一种基于生成对抗网络的无监督多模态图像转换方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明属于深度学习中的生成对抗网络领域,并引入了注意力机制,是一种实现了无监督多模态图像转换的方法。
背景技术
深度学习是机器学习的子领域,它使用了多层次的非线性信息处理和抽象,用于有监督、无监督、半监督、自监督、弱监督等的特征学习、表示、分类、回归和模式识别等。近年来,深度神经网络在监督学习中取得了巨大的成功,此外,深度学习模型在无监督、混合和强化学习方面也非常成功。因为缺乏足够的先验知识,因此难以人工标注或标注成本太高,我们希望计算机能够代替我们完成这些工作或提供一些帮助,因此无监督学习在近些年获得了很大的发展,这也是深度学习领域未来发展的方向。深度学习技术也越来越受到研究者的重视,并已成功地应用于许多实际应用中。
而在生成对抗网络(GAN)的应用方面,近年来也是深度学习领域中一个热门的研究课题,也是迄今为止最成功的生成模型。2014年至今,人们对GAN进行了广泛的研究,并提出了大量算法,GAN由两个网络组成:一个生成器合一个判别器,分别负责伪造图片和识别图片真假。生成器产生图像的目的是诱使判别器相信它们是真实的,同时,判别器会因为发现假图片而获得奖励。通过两者的相互博弈,共同提高性能。GAN在图像处理与计算机视觉、自然语言处理、语音与音频、医学以及数据科学中都有着广泛的应用。
近几年,注意力机制不管在自然语言处理还是在计算机视觉领域中,都是热门的研究方向。许多学者也提出了若干种注意力机制来提高模型的相关任务的性能。计算机视觉中的注意力机制的基本思想是想让模型学会注意力,即能够忽略无关信息而关注重点信息。
图像的跨域转换是近些年新兴起的一种基于深度学习的技术,它也伴随着深度学习发展的而发展迅速。图像跨域转换旨在学习将图像从一个域转换到另一个域的映射。而传统方法只能做到对底层特征的提取,而卷积神经网络能够对图像特征的高层特征的提取,使得图像内容与域风格分离提供了可行性。
从目前相关领域的研究现状来说,目前的图像转换算法主要分为两大类,一种是基于匹配数据的图像转换算法,另一种是基于非匹配数据的图像转换算法。具体来说,数据的匹配指的是从内容角度来看,两张图像具有一致的内容属性,但是从域风格角度来看,两者属于不同的风格域。根据目前的研究结果,基于匹配数据集的算法实验效果更优,但是匹配的数据集稀少,获取难度大也是不可忽视的问题,这也导致基于匹配数据集的风格转换算法应用的范围较小,这也促使基于非匹配数据的无监督图像转换算法成为了众多研究者进行研究的侧重点。目前的非匹配数据算法存在着图像细节不够清晰,边缘形状发生改变以及训练较为困难等问题。而本发明利用编解码器,对图像进行拆分重组操作,对拆分的内容编码进行保留,并引入注意力机制使得网络关注于重要区域的细节信息,能够解决上述存在的相关难题。
发明内容
为了克服现有技术的不足,本发明提供一种基于生成对抗网络的无监督多模态图像转换方法,在没有互相匹配的图像数据情况下,利用深度学习技术,实现将图像的风格所属域进行有效的转换。通过精心设计的网络结构,能够有效地提高转换图像的质量且适应于更广阔的应用场景范围。
本发明解决其技术问题所采用的技术方案是:
