一种基于机器学习的文本分类方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及文本分类技术,特别涉及一种基于机器学习的文本分类方法。
背景技术
随着互联网和社交媒体的发展,目前网络上已经有海里的文本信息,包括维基百科词条、学术文章、新闻报道、以及各种售后服务评论,而这些文本信息中蕴含了大量有价值的信息,
在海量的电子文本数据之中想要实现快速、准确获取到目标数据,对文本文档实现合理分类就变成了这个过程当中一个非常直接和现实的迫切问题。
20世纪80年代以前,受限于技术的发展,处理文本分类这类问题时,通行的做法是通过专家制定规则、人为地选择、制定分类准则从而完成分类器的指导和搭建工作。比较著名的例子是Carnegine Group为路透社开发的CONSTRUE系统,该系统首先由专业人员设计编写分类规则并指导系统完成分类巩固走,主要用于对新闻稿件实现自动分类;同时期还有美国白宫采用的一种邮件分类系统,主要用于对电子邮件的自动分拣和处理工作。这种分类方法在当时取得了比较好的效果,并对文本分类技术起到了积极作用和产生了深远影响。
通过知识工程构建起来的分类器有诸多缺陷:首先需要人类专家根据对待分类文档进行特征分析、总结得到对象特点的基础上,再人为设计提出并选定适当规则,并且针对一个领域所建立的文本分类器在应对其他知识领域的分类情况时,往往回出现分类效果不佳等问题,主要原因在于通过知识工程构建文本分类方法的过程中存在对专家能力过度依赖。由于人类专家研究领域有限,所建立的文本分类器的有效领域也是有限的,在其他领域使用会出现可复现性差或迁移能力差等相关问题。此外,在涉及到数据集规模较大较复杂的文本分类情况时,为应对比较大的工作量又需要大量的专家参与其中,故又显示出方法不够聪明并且费时费力的缺陷。
发明内容
本发明通过引入一种基于机器学习的文本分类方法,以此进行更高效的文本分类。
本发明一种基于机器学习的文本分类方法,其中,包括:文本数据预处理、文本表示、特征降维、分类模型训练以及分类性能评估;文本数据预处理具体包括:按照顺序需要对文本数据进行操作:文本标记、文本分词处理以及去除停用词处理;文本表示包括:经过文本预处理之后,将文本表示成一种形式化数学描述,使之成为计算机能够识别的语言;卡方统计算法以及互信息算法,进行特征降维;分类模型训练包括:采用SVM来进行分类,定义训练数据集中的两个类别中几何距离最近的两组数据为支持向量,超平面H就是与这两组分属于不同类别的数据连线的垂直平分线,而分类线H1与H2分别是指经过这两个类别中支持向量,首先寻找支持向量,通过训练集中不同类数据的几何距离来剔除大量冗余数据,根据保留的少量数据即支持向量,找到超平面H进行类别划分。
根据本发明所述的基于机器学习的文本分类方法的一实施例,其中,文本标记的处理包括:文本中的表情符、图片或者链接非中文字符无法对文本分类提高直接且有用的帮助,进行删除。
根据本发明所述的基于机器学习的文本分类方法的一实施例,其中,去除停用词包括:经过分词处理之后的文本数据仍然还存在许多功能词和停用词,对停用词和功能词进行额外删除。
根据本发明所述的基于机器学习的文本分类方法的一实施例,其中,文本分词的处理包括:首先识别出中文语句中存在的标点符号或是某些汉语文字,并在这些出现位置上通过添加空格符实现切分效果并得到切分后的词条内容,相邻字通过统计学方法得到分布信息,如果得到统计值很高达到一定阈值时,就判定这组相邻的字就可能是一个词语。
