一种工业仓储搬运机器人强化学习导航方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明属于强化学习领域,具体涉及到一种仓储搬运机器人强化学习导航方法。
技术背景
近年来,随着人工智能和机器人技术的发展,采用深度强化学习方法将神经网络应用于机器人控制领域逐渐取代传统控制方法。机器人强化学习赋予机器人类似于人类的判断能力,提高机器人对环境的理解能力,从而控制机器人执行正确的动作。在复杂的大型仓库环境中完成导航任务,为更好的解决机器人防止碰倒周围货物,必须采用更好的环境状态表示,提高机器人在复杂狭窄的环境下完成导航和避障。
对于在实际应用中,强化学习面临着许多挑战。首先,现实环境是动态变化的,若只是简单地利用已知的不变环境来计算导航路径,则难免会带来不理想的结果。传统强化学习导航采用分层强化学习方法,通过全局路径规划完成路径探索,将激光雷达输入一维距离数据作为强化学习网络状态输入,完成近距离避障。使得强化学习需要完成两个策略的训练,才能完成导航任务,传统方法存在全局路径规划和局部路径规划相关性的丢失。为了提高智能体对于全局导航和局部导航的相关性,本发明在一维雷达距离数据作为PPO算法状态输入的基础上引入雷达图和全局地图作为强化学习状态输入,非常适用于机器人在复杂可变环境中导航任务—雷达图引导的深度强化学习导航算法。
发明内容
本发明在于提高导航问题中全局导航和局部导航的相关性的问题,提供了一种全局地图和局部地图融合的仓储机器人强化学习导航方法。
为达到上述目的,本发明通过下述技术方案实现:
为实现强化学习算法在真实机器人上部署,将技术方案分为机器人SolidWorks建模、Gazebo仓库仿真环境搭建、仿真环境的Gym封装、雷达图引导的深度强化学习算法训练五个步骤:
步骤1,所述机器人SolidWorks建模为:在SolidWorks中设计一种适用于仓库环境下搬运货物的导航机器人,实现机器人在仿真环境中对环境数据的采集,用于强化学习模型的训练;
步骤2,所述Gazebo仓库仿真环境搭建为:在Gazebo仿真软件中设计所需的动态仓库环境,用于移动机器人在仿真环境中运动采集强化学习环境状态所需的数据,并通过ROS2完成数据传输;
步骤3,所述仿真环境的Gym封装为:设计适用于移动机器人在动态仓库环境下用于强化学习训练的Gym封装,并在Gym封装中设计所需的动作空间、状态空间、奖励函数;
步骤4,所述雷达图引导的深度强化学习算法训练为:在动态的仓库环境下使用雷达图引导的强化学习,随机的在仓储不同位置生成货物作为动态环境,将全局地图和雷达图堆叠作为PPO算法状态输入训练模型,PPO算法价值网络和策略网络通过卷积层、池化层、激活函数完成对图像降维,生成一维数据和状态其他一维数据合并通过具有相同网络结构的全连接层组成价值网络和策略。
进一步,所述步骤1中在SolidWorks设计一种适用于仓库环境下的导航机器人,实现机器人在仿真环境中对环境数据的采集,用于强化学习模型的训练,具体通过以下三步完成:
步骤1.1,在机器人设计中,机器人采用四轮的麦克拉姆轮,能够实现机器人在仓库环境中全向运动,机器人主体框架设计为长0.6米,宽0.5米的矩形结构,并将底层控制板,电源,PC主机放于主体框架中,框架使用悬挂结构,增加机器人结构稳定性;
步骤1.2,将激光雷达置于机器人底板上表面正中间,便于采集四周障碍物距离数据;
步骤1.3,将IMU传感器置于机器人主体内部中间,用来获取里程计所需的位置信息。