一种基于生成对抗网络的无监督多模态图像转换方法,所述方法包括以下步骤:
1)输入属于A域的图像x
2)编码器将图像编码为图像内容编码c以及域风格编码s;
3)针对不同的域图像配置不同的域特定编码m;
4)将内容编码c、域风格编码s和域特定编码m融合并解码,生成指定目标域图像,若将A域图像x
5)判别器对生成器生成的图像进行质量评判,区分输入判别器的图像是真实图像或网络生成的假图像;
6)将步骤1)~5)不断重复设定的次数,生成器与判别器不断相互博弈,共同提高性能,直到网络收敛。
进一步,所述图像跨域转换神经网络利用域特定编码,只使用一个生成网络即可完成多域图像的互相生成转换。对比传统模型需要多个生成网络模型才能完成多域的转换,本方法大大简化了模型与训练过程。
更进一步,本发明使用的域特定编码命名为m
更进一步,针对生成器结构,其中包含编码器与解码器的结构,编码器对图像进行编码操作,其中包含两个编码器结构:内容编码器,对图像的内容特征进行编码,生成内容编码;域风格编码器,对图像的域风格特征进行编码,生成域风格编码;解码器对编码器完成的编码进行解码,将内容编码、域风格编码和域特定编码融合,合成对应的目标域图像。编码器通过学习特定风格的分布特点,因此成对匹配的监督数据不是训练必备,实现了无监督训练的特点,减小了数据收集的难度。
更进一步,引入了一种注意力机制,将卷积网络提取的特征进行可视化后形成热力图,根据热力图,教会了神经网络能够关注于重要的区域。在生成器以及判别器中都引入了注意力机制,设某一层神经网络提取到的特征图的通道数为n,对应的n张特征图用f
更进一步,判别器本发明使用了多尺度判别器来引导生成器生成真实的细节以及正确的全局结构。本发明选择了三个尺度来进行判别器的训练,第一尺度为原始输入图像的分辨率,第二与第三尺度分别为原始输入图像分辨率的二分之一与四分之一。
本发明的有益效果表现在:通过本发明,只需一个生成网络即可完成多域的图像转换,相比于传统模型,在完成了一对多转换的同时,也并不需要匹配的监督数据,有着广大的应用场景。
附图说明
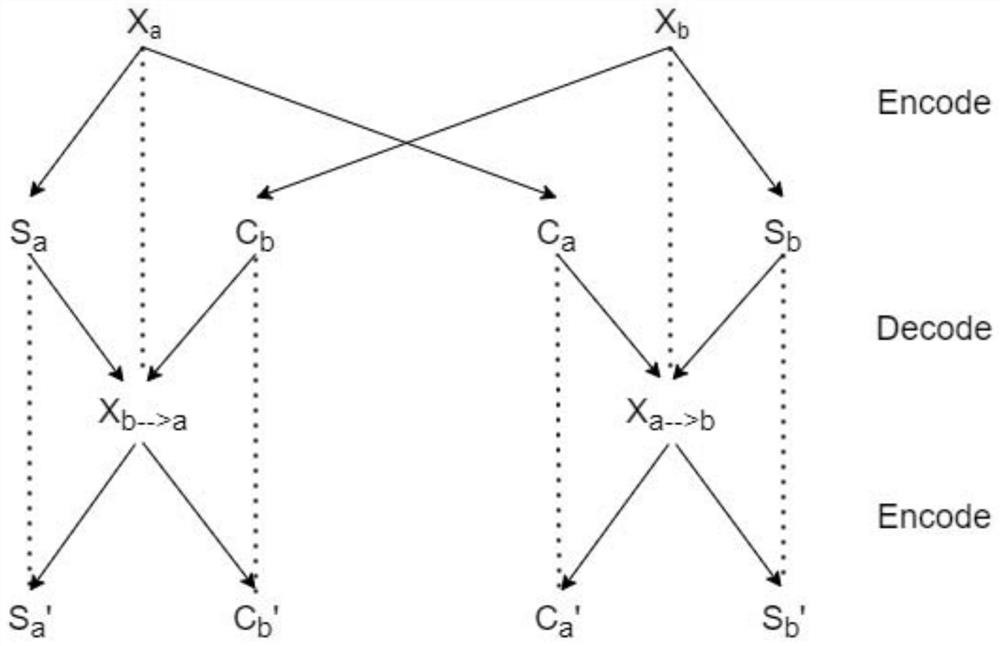
图1为一种基于生成对抗网络的无监督多模态图像转换方法的主要流程机构示意图。
图2为一种基于生成对抗网络的无监督多模态图像转换方法中自编码器流程示意图。
图3为一种基于生成对抗网络的无监督多模态图像转换方法中自编码器内部结构细节示意图。
图4为一种基于生成对抗网络的无监督多模态图像转换方法中注意力机制的方法示意图。
图5为一种基于生成对抗网络的无监督多模态图像转换方法中多尺度判别器示意图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图5,一种基于生成对抗网络的无监督多模态图像转换方法,将需要互相转换的两个域图像命名为x
进一步,本方法做了以下设定:首先,假设图像的潜空间可以分解为域内容空间和域风格空间。进一步假设不同域中的图像共享一个公共的内容空间,而不是风格空间。如图1所示,为了将图像转换到目标域,我们将其内容编码与目标风格编码重新组合。将图像拆分成为内容编码c与风格编码s,而内容编码即为转换期间应该保留下来的信息。m为不同域所分配的域特定编码,通过m可引导生成器进行哪两个域的互相转换。