根据本发明所述的基于机器学习的文本分类方法的一实施例,其中,文本表示通过VSM模型表示成一种形式化数学描述,通过将文本中带有文本主题特征的那些词项表示成特征向量,每一个具有独立属性的词项所对应的一个特征向量就构成了这篇文本特征向量的一个维度,将文本转化成了空间中的一个高维特征向量。
根据本发明所述的基于机器学习的文本分类方法的一实施例,其中,利用VSM模型对文本进行文本表示时,词项以及词项的权重将成为文本表示这个模型的组成部分,文本D就能被n个词项以及他们的权重值所组成的特征向量代表,表示形式如下:D={(t
根据本发明所述的基于机器学习的文本分类方法的一实施例,其中,卡方统计算法包括:
卡方统计算法公式基于词项的词频因子,其大小等于这个词项在该类别文档中出现的词频数与在全体文本数据集文档中存在该词项的文本频数大小的比值。其计算公式:
n(t
词频因子α(t
根据本发明所述的基于机器学习的文本分类方法的一实施例,其中,互信息算法包括:提出基于词项的调节因子,大小等于该类别文档中存在这个词频的文本书与该类别文档中总文本数大小的比值,其计算公式如下:
D(t
调节因子D(t
本发明提出了一种基于机器学习的文本分类方法,在CHI中引入词频因子,MI中引入调节因子,形成新的特征选取算法CHMI,理论效果优于卡方统计和互信息算法。实现快速、准确获取到目标数据。
附图说明
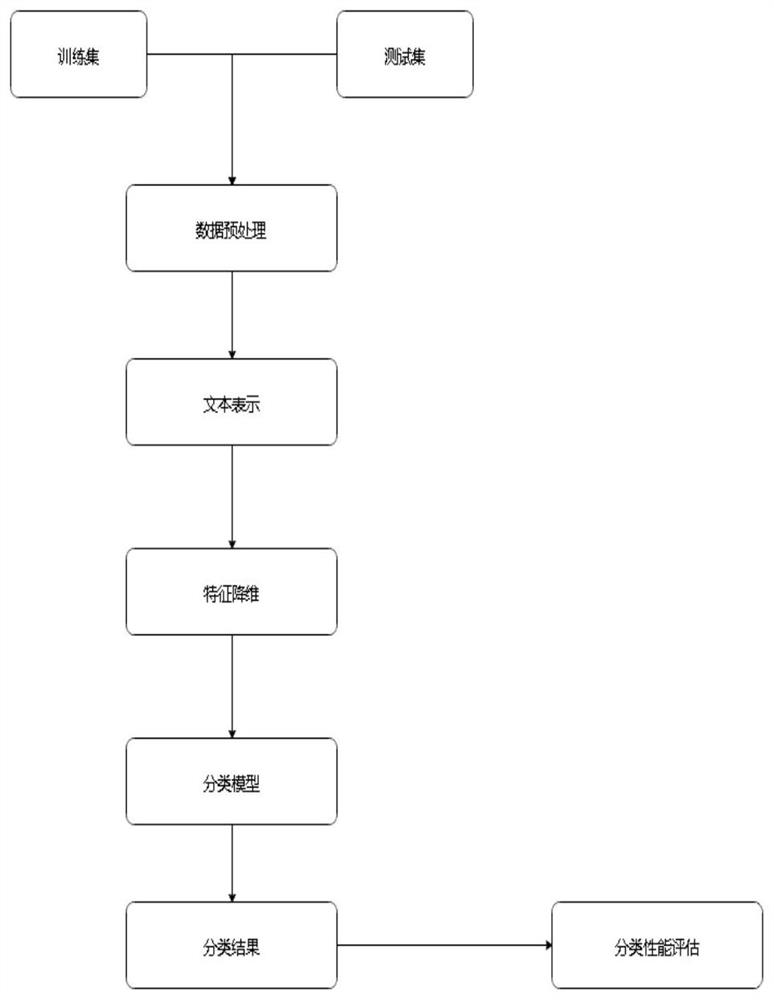
图1为基于机器学习的文本分类方法示意图;
图2为训练数据集中存在所属类别不相同的两种数据分别用不同的图形表示。
具体实施方式
为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
本发明一种基于机器学习的文本分类方法包括:
如图1所示,在文本分类技术的历史发展进程中,最初是由人工为主导定义分类规则,后来逐渐发展成为由计算机主导通过计算机识别、分类模型训练,最终得到分类结果。文本分类方法一般包含以下几个关键处理环节,分别是:文本数据预处理、文本表示、特征降维、分类模型训练、分类性能评估等步骤。
文本数据预处理具体包括:
为实现文本自动分类,在拿到数据集后的第一个处理步骤是对文本数据首先进行预处理操作,在这一过程中,按照顺序需要对文本数据进行如下操作:文本标记、分词、以及去除停用词处理
文本标记的处理包括:
文本中的表情符、图片或者链接等非中文字符无法对文本分类提高直接且有用的帮助,需要删除。
文本分词的处理包括:
中文文本分词技术的基本原理是利用分词算法,首先识别出中文语句中存在的标点符号或是某些汉语文字,并在这些出现位置上通过添加空格符实现切分效果并得到切分后的词条内容。本方法采用基于统计的分词技术,该技术的主要思想是:在数据集中利用N-gram、最大熵等模型实现对一些相邻字通过统计学方法得到他们的分布信息,如果得到统计值很高达到一定阈值时,就判定这组相邻的字就可能是一个词语。按照这种方法进行中文分词,具有方法简单、容易实行等优点
去除停用词包括:
经过分词处理之后的文本数据仍然还存在许多功能词和停用词,如“并且、而且,还”,“是、在、有”,“的”等,这些词的使用频率虽高,却不能为文本分类提高任何判别信息,为方便后续分类,需要在本阶段对停用词和功能词进行额外删除。
