基于注意力机制的人脸表情识别方法
文献发布时间:2023-06-19 09:40:06
技术领域
本发明涉及一种基于注意力机制的人脸表情识别方法,尤其适用于人脸表情快速识别中使用的 基于注意力机制的人脸表情识别方法。
背景技术
在人类的日常交流中,表情代表着人们当前的情感状态,往往比语言更能表达准确的信息,在 人类情感交流中有着不可或缺的作用。20世纪70年代,心里学家Ekman和Friesen定义了6中基 本情感,分别是高兴、生气、吃惊、恐惧、厌恶和悲伤六种基本情感,随后蔑视被加进来,这7种 情感成为人们研究表情识别的基础。
人脸表情识别作为计算机视觉领域的一个研究方向,与人脸检测、识别有着密不可分的关系, 逐渐被应用到日常的生活中,如司机疲劳驾驶检测、刑侦以及娱乐等领域。目前,人脸表情识别的 研究主要分为基于传统方法的人工特征提取和基于深度学的两个方向。Andrew等
自2013年以来,深度学习逐渐应用于表情识别。Matsugu等
发明内容
发明目的:针对上述技术的不足之处,提供一种结构简单,识别效率高,识别精度高的基于注 意力机制的人脸表情识别方法。
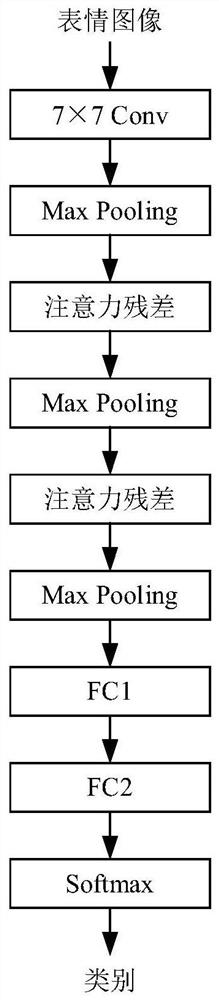
为实现上述技术目的,本发明的基于注意力机制的人脸表情识别方法,首先构建人脸表情识别 模型,其结构按照图像输入顺序为:卷积模块、最大池化模块、注意力残差模块、最大池化模块、 注意力残差模块、最大池化模块和两个全连接层以及softmax函数,通过端到端的方式获得收敛后 的人脸表情预测结果;注意力残差模块为在残差网络的基础上引入自注意力模块,通过计算输入的 人脸表情特征图中所有位置像素的加权平均值来计算人脸表情特征图中关键位置的相对重要性,关 键位置为识别表情重要的位置,具体为特征图中对与识别表情重要的位置,包括嘴巴和眼睛;然后 引入通道注意力学习通道域上的不同特征从而产生通道注意力,以学习不同通道中相互作用特征, 使特征图的通道能够对目标进行检测,从而使通道定位到特征图的关键位置,提升鲁棒性;最后, 将自注意力机制和通道注意力机制相融合以鼓励人脸表情识别模型提取人脸表情特征图中关键位置 作为全局重要特征的能力,通过端到端的学习方式,利用重复的最大池化模块、注意力残差模块减 少误差,输出最优识别结果。
人脸表情识别模型的构建过程中利用的残差网络y=F(x,{W
自注意力模块利用非局部操作在计算特征图每个位置的输出时关注图像中所有和当前表示相关 的信号,将获得相关性权重表征其他位置和当前待计算位置的相关性,定义如下:
其中i表示输出特征图中的任意位置,j是特征图中所有可能位置的索引,x为输入特征图,y是输出 特征图,输出的特征图与输入的特征图像素值发生改变,尺寸与输入特征图相同,f是计算任意两点 间相关性的函数,g是一元函数,用于进行信息变换,C(x)为归一化函数;由于f和g都是通式,结 合神经网络需要考虑具体形式,首先,g是一元输出,采用1×1卷积代替,形式如下:g(x
设自注意力网络的输入特征图为F
从数学角度上说明,假设自注意力网络的前一层的特征图为x∈R
式中,β
式中,W
然后引入残差连接,最终的自注意力模块输出为:y
利用通道注意力模块作用特征检测器,引入通道注意力来学习通道间的权重分布,强化对表情 识别任务有用的通道,同时弱化对任务不相关的通道;对于经过变化的中间特征图的每个通道,分 别经过基于高度和宽度的全局平均池化和全局最大池化操作,将特征图压缩到两个不同空间中得到 两个特征图,然后将得到的两个特征图输入到两个网络用同一套参数,即具有共享参数的全连接神 经网络中,将全连接层的输出向量按对应元素进行求和,融合两个空间的特征,最后经过sigmoid 激活函数得到最终的通道权重;具体如下:
假设输入的特征图为F
M
进一步地:
M
其中,W
