一种面向特定领域的智能问答系统冷启动方法及装置
文献发布时间:2023-06-19 18:46:07
技术领域
本发明涉及自然语言处理技术领域,尤其涉及一种面向特定领域的智能问答系统冷启动方法及装置。
背景技术
在系统构建初期,缺乏有价值数据的时候,如何有效地满足业务需求的问题,即为“冷启动”问题。冷启动问题是机器学习系统中十分常见、无法回避的问题,因为任何机器学习系统都要经历从无到有的过程,冷启动能够保证在产品早期用户的使用要求。
问答系统是自然语言处理领域一个经典问题,它主要用于回答人们以自然语言形式提出的问题,在智能语音交互、在线客服、知识获取等场景中有着广泛的应用。智能问答模型通常是基于有监督式学习,这种学习方式通常十分依赖高质量文本,然而系统构建初期普遍面临缺乏有价值数据的压力和挑战,现有的面向智能问答系统的冷启动策略大多采用人工问答方式产生种子数据,或者是基于规则的方法按照特定模式自动生成用户问答数据集,所述两种方法虽然可以挖掘和积累一定数据量的原始问答集,但也存在一些不容忽视的问题。一方面,基于规则方式可以自动化、批量化地获取数据,但存在数据模式单一,数据缺乏真实性、数据质量参差不齐、数据混乱甚至无效等特点;另一方面,依赖人工方式实现大规模数据集的构造,容易使得制作数据集的成本过高,此外,数据标注任务受标注人员主观影响大,会引入一定的标注误差,导致数据一致性难以保证。
近年来,凭借着强大的泛化能力和对数据的高效利用,预训练模型已在自然语言处理、计算机视觉等多个领域取得了显著效果,特别是针对零样本和少样本学习场景,基于提示的预训练模型研究获得了长足发展,然目前为止,却鲜有看见预训练模型在冷启动场景中的应用。
发明内容
本发明的目的是克服现有技术存在的问题,提供了一种面向特定领域的智能问答系统冷启动方法和装置。
本发明通过以下技术方案来实现上述目的:
一种面向特定领域的智能问答系统冷启动方法及装置,包括以下步骤:
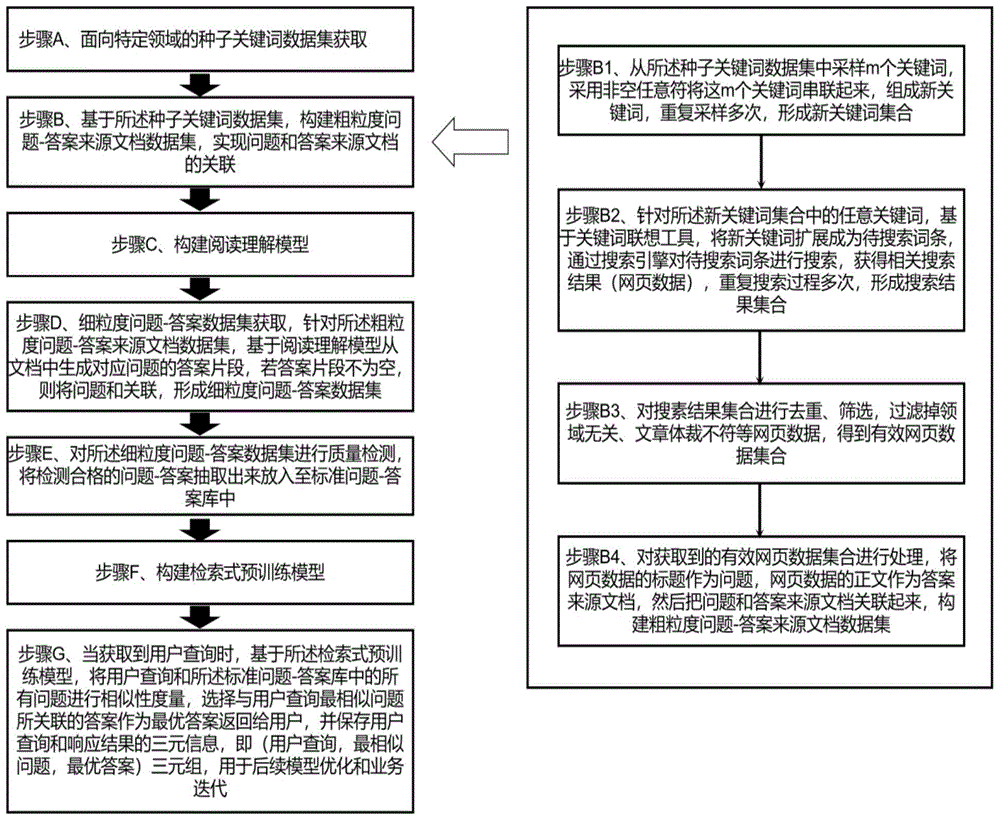
步骤A,获取面向特定领域的种子关键词数据集;
步骤B,基于种子关键词数据集,构建粗粒度问题-答案来源文档数据集,实现问题Q
步骤C,构建阅读理解模型;
步骤D,获取细粒度问题-答案数据集,对粗粒度问题-答案来源文档数据集,基于阅读理解模型从文档Doc
步骤E,对细粒度问题-答案数据集进行质量检测,将检测合格的问题-答案抽取出来放入至标准问题-答案库中;
步骤F,构建检索式预训练模型;
步骤G,当获取到用户查询时,基于所述检索式预训练模型,将用户查询和所述标准问题-答案库中的所有问题进行相似性度量,选择与用户查询最相似问题所关联的答案作为最优答案返回给用户,并保存用户查询和响应结果的三元信息,即(用户查询,最相似问题,最优答案)三元组,用于后续模型优化和业务迭代。
进一步方案为,所述步骤A中,获取特定领域种子关键词数据集的方法包括:由领域专家人工构建;基于统计的方法,如新词发现;从领域相关的开放数据源,如:网页、论文、专利等资料中,利用规则方法抽取种子关键词;结合上述方式构建种子关键词数据集。
进一步方案为,所述步骤B中,具体包括;
B1、从所述种子关键词数据集中采样m个关键词,采用非空任意符将这m个关键词串联起来,组成新关键词w,重复采样多次,形成新关键词集合Corpus_key;
B2、针对所述新关键词集合Corpus_key中的任意关键词w
B3、对搜素结果集合Corpus_search进行去重、筛选,过滤掉领域无关、文章体裁不符等网页数据,得到有效网页数据集合;
B4、对获取到的有效网页数据集合进行处理,将网页数据的标题作为问题,网页数据的正文作为答案来源文档,然后把问题和答案来源文档关联起来,构建粗粒度问题-答案来源文档数据集。
