释本发明,并不用于限定发明。
基于目前太阳能电池能量损耗较大的现状,对高能量转换效率的太阳能电池材料的研发需求越来越大,缩短研发周期、降低实验成本就变得越来越重要。本实施例提供了一种基于机器学习预测单重态裂分材料的三重态产率的方法,以下进行详细描述。
本实施例从现有文献中收集13个苝二酰亚胺衍生物分子,苝二酰亚胺衍生物分子的三重态产率Φ
表1
转换成分子描述符的具体方法为:采用数据挖掘软件进行数据挖掘,采用分子力学程序(MM+)对分子构象进行优化,用量子化学半经验算法PM3(该方位为现有技术,本实施例可以直接使用)计算得到1-11号分子描述符,12号描述符通过分子构型获得。然后将分子描述符随机分成训练集和测试集:
(1)10个分子的分子描述符作为训练集;
(2)3个分子的分子描述符作为测试集;用来测试模型的预报能力。
分子描述符中存在冗余或是不相关的描述符,建模的第一步是对分子描述符进行筛选,进行特征变量的筛选旨在不损失重要信息的情况下降低模型的维度。首先进行Φ
表2
选用特征变量过滤方法中的最大相关最小冗余(mRMR)特征选择方法筛选建模的特征变量。mRMR是一种滤波式的特征选择方法,使已选变量间的冗余度尽可能小的同时利用信息相关性或相似性分数来选择特征变量。经过mRMR筛选变量后,将候选描述符按照最大相关最小冗余顺序排列如下:HE,E
从图2中可以看出:当n从1上升到3时,R急剧上升,RMSE急剧下降;当n大于3时,R与RMSE的变化幅度较小。基于SVR建模的样本数量应大于变量数目的3倍原则,选择前三个描述符进行建模,分别为:水合能(HE)、三重态LUMO能级(E
表3
支持向量回归算法常用的核函数有线性核函数(LKF)、多项式核函数(PKF)和径向基核函数(RBF)。选择合适的核函数对建模和预测效果至关重要,采用支持向量机回归的留一法交叉验证(LOOCV)对上述三种核函数进行测试,结果见表4。根据预测结果的均方根误差RMSE选择合适的核函数,RMSE越小,说明选择的核函数越好。
表4
根据LOOCV测试结果,采用均方根误差RMSE最小的多项式核函数(SVR-PKF)作为建模核函数。选定核函数后,还需优化SVR建模中的参数,包括惩罚因子C、不敏感损失函数ε。采用LOOCV进行参数网格化搜索,以均方根误差RMSE最小为最优参数,参数优化的搜索范围和步长如下:设置惩罚因子C在1到100之间,步长为1;不敏感损失函数ε在0.01到0.1之间,步长为0.01。经计算得到的最优参数分别为惩罚因子C=7、不敏感损失函数ε=0.05,均方根误差RMSE为18.85。
基于上述结果,采用支持向量-多项式核函数算法与选定的三个特征变量,构建预测苝二酰亚胺衍生物的三重态产率Φ
预测苝二酰亚胺衍生物的三重态产率Φ
y=∑β
其中:X是未知矢量,X
预测苝二酰亚胺衍生物的三重态产率Φ
本文采用LOOCV和测试集结果评估所建立模型的预测能力。验证结果见图4,相关误差数据列于表5。在训练集中,LOOCV的均方根误差RMSE为18.85(使用留一法交叉验证优化的参数),相关系数R为0.93,平均相对误差13.98%。在测试集中,模型的平均相对误差为1.25%,可见该模型的预测能力是可靠的。
表5
根据所建SVR回归模型,特征变量水合能(HE)、三重态LUMO能级(E
进一步,为了验证本发明的可行性,基于建立的具有较好预报能力支持向量回归-多项式核函数算法,根据现有技术设计了三个苝二酰亚胺衍生物分子,这三种分子目前并无Φ
表6
根据预报结果,分子1和分子3可能具较高的Φ
用支持向量回归-多项式核函数算法建立苝二酰亚胺衍生物Φ
本发明的技术方案不限于上述具体实施例的限制,凡是根据本发明的技术方案做出的技术变形,均落入本发明的保护范围之内。
- 基于机器学习预测单重态裂分材料的三重态产率的方法
- 一种基于三重态‑三重态湮灭的固态上转换发光材料及其制备方法