计算设备、计算设备的操作方法、电子设备和存储介质
文献发布时间:2023-06-19 19:30:30
技术领域
本公开概括而言涉及处理器领域,更具体地,涉及一种计算设备、计算设备的操作方法、电子设备和计算机可读存储介质。
背景技术
在诸如人工智能(AI)、机器学习(ML)之类的应用中,由于需要执行大量矢量运算、标量运算、卷积运算等多种类型的运算,通常采用包含多个不同计算核的计算设备来执行不同的运算以协同完成一个或多个工作任务。在构造这样的计算设备时,通常使用某种编程模型对这些计算核进行配置和调度以协同执行这些工作任务。
然而,编程模型通常只适用于某种特定架构的计算设备,在计算设备的架构改变后,同一编程模型通常不再适用,需要耗费大量的工作来重新设计新的编程模型。即使仅仅是计算设备中包含的多种计算核中的某种计算核的数量或算力发生变化,也需要重新设计新的编程模型。
发明内容
针对上述问题,本公开提供了一种在计算设备中的某种计算核的数量或算力发生变化时,无需改变计算设备的编程模型,而是通过将计算簇划分为多个子计算簇并且使得一次为每个子计算簇而不是为整个计算簇调度一个计算任务来完成该计算簇的计算负载的方案。
根据本公开的一个方面,提供了一种计算设备。该计算设备包括:计算簇,所述计算簇包括第一计算核和不同于所述第一计算核的多个第二计算核,其中所述多个第二计算核被划分为N个子计算簇,N为大于1的整数;以及调度器,其被配置为每次向所述计算簇调度N个计算任务,其中所述计算簇被配置为将所述N个计算任务分别分配给所述N个子计算簇。
在一些实现中,所述第一计算核的计算能力大于所述第二计算核。
在一些实现中,所述第一计算核包括用于执行卷积运算或者矩阵乘法的张量计算核,所述第二计算核包括用于执行标量和/或矢量运算的计算单元。
在一些实现中,所述N个子计算簇中的每个子计算簇被配置为:在确定分配给所述子计算簇的计算任务中存在需要所述第一计算核执行的部分计算任务时,向所述部分计算任务添加与所述子计算簇对应的子簇标识符,并将所述部分计算任务和所述子簇标识符一起发送给所述第一计算核;并且所述第一计算核被配置为对所述部分计算任务进行处理并且将所述部分计算任务的处理结果返回给与所述子簇标识符对应的子计算簇。
在一些实现中,所述第一计算核包括N个累加器,每个累加器对应于所述N个子计算簇中的一个子计算簇,并且所述累加器被配置为在所述第一计算核处理来自所述子计算簇的部分计算任务时,存放所产生的累加结果。
在一些实现中,所述多个第二计算核被划分为2个子计算簇。
根据本公开的另一个方面,提供了一种计算设备的操作方法。所述计算设备包括计算簇和调度器,所述计算簇包括第一计算核和不同于所述第一计算核的多个第二计算核。所述方法包括:将所述多个第二计算核划分为N个子计算簇,N为大于1的整数;每次向所述计算簇调度N个计算任务以使得所述计算簇将所述N个计算任务分别分配给所述N个子计算簇。
在一些实现中,所述第一计算核的计算能力大于所述第二计算核。
在一些实现中,所述第一计算核包括用于执行卷积运算或者矩阵乘法的张量计算核,所述第二计算核包括用于执行标量和/或矢量运算的计算单元。
在一些实现中,所述方法还包括:在所述N个子计算簇中的每个子计算簇确定分配给所述子计算簇的计算任务中存在需要所述第一计算核执行的部分计算任务时,由所述子计算簇向所述部分计算任务添加与所述子计算簇对应的子簇标识符,并将所述部分计算任务和所述子簇标识符一起发送给所述第一计算核;并且由所述第一计算核对所述部分计算任务进行处理并且将所述部分计算任务的处理结果返回给与所述子簇标识符对应的子计算簇。