进一步,所述步骤2中在Gazebo仿真软件中设计所需的动态仓库环境,用于移动机器人在仿真环境中运动采集强化学习环境状态所需的数据,并通过ROS2完成数据传输,具体通过以下四步完成:
步骤2.1,在Gazebo仿真软件中设计强化学习所需的仓库环境和货物,仓库内部长14.65米,宽8.625米,仓库正中间两边存在两根长宽都为0.5米的柱子,仓库外存在一个长宽都为5米的平台,并在三边都放置平板,用于反射激光雷达的激光,并设计1.2米×0.75米装载货物的托盘,用于动态改变仓库环境;
步骤2.2,设计仓库中两个柱子正中间为(0,0)点,移动机器人的起始位置在仓库外平台上随机位置,在仓库的=除道路所占位置外,其余格子正中间随机放置货物堆垛,在仓库中空余环境随机确定位置作为机器人导航目标点;
步骤2.3,利用机器人上板面配置的360°激光雷达获取环境中障碍物信息,并设置10Hz采样频率,作为机器人在仿真中更新频率,通过机器人内部的IMU获取里程计信息,将激光雷达信息和里程计信息用ROS2的话题发布,经过算法处理后作为强化学习的状态输入。
步骤2.4,通过改变仿真时间与现实时间的比值,将仿真世界时间加快50倍,加快强化学习算法的训练。
进一步,所述步骤3中设计适用于移动机器人在动态仓库环境下用于强化学习训练的Gym封装,并在Gym封装中设计所需的动作空间、状态空间、奖励函数;具体通过以下四步完成:
步骤3.1,设计动作空间,全向移动的机器人采用连续动作,动作分为x轴线速度V
步骤3.2,通过机器人在Gazebo中执行动作,获取的雷达数据和里程计数据,通过Gym调用laser和imu话题获取;
步骤3.3,通过ROS2获取的360束激光雷达数据,形成闭合区域,将闭合区域内使用白色表示,闭合区域外使用黑色表示,形成雷达图,将仓库环境中机器人道路和空余存放货物位置用白色表示,其余地方用黑色表示,形成全局地图,在局部地图和全局地图中使用黑色三角形表示机器人位置,用黑色圆形表示目标点,通过堆叠的方式作为强化学习图像状态输入,将机器人正方向与目标夹角和距离,机器人自身位置和上一步动作作为一维状态输入;
步骤3.4,在Gym封装库中根据强化学习算法的碰撞、到达、每步运行状态设计奖励函数。
进一步,所述步骤4中的雷达图引导的深度强化学习算法训练为:在动态的仓库环境下使用雷达图引导的强化学习,随机的在仓储不同位置生成货物作为动态环境,将全局地图和雷达图堆叠作为PPO算法状态输入训练模型,PPO算法价值网络和策略网络通过卷积层、池化层、激活函数完成对图像降维,生成一维数据和状态其他一维数据合并通过具有相同网络结构的全连接层组成价值网络和策略,具体通过以下步骤完成:
步骤4.1,将初始化状态输入自定义的PPO算法中,获取当前步奖励和下一步状态;
步骤4.2,自定义的PPO算法动作空间线速度取值范围为-0.5m/s~0.5m/s,角速度取值范围为-2.0rad/s~2.0rad/s;
步骤4.3,设计适应于仓储环境导航的奖励函数:为解决机器人运行更少的步数并且不碰到障碍物到达目标点,智能体利用每一步返回的奖惩值进行策略学习:
奖励函数公式如下:
其中_radius代表碰撞时距离目标的直线距离,_init_radius代表每一轮初始时刻机器人到目标距离,max_step代表设置的机器人运行一轮的最大步数,min(laser)表示雷达到障碍物的最小距离,laser_threshold代表机器人到障碍物的阈值;
步骤4.4,设计的状态空间分为图片状态和一维线性状态,图片状态为:全局地图使用320*3200的二值化图片表示,局部地图使用360束激光雷达围成的多边形图片表示,维度也为320*320,一维线性状态:到目标的直线距离和角度,上一步动作(Vx,Vy,w);