在残差模块的基础上添加自注意力机制和通道注意力使之构成注意力残差模块,用以增强症人 脸表情识别模型网络的提取特征能力,捕获长范围特征间依赖关系,提高模型对有用信息的敏感度, 抑制无用信息;添加方式分为串行和并行两种方式,其中串行又分为先进行自注意力后进行通道注 意力和先进行通道注意力后进行自注意力。
串行方式中的先自注意力后通道注意力的添加方式具体为:
串行方式的先进行自注意力后进行通道注意力模式:将前一层经过卷积得到特征图F
串行方式中的先通道注意力后自注意力的添加方式具体为:
串行方式的先通道注意力后自注意力模式:将前一层经过卷积得到特征图F
其中,
并行添加方式步骤为:将前一层经过卷积得到特征图F
式中,
在残差模块中设有通道自注意力形成注意力残差模块,具体分为三种结构:分别为单独使用自 注意力机制、单独使用通道注意力机制和同时使用自注意力和通道注意力机制,注意力残差模块为 在原有残差模块的基础上添加了注意力机制。
有益效果:
本发明提出注意力机制的人脸表情识别模型,在残差网络的基础上引入自注意力机制,克服卷 积运算局部操作的限制,提升了模型捕获长范围关联特征的能力;考虑到特征图通道间的相关性, 引入通道注意力,学习通道间的权重分布;本发明使用的基于注意力的人脸表情识别模型识别速度 快,识别精度高;本发明使用的网络训练的方式是端到端的训练方式,只需要输入一张人脸表情图 像,即可直接输出表情类别,无需预先进行大量的重复训练。
附图说明:
图1为本发明的基于注意力机制的人脸表情识别方法框图;
图2为本发明的残差模块框图;
图3为本发明的自注意力模块框图;
图4为本发明的通道注意力模块框图;
图5为本发明的先自注意式后通道模式框图;
图6为本发明的先通道后自注意力道模式框图;
图7为本发明通道意力和自注意力并行模式框图;
图8(a)为单独使用自注意力机制框图;
图8(b)为单独使用通道注意力机制框图;
图8(c)为同时使用自注意力和通道注意力机制框图;
图9为使用FER2013训练的曲线图;
图10为使用CK+训练的曲线图;
图11为使用FER2013数据集的混淆矩阵;
图12为使用CK+数据集的混淆矩阵。
具体实施方式:
下面结合附图对本发明的具体实施例做进一步说明:
本发明的一种基于注意力机制的人脸表情识别方法,首先构建人脸表情识别模型,其结构按照 图像输入顺序为:卷积模块、最大池化模块、注意力残差模块、最大池化模块、注意力残差模块、 最大池化模块和两个全连接层FC1和FC2以及softmax函数,通过端到端的方式获得收敛后的人脸 表情预测结果;注意力残差模块为在残差网络的基础上添加自注意力机制和通道注意力机制,用以 提高对输入图像中有用信息的敏感度,抑制无用信息;其添加方式为串行和并行两种方式,其中串 行方式又分为先进行自注意力后进行通道注意力、先进行通道注意力后进行自注意力,并行方式即 为自注意力和通道注意力并行;利用自注意力计算输入的人脸表情特征图中所有位置像素的加权平 均值来计算人脸表情特征图中关键位置的相对重要性,关键位置为识别表情重要的位置,具体为特 征图中对与识别表情重要的位置,包括嘴巴和眼睛;然后利用通道注意力学习通道域上的不同特征 从而产生通道注意力,以学习不同通道中相互作用特征,使特征图的通道能够对目标进行检测,从 而使通道定位到特征图的关键位置,提升鲁棒性;最后,将自注意力机制和通道注意力机制相融合 以鼓励人脸表情识别模型提取人脸表情特征图中关键位置作为全局重要特征的能力,通过端到端的 学习方式,利用重复的最大池化模块、注意力残差模块减少误差,输出最优识别结果。
图1为注意力机制模型的整体框架。前一部分使用下采样进行特征提取得到表情特征图;然后 将特征图输入到注意力残差模块中进行特征转换,来提升模型性能;最后通过全连接层实现表情分 类。其中注意力残差模块包含自注意力模块何通道注意力模块。
残差网络:由于在深度学习中,往往是通过增加模型规模来提升模型性能,但是随着网络层数 的加深,会出现梯度消失问题,给模型训练带来困难。为解决这个问题,残差网络采用一种短路连 接的方式,允许网络之前的信息直接传递到模块输出层,
