基于多种机器学习算法的肺癌诊断系统
文献发布时间:2023-06-19 09:38:30
技术领域
本发明涉及医疗器械领域,尤其涉及一种基于多种机器学习算法的肺癌诊断系统。
背景技术
肺癌的诊断主要依靠实验室辅助检查、胸部影像学检查以及病理学诊断等。因肺癌早期缺乏典型的临床症状,加之肿瘤异质性等特点,实验室辅助检查、胸部影像学检查等筛查手段都具有一定的局限性,组织病理学检查虽是肺癌诊断的金标准,但又存在有创性和操作可行性等问题,因此,肺癌的早期诊断仍是亟待攻克的难题。鉴于上述问题,许多研究者通过引入传统数学统计模型如线性回归等辅助医生进行预测和决策。目前已经有不同研究建立了多种肺癌诊断模型,如Mayo临床模型,the Department of Veterans Affairs(VA)模型和PanCan风险预测模型等。这些模型主要是基于Logistic回归分析而建立的。但Logistc回归属于传统统计学概率模型,其对数据的要求较为严格:数据缺失值少,符合线性、分布为正态分布、满足方差齐性等。而临床工作中的数据大多难以满足以上条件,同时肺癌的临床诊断数据来源较多,由患者基本信息、影像学数据、实验室数据、病理学数据等多方面组成,各个方面间因素的作用方式较为复杂,这使得传统的统计学模型在应对这种复杂的疾病时,较难建立适用性强的预测模型。
发明内容
为解决上述问题,本发明实施例提供了一种基于多种机器学习算法的肺癌诊断系统。
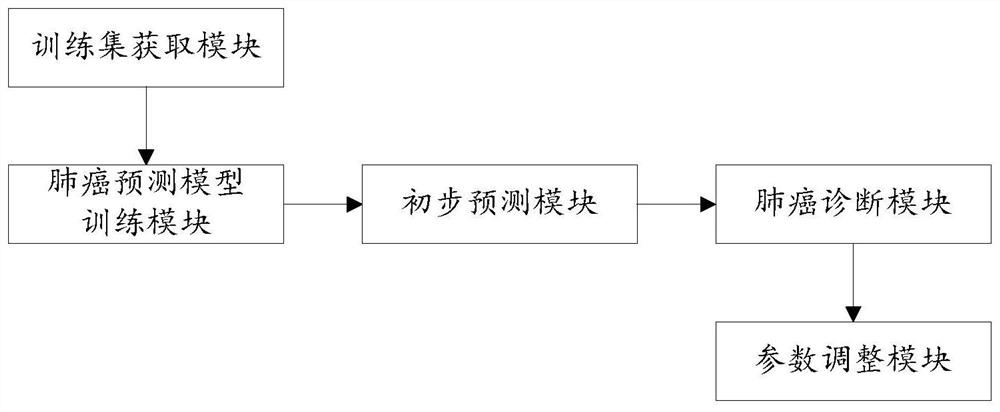
本发明实施例提供的基于多种机器学习算法的肺癌诊断系统包括:
初步预测模块,用于利用已训练的多个肺癌预测模型分别对待诊断患者的肺部临床数据进行肺癌初步预测处理,得到多个肺癌初步预测结果;
肺癌诊断模块,用于利用已训练的肺癌元分类器对所述多个肺癌初步预测结果进行肺癌分类处理,确定所述待诊断患者是否为肺癌患者。
优选地,所述系统还包括:
肺癌预测模型训练模块,用于利用用来训练肺癌预测模型的训练集,对所述多个肺癌预测模型和肺癌元分类器进行训练,得到已训练的多个肺癌预测模型和已训练的肺癌元分类器。
优选地,所述系统还包括:
训练集获取模块,用于筛选出肺癌患者和非肺癌患者的肺部临床数据,并对已筛选的肺部临床数据进行预处理,得到预处理后的肺部临床数据,从预处理后的肺部临床数据中划分出所述训练集。
优选地,所述肺部临床数据包括电子病历数据、实验室检查结果、肺部的CT影像学报告,所述训练集获取模块对所述肺部的CT影像学报告进行结构化处理,从所述肺部的CT影像学报告中得到包括病灶所在部位、毛刺现象、是否有胸膜牵拉、结节影像学性质、结节直径的结构信息。
优选地,所述肺部临床数据包括肺癌患者和非肺癌患者的肺部诊断结果,所述训练集获取模块用于对肺癌患者和非肺癌患者的肺部诊断结果进行分类,得到分类信息。
优选地,所述训练集获取模块用于对已筛选的肺部临床数据进行编码处理,得到编码信息。
优选地,所述训练集获取模块对已筛选的肺部临床数据进行去重、异常值处理、填补缺失值等处理,得到清洗后的肺部临床数据。
优选地,所述多个肺癌预测模型包括XBGoost模型、随机森林模型、逻辑回归模型、支持向量机、多层感知机中的至少两个。
优选地,所述系统还包括:
参数调整模块,用于根据所述肺癌诊断模块确定的所述待诊断患者是否为肺癌患者的诊断结果以及所述待诊断患者的实际诊断结果,对所述多个肺癌预测模型和所述肺癌元分类器的参数进行调整。
优选地,所述肺癌元分类器是用于集成模型的Stacking模型。
本发明采用多维度肺部临床数据,结合多种机器学习算法和集成模型,得到诊断性能良好的肺癌预测模型,由于所采用的数据来自于临床常规检查,具有较好的临床实用性,可在一定程度上提高医生诊断肺癌的准确度,助力临床诊疗工作。
附图说明
图1是本发明实施例提供的基于多种机器学习算法的肺癌诊断系统的示意性结构框图;
图2是本发明实施例提供的基于多种机器学习算法的肺癌诊断系统的工作流程图;
