一种基于脑电互信息的多源流形嵌入特征选择方法
文献发布时间:2023-06-19 18:46:07
技术领域
本发明属于神经系统运动控制机制研究领域,主要涉及到脑电信号预处理,脑电信号流形特征提取,流形特征选择,多源域迁移框架设计,具体指一种基于脑电互信息的多源流形嵌入特征选择方法。
背景技术
情绪是人类特有的生理活动,包括情绪的表达、情绪的识别和情绪的转化等,它反映了人类对外界刺激的心理和生理反应,可以用一些科学的方法来测量和识别。利用计算机进行人类情感识别是人工智能、认知科学和情感脑机交互(affective brain-computerinterface,aBCI)的重要组成部分。人们期望机器可以基于人类的情感与自己交流。因此,情感识别在实现这一目的中起着至关重要的作用,在人工智能技术支持下的人类健康情感护理和患者监护等各种应用中都具有很大的实用价值。
在aBCI中,情绪识别常用的输入信号包括视频、文本、音频、生理信号等。与这些信号相比,脑电信号(electroencephalogram,EEG)具有更好的可靠性和准确性,能够更真实地反映个体的情绪状态,使其成为aBCI中应用最广泛的输入信号。一个典型的aBCI范式操作如下:首先,将诱发特定情感的情感刺激呈现给用户,并根据期望的情感记录脑电信号;然后,从记录的信号中提取EEG数据特征,并使用所选择的特征和情感标签来训练分类器。在接下来的aBCI中,利用已经训练好的分类器来执行基于脑电信号的实时情感分类。许多研究人员已经报告了在该范例下令人满意的分类性能。然而,aBCI的使用仍然受到一些因素的限制。具体地说,脑电信号具有很大的非平稳性和个体差异性,不同受试者的脑电数据分布存在很大差异。即使在同一受试者中,不同时段的脑电数据分布也往往不同。传统的机器学习方法需要事先假设训练数据和测试数据的分布是独立的和同分布的。然而,EEG信号并不总是满足这一假设,这使得这些方法在情感识别方面只取得了较差的性能。并且脑电极易受噪声干扰。为了减少被试的训练时间和提高准确率与适应性,设计和实现具有自适应能力强、情绪识别准确率高的脑电信号解析模型,很多研究团队陆续开始研究迁移学习理论和方法,寻找一种适用于所有被试的通用算法模型,解决aBCI系统实用化过程中亟待解决的共性关键基础科学问题。
迁移学习是一种机器学习技术,旨在从一个或多个源任务中提取共同知识,并将这些知识应用于相关的目标任务。具体地说,情绪识别中的迁移学习使用源域(来自其他用户的脑电数据)来帮助目标域(来自新用户的脑电数据)进行学习。它的主要任务之一是通过映射减少源域和目标域之间的数据分布差异。
近年来,迁移学习在aBCI领域得到了广泛的应用。一些研究人员提出了各种领域自适应方法。PANSJ等人提出了迁移成分分析(transfer components analysis,TCA),它以核函数的形式解决了映射问题,将源和目标域数据投影到一个新的子空间中,以减少分布差异。联合分布自适应(joint distribution adaptation,JDA)考虑了不同域之间的边缘分布和条件分布,这是对TCA的改进。Wang等人指出,在实际应用中,边缘分布和条件分布往往被同等对待,而彼此的重要性却没有被利用,因此提出了均衡分布自适应,以自适应地利用边缘分布和条件分布差异的重要性。流形嵌入分布对齐(Manifold embeddeddistribution alignment,MEDA)在Grassmann流形上执行动态分布对齐,然后学习一个域不变的分类器来避免特征失真。