用于提供具有可调节计算需求的机器学习模型的系统和方法
文献发布时间:2023-06-19 11:06:50
相关申请
本申请要求于2018年10月1日提交的第62/739584号美国临时专利申请的优先权和利益。通过引用第62/739584号美国临时专利申请的全部内容将其合并于此。
技术领域
本公开一般涉及机器学习模型。更具体地,本公开涉及用于提供具有可调节计算需求的机器学习模型的系统和方法。
背景技术
设备上机器学习模型已经变得更加普遍。例如,深度神经网络已经部署在“边缘”设备上,诸如移动电话、嵌入式设备、其他“智能”设备或其他资源受限的环境。当与基于云的配置相比校时,这样的设备上模型可以提供包括减少延迟和改进隐私的好处,在基于云的配置中,机器学习模型被远程存储和访问,例如,在经由广域网访问的服务器中。
然而,这种边缘设备的计算资源可以显著变化。此外,对于特定设备,在给定时间用于执行这样的设备上机器学习模型的可用计算资源量可以基于各种因素而变化。因此,设备上机器学习模型可能表现出差的性能,诸如增加的时延或延迟,和/或要求次优的设备资源分配。
发明内容
本公开的实施例的方面和优点将在下面的描述中部分阐述,或者可以从描述中获知,或者可以通过实施例的实践获知。
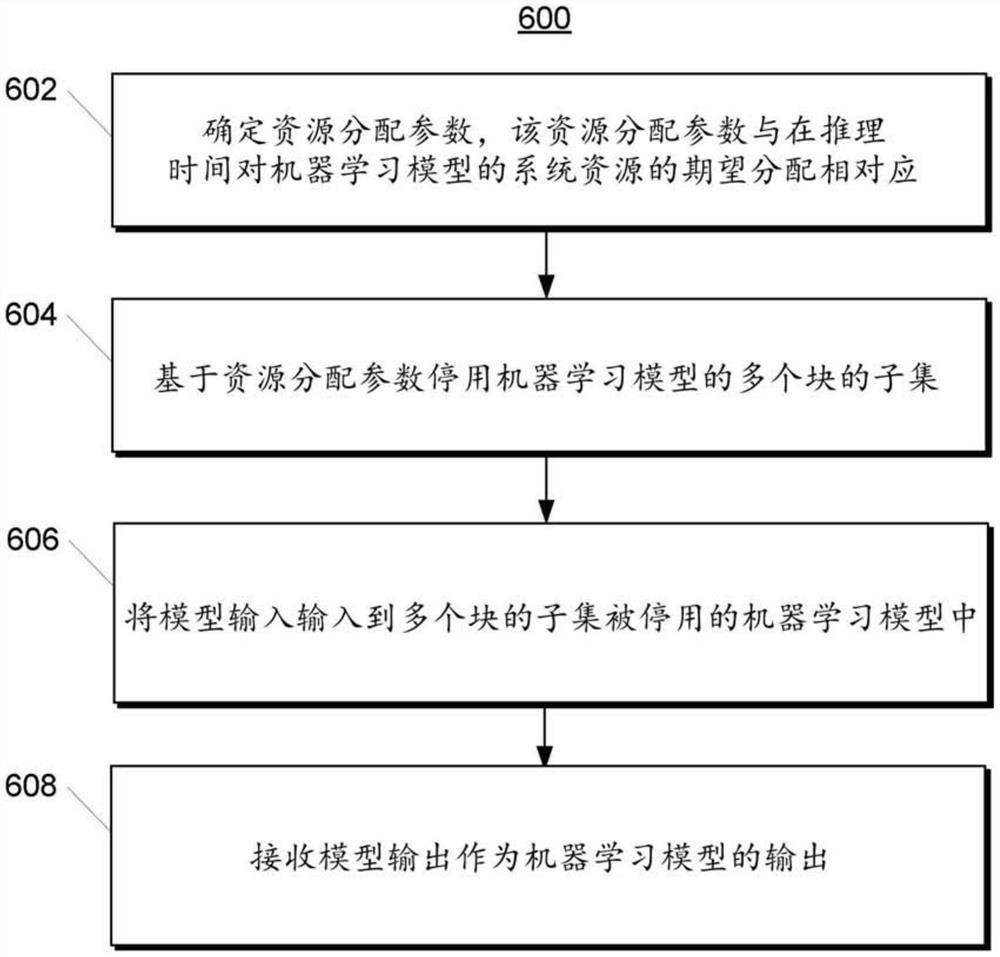
本公开的一个示例方面针对计算设备。计算设备可以包括至少一个处理器和机器学习模型。机器学习模型可以包括多个块和所述多个块中的两个或更多个块之间的一个或多个残差连接。机器学习模型可以被配置为接收模型输入,并且响应于模型输入的接收,输出模型输出。机器学习模型可以包括至少一个有形的、非瞬时性的计算机可读介质,该计算机可读介质存储当由至少一个处理器执行时使得至少一个处理器执行操作的指令。操作可以包括确定资源分配参数,资源分配参数与在推理时间对机器学习模型的系统资源的期望分配相对应。操作可以包括基于资源分配参数停用机器学习模型的多个块的子集。操作可以包括将模型输入输入到多个块的子集被停用的机器学习模型中,并且接收模型输出作为机器学习模型的输出。
本公开的另一示例方面针对减少与机器学习模型相关联的计算成本的计算机实施的方法。该方法可以包括由一个或多个计算设备确定资源分配参数,资源分配参数描述在推理时间对机器学习模型的系统资源的期望分配。该方法可以包括由一个或多个计算设备基于资源分配参数停用机器学习模型的多个块的子集。该方法可以包括由一个或多个计算设备将输入集输入到机器学习模型中,并且由一个或多个计算设备接收输出集作为机器学习模型的输出。
本公开的另一示例方面针对用于将机器学习模型训练为针对在推理时间停用机器学习模型的神经网络的多个块中的至少一些块是鲁棒的方法。该方法可以包括由一个或多个计算设备使用训练数据集迭代地训练机器学习模型。该方法可以包括在机器学习模型的迭代训练的至少一次迭代之前,由一个或多个计算设备停用机器学习模型的多个块的迭代特定子集。
本公开的其他方面针对各种系统、装置、非瞬时性计算机可读介质、用户接口和电子设备。
参考以下描述和所附权利要求,将更好地理解本公开的各种实施例的这些和其他特征、方面和优点。并入本说明书并构成本说明书一部分的附图示出本公开的示例实施例,并且与说明书一起用于解释相关原理。
附图说明
说明书中参考附图阐述了针对本领域普通技术人员的实施例的详细讨论,其中:
图1A描绘根据本公开的示例实施例的示例计算系统的框图。
图1B描绘根据本公开的示例实施例的示例计算系统的框图。
图1C描绘根据本公开的示例实施例的示例计算系统的框图。
图2A描绘根据本公开的示例实施例的机器学习模型。
图2B描绘根据本公开的示例实施例的机器学习对象识别模型。
图2C描绘根据本公开的示例实施例的机器学习语音识别模型。
图3A描绘根据本公开的示例实施例的机器学习模型的层的示例块。
图3B描绘根据本公开的示例实施例的机器学习模型的层的另一示例块。
图4描绘根据本公开的示例实施例的其中多个块的子集已经被停用的示例机器学习模型。
图5描绘根据本公开的示例实施例的其中多个块的子集已经被停用的另一示例机器学习模型。
图6描绘根据本公开的示例实施例的减少与机器学习模型相关联的计算成本的示例方法的流程图。
图7描绘示例方法的流程图,该示例方法用于将机器学习模型训练为针对在推理时间停用机器学习模型的神经网络的多个块中的至少一些块是鲁棒的。
多个附图中重复的附图标记旨在标识各种实施方式中的相同特征。
具体实施方式
一般来说,本公开针对用于提供具有可调节计算需求的机器学习模型的系统和方法。本公开的示例方面针对包括或除此之外利用机器学习模型的计算系统和相关方法,该机器学习模型可以被调整来调节在计算设备上执行机器学习模型的计算需求。在一些实施方式中,机器学习模型可以存储和/或执行在计算设备(诸如“边缘”设备)上。示例设备包括智能电话、“智能”设备、嵌入式设备以及可以具有有限的计算能力和/或可以对云计算进行访问的任何计算设备。在推理时间之前,计算设备可以基于资源分配参数来选择机器学习模型的子集(例如,层的一个或多个层和/或块的集合),该资源分配参数对应于在推理时间对对机器学习模型的系统资源的期望分配。计算设备可以以减少或消除与停用部分相关联的计算需求的方式停用所选模型的子集。结果,可以减少在推理时间对计算设备的总计算需求。更具体地,可以智能地控制在推断时间对计算设备的总计算需求以匹配系统资源的期望分配,其中期望分配基于各种环境和/或上下文因素(诸如,在推断时间与设备的可用处理能力或存储器相关联的一个或多个度量)和/或基于用户输入。虽然停用机器学习模型的部分可以提供更快的处理时间,这种停用也可以降低由模型输出的结果的质量。因此,处理时间和质量之间的权衡常常存在。因此,本公开的方面提供了一种可调整的模型,该模型可以被智能地和粒度地调节以在速度和质量之间提供期望的权衡。
机器学习模型可以被训练为对在推理时间停用块是鲁棒的。更具体地,在模型的迭代训练期间,可以停用块的迭代特定子集。在训练期间被停用的块的子集可以以与在推理时间被停用的那些块相似的方式来选择。因此,该模型可以被训练为对可能在推理时间被停用的块的停用是鲁棒的,这可以在推理时间改进机器学习模型的输出的质量。