图3是本发明实施例提供的采用Stacking的模型集成方法进行模型集成的工作原理图。
具体实施方式
以下结合附图对本发明的优选实施例进行详细说明,应当理解,以下所说明的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
图1是本发明实施例提供的基于多种机器学习算法的肺癌诊断系统的示意性结构框图,如图1所示,所述系统可以包括:
初步预测模块,用于利用已训练的多个肺癌预测模型分别对待诊断患者的肺部临床数据进行肺癌初步预测处理,得到多个肺癌初步预测结果;
肺癌诊断模块,用于利用已训练的肺癌元分类器对所述多个肺癌初步预测结果进行肺癌分类处理,确定所述待诊断患者是否为肺癌患者。
机器学习方法对数据分布无线性要求,自动发现并利用相关因素之间的交互效应及非线性关系;可以充分利用有缺失的数据,无须事前对数据进行填补,更加真实地反映数据的原貌;且可通过大量随机选择样本的方法平衡样本误差的影响。因此本发明的多个肺癌预测模型可以采用多个机器学习模型,例如XBGoost模型、随机森林模型、逻辑回归模型、支持向量机、多层感知机中的至少两个。所述肺癌元分类器可以是用于集成模型的Stacking模型,。
所述系统还包括:
肺癌预测模型训练模块,用于利用用来训练肺癌预测模型的训练集,对所述多个肺癌预测模型和肺癌元分类器进行训练,得到已训练的多个肺癌预测模型和已训练的肺癌元分类器。
训练集获取模块,用于筛选出肺癌患者和非肺癌患者的肺部临床数据,并对已筛选的肺部临床数据进行预处理,得到预处理后的肺部临床数据,从预处理后的肺部临床数据中划分出所述训练集。
所述预处理可以包括对肺部临床数据进行数据结构化处理,例如,所述训练集获取模块对所述肺部的CT影像学报告进行结构化处理,从所述肺部的CT影像学报告中得到包括病灶所在部位、毛刺现象、是否有胸膜牵拉、结节影像学性质、结节直径的结构信息。
所述预处理可以包括对肺部临床数据进行分类处理,例如,所述肺部临床数据包括肺癌患者和非肺癌患者的肺部诊断结果,所述训练集获取模块用于对肺癌患者和非肺癌患者的肺部诊断结果进行分类,得到分类信息。
所述预处理可以包括对肺部临床数据进行标准化处理,例如其中,所述训练集获取模块对已筛选的肺部临床数据进行编码处理,得到编码信息。
所述预处理可以包括对肺部临床数据进行清洗处理,例如,所述训练集获取模块对已筛选的肺部临床数据进行去重、异常值处理、填补缺失值等处理,得到清洗后的肺部临床数据。
所述预处理也可以包括对肺部临床数据的上述多种处理。
需要说明的是,在肺癌辅助诊断及风险预测方面,多种机器学习算法结合多方面的数据训练出的模型,都体现出了良好的预测性能,有一定的辅助诊断价值。已有多项研究运用临床数据及来自如TCGA(The Cancer Genome Atlas,癌症基因图谱数据库)、GEO(GeneExpression Omnibus,高通量基因表达)等数据库的数据,利用多种机器学习算法建立了性能良好的肺癌预测模型。但以往研究中存在的普遍问题是,使用临床数据进行研究的样本量远远小于使用外部数据库的研究的样本量,且使用外部数据库研究多为基因甲基化、miRNA等数据,尚不能真正服务于临床。个别临床数据研究除样本量少之外,仅涉及影像学数据或肿瘤标志物数据,数据类型单一,不能很好地反映肿瘤复杂性及异质性特点。为此,本发明的肺部临床数据包括电子病历数据、实验室检查结果、肺部的CT影像学报告等,即根据常规患者病历信息、实验室检查、CT影像学检查中肺结节影像特征等数据来即可鉴别可能存在的恶性肺肿瘤患者。
所述系统还包括:
参数调整模块,用于根据所述肺癌诊断模块确定的所述待诊断患者是否为肺癌患者的诊断结果以及所述待诊断患者的实际诊断结果,对所述多个肺癌预测模型和所述肺癌元分类器的参数进行调整。