文本表示包括:
经过文本预处理环节之后,得到的文本数据大概是这样的:“我/热爱/围棋”。这些数据都是字符数据,并且没有呈现出文本的结构化信息,即使将这些数据输入计算机,计算机也无法直接利用和进行后续的文本分类,因此需要对文本数据进行进一步处理,本方法通过VSM模型将文本表示成一种形式化数学描述,使之成为计算机能够识别的语言。
VSM的思想是通过将文本中带有文本主题特征的那些词项表示成特征向量,那么每一个具有独立属性的词项所对应的一个特征向量就构成了这篇文本特征向量的一个维度,最后将该文本转化成了空间中的一个高维特征向量。
利用VSM模型对文本进行文本表示时,词项以及词项的权重将成为文本表示这个模型的组成部分,文本D就能被n个词项以及他们的权重值所组成的特征向量代表,表示形式如下:D={(t
特征降维包括:
特征降维的目的是通过数据降维仍然能够完整保存原始文本特征,不仅能够减少分类计算量,还能提供分类精度、提升效率,同时还可以避免分类器过拟合等现象。特征选取是对文本数据进行的一种常用特征降维方式,一般流程是:根据文本数据集特点,通过选定流程选取适合的特征计算函数,对数据集中的每一条文本中的每个词项分别进行特征计算得到量化结果,将结果按照由大到小进行顺序排列,根据提前设定的阈值情况,从中选出一定数量的特征项作为原始文本数据的代表,期间不涉及特征空间的转化问题。本方法基于CHI、MI,提出一种改进型的特征降维算法。
卡方统计算法(CHI)包括:
CHI算法对文本特征由于具备较好的量化能力,因此经常用于文本分类问题并作为其中一种重要的算法进行使用。但也存在对低频词的高估问题,因此需进行改进。接下来进行举例说明,下附某文本数据集的一段节选的三条语句:
“小郎是一名钢琴家同时也爱好围棋,小郎最崇拜的围棋明星是柯洁,他是一位伟大的围棋运动员,在围棋领域里取得了令人瞩目的成绩”
“据统计,钢琴家中最常见的是男性”
“如何才能成为一名优秀的钢琴家,答案往往是:源于兴趣”
上述节选内容中,一共有三条语句,“围棋”出现了4次,“钢琴家”出现了3次。其中,“围棋”只在语句一中出现,而“钢琴家”在三条语句中各出现1次。现在假设该文本数据集中一共存有20篇文本,分为两个类别。类别一有10篇文本:其中有3篇文本都出现了语句一,剩下的7篇文本中都出现了后两条语句。类别二也有十篇文本:其中没有文本出现语句一,但10篇文本中有2篇出现了后两条语句。利用卡方统计算法公式计算词项“围棋”与“钢琴家”的卡方统计值,此时可以得到“围棋”的卡方统计值CHI=60/17≈3.5,这个值远小于“钢琴家”的卡方统计值CHI=40/3≈13.3。所以按照卡方统计算法的思想,根据计算结果此时进行特征选取需优先选择“钢琴家”作为特征词。但从本文涉及的文本数据集中可以观察得到,词项“围棋”仅在类别一中出现,并且出现频度很高,而词项“钢琴家”在所有类别文档中均有出现,在此时若选择“围棋”作为特征词,可以带来更好的类别分类信息。所以,这里应该选择“围棋”作为特征词。上述内容中提到了卡方统计算法中存在的问题,分析后可知,这是由于算法只统计了存在某词项的文本数量而忽略了该词项在文本中具有词频信息这一重要因素所导致的。当计算某词项的卡方信息值时,如果该词项仅在某一类别文档的少量文本中频繁出现,即使出现频度很高,按照卡方统计算法,得到的结果值也不会太大,就可能导致该词项无法被优先选取为特征词,但往往该词项具备很好的类别分类信息,可以更好的代表文本内容。所以,针对以上情况的发生,为选取得到更好的特征词,需要对该算法做出改进。