在一些实现中,所述第一计算核包括N个累加器,每个累加器对应于所述N个子计算簇中的一个子计算簇,并且所述方法还包括:在所述第一计算核处理来自所述子计算簇的部分计算任务时,由所述累加器存放所产生的累加结果。
在一些实现中,所述多个第二计算核被划分为2个子计算簇。
根据本公开的又一个方面,提供了一种电子设备,包括:存储器,非瞬时性地存储有计算机可执行指令;处理器,配置为运行所述计算机可执行指令;其中,所述计算机可执行指令被所述处理器运行时实现如上所述的方法。
根据本公开的再一个方面,提供了一种计算机可读存储介质,其上存储有计算机程序代码,该计算机程序代码在被运行时执行如上所述的方法。
附图说明
通过参考下列附图所给出的本公开的具体实施方式的描述,将更好地理解本公开,并且本公开的其他目的、细节、特点和优点将变得更加显而易见。
图1示出了一种计算设备的示例性结构示意图。
图2示出了根据本公开一些实施方式的计算设备的示例性结构示意图。
图3示出了根据本公开实施例的计算设备的操作方法的示意性流程图。
具体实施方式
下面将参照附图更详细地描述本公开的优选实施例。虽然附图中显示了本公开的优选实施例,然而应该理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
在本文中使用的术语“包括”及其变形表示开放性包括,即“包括但不限于”。除非特别申明,术语“或”表示“和/或”。术语“基于”表示“至少部分地基于”。术语“一个实施例”和“一些实施例”表示“至少一个示例实施例”。术语“另一实施例”表示“至少一个另外的实施例”。术语“第一”、“第二”等等可以指代不同的或相同的对象。
图1示出了一种计算设备10的示例性结构示意图。如图1中所示,计算设备10可以包括一个或多个计算簇100(图1中仅示例性地示出了一个计算簇100),每个计算簇100可以包括一个或多个第一计算核110和一个或多个第二计算核120。
第一计算核110和第二计算核120可以具有不同的计算能力(即算力),这里假设第一计算核110的计算能力大于第二计算核120,因此一个计算核110可以服务于多个第二计算核120。在本文中,以每个计算簇100包含一个第一计算核110和多个第二计算核120为例进行描述,例如图1中示例性地示出了4个第二计算核120。在一些实施例中,例如在用于神经网络计算的场景中,计算设备10可以是一个单独的图形处理单元(Graphics ProcessingUnit,GPU),第一计算核110可以包括用于执行卷积运算或者矩阵乘法的张量计算核(Tensor Core,TC),其可以用作AI加速器,第二计算核120可以包括用于执行标量和/或矢量运算的计算单元(Compute Unit,CU)。每个第二计算核120例如可以包含一个或多个标量计算单元和/或一个或多个矢量计算单元以及其他计算单元(如特殊函数运算单元)等。这里,第二计算核120中的矢量计算单元可以是用于通用计算的单指令多线程(SIMT)单元。
计算设备10还可以包括调度器130,其被配置为每次为一个计算簇100分配一个计算任务。