需要说明的是,可以从预处理后的肺部临床数据中划分出训练集以及测试集(或验证集),所述训练集(包括用于训练多个肺癌预测模型的第一训练集和用于训练肺癌元分类器的第二训练集)用以训练模型或确定模型参数,所述测试集用以测试已经训练好的模型的推广能力,评估模型泛化误差。在本系统中,所述肺癌预测模型训练模块利用该训练集训练模型或确定模型参数,所述参数调整模块利用该测试集进行模型参数调整。进一步地,在实际应用过程中,也可以随着临床数据量的增加,由所述参数调整模块利用新增加的肺部临床数据,不断进行模型参数调整,从而得到不断优化的模型。
本发明涉及的肺癌诊断模型,首先收集临床数据,包括肺癌患者以及健康人的电子病历数据、实验室检查结果、CT影像学报告等数据,对数据进行结构化和标准化处理,将所得到的数据集划分出训练集用以机器学习算法进行训练,得到肺癌诊断模型。
下面结合图2和图3进行详细说明。
图2是本发明实施例提供的基于多种机器学习算法的肺癌诊断系统的工作流程图,如图2所示,工作流程可以具体如下:
步骤1、首先确定纳入本模型构建的患者组。
纳入标准:经病理检查确诊为肺癌及排除肺癌可能性,诊断为良性肺部疾病的患者。
排除标准:经病理检查不能确诊或排除肺癌可能性的患者;转移癌患者;临床资料缺失严重的患者。
步骤2、收集筛选后患者的临床数据,包括肺癌患者以及健康人的电子病历数据、实验室检查结果、CT影像学报告等数据。
电子病历数据:除患者性别年龄等基本信息外,本发明纳入的电子病历数据有吸烟史(分为无吸烟史、现有吸烟、及既往吸烟近五年内戒烟),肿瘤史、恶性肿瘤家族史,肺功能实验数据(一秒钟用力呼气容积与用力肺活量的比值的实测值,FEV1/FVC%实测值),病理结果及肺癌组织学类型。
实验室检查结果(即实验室检查数据):主要指血清肿瘤标志物检测数据,例如,癌胚抗原(carcinoembryonic antigen,CEA);鳞状细胞上皮癌抗原(squamous cellcarcinoma antigen,SCC);细胞角蛋白19片段(Cytokeratin-19-fragment,CYFRA21-1);胃泌素释放肽前体(pro-gastrin releasing peptide,ProGRP);神经元特异性烯醇化酶(neuron-specific enolase,NSE),使用的生物参考区间范围为:CEA<5.0ng/mL,SCC<1.5ng/mL,CYFRA21-1<3.3ng/mL,NSE<16.3ng/mL,ProGRP<69.2pg/mL。
CT影像学结节特征:依据临床医师给出的影像学报告,提取出包括病灶所在部位、毛刺现象、是否有胸膜牵拉、结节影像学性质、结节直径的影像学结节特征。
步骤3、对数据进行结构化和标准化处理。
主要针对CT影像学报告进行数据结构化处理。从CT影像学报告中提取出包括病灶所在部位、毛刺现象、是否有胸膜牵拉、结节影像学性质、结节直径的信息,录入数据库。
对患者最终诊断进行分类,分为恶性肺部肿瘤(包括肺腺癌、肺鳞癌等)、良性肺部疾病(包括肺结核、肺部真菌感染等)两大类。
同时对分类变量进行One-Hot编码(如疾病类型、影像学结节所在部位等),由此将分类变量转换为机器学习算法易于利用的一种形式。
步骤4、进行数据清洗以获得有效的数据以提升模型性能。
数据清洗指对患者数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。具体包括:
对患者数据进行去重、异常值处理、填补缺失值等操作。
数据去重根据患者病历号进行去重处理,保留所记录患者病例信息最多的患者数据。
异常值处理主要针对实验室检查报告中不合理数据的确认、删减、填补。
填补缺失值采用K最近邻拟合后填补缺失值,包括原数据中存在的缺失和数据清洗中产生的缺失。
上述步骤1-步骤4可由图1的训练集获取模块实现。
步骤5、将清洗后所得到的数据集划分出训练集用以机器学习算法进行训练,本发明所采用的机器学习算法包括XGBoost、随机森林、逻辑回归、支持向量机、多层感知机,并利用上述算法综合得到集成模型。