更进一步,转换模型包含同一对域编码器E与解码器D,如图2所示,自编码器将图像x映射成为内容编码c与风格编码s,其中c=E
更进一步,如图3所示,为本方法的自编码器结构示意图,它由内容编码器、风格编码器和解码器组成;内容编码器E
更进一步,如图4所示,为本方法中注意力机制的方法示意图,本方法将输入图像经过下采样和残差块后得到的内容特征图,经过全局平均池化层和全局最大池化层,得到依托于通道数的特征向量。创建可学习参数weight,经过全连接层压缩到B×1维,这里的B是BatchSize大小,对于图像转换任务,该值通常取为1。对于学习参数weight和EncoderFeature map做multiply(对应位想乘)也就是对于Encoder Feature map的每一个通道,我们赋予一个权重,这个权重决定了这一通道对应特征的重要性,这就实现了Feature map下的注意力机制。对于经过全连接得到的B×1维,在average和max pooling下做concat后送入分类,做源域和目标域的分类判断,这是个无监督过程,仅仅知道的是源域和目标域,这种二分类问题在CAM全局和平均池化下可以实现很好的分类。当生成器可以很好的区分出源域和目标域输入时在注意力模块下可以帮助模型知道在何处进行密集转换。将average和max得到的注意力图做concat,经过一层卷积层还原为输入通道数,便送入AdaIN下进行自适应归一化。
更进一步,如图5所示,考虑到算法落地的应用场景并不需要部署判别器的模型,因此判别器在训练过程中则使用了多个判别器进行训练,每种模态对应于一个判别器。判别器对生成器生成的目标模态影像进行判别打分,最低分为0,最高分为1,越接近真实MRI模态影像得分越高。为了使判决器在感知到图像全局信息的同时,还能够关注到局部信息,判别器在设计结构上采用多尺度判别器,防止了影像细节有误却别判别器误判为整体质量优异的影像。多尺度判别器采用了三个网络结构一样的判别器,对生成影像进行两次下采样,每次下采样将目标影像缩小至一半的辨率后,对多个尺度图像进行判别,提高了影像生成质量。
另外值得注意的是,本方法所用的判别器会预先经过一次分类的实验训练,用于区分不同模态MRI的分类。具体来说,训练不同的分类器能够准确进行不同模态MRI的判别,例如分类器D
将上述步骤循环若干的设定次数后,生成器与判别器相互博弈,互相进步,最终的生成器具有强大的性能,根据一张其他风格的参考图像,即可生成十分逼真的属于该风格的转换图像。
以上通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点和功效。本发明还可以通过另外不同的具体实例方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互结合。
需要说明的是,以上实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图示中仅显示与本发明中有关的组件而非按照实际实施时的组件数目绘制,其实际实施时各组件的数量及比例可为一种随意的改变。
- 一种基于生成对抗网络的无监督多模态图像转换方法
- 一种基于随机重构的无监督图像到图像的转换方法