针对卡方统计算法公式中,未考虑词项在文本中出现的频度关系,这里提出基于词项的词频因子,其大小等于这个词项在该类别文档中出现的词频数与在全体文本数据集文档中存在该词项的文本频数大小的比值。其计算公式所示:
在上式中,n(t
词频因子α(t
例如:我们可以算出“围棋”的词频因子α(t
互信息算法(MI)包括:
MI算法的基本思想较直接,可以考虑词项与词项的类内分布之间的相关关系,同时它还考虑了词项的类间关系。但它也存在对低频词具备的类别特征信息量的高估问题。接下来进行举例说明,现假定又一文本数据集中共存有2000篇文本,分为两个类别,类别一(即c
根据上表中的数据,利用互信息算法公式得到的互信息值分别为MI(t
上述针对互信息统计算法的公式中,该算法未考虑词项可能在文本中出现频度很少的情况,这里提出基于词项的调节因子,其大小等于该类别文档中存在这个词频的文本书与该类别文档中总文本数大小的比值。其计算公式如下:
在上式中,D(t
调节因子D(t
例如:在前文中,利用本节所述公式及文本数据集情况可以算出词项t
MI(t
改进的卡方-互信息统计算法包括:
上述两节分别对CHI算法、MI算法进行了仔细分析,利用算法函数针对实际应用中的文本数据集案例展开理论计算。并结合文本数据集本身存在的特征,对上述算法的计算结果中存在的问题和不足,展开了关于理论原因的详细讨论,最后提出了改进方法。这里,综合所提出的改进方法,形成了一种新的特征选
取算法函数,计算公式如下:
CHMI(t
ρ*[CHI(t
上式中,ρ∈(0,1)。同理,处理多分类问题时,上述公司可以改进为如下公式:
CHMI
ρ*[CHI
分类模型包括:
采用SVM来进行分类。SVM是一种基于统计学理论的线性二分类算法,在多分类的问题和非线性问题中也可以使用,该算法的基本思想是通过在训练集中找到两个支撑向量和一个超平面,超平面可以是线性也可以是非线性,利用这个超平面可以实现将数据集中两个不同类别的数据进行完整区分,并且使得此时的分类错误率是最低的,以获得最佳的分类性能。下面举例说明
如图2所示,训练数据集中存在所属类别不相同的两种数据,分别用不同的图形表示,首先定义训练数据集中的两个类别中几何距离最近的两组数据为支持向量,超平面H就是与这两组分属于不同类别的数据连线的垂直平分线。而分类线H1、H2分别是指经过这两个类别中支持向量,且与超平面H的平行的两条分类学。分类线H1、H2之间存在的距离即为分类的几何间隔。
SVM算法思想简单直观,首先寻找支持向量,通过训练集中不同类数据的几何距离来剔除大量“冗余数据”,根据保留的少量数据即支持向量找到超平面H进行类别划分。由于超平面H主要是基于支持向量产生的,所以它在处理少量数据的分类问题时具有较大优势和分类精度,在面对大量数据分类问题时可以避免发生“维度灾难”等问题。
本发明提出了一种基于机器学习的文本分类方法,在CHI中引入词频因子,MI中引入调节因子,形成新的特征选取算法CHMI,理论效果优于卡方统计和互信息算法。实现快速、准确获取到目标数据。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 一种基于机器学习的文本分类方法
- 一种基于自动机器学习算法选择的文本分类方法