此外,这种可调整机器学习模型可以适合于跨具有各种资源级别的一系列计算设备的部署。每个计算设备可以根据需要(例如,基于相应计算设备的资源)来调整机器学习模型。可替代地,可以训练单个机器学习模型,并且然后可以基于单个、经训练的机器学习模型创建和分发各种调整的机器学习模型。各种调整的机器学习模型在推理时间可以需要不同级别的计算资源。因此,可以根据将会执行机器学习模型的特定计算设备来调整或定制根据本公开方面的机器学习模型。
在一个示例中,用户可以请求操作(诸如对象识别),该操作利用驻留在智能电话上的设备上机器学习模型。在执行机器学习模型之前,计算设备可以,例如,基于与智能电话相关联的上下文特定的考虑来停用机器学习模型的部分以减少执行机器学习模型所需的计算资源。示例包括在推理时间的智能电话的电池状态、当前可用的处理器能力以及当前执行的应用的数量。机器学习模型的这种调整可以减少执行机器学习模型并向用户提供输出(例如,识别文本)所需的时间。
具体地,根据本公开的一个方面,计算设备可以包括包括多个块的机器学习模型。每个块可以包括一个或多个层,并且每个层可以包括一个或多个节点。例如,在一些实施方式中,机器学习模型可以是或包括卷积神经网络。机器学习模型可以包括在多个块中的两个或更多个块之间的一个或多个残差连接。残差连接可被配置为例如通过绕过已被停用的块来将信息传递给“下游”块。因此,该模型可以包括任意数量的块和各个块之间的任意数量的残差连接。在一个示例中,每个相邻块之间存在残差连接,而在其他示例中,残差连接是稀疏的。
计算设备可以被配置为确定资源分配参数,该参数与在推理时间对机器学习模型的系统资源的期望分配相对应。计算设备可以基于资源分配参数停用机器学习模型的多个块的子集。结果,可以减少与执行所得到的机器学习模型相关联的计算需求。例如,与执行机器学习模型相关联的计算需求中的减少可以与资源分配参数的幅度成反比。最后,计算设备可以被配置为将模型输入输入到多个块的子集被停用的机器学习模型中,并且接收模型输出作为机器学习模型的输出。
在一些实施方式中,可以在将模型输入输入到机器学习模型之前(例如,在推理时间之前)确定资源分配参数。还可以基于计算设备的当前状态来确定资源分配参数。作为示例,当计算设备的电池状态为低时,资源分配参数可以与在推断时间对机器学习模型的系统资源的低期望分配相对应,以保持计算设备的剩余电池功率。类似地,当当前可用处理器能力低和/或大量应用当前正在执行时,资源分配参数可以与系统资源的低期望分配相对应以避免长处理时间。因此,所得到的机器学习模型可以基于计算设备的当前状态进行调整,以快速提供解决方案和/或保留计算设备的资源。
在一些实施方式中,用户可以提供指示用户想要分配给机器学习模型的计算资源量的输入。作为示例,用户可以与计算设备(例如,智能电话)的触摸敏感显示屏进行交互以提供输入。例如,用户可以输入值(例如,经由键盘)或调节滑块(或其他虚拟控制对象),以指示她的对更快的结果但潜在的不太准确的结果或较慢但潜在的更准确的结果的偏好。
在一些实施方式中,机器学习模型可以具有结构布置,该结构布置提供针对停用各种块的弹性或鲁棒性。更具体地,这些块可以通过各种残差连接来连接,以使得信息可以“绕过”停用的块传递到后续的块或层(例如,到分类或其他(多个)输出层)。作为一个示例,可以选择多个块的子集,以使得残差连接中的至少一个绕过包括在多个块的子集中的每个块。换句话说,包括在多个块的子集中的每个块可以位于机器学习模型的残差连接的至少一个之间。因此,停用块的子集可以减少与执行机器学习模型相关联的计算需求,而不会使得机器学习模型不可操作或不可接受地降低模型的输出的质量。
机器学习模型的残差连接可以具有各种配置。作为一个示例,多个块可以“密集”连接,以使得提供从每个块的输出到直接跟随在下一个顺序块之后的块的输入的残差连接,以使得每个块残差地连接到一个块之外的块(例如,从块1到块3的连接跳过块2)。在这样的示例中,每个块都有资格停用。作为另一示例,可以仅在一些块之间形成残差连接。每个残差连接可以跳过一个块或者可以跳过多个块。残差连接可以在网络中具有不同的连接和跳过量。在这样的配置中,只有对其提供残差连接的块(例如,可以被残差连接跳过的块)可以有资格停用。然而,本公开的方面可以应用于具有任意数量的残差连接的不同合适配置的机器学习模型中。
如本文所使用的,“块”可以指一个或多个连续层的组,并且每个层可以包括一个或多个节点。在一些实施例中,一个块内的层可以按一般顺序配置来布置,在该一般顺序配置中一层的输出传递到下一层作为输入。在一些实施方式中,机器学习模型可以包括卷积神经网络,并且多个块中的至少一个块可以包括卷积块。卷积块可以应用至少一个卷积滤波器。卷积块还可以包括一个或多个池化层或在卷积神经网络中发现的其他合适层。附加的残差连接可以包括在卷积块内,例如,该残差连接绕过卷积滤波器中的一个或多个。此外,在一些实施方式中,机器学习模型可以包括一个或多个全连接层和/或分类层,诸如softmax层。
可以使用各种合适的技术来停用块的子集。作为示例,可以断开块的子集,以使得信息不被输入到块的子集中。然而,停用块的子集可以包括任何合适的技术,以使得在推断时间块的子集的计算资源的消耗显著减少或消除。
在一些实施方式中,可以基于资源分配参数的幅度来选择多个块的子集的大小,以使得多个块的子集的大小与资源分配参数的幅度负相关。例如,小的资源分配参数可以导致在推断时间之前停用大量块。然而,在其它实施方式中,取决于所选择的惯例,多个块的子集的大小可以与资源参数的幅度正相关。
在一些实施方式中,多个块(或其子集)可以残差地连接在“残差链”中,该“残差链”可以从机器学习模型的输入端延伸到机器学习模型的输出端。停用机器学习模型的多个块的子集可以包括停用残差链内的起始残差块和残差链的残差尾部部分。残差尾部部分可以包括从起始残差块延伸到机器学习模型的输出端的残差链内的块。因此,残差尾部部分可以包括位于起始残差块“之后”的块的连续串。当残差尾部部分被停用时,残差连接可以(例如,“绕过”停用部分)将信息传递给后续的层或块。因此,块的子集可以包括机器学习模型的多个块内的连续块链。