传统的迁移学习方法旨在解决单源域到单源域迁移问题,在实验中,我们可以发现,即使使用最简单的迁移学习算法,一个好的源域也有助于获得非常高的分类精度,因此源域的质量非常重要。然而,实际上我们很可能有多个源域,就像BCI设备往往有很多以前使用过的标记数据一样,多源迁移学习在情绪识别中,也通常能够获得比单源迁移学习更好的识别精度。当存在多个源域时,好的源域更有可能被包括在内。但是,多源迁移中,许多aBCI的相关工作倾向于将所有源域合并为一个域,这意味着所有受试者的脑电数据都需要使用,而在一些实际应用中,一些与目标数据相关性较差的受试者的脑电数据可能不适合应用于迁移,也就是说这些源域并不是好的源域。如果强行使用会造成负迁移。以这种方式训练的模型不会有很好的泛化性能。因此,在多源迁移学习中,有必要选择合适的知识输出源。因此需要一种源域选择方法,来确定源域对于目标域是否合适进行迁移,包括域秩(rank of domains,ROD)(Gong等)、域迁移性估计(domaintransferability estimation,DTE)(Zhang&Wu,2020)、域间相似度系数(domainsimilarity rank,孙等)。
发明内容
本发明针对现有脑电迁移学习方法在负迁移、提取的脑电特征冗余度高等方面存在的问题,提出了一种基于脑电互信息的多源流形嵌入特征选择方法,能够减少对新的标记数据的需求,提升源域质量,减小源域和目标域的样本分布差异,进行多源脑电迁移学习。
为实现上述目的,本发明方法主要包括以下步骤:
步骤(1),对脑电信号进行预处理,按频段提取脑电微分熵特征。
步骤(2),对多个源域数据进行筛选,选择高质量源域;
步骤(3),将脑电信号特征变换到流形空间,进一步提取流形特征。
步骤(4),对脑电流形特征进行相关性和冗余性分析,降低特征维度。
步骤(5),将降维之后的流形特征进行迁移,学习最终分类器用于预测标签。
步骤(6),根据分类器结果,对目标域的多组识识别结果进行加权融合,得到最终分类结果。
作为优选,在进行源域选择时,利用每个源域数据进行预训练得到分类器,应用于少量已有标签的目标域数据,进行筛选。具体步骤如下:
步骤2-1:针对每一个目标域的脑电信号微分熵特征,将其分为有标签的目标域数据
步骤2-2:对每一个源域A
步骤2-3:根据排序结果,选择准确率排序较高的几个分类器所训练的数据作为合适的源域,进行后续的迁移。
作为优选,所述步骤4包括:
步骤4-1:根据源域数据的脑电流形特征x,其对应的标签类别c,分别计算特征与标签之间的相关性D,特征与特征之间的相关性R:
其中,I(·,·)为互信息大小,S为特征集合。
步骤4-2:区别于用公式(3)作为评价函数指导特征子集选择进行降维,引入指示向量β和参数k定义新的评价函数公式(4)。
maxφ(D,R)=D-R (3)
其中,k为最终特征维度,β=[β
步骤4-3:对于上一步骤目标函数(4),利用增量搜索方法,最大化一个二次函数,求解得到指示向量β和最终特征维度k,分别从源域和目标域数据中按照上述参数选择新的源域特征数据集F′
作为优选,所述步骤6包括:
针对多组源域数据,得到了多组目标域数据识别准确率之后,将各个分类器的识别准确率作为权重,对最终的预测标签进行加权融合,每个样本的加权融合计算方式如公式(5):
其中,n为源域的序号,w为权重,
