一种基于模糊匹配算法的单位名称匹配、查找方法及装置
文献发布时间:2023-06-19 12:14:58
技术领域
本发明涉及一种单位名称匹配、查找方法及装置,尤其是涉及一种基于模糊匹配算法的单位名称匹配、查找方法及装置。
背景技术
当今信息技术时代背景下,各行业特别是金融行业对于客户信息的挖掘要求越来越迫切,需要客户信息更加精准,并且挖掘速度更加快捷。为了满足这个需求,引入了ES数据库,ES作为一个分布式的数据库,提供了可扩展的搜索,具有接近实时的搜索能力,并且支持大量数据的精准查询和模糊查询处理。
ES模糊查询,是基于Elasticsearch自带分词方法实现的快速模糊匹配的查询方法。Elasticsearch是一个分布式的数据库,它提供了一个分布式多用户能力的全文搜索引擎,通过HTTP使用JSON进行数据索引。ES可被用作全文检索,结构化搜索,以及数据分析。通过ES自带的字典库以及分词方法,可实现快速查询库表内的相似数据。
但是由于原生的分词方法较为单一,应用场景也较为单一,无法满足对多个单位名称模糊匹配并且获取相似度的业务场景。而且原生的ES模糊查询方法依赖于词库,所以无法达到对单位名称这种模糊匹配要求较高的数据精准匹配。现有技术中对单位名称查找是直接通过Elasticsearch的IK分词,对需要模糊匹配的单位名称进行分词。应用在调用ES原生的模糊匹配方法时,通过给ES数据库发送HTTP的JSON报文实现模糊匹配和查询。但是该技术仅局限于把输入的单位名称进行IK分词,分成不同的索引,然后根据索引定位到数据库内匹配到的名称。这样的匹配方法较为简单,对于一些特定规则的单位,会存在错误匹配的情况,具体体现为:
1、单位名称里面存在简称,ES无法直接识别出简称;
2、单位名称内包含了区域名称,但是ES无法识别出这是个区域,会筛选出非本区域的其他单位名称;
3、单位名称内包含别名字段,但是ES无法直接筛选出别名的单位名称;
4、用户输入的不确定性导致单位名称里面会包含很多无效的字符,比如括号,点等,ES无法识别出来;
5、没有权重概念,ES每个匹配到的分词索引的权重都是一样的,没有办法动态调控不同分词的权重。
发明内容
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于模糊匹配算法的单位名称匹配、查找方法及装置。
本发明的目的可以通过以下技术方案来实现:
一种基于模糊匹配算法的单位名称匹配方法,该方法包括如下步骤:
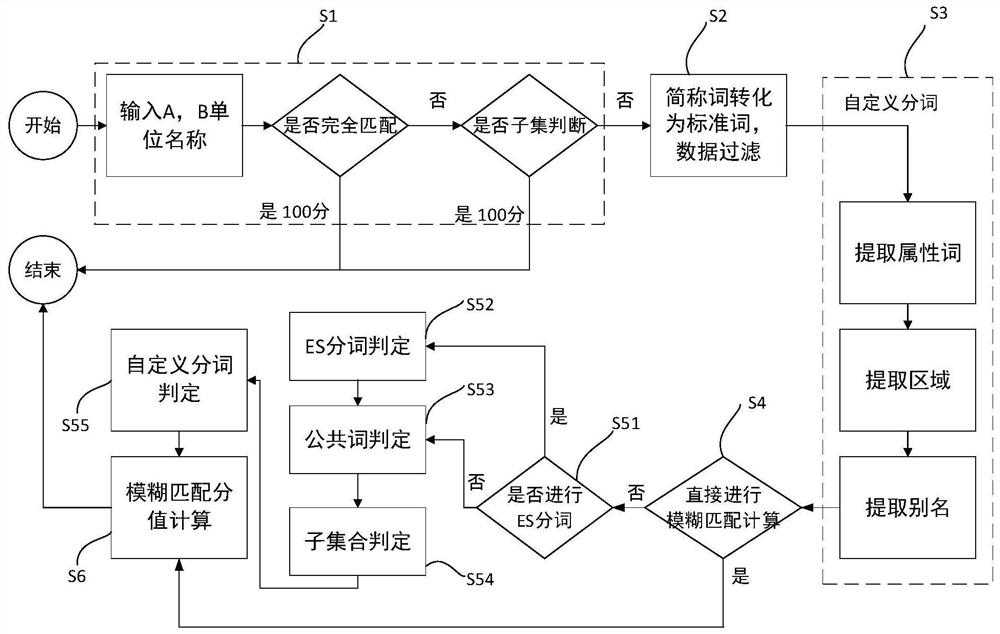
S1、获取待匹配的两个单位名称,判定是否互相包含或者完全匹配,若是则直接输出模糊匹配分值为100,否则执行步骤S2;
S2、对两个单位名称分别进行预处理,包括标准化处理和过滤处理;
S3、对两个单位名称分别进行自定义分词处理获取相应的自定义分词,所述的自定义分词包括三类,分别为属性词、区域词和别名词;
S4、基于自定义分词结果判定能否直接进行模糊匹配计算,若是则执行步骤S6,否则执行步骤S5;
S5、对两个单位名称进行模糊匹配直接判定,若满足模糊匹配直接判定条件,则直接输出模糊匹配分值为100,否则执行步骤S6;