在一些实施方式中,可以以半随机的方式选择块的子集,该方式相对于停用位于机器学习模型的输入端附近的块,偏好停用位于模型的输出端附近的块。例如,可以基于每个块的相应概率来选择块。这些概率可以被分配给这些块,并且可以与每个块被选择用于停用的可能性相对应。每个块的相应概率可以与神经网络中每个块的相应位置正相关。更具体地,位于机器学习模型的输入端附近的块可以具有低关联概率。与相应块相关联的概率可以向输出端增加。因此,块的子集可以包括可以分散在机器学习模型的多个块中的非连续块。
根据本公开的另一方面,公开了用于减少与机器学习模型相关联的计算成本的方法。该方法可包括确定资源分配参数,该资源分配参数描述在推理时间对机器学习模型的系统资源的期望分配。可以基于资源分配参数停用机器学习模型的多个块的子集。该方法可以包括将输入集输入到机器学习模型中,并接收输出集作为机器学习模型的输出。
在一些实施方式中,该方法可以包括在(例如,在服务器计算系统处)停用多个块的子集之后在用户计算设备(例如,“边缘”设备)处接收机器学习模型。可以(例如,在服务器计算系统处)训练机器学习模型。在训练期间,机器学习模型的部分可以被停用,例如如下所述,以使得机器学习模型对停用块是鲁棒的。在经训练的机器学习模型被发送到用户计算设备之前,可以(例如,在服务器计算系统处)例如,基于机器学习模型将要被发送到的用户计算设备的计算资源确定资源分配参数。然后可以(例如,在服务器计算系统处)基于资源分配参数停用机器学习模型的多个块的子集,并且可以将调整的机器学习模型发送到用户计算系统。然后,用户计算系统可以通过输入模型输入并接收模型输出作为机器学习模型的输出来利用机器学习模型。
这样的实施方式可以提供机器学习模型的更有效的训练和分发。代替为具有不同级别计算资源的设备阵列训练各种具有不同复杂度的相似机器学习模型,可以训练单个机器学习模型。然后,通过停用经训练的机器学习模型的部分,然后经训练的机器学习模型的多个副本可以被调整来要求不同级别的计算资源(例如,对应于各种设备)。然后所得到的机器学习模型可以被分发到具有不同级别计算资源的设备阵列。然而,应当理解,在其他实施方式中,上述方法的每个步骤可以由单个用户计算设备执行。
在一些实施方式中,例如如上所述,可以选择多个块的子集,以使得残差连接中的至少一个绕过多个块的子集中的每一个。类似地,在一些实施方式中,例如如上所述,可以基于电池状态、当前可用处理器能力或当前执行的应用的数量中的至少一个来确定资源分配参数。
根据本公开的另一方面,公开了一种方法,该方法用于将机器学习模型训练为针对在推理时间停用机器学习模型的神经网络的多个块中的至少一些块是鲁棒的。该方法可以包括使用训练数据集迭代地训练机器学习模型。训练数据集可以包括任何合适的训练输入数据集,并且可选地可以包括训练输出数据集。示例训练数据集可以包括音频文件和音频文件中口语单词的识别文本。另一示例训练数据集可以包括图像和描述识别到的、图像中描绘的对象的位置和/或标签的对象识别输出。
该方法可以包括在机器学习模型的迭代训练的至少一次迭代之前停用机器学习模型的多个块的迭代特定子集。可以以各种合适的方式选择迭代特定子集。作为一个示例,可以基于与神经网络内的每个块的相应位置正相关的与每个块相关联的相应概率来选择迭代特定子集。应当理解,可以使用如上所述的关于在推断时间之前基于资源分配参数停用多个块的子集的方法类似的方法来选择迭代特定子集。例如,在训练期间,可以以半随机方式选择迭代特定的块的子集,该半随机方式相对于停用位于机器学习模型的输入端附近的块,偏好停用位于机器学习模型的输出端附近的块。因此,机器学习模型可以被训练为针对在推理时间停用可能被停用的块是鲁棒的。这种训练方法可以在推理时间改进机器学习模型的输出的质量。
本公开的系统和方法提供了许多技术效果和益处,包括例如减少机器学习模型在推理时间所要求的计算资源。此外,在期望具有不同计算需求的机器学习模型的变体的情况下,用于设备上的机器学习模型的存储可以被减少为可调整机器学习模型,该可调整机器学习模型可以调节其计算需求,可以替代多个机器学习模型。所描述的系统和方法还可以减少训练机器学习模型所要求的计算资源,因为可以训练可调整的机器学习模型来代替具有不同计算需求的多个机器学习模型。
作为一个示例,本公开的系统和方法可以包括在或除此之外采用在应用、浏览器插件的上下文中或在其他上下文中。因此,在一些实施方式中,本公开的模型可以包括在用户计算设备(诸如膝上型计算机、平板电脑或智能电话)中,或者除此之外由用户计算设备(诸如膝上型计算机、平板电脑或智能电话)存储和实施。作为又一示例,这些模型可以包括在根据客户端-服务器关系与用户计算设备通信的服务器计算设备中或除此之外由根据客户端-服务器关系与用户计算设备通信的服务器计算设备存储。
现在参考附图,将进一步详细地讨论本公开的示例实施例。
图1A描绘根据本公开的示例实施例的减少与机器学习模型相关联的计算成本的示例计算系统100的框图。系统100包括通过网络180通信地耦合的用户计算设备102、服务器计算系统130和训练计算系统150。
在一些实施方式中,用户计算设备102可以是“边缘”设备。示例“边缘”设备包括智能电话、“智能”设备、嵌入式设备以及任何可能具有有限的计算能力和/或访问云计算的计算设备。然而,用户计算设备102可以是任何类型的计算设备,诸如,个人计算设备(例如,膝上型或桌上型)、移动计算设备(例如,智能电话或平板)、游戏机或控制器、可穿戴计算设备、嵌入式计算设备或任何其他类型的计算设备。
用户计算设备102包括一个或多个处理器112和存储器114。一个或多个处理器112可以是任何合适的处理设备(例如,处理器核心、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是一个处理器或操作地连接的多个处理器。存储器114可以包括一个或多个非瞬时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪存设备、磁盘等及其组合。存储器114可以存储数据116和由处理器112执行以使得用户计算设备102执行操作的指令118。