步骤4.5,每个回合结束都需随机化仓储中货物的位置,以实现复杂的动态仓储环境。
本发明相较于其他发明的优点:
(1)在复杂动态环境下,对先前的强化学习算法输入状态进行改进,通过全局地图和局部雷达地图图片堆叠的方式来增加其相关性;
(2)本发明使用雷达图引导的强化学习算法只需要训练一个智能体,相较于分层强化学习需要训练两个智能体降低了算法的复杂度。
附图说明
图1为仓储导航机器人SolidWorks模型图;
图2为Gazebo仓储环境内部图;
图3为Gazebo仓储环境外部图;
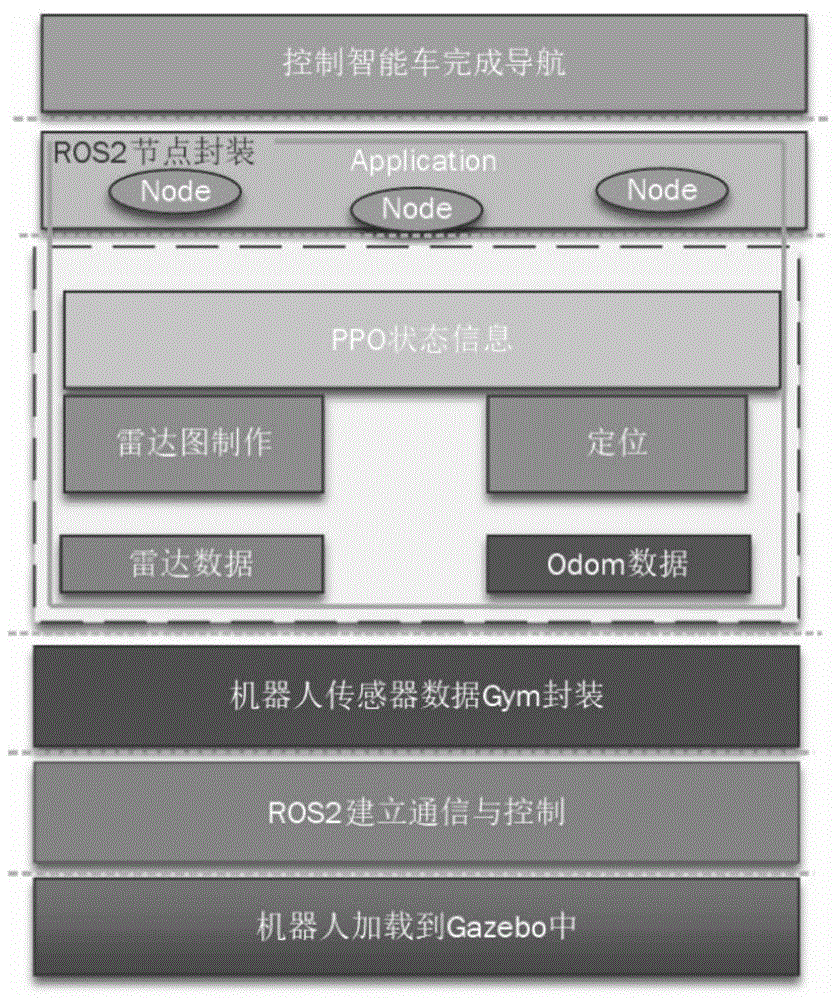
图4为本发明所述的一种工业仓储机器人导航系统整体框架图;
图5为仿真环境俯视图、全局地图、雷达图;
具体实施方式
下面结合附图对本发明具体实施步骤进一步说明
完成基于强化学习的仓储机器人导航任务,需要以下步骤:
步骤1,如图1所示通过SolidWorks完成智能机器人的模型设计,并赋予模型惯性系数矩阵、材料、碰撞属性、质量,减小机器人在仿真环境运行与真实环境的差距,仓储导航机器人主要由主体、左前轮、右前轮、左后轮、右后轮、激光雷达、imu七个部件组成,上下底板、电调、小车金属框架、电机、主控电脑、电源、电机支撑座构成主体部分,智能车前后麦克拉姆轮轮距0.4m,左右轮距相距0.42m作为智能车运动轮,STM32的C板控制板中安装BMI088作为IMU。分别赋予部件坐标系,然后将建好的机器人模型导出为可以在Gazebo仿真环境中运行的urdf文件模型,将机器人主体中心与地面相接处建立机器人坐标系,以便机器人在Gazebo中部署。
步骤2,在Gazebo中完成仓储环境的搭建,如图2在仓库中设定货物堆放位置,通过放置货物来动态的改变仓储环境,在图3中仓储外部平台作为机器人出发点,随机化机器人导航的目标位置,通过机器人在Gazebo环境中交互,通过ROS2完成传感器数据的传输,实现强化学习算法的状态输入,为加快强化学习的训练,将关闭Gazebo可视化,并将仿真时间加快为现实时间的50倍。
步骤3,根据图4中仓储机器人强化学习导航框架图完成机器人和仓储环境的Gym封装,首先编写render函数,实现仓库环境模型加载,初始化在仓储标定货物位置随机生成小于总货物量的货物,然后在仓库无货物位置随机生成目标位置,将机器人位置在图2仓库外平台随机位置产生,将图5的左侧为机器人在仿真环境中运行,图5中间图为全局地图,图中三角形表示机器人,三角形顶端表示机器人实时运动方向,圆形表示目标位置,图5右侧表示由360束激光雷达距离数据生成闭合的雷达图,将仓储带目标和机器人位置的二值化全局地图和雷达图堆叠作为作为Gym的状态,根据与目标点或者障碍物距离来判断机器人是否到达目标位置或发生碰撞,根据如下的奖励函数实现对应的奖励反馈:
根据麦克拉姆轮的全向运动特性,编写step函数,函数输出如下:
action=[Vx,Vy,w](3)
步骤4,通过二值化图片的形式作为强化学习算法的状态输入,可以将全局信息和局部信息融合输入神经网络中,构建PPO网络架构,将状态信息通过卷积层进行特征提取和降维为一维线性层作为PPO算法策略网络和价值网络的输入,通过策略网络输出公式3中机器人动作。
本发明通过制作与全局地图维度相同的二值化雷达图作为状态输入,有效解决了机器人在二维平面导航全局信息和局部信息融合的问题,相较于采用分层强化学习训练两个智能体简化了训练的复杂度。