如图2所示,残差模块通过恒等映射的方式在输入和输出之间建立了一条连接,从而使得卷积 层能够学习输入、输出之间的残差,用F(x,{W
如图3所示,自注意力模块:在卷积神经网络中,由于计算资源的限制,卷积核的大小一般小 于7,因此每次卷积运算只能覆盖像素点周围很小的一块邻域,对于距离较远的特征,例如人的两 只眼睛之间的关联特征就不容易捕获。为了捕获长范围像素之间的依赖关系,需要反复堆叠卷积操 作并通过反向传播得到,但是这样容易造成梯度消失和收敛慢的问题;由于网络很深,需要设计合 理的网络结构而不影响梯度传播等。与卷积局部计算不同,非局部操作的核心思想是在计算特征图 每个位置的输出时不再只和局部邻域的像素进行计算,而是关注图像中所有和当前表示相关的信号, 将获得相关性权重表征其他位置和当前待计算位置的相关性,定义如下:
其中i表示输出特征图中的某个位置,j是特征图中所有可能位置的索引,x为输入特征图,y是输出 特征图,尺寸与输入特征图相同,f是计算任意两点间相关性的函数,g是一元函数,目的是进行信 息变换,C(x)为归一化函数。由于f和g都是通式,结合神经网络,需要考虑具体形式。首先,g是 一元输出,采用1×1卷积代替,形式如下:g(x
对于计算两个位置相关性的函数f,本文在嵌入空间中计算相似度,数学表达式如下:
从数学角度上分析,假设前一层的特征图为x∈R
其中,β
其中,W
此外,为了更好地进行梯度反向传播,引入残差连接,所以注意力模块最终的输出为:
y
其中,γ是一个可学习的超参数,初始化为0,在训练过程中逐渐增大权重。
如图4所示,通道注意力模块:特征图的每个通道都扮演着特征检测器的作用
为了更加高效地计算通道注意力,对于中间特征图的每个通道,分别经过基于高度和宽度的全 局平均池化和全局最大池化操作,将特征图压缩到两个不同空间中,然后将得到的两个特征图输入 到具有共享参数的全连接网络中,将全连接层的输出向量按对应元素进行求和,融合两个空间的特 征,最后经过sigmoid激活函数得到最终的通道权重,详细结构如下图所示。
假设输入的特征图为F
M
进一步地:
M
其中,W
注意力融合:为了增强网络模型的提取特征能力,捕获长范围特征间依赖关系,本文在残差模 块的基础上添加自注意力机制和通道注意力使之构成注意力残差模块,以提高模型对有用信息的敏 感度,抑制无用信息。添加方式分为串行和并行两种方式,其中串行又分为先进行自注意力后进行 通道注意力和先进行通道注意力后进行自注意力。
先自注意力后通道注意力:串行方式下的先进行自注意力后进行通道注意力如图4所示,将前 一层经过卷积得到特征图F
先通道注意力后自注意力:串行方式的先通道后自注意力模式如图5所示,将前一层经过卷积 得到特征图F
其中,
并行方式:并行连接方式如图7所示,将前一层经过卷积得到特征图F
其中,
注意力残差
为了更好地利用前文设计的通道自注意力,本文将其插入到残差模块中。具体分为三种结构设 计,分别为单独使用自注意力机制、单独使用通道注意力机制和同时使用自注意力和通道注意力机 制。注意力残差模块为在原有残差模块的基础上添加了注意力机制,具体的结构如图8(a)、8(b)、 8(c)所示。
为验证本文模型的有效性,在FER2013和CK+两个数据集上进行实验。实验基于TensorFlow框 架
实施例:
FER2013数据集
CK+数据集
由于两个数据集数量较小,本文采用数据增强的方式扩增数据集,主要方式包括随机旋转、随 机调整亮度、随机灰度化等。CK+数据集扩增到29000张左右,FER2013扩增到63000张左右。通过 数据增强操作,有效地提升模型准确率,同时防止出现过拟合现象。
1消融实验