用户计算设备102可以存储或包括一个或多个机器学习模型120。例如,机器学习模型120可以是或可以除此之外包括各种机器学习模型,诸如神经网络(例如,深度神经网络)或其他多层非线性模型。神经网络可以包括卷积神经网络、循环神经网络(例如,长-短期记忆循环神经网络)、前馈神经网络或其它形式的神经网络。参考图2A到图2C讨论示例机器学习模型120。
在一些实施方式中,一个或多个机器学习模型120可以通过网络180从服务器计算系统130接收,存储在用户计算设备存储器114中,并且然后由一个或多个处理器112使用或除此之外实施。在一些实施方式中,用户计算设备102可以实施单个机器学习模型120的多个并行实例(例如,跨模型120的多个实例执行并行操作)。
附加地或可替代地,一个或多个机器学习模型140可以包括在根据客户端-服务器关系与用户计算设备102通信的服务器计算系统130中或者除此之外由根据客户端-服务器关系与用户计算设备102通信的服务器计算系统130存储。因此,可以在用户计算设备102处存储和实施。在一些实施方式中,一个或多个模型120可以从服务器计算系统130发送到用户计算设备102。
用户计算设备102还可以包括模型控制器122,例如,如参考图2A到图7所述,该模型控制器122被配置为停用机器学习模型120的多个块的子集。模型控制器122可以与被配置为如本文所述停用块的计算机程序(例如,数据116和指令118)相对应。
用户计算设备102还可以包括接收用户输入的一个或多个用户输入组件124。例如,用户输入组件124可以是对用户输入对象(例如,手指或触笔)的触摸敏感的触摸敏感组件(例如,触摸敏感显示屏或触摸板)。触摸敏感组件可以用于实施虚拟键盘。其他示例用户输入组件包括麦克风、传统键盘或用户可以通过其输入通信的其他方式。
服务器计算系统130包括一个或多个处理器132和存储器134。一个或多个处理器132可以是任何合适的处理设备(例如,处理器核心、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是一个处理器或操作地连接的多个处理器。存储器134可以包括一个或多个非瞬时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪存设备、磁盘等及其组合。存储器134可以存储数据136和由处理器132执行以使得服务器计算系统130执行操作的指令138。
在一些实施方式中,服务器计算系统130包括一个或多个服务器计算设备或除此之外由一个或多个服务器计算设备实施。在其中服务器计算系统130包括多个服务器计算设备的实例中,这样的服务器计算设备可以根据顺序计算架构、并行计算架构或其一些组合来操作。
如上所述,服务器计算系统130可以存储或除此之外包括一个或多个机器学习模型140。例如,模型140可以是或可以除此之外包括各种机器学习模型,诸如神经网络(例如,卷积神经网络、深度循环神经网络等)或其他多层非线性模型。参考图2A到图2C讨论示例模型140。
服务器计算系统130可以经由与通过网络180通信地耦合的训练计算系统150的交互来训练模型140。训练计算系统150可以与服务器计算系统130分开,或者可以是服务器计算系统130的一部分。
服务器计算系统130还可以包括模型控制器142,例如,如参考图2A到图7所述,该模型控制器142被配置为停用机器学习模型140的多个块的子集。模型控制器122可以与被配置为如本文所述的停用块的计算机程序(例如,数据116和指令118)相对应。
训练计算系统150包括一个或多个处理器152和存储器154。一个或多个处理器152可以是任何合适的处理设备(例如,处理器核心、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是一个处理器或操作地连接的多个处理器。存储器154可以包括一个或多个非瞬时性计算机可读存储介质,例如RAM、ROM、EEPROM、EPROM、闪存设备、磁盘等及其组合。存储器154可以存储数据156和由处理器152执行以使得训练计算系统150执行操作的指令158。在一些实施方式中,训练计算系统150包括一个或多个服务器计算设备,或者除此之外由一个或多个服务器计算设备实施。
训练计算系统150可以包括模型训练器160,模型训练器160使用各种训练或学习技术训练存储在服务器计算系统130处的机器学习模型140。例如,如下面参考图7所述,模型训练器160可以被配置为在机器学习模型的迭代训练的至少一次迭代之前停用机器学习模型的多个块的迭代特定子集。示例训练技术包括误差的反向传播,误差的反向传播可以包括执行通过时间的截断反向传播。模型训练器160可以执行许多泛化技术(例如,权重衰减、丢弃等)以改进正在被训练的模型的泛化能力。
具体地,模型训练器160可以基于训练数据162集训练机器学习模型140。例如,如下面参考图2A到图2C所述,训练数据162可以包括例如模型输入数据(例如,图像、音频等)。在一些实施方式中,例如,如下面参考图2A到图2C所述,训练数据162可以被“打标签”,并且还包括模型输出数据(例如,对象识别数据、语音识别数据等)。
在一些实施方式中,如果用户已经提供许可,训练示例可以(例如,基于由用户计算设备102的用户先前提供的通信)由用户计算设备102提供。因此,在这样的实施方式中,可以由训练计算系统150在从用户计算设备102接收的用户特定通信数据上训练提供给用户计算设备102的模型120。在某些实例中,此过程可以指代为个性化模型。
模型训练器160包括用于提供期望功能的计算机逻辑。模型训练器160可以在控制通用处理器的硬件、固件和/或软件中实施。例如,在一些实施方式中,模型训练器160包括存储在存储设备上、加载到存储器中并由一个或多个处理器执行的程序文件。在其它实施方式中,模型训练器160包括一组或多组计算机可执行指令,这些指令存储在有形计算机可读存储介质(诸如RAM硬盘或光或磁介质)中。