本发明与现有的迁移学习方法相比,具有如下优点:
传统的脑电迁移学习方法没有充分利用多源域的数据信息,单源域迁移学习的效果不如多源域;并且,存在的多源域迁移学习往往很直接的将多个源域直接整合成一个大源域,没有考虑到低质量源域的存在,导致学习模型的泛化能力不足,出现负迁移;同时脑电特征存在冗余度高,特征维度高,导致计算成本大。针对这些问题,本发明提出了一种新型的一种基于脑电互信息的多源流形嵌入特征选择方法。本方法简单直观,相较于普通的无监督选择方法更加快速有效,同时进一步降低了脑电流形特征的维度,在提升了源域质量的同时,进一步提升了脑电特征的质量,减少特征冗余度,降低了计算复杂度,是一个有效的多源迁移学习框架。
附图说明
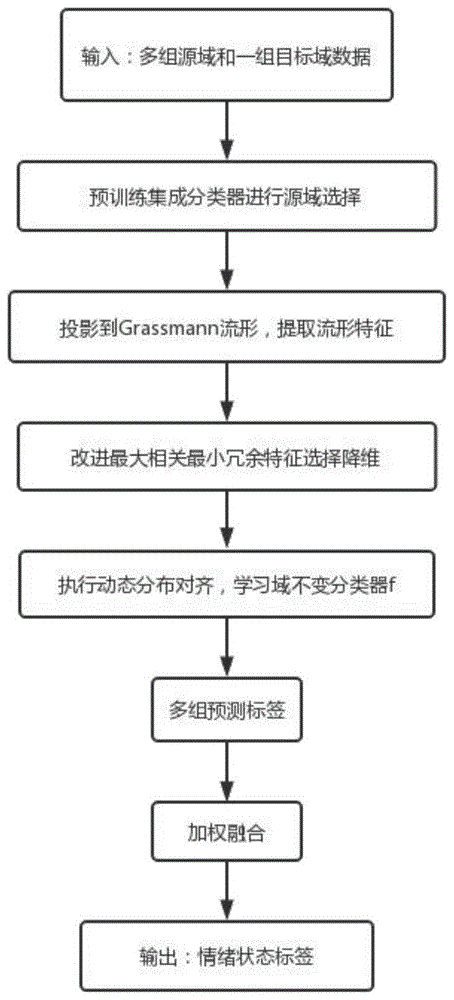
图1为本发明实施例的方法流程图。
图2为本发明方法的算法框架图。
图3为源域个数对于受试者情绪识别准确率曲线的影响。
图4为本发明方法在SEED数据集上与各种领域自适应方法的识别准确率对比。
图5为本发明方法在DEAP数据集上与各种领域自适应方法的识别准确率对比。
具体实施方式
下面结合附图对本发明的实施例作详细说明,图1为算法框架图。以下描述仅作为示范和解释,并不对本发明做任何形式上的限制。
实施例1
本文使用的数据集分别为SEED数据集和DEAP数据集。具体描述如下:
(1)SEED,它是由上海交通大学吕宝粮教授团队提供的开源情感脑电数据集。SEED数据集记录了15名受试者(7名男性和8名女性,平均年龄为25岁)在观看不同类型电影视频片段时的脑电数据。每个被试参与了3个实验,每个实验间隔约1周,每个实验包括15个情绪诱导实验,分别诱发积极情绪、中性情绪和负面情绪。每个试验包括开始的5s提示、片段刺激、45s的自我评估和15s的休息时间。原始脑电信号以1000Hz的采样率记录下来,下采样到200Hz,然后用0~75Hz的带通滤波器进行滤波。
(2)DEAP,这是Kolestra等人为情感计算收集和发布的另一个公共数据集。它收集了32名受试者的生理电信号。脑电信号由40通道电极帽记录,包括32路脑电信号和8路外周生理信号。每个受试者的实验包括40个情绪唤起视频。观看完视频后,受试者被要求对自我评估模型(self-assessment manikins,SAM)的效价、唤醒、优势和喜爱程度进行从1到9的连续评分。原始脑电信号以512Hz的采样率记录下来,经4~45Hz的带通滤波后,下采样降至128Hz,然后分成60s的实验数据和3s的基线数据。
如图1和图2所示,本发明的实施例实现步骤如下:
步骤1,对脑电信号进行预处理,按频段提取脑电微分熵特征,具体步骤如下:
对于一段时间的序列的EEG信号x,其微分熵特征定义为:
h(x)=-∫f(x)log[f(x)]dx (6)
其中,f(x)是EEG信号的概率密度函数,经过带通滤波之后,EEG信号的时间序列服从高斯分布N(μ,σ
根据公式(7),即可计算出每个样本的EEG微分熵特征;
步骤2,根据步骤一得到的EEG微分熵特征,对每个目标域进行源域选择,具体步骤如下:
步骤2-1:针对每一个目标域的脑电信号,利用公式(7)计算得到微分熵特征,并将其分为有标签的目标域数据
步骤2-2:对每一个源域A
步骤2-3:根据排序结果,得到不同源域的可迁移值权重,并根据此权重,除去i个源域,将剩余的数据作为合适的源域进行后续的迁移。