通过实验验证自注意力机制和通道注意力机制的有效性。对于消融实验,使用FER2013和CK+ 数据集,并采用残差模块作为基本模块构建基准模型。在FER2013数据集实验中,采用官方提供的 数据集划分方式,即28709张图像用于训练,3589张图像用于验证模型,3589张图像用于测试最终 模型的准确率。对于CK+数据集,我们对扩增后的数据集按照7:2:1的比例划分训练集、验证集和 测试集。
在训练过程中,选择Adam作为优化器,学习率设置为0.0001,总的训练步骤为50个epoch, batch_size设置为64。实验结果如表1所示。
表1消融实验结果
从表1中得出如下结论:(1)在FER2013和CK+两个数据集上,基准模型的性能明显不如添加 注意力机制的模型,无论添加何种注意力以及何种添加方式,这表明注意力机制能够改善神经网络 的特征提取能力,有助于表情识别模型性能的提升;(2)对于添加注意力机制的模型,使用混合注 意力明显好于单一注意力方式,这表明增加模型的非线性映射对于表情识别任务是有效的;(3)对 于混合注意力模型,在FER2013数据集上,先进行通道注意力后进行自注意力效果最好,相比并行 方式和先进行自注意力后进行通道注意力准确率分别提升了3.98%和2.89%,在CK+数据集上,先进 行自注意力机制效果最好,相比并行方式和先通道后自注意力准确率分别提升了0.66%和1.48%。
2方案选择
从前一节消融实验分析可得,先进行通道注意力后进行自注意力的组合方式综合表现最好,在 FER2013和CK+两个数据集上均取得较高的准确率,因此本文选取该模型作为最终模型。为了验证本 文模型的有效性,下面将该模型与当前其他方法进行对比实验,实验结果如表2和表3所示。
从表2和表3中的实验数据可以得出如下结论:(1)与前面三种传统表情识别方法相比,使用 深度学习的方法能明显提升表情识别准确率。使用卷积神经网络提取到的特征比人工特征算子能更 好的进行表情描述;(2)与目前主流的基于深度学习方法相比,所提自注意力机制模型在两个数据 集上均获得了更高的准确率;(3)FER2013数据集的准确率明显低于CK+数据集的准确率,说明数 据集的质量对实验结果有一定的影响。FER2013数据集与CK+数据集的规模都比较小,FER2013数据 集还存在着错误的标签与非人脸表情标签,这些都会给模型的训练带来干扰,从而影响模型的性能。
图9和图10展示了本文模型在FER2013和CK+数据集上的训练损失和准确率曲线图,从图中可 以看出,本文模型在FER2013数据集上的训练过程没有在CK+数据集上的稳定,这与两者数据集有 一定的关系。通过检查两个数据集,可以发现FER2013数据集表情图片差异较大,图像分辨率低, 且图像质量不一,给训练过程带来一定的干扰,准确率最终稳定在75%左右。而CK+数据集图像质量 较好,且分布均匀,所以模型在该数据集上训练较为稳定,且最终准确率较高,训练集与验证集的 准确率均在98%左右。
图11是在FER2013数据集上实验得到的混淆矩阵,显示出人脸图像在7种表情上的分类准确率。 其中横坐标代表预测标签,纵坐标代表真实标签。从矩阵中可以看出,本文添加自注意力单元的的 模型在各个表情上准确率均有提升,其中在“悲伤”表情提升效果最大,有13%的提升,说明自注 意力单元的加入使表情分类更加准确。但是,7种表情的准确率之间有一定的差距,如最高的“高 兴”表情准确率达到92%,而“悲伤”、“恐惧”、“生气”分别为49%、53%和64%。一方是由于 这三类表情数据量较少,样本不均衡给网络训练带来一定的消极影响,另一方面,这三类表情具有 一定的相似性,特征差异不明显,不容易区分。
图12展示了在CK+测试上得到的混淆矩阵,可以看到,大多数的表情识别准确率都有所提升, 与FER2013结果相同,由于生气、悲伤、蔑视数据量相对较少,且表情之间特征差异不是很明显, 所以识别率稍低于恶心、恐惧、高兴和惊讶这些表情。
- 一种基于分离混合注意力机制的人脸表情识别方法
- 一种基于注意力机制的人脸表情识别方法