网络180可以是任何类型的通信网络,诸如局域网(例如,内部网)、广域网(例如,因特网)或其一些组合,并且可以包括任何数量的有线或无线链路。一般来说,可以使用种类繁多的通信协议(例如,TCP/IP、HTTP、SMTP、FTP)、编码或格式(例如,HTML、XML)和/或保护方案(例如,VPN、安全HTTP、SSL)经由任何类型的有线和/或无线连接来执行通过网络180的通信。
图1A示出可以用于实施本公开的一个示例计算系统。也可以使用其他计算系统。例如,在一些实施方式中,用户计算设备102可以包括模型训练器160和训练数据集162。在这样的实施方式中,模型120可以在用户计算设备102处本地训练和使用。在这样的实施方式的一些中,用户计算设备102可以实施模型训练器160以基于用户特定数据来个性化模型120。
图1B描绘根据本公开的示例实施例的示例计算设备10的框图。计算设备10可以是用户计算设备或服务器计算设备。
计算设备10包括许多应用(例如,应用1到N)。每个应用包括其自己的机器学习库和(多个)机器学习模型。例如,每个应用可以包括机器学习模型。示例应用包括文本消息应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。在一些实施方式中,每个应用还可以包含其自己的模型控制器,该模型控制器可以智能地停用应用中包括的相应机器学习模型内的块。
如图1B所示,每个应用可以与计算设备的许多其他组件(诸如,一个或多个传感器、上下文管理器、设备状态组件和/或附加组件)进行通信。在一些实施方式中,每个应用可以使用API(例如,公共API)与每个设备组件进行通信。在某些实施方式中,由每个应用使用的API是特定于该应用的。
图1C描绘了根据本公开的示例实施例的示例计算设备50的框图。计算设备50可以是用户计算设备或服务器计算设备。
计算设备50包括许多应用(例如,应用1到N)。每个应用与中央智能层进行通信。示例应用包括文本消息应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。在一些实施方式中,每个应用可以使用API(例如,跨所有应用的公共API)与中央智能层(以及其中存储的(多个)模型)进行通信。
中央智能层包括许多机器学习模型。例如,如图1C所示,可以为每个应用提供相应的机器学习模型(例如,模型),并由中央智能层管理。在其他实施方式中,两个或更多个应用可以共享单个机器学习模型。例如,在一些实施方式中,中央智能层可以为所有应用提供单个模型(例如,单个模型)。在一些实施方式中,中央智能层包括在计算设备50的操作系统内或除此之外由计算设备50的操作系统实施。
中央智能层可以与中央设备数据层进行通信。中央设备数据层可以是用于计算设备50的数据的集中存储库。如图1C所示,中央设备数据层可以与计算设备的许多其他组件(诸如,一个或多个传感器、上下文管理器、设备状态组件和/或附加组件)进行通信。在一些实施方式中,中央设备数据层可以使用API(例如,私有API)与每个设备组件进行通信。在一些实施方式中,中央智能层还可以包含模型控制器,该模型控制器经由API智能地停用为给定应用提供的机器学习模型中的块。
图2A描绘根据本公开的示例实施例的示例机器学习模型200的框图。在一些实施方式中,机器学习模型200被训练成接收一组输入数据202,并且作为接收输入数据202的结果,提供输出数据204。机器学习模型可以被训练以执行种类繁多的功能。作为示例,参考图2B,对象识别机器学习模型240可以接收一个或多个图像242(例如,单个图像或视频文件),并输出对象识别数据244(例如,描述识别到的、图像中描绘的对象的位置和/或标签)。作为另一示例,参考图2C,语音识别机器学习模型260可以被训练以接收音频文件262并输出语音识别数据264(例如,包括音频文件中的口语单词的识别文本)。然而,应当理解,本公开的方面可以应用于被配置为执行任何合适功能的机器学习模型200,这些功能包括由设备上机器学习模型执行的功能(例如,文本预测、个人助理功能等)。
一般而言,本公开针对用于提供具有可调节计算需求的机器学习模型200的系统和方法。本公开的示例方面针对包括或除此之外利用机器学习模型的计算系统和相关方法,该机器学习模型可被调整来调节在计算设备上执行机器学习模型的计算需求。在一些实施方式中,机器学习模型可以在计算设备(诸如“边缘”设备)上存储和/或执行。示例设备包括智能电话、“智能”设备、嵌入式设备以及任何可能具有有限的计算能力和/或访问云计算的计算设备。在推理时间之前,计算设备可以基于资源分配参数来选择机器学习模型的子集(例如,层的一个或多个层和/或块的集合),该资源分配参数与在推理时间对机器学习模型的系统资源的期望分配相对应。计算设备可以以减少或消除与停用部分相关联的计算需求的方式停用所选模型子集。结果,可以减少在推理时间对计算设备的总计算需求。更具体地,可以智能地控制在推断时间对计算设备的总计算需求以匹配系统资源的期望分配,其中期望分配基于各种环境和/或上下文因素(诸如,例如在推断时间与设备的可用处理能力或存储器相关联的一个或多个度量)和/或基于用户输入。虽然停用机器学习模型的部分可以提供更快的处理时间,这种停用也可以降低由模型输出的结果的质量。因此,处理时间和质量之间的权衡常常存在。因此,本公开的方面提供了可以被智能地和粒度地调节以在速度和质量之间提供期望的权衡的可调整性模型。
机器学习模型可以被训练为针对在推理时间停用块是鲁棒的。更具体地,在模型的迭代训练期间,可以停用块的迭代特定子集。在训练期间被停用的块的子集可以以与在推理时间被停用的那些块类似的方式来选择。结果,该模型可以被训练为针对停用可能在推理时间被停用的块是鲁棒的,这可以改进在推理时间的机器学习模型的输出的质量。
此外,这种可调整机器学习模型可以适合于跨具有各种资源级别的一系列计算设备的部署。每个计算设备可以根据需要,例如,基于相应计算设备的资源来调整机器学习模型。可替代地,可以训练单个机器学习模型,并且然后可以基于单个、经训练的机器学习模型创建和分发各种调整的机器学习模型。各种调整的机器学习模型在推理时间可以需要不同级别的计算资源。因此,可以根据将会执行机器学习模型的特定计算设备来调整或定制根据本公开的方面的机器学习模型。
