基于生成对抗深度卷积网络的流量识别方法
文献发布时间:2023-06-19 11:11:32
技术领域
本发明涉及计算机网络安全技术领域,特别是涉及基于生成对抗深度卷积网络的流量识别方法。
背景技术
互联网的快速发展,增加了人们对互联网的依赖,同时也潜移默化的改变了人们的生活方式和社会习惯,网络空间中的流量数据的类型和数量也在不断增加,越来越多的网络安全问题和网络服务质量问题给用户的使用带来了不小的影响。网络流量识别技术作为网络安全的基础,在维护信息安全和保障网络合理运行等方面具有重要的作用。一方面,可以通过对网络流量分析来识别其中可疑数据包。另一方面,管理员可以通过网络流量识别技术更有效的合理分配网络资源,以便提供更优质的网络服务。随着互联网环境的更新换代,网络流量数据呈现出海量,高维复杂且各类别呈现不均衡的特点,直接用来识别异常行为十分困难。此外传统的机器学习方法出现识别效率低下、误报率和漏报率较高的问题,已不能满足网络信息安全的需求。
目前最常用的网络流量识别技术主要包括基于端口的网络流量识别技术、深度包检测技术和基于机器学习法的网络识别技术。现如今互联网的飞速发展致使网络应用频繁更新,越来越多的新型网络应用已经不再刻意遵循端口号注册规则,使用的端口号大多都是随机选取的,因此给端口号的识别带来了巨大的挑战。深度包检测技术不再局限于端口号,而是检测网络流量中的负载特征,通过判断流量数据中的负载特征字段和已知特征,来区分该流量的类别。一方面,尽管该方法识别的准确率较高而且简单高效,但是依旧存在一定的局限性。在网络应用的频繁更新迭代过程中,原有的特征字段极有可能会发生改变,需要及时对特征字段处理并进行更新,因此该方法的维护成本比较高。另一方面,该方法难以对加密的流量进行识别,因为数据加密后就会丢失所属的负载特征,而且目前的大多应用为了安全都会考虑进行加密传输。因此,该方法也难以胜任当前的网络流量识别需求。虽然传统的机器学习在网络流量识别及异常识别当中能够取得不错的性能,但是由于它特别依赖研究人员手工提取特征,分类效果一般取决于手工特征提取的优劣,无法对大型数据集处理。流量特性过时较快,需要经常不断的更新,而且手工特征的选择限制了传统机器学习的鲁棒性和泛化能力。此外,传统的机器学习都是浅层结构的模型,限制了其表示和分类能力。
发明内容
本发明提供的基于生成对抗深度卷积网络的流量识别方法,可以解决现有技术中存在的问题。
本发明提供了基于生成对抗深度卷积网络的流量识别方法,包括以下步骤:
步骤1,流量数据预处理:
读取原始流量数据,根据流量粒度将连续的原始流量数据切分为会话和所有协议层次数据的流量单元,并删除数据链路层的Mac地址和IP层IP地址;将处理后的流量单元文件按照二进制形式转化为灰度图像;将灰度图像转化为IDX文件;
步骤2,流量数据拟合扩充:
将步骤1生成的每一类流量单元文件的IDX文件分别输入WGAN,经过拟合和扩充后生成新的灰度图像,将灰度图像分为训练样本和测试样本,将训练样本和测试样本的灰度图像转化成IDX文件;
步骤3,神经网络训练与识别:
将步骤2输出的IDX文件中的训练样本输入卷积神经网络中,对卷积神经网络进行训练,训练完成后使用测试样本进行性能测试,最后将待识别的流量数据输入卷积神经网络进行流量识别。
优选地,步骤1中通过丢弃数据包中的相关字符串来删除Mac地址和IP地址。
优选地,步骤1中将处理后的流量单元文件统一截取为固定长度,然后将统一长度的流量单元文件转化为灰度图像。
优选地,步骤1中所述固定长度为784字节,如果流量单元文件长度小于784字节,在流量单元文件后面补0x00;如果大于784个字节,裁剪至784个字节。
优选地,步骤2中每类流量生成多张灰度图像,删除一部分拟合不充分的图像,剩下的图像按照一定比例随机分为训练样本和测试样本。
优选地,步骤3中的卷积神经网络有7层,步骤2得到的IDX文件从输入层输入28x28的灰度图像,卷积层C1采用32个特征图,卷积窗口的大小为5x5,下采样层S2具有32个特征图,采样区域大小为2x2,移动步长为2,输出特征图的大小为14x14,卷积层C3和C4有64个特征图,下采样层S5的采样区域大小为2x2,移动步长为2,输出特征图的大小为7x7,卷积层C6的特征图数量为64,全连接层F7神经元数量为1024。
本发明中的基于生成对抗深度卷积网络的流量识别方法,具有以下优点:
1.海量高维数据。由于网络数据量的成倍增长,怎样对海量数据快速准确处理成了当前亟待解决的问题。传统的机器学习方法通常先使用聚类或者降维的方式对海量数据处理,再通过分类器对处理好的数据进行分类。由于传统机器学习的都是数据的浅层表示,在进行分类时效果较差。而深度学习具有强大的表征学习能力,更容易对大型高维数据处理。本发明采用卷积神经网络,不仅能处理高维数据,还能提高整体流量的识别准确率。