在设计计算设备10时,可以利用编程模型将一个应用负载划分为多组较小的负载并分配给不同的计算簇100来进行处理。每组较小的负载可以被称为一个计算任务。在本文的上下文中,计算任务也可以称为宽线程组(Wide Thread Group,WTG)。编程模型在将一个应用负载划分为多个计算任务之后,可以通过调度器130将这些计算任务映射给不同的计算簇100以由每个计算簇100处理一个计算任务。在处理该计算任务时,可以在第一计算核110和多个第二计算核120之间进行数据映射和转移,并且利用相应的同步资源(如WTGBarrier(WTG屏障))实现第一计算核110和第二计算核120之间的同步。具体地,计算簇100可以从调度器130接收一个计算任务,在确定该计算任务中存在需要由第一计算核110处理的部分(如张量运算或矩阵乘法)时,将该部分传送给第一计算核110进行处理并且从第一计算核110接收该部分的处理结果。
在一些情况下,计算设备10中所包含的第一计算核110或第二计算核120的数量可能发生改变,从而计算设备10的硬件结构发生改变。例如,在第一计算核110的算力提高而第二计算核120的算力不变的情况下,一个第一计算核110可以服务于更多的第二计算核120,从而计算设备10的一个计算簇100中可以包含一个第一计算核110和更多的第二计算核120。或者,为了处理具有更多矢量计算的应用,计算设备10中的第二计算核120的数量需要增加,而第一计算核110的数量保持不变。在这种情况下,计算设备10的硬件都将发生改变,硬件的改变又将带来很多指令级改变。例如,如果将图1所示的计算设备10中的每个计算簇100中的第二计算核120的数量增加为8个,则每个第二计算核120的工作负载将从总WTG数的1/4变为总WTG数的1/8,每个第二计算核120接收的第一计算核110的输出变为原来的1/2,每个计算簇100的归约槽数变为原来的2倍,并且WTG同步所需的线程束(Warp)数变为原来的2倍。
这些指令级改变将会应产生后向兼容问题。可能需要修改以前的编程模型来使其可以运行在更新一代硬件上。如果应用程序被编译为虚拟指令集架构,则实时编译器可能会失败,因为该差异非常基础,即使是虚拟的ISA也不能隐藏。虽然可以要求应用开发者通过查询第二计算核120的数量来根据第二计算核120的数量前向兼容,但是这将会使得应用开发者混淆。
鉴于上述情况,在本文中,提供了一种在第二计算核的数量增加从而计算设备的硬件结构发生改变时,通过将第二计算核划分为多个子计算簇并且每次为一个计算簇调度多个计算任务以使得一个子计算簇对应于一个计算任务,从而使得能够在计算设备的编程模型不变的情况下,完成计算设备的计算负载。
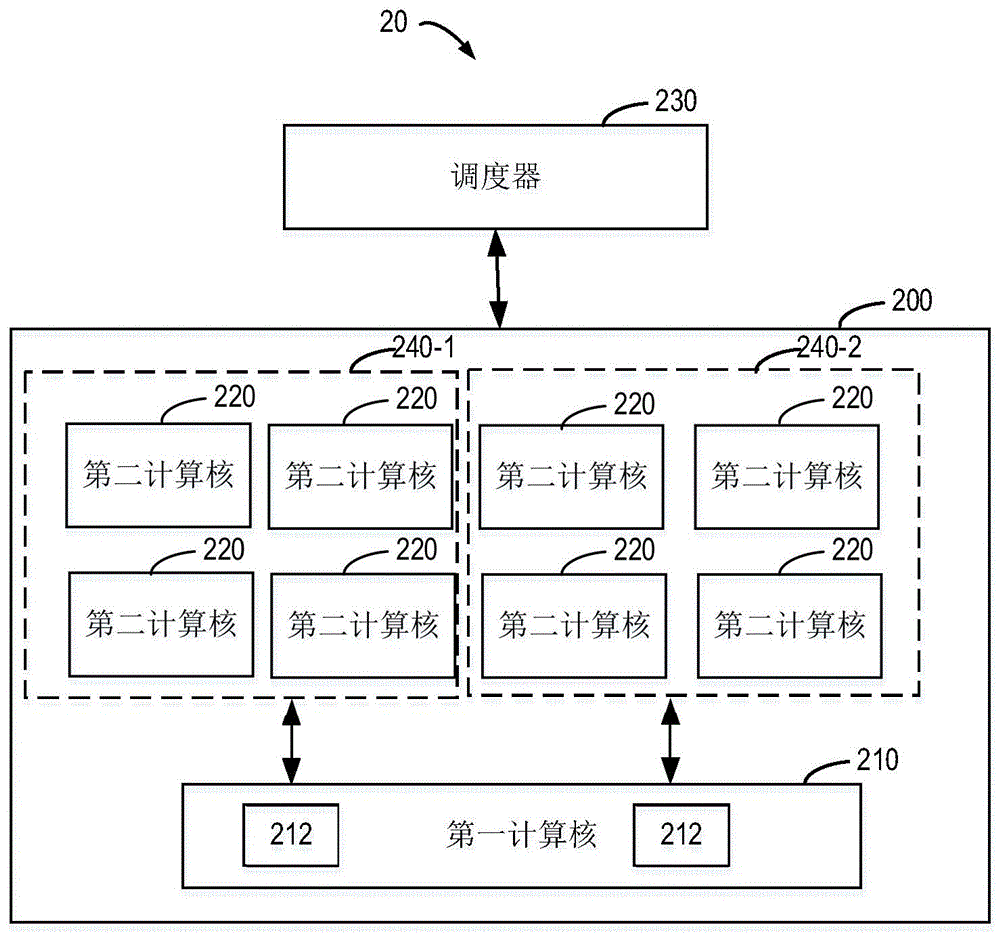
图2示出了根据本公开一些实施方式的计算设备20的示例性结构示意图。与图1中类似,图2所示的计算设备20可以包括一个或多个计算簇200(图2中也仅示例性地示出了一个计算簇200),每个计算簇200可以包括一个或多个第一计算核210和一个或多个第二计算核220。计算设备20还可以包括调度器230,用于向计算簇200调度计算任务。其中关于第一计算核210、第二计算核220和调度器230的描述可以参见上述结合图1对第一计算核110、第二计算核120和调度器130的描述。
图2所示的计算设备20与图1所示的计算设备20的主要不同之处在于每个计算簇200中的第二计算核220的数量大于计算簇100中的第二计算核120。更进一步地,假设每个计算簇200中的第二计算核220的数量是计算簇100中的第二计算核120的N倍(N为大于1的整数)。图2中示例性地显示了每个计算簇200中包含8个第二计算核220,即N=2。注意,这里假设图2中的第二计算核220的算力与图1中的第二计算核120相同,而图2中的第一计算核210的算力与图1中的第一计算核110可以相同或不同。