在一个示例中,用户可以请求操作(诸如对象识别),该操作利用驻留在智能电话上的设备上机器学习模型。在执行机器学习模型之前,计算设备可以,例如,基于与智能电话相关联的上下文特定的考虑来停用机器学习模型的部分以减少执行机器学习模型所需的计算资源。示例包括在推理时间的智能电话的电池状态、当前可用的处理器能力以及当前执行的应用的数量。机器学习模型的这种调整可以减少执行机器学习模型并向用户提供输出(例如,识别文本)所需的时间。
如本文所使用,“块”可以指一个或多个连续层的组,并且每个层可以包括一个或多个节点。在一些实施例中,块内的层可以按一般顺序配置来布置,在该一般顺序配置中一层的输出传递到下一层作为输入。在一些实施方式中,机器学习模型可以包括卷积神经网络,并且多个块中的至少一个块可以包括卷积块。卷积块可以应用至少一个卷积滤波器。卷积块还可以包括一个或多个池化层或在卷积神经网络中发现的其他合适层。附加的残差连接可以包括在卷积块内,例如,附加的残差连接绕过卷积滤波器中的一个或多个。此外,在一些实施方式中,机器学习模型可以包括一个或多个全连接层和/或分类层,诸如softmax层。
例如,参考图3A,示出示例块300。本文所描述的模型中包括的块可以如示例块300中所示,和/或可以具有其它与示例块300不同的配置/结构。块300可以具有输入302、输出304,并且包括一个或多个层306、308。每个层306、308可以包括一个或多个节点。残差连接310可以被配置为(例如,“绕过”块300的层306、308)将信息从输入302传递到块300的输出304。在一些实施方式中,可以提供一个或多个“内部”残差连接312,残差连接312绕过比块300的层306、308的全部更少的块传递信息。例如,内部残差连接312可以绕过层306或绕过层308传递信息。
图3B示出包括“并行”结构的另一示例块350。例如,块350可以包括被配置为卷积滤波器或其他类型的并行神经网络结构的多个层354。一个或多个残差连接356可以被配置为将信息从输入352传递到块350的输出360。此外,“内部”残差连接358可异被配置为绕过块350的一个或多个单独层354传递信息。
图4示出具有输入402、输出404和多个块405的示例机器学习模型400。机器学习模型400可以与上面参考图2A到图2C描述的机器学习模型200、240、260中的一个或多个相对应。机器学习模型400还可以包括一个或多个全连接层和/或分类层426,诸如softmax层。块405通常可以被布置在线性配置中,其中第一块406的输出被输入到第二块408,并且第二块408的输出被输入到第三块410等等。最后一个块424的输出可以输入到分类层426中。分类层426的输出可以与模型400的输出404相对应。
机器学习模型400可以包括多个块406-424中的两个或更多个块之间的一个或多个残差连接427。残差连接427可以被配置为例如通过绕过某些块来将信息传递给“下游”块。因此,该模型可以包括任意数量的块和各种块405之间任意数量的残差连接427。
计算设备(例如,图1A中所示的设备102或系统130)可以被配置为确定资源分配参数,该资源分配参数与在推断时间用于机器学习模型400的系统资源的期望分配相对应。计算设备可以基于资源分配参数停用机器学习模型400的多个块405的子集。在图4所示的示例中,多个块405的子集包括块414、418、422、424。结果,可以减少与执行所得到的机器学习模型400相关联的计算需求。例如,与执行机器学习模型400相关联的计算需求中的减少可以与资源分配参数的幅度成反比。最后,计算设备可以被配置为将模型输入402输入到多个块405的子集(例如,块414、418、422、424)被停用的机器学习模型400,并且接收模型输出404作为机器学习模型的输出。
在一些实施方式中,计算设备可以至少部分地基于与执行机器学习模型400中的每个相应块相关联的计算资源量来选择用于停用的块。更具体地,资源分配参数可以与机器学习模型的最大目标资源分配量相对应。作为示例,最大目标资源分配量可以对应于总处理器能力的百分比、总可用存储器(例如,随机存取存储器)的百分比或描述计算资源的使用的任何其它合适度量。与每个块相关联的相应资源消耗量可以例如基于每个块中的层和/或节点的数量和/或类型而变化。计算设备可以被配置为基于每个块的相应资源消耗量(例如,预期计算需求)来选择块,以将执行机器学习模型所要求的资源调节为小于总目标资源分配量。因此,计算设备可以被配置为智能地选择停用的块,以使得所得到的模型400在推断时间需要小于最大目标资源分配量的资源。
例如,给定与每个块相关联的相应资源消耗量和总目标资源分配的知识,计算设备可以执行一个或多个优化技术来选择要停用哪些块。例如,计算设备可以通过迭代地搜索要停用的块的组合来最小化实现的资源分配和目标资源分配之间的差异。在另一示例中,将资源分配参数值与要停用的块的相应子集相关联的查找表可以存储在计算设备的存储器中,并且在推断时间被访问以确定要停用的块。在又一示例中,可以简单地停用模型中可变数量的“最终”块,其中可变数量是资源分配参数的函数。因此,例如,随着资源分配参数的增加,模型中增加的数量的“最终”块可以被停用。
仍然参考图4,为了提供示例,块406-416可以具有每个等于10个单位的相应资源消耗量。块418-424可以具有等于20个单元的相应资源消耗量。在该示例中,如果总目标资源分配等于75个单元,计算设备可以选择阴影块414、418、422、424。剩余块406-412、416、420的相应资源消耗量的和等于70,这小于75个单元的总目标资源分配。