步骤3,将脑电信号特征变换到流形空间,进一步提取流形特征,具体步骤如下:
步骤3-1:引入测地线流式核方法(Geodesic Flow Kernel,GFK),将原始EEG微分熵特征变换到Grassmann流形G中,完成流形特征变换。测地线流式核GFK的定义如下:
其中,x
步骤3-2:根据求解出来的半正定矩阵G,变换后的特征z可以通过公式
步骤4,得到EEG流形特征之后,根据改进的最大相关和最小冗余方法对特征进行降维,选择更具代表性的特征,具体步骤如下:
步骤4-1:根据源域数据的脑电流形特征x,其对应的标签类别c,分别计算特征与标签之间的相关性D,特征与特征之间的相关性R:
其中,I(·,·)为互信息大小,S为特征集合。
步骤4-2:区别于用公式(11)作为评价函数指导特征子集选择进行降维,引入指示向量β和参数k定义新的评价函数公式(12)。
maxφ(D,R)=D-R (11)
其中,k为最终特征维度,β=[β
步骤4-3:对于上一步骤目标函数(12),利用增量搜索方法,最大化一个二次函数,求解得到指示向量β和最终特征维度k,分别从源域和目标域数据中按照上述参数选择新的源域特征数据集F′
步骤5,得到新的目标域和源域的特征数据集之后,对其进行动态分布对齐,同时适配边缘分布和条件概率分布,最终学习到一个域不变的分类器f,具体步骤如下:
步骤5-1:执行动态分布对齐
其中,μ∈[0,1],衡量边缘分布和条件概率分布的重要性。D
步骤5-2:引入MMD(maximum mean discrepancy)距离来计算上述差异,不同分布p和q之间的MMD距离定义为:
式中,HK为特征映射φ(·)张成的再生希尔伯特空间(reproducing kernelHilbert space,RKHS),E(·)为嵌入样本的均值。
步骤5-3:最后,基于结构风险最小化(structural risk minimization,SRM)原理,一个域不变的分类器f可以表示为:
式中,前两项为源域数据的损失,
步骤6,根据上一步骤得到的分类器f,可以得到每一组源域对于目标域的预测标签和准确率,根据多组分类器的识别结果进行加权融合,得到最终分类标签和识别准确率,具体步骤如下:
针对多组源域数据,得到了多组目标域数据识别准确率之后,将各个分类器的识别准确率作为权重,对最终的预测标签进行加权融合,每个样本的加权融合计算方式如公式(16):
其中,n为源域的序号,w为权重,
本发明在SEED数据集和DEAP数据集上,均以15个受试者为实验对象,选择1名受试者为目标域,剩余14名为源域,进行实验,整个过程重复15次,以确保每名受试者都会作为目标域。实验结果如图3、图4和图5所示。图3给出了SEED数据集上每位受试者的识别准确率随源域个数的增长的变化曲线,可以看到源域个数从1增长至7时,准确率开始上升,源域个数从7增长至14时,准确率曲线开始稳定,甚至出现下滑,说明存在一些质量不好的源域,导致了负迁移的产生,因此源域个数选择7个,可以有效的去除坏的源域。图4、图5给出了本发明方法和各种领域自适应方法在SEED和DEAP上对于每位受试者的识别准确率对比,可以看出本方法在绝大多数的受试者上都取得了最好的识别准确率,说明了本方法提出的多源流形脑电特征领域自适应方法的有效性。
以上所述的实施例仅仅是对本发明的优选实例方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。