如上所述,每个计算簇中的第二计算核的数量增加将带来大量的指令级改变,从而需要对编程模型进行修改或重写以适应硬件的改变,这对于应用开发人员来说增加了额外的负担。在本公开的方案中,通过根据前一代计算设备10中的计算簇100中的第二计算核120的数量将新一代的计算设备20中的每个计算簇200中的第二计算核220划分为多个子计算簇来使得能够在几乎不改变编程模型的情况下使用新一代的计算设备20。
具体地,如图2中所示,假设计算簇200中的第二计算核220的数量是计算簇100中的第二计算核120的数量的N倍,则在计算设备20中,可以将多个第二计算核220划分为N个子计算簇240。图2中示例性地示出了2个子计算簇240-1和240-2。
在这种情况下,与调度器130不同,调度器230被配置为每次向一个计算簇200调度N个计算任务,例如每次调度N个WTG而不是一个WTG。在对编程模型几乎不进行修改或仅进行微小修改的情况下,调度器230可以在一个调度周期一次向一个计算簇200调度N个计算任务,或者可以在N个连续的调度周期每次向计算簇200调度一个计算任务。如上述结合图1所述,计算任务是利用编程模型对应用负载进行划分产生的,因此这里的计算任务可以利用同样的编程模型按照同样的方式来进行划分,无需对编程模型进行修改。
计算簇200可以进一步将被调度的N个计算任务分别分配给N个子计算簇240,从而使得每个子计算簇240对应于一个计算任务。这样,每个子计算簇240可以如计算簇100那样来完成对应的计算任务。
由于一个计算簇200中的多个子计算簇240共享同一第一计算核210,因此应当为每个子计算簇240分配专用的子簇标识符,以用于子计算簇240与第一计算核210之间的数据传输。
具体地,子计算簇240在处理分配给它的计算任务时,如果确定存在需要第一计算核210执行的部分计算任务(如卷积运算或者矩阵乘法)时,其可以向该部分计算任务添加与该子计算簇240对应的子簇标识符,并将该部分计算任务和该子簇标识符一起发送给第一计算核210。在这种情况下,第一计算核210可以对该部分计算任务进行处理并且将处理结果返回给与该子簇标识符对应的子计算簇240。
例如,如图2中所示,如果子计算簇240-1需要将其部分计算任务发送给第一计算核210,则其会将其子簇标识符(如SCC-1)与该部分计算任务一起发送给第一计算核210。第一计算核210在对该部分计算任务进行处理之后,会将处理结果返回给子簇标识符为SCC-1的子计算簇240-1。
此外,由于多个子计算簇240共享同一第一计算核210,第一计算核210在处理来自不同子计算簇240的计算任务时,需要区分各个子计算簇240的累加结果。为此,第一计算核210还应当包括N个累加器212,其中每个累加器212对应于一个子计算簇240。每个累加器212倍配置为在处理来自对应的子计算簇240的部分计算任务时,存放所产生的累加结果。通过这种方式,可以利用第一计算核210中的不同的累加器212来区分不同子计算簇240的累加结果,以避免各个子计算簇240的计算任务的执行过程中出现错乱。
注意,与图2所示的计算设备20不同,图1所示的计算设备10的第一计算核110中可以仅包括一个累加器(图中未示出)。
利用上述方案,与图1所示的计算设备10相比,图2所示的计算设备20的每个第二计算核220的工作负载、每个第二计算核120接收的第一计算核110、每个计算簇200的归约槽数以及WTG同步所需的线程束(Warp)数都保持不变,从而整个编程模型可以保持不变,无需重写计算设备上运行的应用程序的软件代码,从而容易地实现了后向兼容。