在一些实施方式中,可以在将模型输入402输入到机器学习模型400之前(例如,在推断时间之前)确定资源分配参数。还可以基于计算设备的当前状态来确定资源分配参数。作为示例,当计算设备的电池状态为低时,资源分配参数可以与在推断时间对机器学习模型400的系统资源的低期望分配相对应,以保持计算设备的剩余电池功率。作为又一示例,计算设备的当前状态可以包括计算设备的模式(例如,电池节省模式)。当计算设备处于电池节省模式时,资源分配参数可以与在推断时间对机器学习模型400的系统资源的低期望分配相对应,以减少在推断时间使用的电池功率。类似地,当当前可用处理器能力低和/或大量应用当前正在执行时,资源分配参数可以与系统资源的低期望分配相对应以避免长处理时间。因此,可以基于计算设备的当前状态调整所得到的机器学习模型400,以快速提供解决方案和/或保持计算设备的资源。
在一些实施方式中,用户可以提供指示用户想要分配给机器学习模型400的计算资源量的输入。作为示例,参考图1A,用户可以与计算设备102(例如,智能电话)的用户输入组件124(例如,触摸敏感显示屏)进行交互以提供输入。例如,用户可以(例如,经由键盘)输入值或调节滑块(或其他虚拟控制对象),以指示她对更快的结果但潜在的不太准确的结果或较慢但潜在的更准确的结果的偏好。
再次参考图4,在一些实施方式中,机器学习模型400可以具有提供针对各种块的停用的弹性或鲁棒性的结构布置。更具体地,模型400的块可以通过各种残差连接427连接,以使得信息可以“绕过”停用块414、418、422、424传递到后续的块或层(例如,到分类层524或其他(多个)输出层)。作为一个示例,可以选择多个块405的子集,以使得残差连接427中的至少一个残差连接绕过包括在多个块405的子集中的每个块414、418、422、424。换言之,包括在多个块405的子集中的块414、418、422、424中的每一个可以位于机器学习模型的残差连接427中的至少一个之间。因此,停用块414、418、422、424的子集可以减少与执行机器学习模型400相关联的计算需求,而不会使得机器学习模型不可操作或不可接受地降低模型400的输出的质量。
机器学习模型400的残差连接可以具有各种配置。例如,如图4所示,可以仅在块405的一些之间形成残差连接427。例如如图4所示,每个残差连接427可以跳过单个块。在其他实施方式中,残差连接可以跳过多个块。残差连接可以在网络中具有不同的连接和跳过量。在这样的配置中,只有为其提供残差连接的块(例如,可以被残差连接跳过的块)可以有资格停用。然而,本公开的方面可以应用于具有任意数量的残差连接的不同合适配置的机器学习模型中。
例如,再次参考图4,残差连接427可以仅在块412-424之间形成。其他块406、408、410可以不具有相关联的残差连接。在该示例中,只有具有相关联的残差连接427的块412-424可以有资格停用。
在一些实施方式中,可以以半随机的方式选择块405的子集,该半随机的方式相对于停用位于机器学习模型400的输入端430(邻近输入402)附近的块,偏好停用位于机器学习模型400的输出端428(邻近输出404)附近的块。例如,可以基于每个块的相应概率来选择块405中的某些。这些概率可以被分配给这些块,并且可以与每个块被选择用于停用的可能性相对应。块405中的每一个块的相应概率可以与神经网络中块405中的每一个块的相应位置正相关。更具体地,位于机器学习模型400的输入端430附近的块可以具有低关联概率。与相应块405相关联的概率可以向输出端428增加。因此,例如如图4所示,块405的子集可以包括可以分散在机器学习模型400的多个块405中的非连续块414、418、422、424。
例如,参考图4,块412、414、416可以具有相对低的相应相关联概率(例如,小于25%);块418、420可以具有中等的相应相关联概率(例如,25%到50%);并且块422、424可以具有高的相应相关联概率(例如,大于50%)。计算设备然后可以基于他们的相应的概率来选择用于停用的块。结果,例如如图4所示,被选择用于停用的块可以向机器学习模型400的输出端428集中。
参考图5,在一些实施方式中,多个块503可以“密集”连接,以使得提供从每个块的输出到直接跟随在下一个顺序块之后的块的输入的残差连接528、529,以使得每个块残差地连接到一个块之外的块(例如,从第一块504的输出到第三块508的输入的连接跳过第二块506)。在这样的示例中,块503中的每一个可以有资格停用。
然而,如上所指示,可以选择多个块503的子集,以使得残差连接528、529中的至少一个绕过包括在多个块503的子集中的每个块512、530。换言之,包括在多个块503的子集中的每个块512、530可以位于机器学习模型500的残差连接528、529中的至少一个之间。因此,用于停用的各种块的资格可以取决于残差连接528、529的布置。例如,参考图5,如果示出的所有残差连接528、529都存在,则块503中的每一个将在任何组合中有资格停用。然而,如果虚线所示的残差连接529不存在,则只有阴影块512、530将有资格停用。
在一些实施方式中,多个块(或其子集)可以残差地连接在“残差链”(例如,块503)中,该“残差链”可以从机器学习模型500的输入端532向机器学习模型500的输出端534延伸。停用机器学习模型500的多个块的子集可以包括停用残差链内的起始残差块512和残差链的残差尾部部分530。残差尾部部分530可以包括块(例如,块514-522),这些块在残差链内并且从起始残差块512向机器学习模型500的输出端534延伸。因此,残差尾部部分530可以包括位于起始残差块512“之后”的块514-522的连续串。当残差尾部部分530被停用时,残差连接528可以(例如,“绕过”停用部分512、530)将信息传递给后续的层或块(例如,给分类层524)。因此,块512、530的子集可以包括机器学习模型500的多个块503内的连续块链。
图6描绘了根据本公开的示例实施例的减少与机器学习模型相关联的计算成本的示例方法的流程图。尽管为了说明和讨论的目的,图6描绘了以特定顺序执行的步骤,但是本公开的方法不限于特定地说明的顺序或布置。在不偏离本公开的范围的情况下,可以以各种方式省略、重新布置、组合和/或调整方法600的各种步骤。