采用随机抽样无放回的方式划分训练集和测试集。其中训练集共434例,良性肺部疾病患者71例,恶性肺癌患者363例。而测试集共218例,其中良性肺部疾病患者29例,恶性肺癌患者189例。
XGBoost按照顺序依次训练决策树,每次训练新的决策树(记为第k颗决策树)时都会用到前k-1颗决策树的信息,使得当前决策树与前k-1颗决策树的总预测结果的损失函数最小。与随机森林相比,梯度提升方法会更加关注在已训练的决策树上预测结果不好的数据点,不断提升模型的短板,因此其效果通常会比随机森林更好。
随机森林是基于决策树的分类模型。它是利用Bootstrap重抽样方法从原始样本中抽取多个样本,对每个Bootstrap样本进行决策树算法建模,然后组合多棵决策树的预测,通过投票得出最终预测结果。
逻辑回归是一种基于线性回归的分类模型。逻辑回归通过对数线性函数的形式将待分类数据(X)映射到分类概率(y),并通过最大似然估计的方法给出对于对数线性函数中线性部分系数的估计,估计的过程通过梯度下降的方法进行求解。逻辑回归模型的优势在于计算简单,可解释性强。对于数据中的每个特征,都可以通过线性部分的系数来衡量其对分类标签的影响。
支持向量机是基于统计学习理论发展而来。它的机理是寻找一个满足所要求的分类条件的最优分类超平面,该超平面与任何类的最近的训练数据点具有最大距离(所谓的功能边界),因为通常边距越大,则泛化误差越小,即所得的分类器有很好的通用性。
在进行模型选择,超参数优化,以及特征工程的过程中,会得到许多不同的模型以及它们在验证集上的表现。接下来,根据这些模型的表现以及差异度,选出一些模型进行模型集成,即综合考虑这些模型的输出值,来确定最后的输出结果。
常见的模型集成方法有Bagging,Blending,Ensemble Selection,Stacking,Boosting等。其中Bagging方法简单快捷,Ensemble Selection在训练集上容易得到好的效果但经常会过拟合,Stacking方法的效果通常最好但超参数也最多,Blending方法的特点介于Bagging和Stacking两者之间,Boosting方法一般不用于不同模型之间的集成。本发明所使用的集成模型采用Stacking的方法进行模型集成,Stacking的工作原理如图3所示,在第一训练集上分别训练好m个模型C1,C2,……,Cm后,在第二训练集(另一份数据)上用这些模型对每条数据进行预测,这样对于每条数据都会得到m个预测值P1,P2,……,Pm。接下来将P1,P2,……,Pm作为新的输入特征,训练一个“元分类器”去拟合最终的类别标签,这个元分类器与之前的模型一样,可以选用逻辑回归,随机森林,神经网络等常见的机器学习模型。在用集成模型预测新的数据时,先用每个模型预测得到m个预测结果,再将这m个预测结果输入到“元分类器”中得到最终的预测结果Pf。
步骤6、使用训练集数据分别利用不同算法进行模型构建,每次训练中采用部分训练集数据进行训练(可由图1的肺癌预测模型训练模块实现)而另一部分数据用于参数调整(可由图1的参数调整模块实现),在不同算法下分别得到预测性能较好的肺癌预测模型,并通过加权得到预测性能良好的集成模型,最后利用测试集对模型预测性能进行评估。
也就是说,本发明使用多种机器学习算法对训练集进行学习,用测试集检测预测效能,进行参数调优,再次进行机器学习和效能分析,直至获得最优模型。
本发明可应用于临床辅助诊断肺癌的过程中,帮助临床医生进行决策,同时可通过网络平台共享给多个中心,为缺乏经验的临床医生提供诊断意见,提升临床整体的肺癌诊断水平。
尽管上文对本发明进行了详细说明,但是本发明不限于此,本技术领域技术人员可以根据本发明的原理进行各种修改。因此,凡按照本发明原理所作的修改,都应当理解为落入本发明的保护范围。
- 基于多种机器学习算法的肺癌诊断系统
- 基于多种机器学习算法融合的污染物浓度反演方法