图3示出了根据本公开实施例的计算设备20的操作方法300的示意性流程图。计算设备20的操作方法300可以利用如上所述的编程模型执行或者由编程模型与计算设备20的组成部分一起执行。
如图3中所示,在方框310,可以将计算设备20的计算簇200的多个第二计算核220划分为N个子计算簇240,其中N为大于1的整数。
在方框320,每次向计算簇200调度N个计算任务以使得计算簇200可以将该N个计算任务分别分配给N个子计算簇240。
在一些实施例中,方法300还可以包括方框330,其中在N个子计算簇240中的每个子计算簇240确定分配给该子计算簇240的计算任务中存在需要第一计算核210执行的部分计算任务时,由该子计算簇240向该部分计算任务添加与该子计算簇240对应的子簇标识符,并将该部分计算任务和该子簇标识符一起发送给第一计算核210。
在这种情况下,方法300还可以包括方框340,其中由第一计算核210对该部分计算任务进行处理并且将该部分计算任务的处理结果返回给与该子簇标识符对应的子计算簇240。
在一些实施例中,第一计算核210可以包括N个累加器212,每个累加器212对应于第二计算核220的一个子计算簇240,如图2中所示。在这种情况下,累加器212可以在第一计算核210处理来自该子计算簇240的部分计算任务时,存放所产生的累加结果。
本领域技术人员可以理解,图2所示的计算设备20仅是示意性的。在一些实施例中,计算装置20可以包含更多或更少的组成部分。
以上结合附图对根据本公开的计算设备20及其操作方法300进行了描述。然而本领域技术人员可以理解,计算设备20及其操作方法300的执行并不局限于图中所示和以上所述的顺序,而是可以以任何其他合理的顺序来执行。此外,计算设备20也不必须包括图2中所示的所有组件,其可以仅仅包括执行本公开中所述的功能所必须的其中一些组件或更多组件,并且这些组件的连接方式也不局限于图中所示的形式。
本公开可以实现为方法、计算设备、系统和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于执行本公开的各个方面的计算机可读程序指令。计算设备可以包括至少一个处理器和耦合到该至少一个处理器的至少一个存储器,该存储器可以存储用于由至少一个处理器执行的指令。该指令在由该至少一个处理器执行时,该计算设备可以执行上述非对称同步方法。
在一个或多个示例性设计中,可以用硬件、软件、固件或它们的任意组合来实现本公开所述的功能。例如,如果用软件来实现,则可以将所述功能作为一个或多个指令或代码存储在计算机可读介质上,或者作为计算机可读介质上的一个或多个指令或代码来传输。
本文公开的装置的各个单元可以使用分立硬件组件来实现,也可以集成地实现在一个硬件组件,如处理器上。例如,可以用通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或其它可编程逻辑器件、分立门或者晶体管逻辑、分立硬件组件或用于执行本文所述的功能的任意组合来实现或执行结合本公开所描述的各种示例性的逻辑块、模块和电路。
本领域普通技术人员还应当理解,结合本公开的实施例描述的各种示例性的逻辑块、模块、电路和算法步骤可以实现成电子硬件、计算机软件或二者的组合。
本公开的以上描述用于使本领域的任何普通技术人员能够实现或使用本公开。对于本领域普通技术人员来说,本公开的各种修改都是显而易见的,并且本文定义的一般性原理也可以在不脱离本公开的精神和保护范围的情况下应用于其它变形。因此,本公开并不限于本文所述的实例和设计,而是与本文公开的原理和新颖性特性的最广范围相一致。