在(602)处,方法600可以包括确定资源分配参数,该资源分配参数与在推断时间对对机器学习模型的系统资源的期望分配相对应。在一些实施方式中,可以在将模型输入输入到机器学习模型之前(例如,在推理时间之前)确定资源分配参数。还可以基于计算设备的当前状态来确定资源分配参数。作为示例,当计算设备的电池状态为低时,资源分配参数可以与在推断时间对机器学习模型的系统资源的低期望分配相对应,以保持计算设备的剩余电池功率。类似地,当当前可用处理器能力低和/或大量应用当前正在执行时,资源分配参数可以与系统资源的低期望分配相对应以避免长处理时间。因此,所得到的机器学习模型可以基于计算设备的当前状态进行调整,以快速提供解决方案和/或保留计算设备的资源。
在一些实施方式中,用户可以提供指示用户想要分配给机器学习模型的计算资源量的输入。作为示例,用户可以与计算设备(例如,智能电话)的触摸敏感显示屏进行交互以提供输入。例如,用户可以(例如,经由键盘)输入值或调节滑块(或其他虚拟控制对象),以指示她的对更快的结果但潜在的不太准确的结果或较慢但潜在的更准确的结果的偏好。
在(604),该方法可以包括基于资源分配参数停用机器学习模型的多个块的子集。可以使用各种合适的技术来停用块的子集。作为示例,可以断开块的子集,以使得信息不被输入到块的子集中。作为另一示例,停用子集可以包括调节与块的子集相关联的相应激活函数。可以调节激活函数,以使得每个节点的输出被设置成恒定值,诸如1或0。停用块的子集可以包括任何合适的技术,以使得在推断时间块的子集的计算资源的消耗被实质上减少或消除。
在一些实施方式中,可以基于资源分配参数的幅度来选择多个块的子集的大小,以使得多个块的子集的大小与资源分配参数的幅度负相关。例如,小的资源分配参数可以导致在推断时间之前停用大量块。然而,在其它实施方式中,取决于所选择的惯例,多个块的子集的大小可以与资源参数的幅度正相关。
在一些实施方式中,例如,如上文参考图4所解释的,计算系统可以至少部分地基于与执行机器学习模型中的每个相应块相关联的计算资源量来选择用于停用的块。
在(606),例如,如参考图1A到2C所述,方法600可以包括将模型输入输入到多个块的子集被停用的机器学习模型。
在(608),例如,如参考图1A到2C所述,方法600可以包括接收模型输出作为机器学习模型的输出。
图7描绘了用于示例方法的流程图,该示例方法将机器学习模型训练为针对在推理时间停用机器学习模型的神经网络的多个块中的至少一些块是鲁棒的。尽管为了说明和讨论的目的,图7描绘了以特定顺序执行的步骤,但是本公开的方法不限于特定地说明的顺序或布置。在不偏离本公开的范围的情况下,方法700的各个步骤可以以各种方式被省略、重新排列、组合和/或调节。
在(702),方法700可以包括使用训练数据集(例如,训练数据162)迭代地训练机器学习模型。训练数据集可以包括任何合适的训练输入数据集,并且可选地可以包括训练输出数据集。示例训练数据集可以包括音频文件和音频文件中口语单词的识别文本。另一示例训练数据集可以包括图像和描述识别到的、图像中描绘的对象的位置和/或标签的对象识别输出。
在(704),方法700可以包括在机器学习模型的迭代训练的至少一次迭代之前停用机器学习模型的多个块的迭代特定子集。可以以各种合适的方式选择迭代特定的子集。作为一个示例110,可以基于与神经网络内的每个块的相应位置正相关的与每个块相关联的相应概率来选择迭代特定子集。应当理解,例如参考图4和图5,可以使用如上所述的关于在推断时间之前基于资源分配参数停用多个块的子集的方法类似的方法来选择迭代特定子集。再次参考图4,在训练期间,可以以半随机方式选择迭代特定的块的子集,该半随机方式相对于停用位于机器学习模型的输入端附近的块,偏好停用位于机器学习模型的输出端附近的块。例如,在第一次迭代中,可以停用第一迭代特定块的子集(例如,阴影块414、418、422和424);在第二次迭代中,可以停用第二迭代特定块的子集(例如,块412、416、418和422);在第三次迭代中,可以停用第三迭代特定块的子集(例如,块408、414和424)可以被停用;等等。作为另一示例,再次参考图5,在第一次迭代中,可以停用第一迭代特定块的子集(例如,起始残差块512和相关联的残差尾部部分530)。在第二次迭代中,可以选择不同的块(例如,块518)作为起始残差块,以使得第二迭代特定块的子集(例如,块518、520、522)被停用。在第三次迭代中,还可以选择另一块(例如,块508)作为起始残差块,以使得第三迭代特定块的子集(例如,块508-522)被停用,等等。因此,机器学习模型可以被训练为针对在推理时间停用可能被停用的块是鲁棒的。这种训练方法可以改进机器学习模型在推理时间的输出的质量。
本公开的系统和方法提供了许多技术效果和益处,包括例如减少机器学习模型在推理时间所要求的计算资源。此外,在期望具有不同计算需求的机器学习模型的变体的情况下,用于设备上的机器学习模型的存储可以如可调整机器学习模型被减少,该可调整机器学习模型可以调节其计算需求,可以替代多个机器学习模型。所描述的系统和方法还可以减少训练机器学习模型所要求的计算资源,因为可以训练可调整的机器学习模型来代替具有不同计算需求的多个机器学习模型。
本文讨论的涉及服务器、数据库、软件应用和其他基于计算机的系统,以及所采取的动作和向这些系统发送的信息和从这些系统发送的信息。基于计算机的系统固有的灵活性允许在组件之间和组件中的任务和功能的种类繁多的可能配置、组合、以及划分。例如,本文讨论的过程可以使用单个设备或组件或组合工作的多个设备或组件来实施。数据库和应用可以在单个系统上实施,也可以跨多个系统分布。分布式组件可以顺序或并行地操作。
虽然已经针对本主题的各种具体示例实施例详细描述了本主题,但是每个示例都是作为解释而提供的,而不是作为对本公开的限制。本领域技术人员在理解前述内容后,可以容易地产生对这些实施例的改变、变化和等效。因此,本主题公开并不排除包括对本领域普通技术人员显而易见的对本主题的这样的修改、变化和/或添加。例如,作为一个实施例的一部分示出或描述的特征可以与另一实施例一起使用以产生又一实施例。因此,本公开的目的在于涵盖这种改变、变化和等效物。
- 用于提供具有可调节计算需求的机器学习模型的系统和方法
- 用于训练机器学习模型和用于提供患者的估计内部图像的系统和方法