2.数据集各类别间数量不均衡。当前网络安全领域公开并著名的数据集各类别间大小差异很大,采用深度学习进行流量识别与分类时最后的结果也会产生差异。当前在解决数据集不平衡问题上的研究相对较少,通常通过采样方式来调整数据集的不平衡。采样方式主要分为两种欠采样和过采样,主要通过减少较大样本的数量和增加较少样本的数量来达到数据集的相对平衡。但欠采样容易产生偏差,过采样又容易引发过拟合问题,因此这些采样方法在处理数据集不平衡的问题上均存在一定的局限性。本发明采用WGAN重新生成新的平衡的流量样本,以提高异常流量的识别准确率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明识别方法的整体流程示意图;
图2为数据集预处理流程示意图;
图3为数据集再处理流程示意图;
图4为卷积神经网络示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
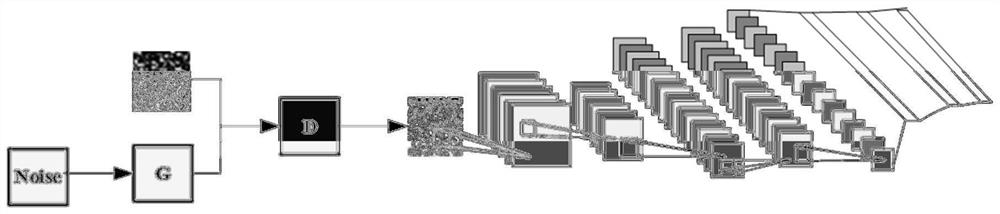
参照图1,本发明提供了基于生成对抗深度卷积网络的流量识别方法,该方法包括流量数据预处理、流量数据拟合扩充和神经网络训练与识别三个步骤。下面对每个步骤进行详细说明。
步骤1,流量数据预处理。
1、流量切分并删除Mac地址和IP地址。
读取原始流量数据,根据流量粒度将连续的原始流量数据切分为会话和所有协议层次数据的流量单元,并删除数据链路层的Mac地址和IP层IP地址。本实施例中通过丢弃数据包中的相关字符串来删除Mac地址和IP地址,因为它们的存在会导致模型过拟合。
2、统一大小并生成图片。
将上述处理后的流量单元文件统一截取为固定长度,本实施例中所述固定长度为784字节,如果流量单元文件长度小于784字节,那么要在流量单元文件后面补0x00;如果大于784个字节,裁剪至784个字节。然后将统一长度的流量单元文件按照二进制形式转化为灰度图像,该灰度图像格式为png。
3、灰度图像转化为IDX文件。
将png格式的灰度图像转化为IDX文件,因为IDX文件是深度学习领域常用的标准文件输入格式。
步骤2,流量数据拟合扩充。
流量数据预处理生成的每一类(共20类)流量单元文件的IDX文件分别输入WGAN(Wasserstein GAN),经过拟合和扩充后生成新的28*28的灰度图像,每类流量生成12000张灰度图像,并删除前5000张拟合不充分的图像,剩下的7000张按照8:2的比例随机分为训练样本和测试样本。这样各类流量单元文件之间的数量一致,保持了各类别之间的平衡,然后这些灰度图像再转化成新的IDX文件,最后作为卷积神经网络的输入。
步骤3,神经网络训练与识别。
将步骤2输出的IDX文件中的训练样本输入卷积神经网络中,对卷积神经网络进行训练,训练完成后使用测试样本进行性能测试。最后将待识别的流量数据输入卷积神经网络进行流量识别。
本发明中的卷积神经网络有7层,步骤2得到的IDX文件从输入层输入28x28的灰度图像,卷积层C1采用32个特征图,卷积窗口的大小为5x5,经过下采样层S2,该层具有32个特征图,采样区域大小为2x2,移动步长为2,输出特征图的大小为14x14,卷积层C3和C4有64个特征图,下采样层S5的采样区域大小为2x2,移动步长为2,输出特征图的大小为7x7,卷积层C6的特征图数量为64,全连接层F7神经元数量为1024,全连接层F7输出的数据通过softmax分类,分为20类,分别对应20类流量。
本发明实验平台为戴尔笔记本,系统为Window10,处理器为Intel(R)Core(TM)i5-6200U@2.40GHz,RAM为8GB,语言为python,学习框架为Tensorflow。实验数据集采用公开并著名的数据集USTC-TFC2016,因为USTC-TFC2016数据集中各类别间的大小差别很大,如:最小的Tinba流量大小为2.55Mb,最大的流量Weibo流量大小为1620.4Mb。正是由于这种数据集各类别间大小不均衡性,更能体现该模型的性能。实验主要分为以下几个步骤:
1.流量数据预处理。通过对原始流量数据进行切割,采用会话加所有层的切割方式,并删除冗余部分,最后生成IDX格式的数据集作为WGAN的输入。
2.流量数据拟合扩充。通过噪声生成新的拟合扩充后的IDX数据集,该数据集各类别间数量相对平衡,作为改进的卷积神经网络输入。
3.神经网络训练与识别。通过加载训练样本对卷积神经网络进行训练,训练完成后保存训练模型,然后使用测试样本测试,加载本地训练模型,通过一系列评价标准来计算评价结果。
分析实验结果,生成对抗深度卷积网络较传统的机器学习均有较大提升,相对于LeNet-5(一种用于手写数字集的卷积神经网络),Neris和Virut流量F1-score值分别提升了约10%和12%,相对于门控递归单元(GRU)分别提升了约12%和13%,相对于长短期记忆网络(LSTM),分别提升了约7%和14%,相对于改进的卷积神经网络,分别提升了约6%和9%,总的来看改进的卷积神经网络和生成对抗深度卷积网络实验结果中有16种流量的F1-score值都能达到99%。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 基于生成对抗深度卷积网络的流量识别方法
- 一种基于深度卷积生成对抗网络的场景识别方法