进一步方案为,所述步骤B1包括:
种子关键词数据集合的大小为n,每次从种子关键词数据集合中采样的关键词个数为m:1≤m≤n,完整采样过程结束后,新关键词集合的大小为:
所述步骤B2包括:
所述关键词联想工具t的个数为a,a≥1,获取的待搜索词条集合Corpus_entry为所有关键词联想工具针对所有新关键词扩展得到的词条的总和:
式(2)中的f指的是关键词扩展过程;
所述搜索引擎的个数为b,b≥1;获得的搜索结果(网页数据)集合为所有搜索引擎基于上述待搜索词条集合进行词条搜索而得到的搜索结果的总和:
式(3)中的g指的是词条搜索过程;
关键词联想工具包括:关键词联想API、关键词联想生成器等;
关键词联想API包括:百度搜索关键词联想API、谷歌搜索关键词联想API、搜狗搜索关键词联想API等;
关键词联想生成器包括各类开源、半开源、闭源等形式的关键词联想生成工具;
所述步骤B3包括:
对网页数据的分析主体包括:网页数据标题、网页数据正文,所述网页关联的其它相关数据、网页数据等;
过滤网页数据的方式包括:基于规则的方式、基于人工方式、基于规则与人工相结合方式。
进一步方案为,所述步骤C中,所述阅读理解模型类型可以为:抽取式阅读理解模型以及生成式阅读理解模型;
所述阅读理解模型具备两大功能:判别文档是否可用于回答相应问题;若文档可支持问题的回答,从文档中定位相应问题的答案;
所述阅读理解模型包括:开源预训练阅读理解模型、经过下游任务微调后的预训练阅读理解模型、从头开始训练获得的预训练阅读理解模型、以及各种开源、半开源、闭源形式的阅读理解模型。
进一步方案为,所述步骤D中,所述答案的获取,可以是单个阅读理解模型推理的结果,也可以是多个阅读理解模型综合决策的结果;
多模型综合决策的方式包括:投票、模型输出分布结果加权平均、stacking等其它多模型融合方法;
式(4)中的z为阅读理解模型个数,M(Q,Doc)为阅读理解模型从文档Doc中推理获得的对应问题Q的答案结果,U是模型融合决策方式。
进一步方案为,所述步骤E中,所述质量检测的维度包括:问题是否领域无关、问题所对应的答案是否正确,答案是否包含过多冗余、不相干信息等;
所述质量检测方式包括:基于规则的方式、基于人工方式、基于深度学习模型、多种策略相结合等方式。
进一步方案为,所述步骤F中,所述检索式预训练模型包括:开源预训练检索模型、经过下游任务微调后的预训练检索模型、从头开始训练获得的预训练检索模型、以及各种开源、半开源、闭源形式的检索模型。
进一步方案为,所述步骤G中,
首先基于所述检索式预训练模型对标准问题-答案库中的所有问题进行特征抽取,将问题Q
本发明另一方面还提供了一种面向特定领域的智能问答系统冷启动装置,包括:
种子关键词数据集获取模块,用于采集领域相关的关键词;
粗粒度问题-答案来源文档数据集获取模块,用于搜集问题和答案来源文档数据,并将两者关联,然后存储至数据库中;
阅读理解模型构造模块,用于获取阅读理解模型;
细粒度问题-答案数据集获取模块,基于阅读理解模型,从问题对应的答案来源文档中生成问题所需的答案片段,并将问题和答案片段关联起来,形成细粒度问题-答案数据集,然后存储至数据库中;
标准问题-答案数据集获取模块,用于对获取到的细粒度问题-答案数据集进行质量检测,并将检测合格的细粒度问题-答案数据集存放至数据库中,形成标准问题-答案数据集;
检索式预训练模型构造模块,用于获取检索式预训练模型;
在线问答模块,基于检索式预训练模型对用户查询进行推理,并返回答案给用户,同时将保存用户查询和响应结果的三元信息,即(用户查询,最相似问题,最优答案)三元组,用于后续模型优化和业务迭代。
本发明的有益效果在于:
本发明的一种面向特定领域的智能问答系统冷启动方法及装置,通过种子关键词与关键词联想工具的结合,可以批量化、自动化地搜集大规模形式多样、覆盖面广的问题-答案来源文档语料;采用阅读理解式预训练模型可以有效利用预训练模型的先验知识,高效地获取高质量问题-答案语料,大大节省人力;采用检索式预训练模型可以在无样本场景下保证模型问题检索性能。基于上述方式,可以高效、快捷、可靠地实现问答系统冷启动,即使在模型系统构建初期,也能保证模型上线效果。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要实用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中的一种面向特定领域的智能问答系统冷启动方法流程图;
图2为实施例中的一种面向特定领域的智能问答系统冷启动装置结构框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
实施例一
图1示出了本发明一种面向特定领域的智能问答系统冷启动方法的实施例一的流程图,包括:
A、面向特定领域的种子关键词数据集获取;
具体地,获取特定领域种子关键词数据集的方法可采用多种策略,如基于统计方法(新词发现)、基于规则的方法、人工构建方法、上述方法相结合等方式。
B、基于所述种子关键词数据集,构建粗粒度问题-答案来源文档数据集,实现问题Q
具体地,首先从所述种子关键词数据集中采样m个关键词,采用非空任意符将这m个关键词串联起来,组成新关键词w,重复采样多次,形成新关键词集合Corpus_key,然后针对所述新关键词集合Corpus_key中的任意关键词w
从所述种子关键词数据集中采样m个关键词,采用非空任意符将这m个关键词串联起来,组成新关键词w,重复采样多次,形成新关键词集合Corpus_key,具体地:
种子关键词数据集合的大小为n,每次从种子关键词数据集合中采样的关键词个数为m:1≤m≤n,完整采样过程结束后,新关键词集合的大小为:
针对所述新关键词集合Corpus_key中的任意关键词w
所述关键词联想工具t的个数为a,a≥1,获取的待搜索词条集合Corpus_entry为所有关键词联想工具针对所有新关键词扩展得到的词条的总和:
式(2)中的f指的是关键词扩展过程。
本实施例中所提及的关键词联想工具为:百度搜素关键词联想API,谷歌搜素关键词联想API,搜狗搜素关键词联想API。
所述搜索引擎的个数为b,b≥1。获得的搜索结果(网页数据)集合为所有搜索引擎基于上述待搜索词条集合进行词条搜索而得到的搜索结果的总和:
式(3)中的g指的是词条搜索过程。
本实施例中所提及的搜索引擎为:百度搜索,谷歌搜索,搜狗搜索。
对搜素结果集合Corpus_search进行去重、筛选,过滤掉领域无关、文章体裁不符等网页数据,得到有效网页数据集合,具体地:
对网页数据的标题、正文等数据进行分析,过滤掉领域无关、文章体裁不符等数据,例如诗歌、议论文、小说等体裁都是需被过滤掉的目标对象。
C、构建阅读理解模型;
具体地,所述阅读理解模型类型可以是抽取式阅读理解模型,也可以是生成式阅读理解模型。
本实施例中所提及阅读理解模型为抽取式开源预训练阅读理解模型,且该模型未被微调。
本实施例中所提及阅读理解模型具备两大功能:判别文档是否可用于回答相应问题;若文档可支持问题的回答,从文档中定位相应问题的答案。
本实施例中所提及的抽取式预训练阅读理解模型把阅读理解任务建模为输入问题和文档,在文档中预测出指示答案的起始和结束位置。若预测出的起始位置和结束位置都在“[CLS]”处,那么意味着文档不支持问题的回答,否则,根据预测的答案起始位置即可抽取出问题的答案片段。
D、细粒度问题-答案数据集获取,针对所述粗粒度问题-答案来源文档数据集,基于阅读理解模型从文档Doc
具体地,所述答案的获取,可以是一个阅读理解模型推理的结果,也可以是多个阅读理解模型综合决策的结果。
多模型综合决策可以采用多种策略,如投票、模型输出分布结果加权平均、stacking等其它多模型融合方法。
式(4)中的z为阅读理解模型个数,M(Q,Doc)为阅读理解模型从文档Doc中推理获得的对应问题Q的答案结果,U是模型融合决策方式。
本实施例中所采用的预训练阅读理解模型有:luhua/chinese_pretrain_mrc_roberta_wwm_ext_large,hfl/chinese-pert-large-mrc,luhua/chinese_pretrain_mrc_macbert_large。
本实施例中所采用的多模型决策策略为:将模型输出的答案起止位置的概率分布求和平均,获得最终的答案起止位置。
E、对所述细粒度问题-答案数据集进行质量检测,将检测合格的问题-答案抽取出来放入至标准问题-答案库中;
具体地,对阅读理解模型处理后的数据做进一步的质量检测,质量检测的范围包括:问题是否是领域无关、问题所对应的答案是否正确,预测出的答案信息是否包含过多冗余信息等。
质量检测的方式可以是基于规则的方式,也可以是基于人工的方式,还可以是规则与人工相结合的方式。
F、构建检索式预训练模型;
具体地,本实施例中所采用的检索式预训练模型为simbert,输入一段文本,模型输出的”[CLS]”词嵌入为该输入文本的特征向量表示。
G、当获取到用户查询时,基于所述检索式预训练模型,将用户查询和所述标准问题-答案库中的所有问题进行相似性度量,选择与用户查询最相似问题所关联的答案作为最优答案返回给用户,并保存用户查询和响应结果的三元信息,即(用户查询,最相似问题,最优答案)三元组,用于后续模型优化和业务迭代。
具体地,首先基于simbert模型对标准问题-答案库中的所有问题进行特征抽取,将问题Q
实施例二
图2示本发明一种面向特定领域的智能问答系统冷启动装置的结构示意图,包括:
种子关键词数据集获取模块,用于采集领域相关的关键词;
粗粒度问题-答案来源文档数据集获取模块,用于搜集问题和答案来源文档数据,并将两者关联,然后存储至数据库中;
阅读理解模型构造模块,用于获取阅读理解模型;
细粒度问题-答案数据集获取模块,基于阅读理解模型,从问题对应的答案来源文档中生成问题所需的答案片段,并将问题和答案片段关联起来,形成细粒度问题-答案数据集,然后存储至数据库中;
标准问题-答案数据集获取模块,用于对获取到的细粒度问题-答案数据集进行质量检测,并将检测合格的细粒度问题-答案数据集存放至数据库中,形成标准问题-答案数据集;
检索式预训练模型构造模块,用于获取检索式预训练模型;
在线问答模块,基于检索式预训练模型对用户查询进行推理,并返回答案给用户,同时将保存用户查询和响应结果的三元信息,即(用户查询,最相似问题,最优答案)三元组,用于后续模型优化和业务迭代。
通过本发明实施例二提供的一种面向特定领域的智能问答系统冷启动装置,利用种子关键词与关键词联想工具的结合,可以批量化、自动化地搜集大规模形式多样、覆盖面广的问题-答案来源文档语料;采用阅读理解式预训练模型可以有效利用预训练模型的先验知识,高效地获取高质量问题-答案语料,大大节省人力;采用检索式预训练模型可以在无样本场景下保证模型问题检索性能。基于上述方式,可以高效、快捷、可靠地实现问答系统冷启动,即使在模型系统构建初期,也能保证模型上线效果。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 一种用排气加热进气的发动机智能冷启动装置及控制方法
- 一种面向智能应用的领域本体构建方法
- 一种面向人工智能领域知识的高效智能问答系统
- 一种面向汽车领域的智能问答系统