S6、基于自定义分词结果计算两个单位名称中各类自定义分词的模糊匹配分值,进而将各类自定义分词的模糊匹配分值进行加权处理获取两个单位名称的模糊匹配分值。
优选地,步骤S2中标准化处理包括:基于简称词库将单位名称中的简称词替换为标准词。
优选地,步骤S2中过滤处理包括:删除单位名称中无意义的字符,基于无效词库删除单位名称中的无效词。
优选地,步骤S4判定能够直接进行模糊匹配计算的条件包括其中任意一个:
两个单位名称的分词结果中均包含区域词,且区域词不相同;
其中一个单位名称的分词结果中包含别名词,另一个单位名称的分词结果中不包含别名词。
优选地,步骤S5模糊匹配直接判定的具体判定包括:
S51、若两个单位名称的分词结果中均包含别名词,且别名词不相同,则执行步骤S52,否则执行步骤S53;
S52、ES分词判定:利用ES词库自带的IK分词方法对两个单位名称分别进行ES分词得到两个分词结合,将较短的分词集合记作Aset,较长的分词集合记作Bset,若Aset内的所有分词都包含在Bset中,则直接输出模糊匹配分值为100,否则对两个分词集合中的重复分词进行计数记作Cnt,同时记Aset中的分词总数为Cnaset,若Cnaset≥esLen且Cnt/Cnaset≥esPct,则直接输出模糊匹配分值为100,否则执行步骤S53,其中,esLen、esPct为设置阈值;
S53、公共词判定:将字符数较少的单位名称记作A,字符数较多的单位名称记作B,将A中每个字符依次遍历到B中,取得一个最长的匹配到的字符串集合,称作公共词C,若公共词与其中一个单位名称完全匹配且公共词长度超过3位,则直接输出模糊匹配分值为100,否则:将公共词C与单位名称B重新进行自定义分词,若B和C的分词结果中属性词相同,并且别名词为空则直接输出模糊匹配分值为100,否则执行步骤S54;
S54、子集合判定:对步骤S2预处理后的单位名称进行子集判定,若两者互相包含,则直接输出模糊匹配分值为100,否则执行步骤S55;
S55、自定义分词判定:若两个单位名称分词结果中两个区域词集合非空并且相等并且两个别名词集合非空并且相等,则直接输出模糊匹配分值为100,否则执行步骤S6。
优选地,步骤S6中各类自定义分词的模糊匹配分值通过如下方式获得:
记两个公司名称为A和B,对于i类别的自定义分词,将两个公司名称对应的该类别的自定义分词的集合通过最长公共子序列长度计算方法,计算得到i类别自定义分词的最长公共子序列长度maxSubSeq(A,B)
其中,|A|
优选地,两个单位名称的模糊匹配分值通过下式获得:
其中,mathScore表示两个单位名称的模糊匹配分值,
一种基于模糊匹配算法的单位名称查找方法,该方法包括:
获取待查找的单位名称,通过ES模糊匹配确定单位名称词库中匹配度最高的待匹配名称;
将待查找的单位名称与待匹配名称采用权利要求1~7任意一项所述的基于模糊匹配算法的单位名称匹配方法进行匹配确定单位名称词库中待匹配名称与待查找的单位名称的模糊匹配分值。
一种基于模糊匹配算法的单位名称匹配装置,该装置包括存储器和处理器,所述存储器用于存储计算机程序,所述处理器用于当执行所述的计算机程序时实现所述的基于模糊匹配算法的单位名称匹配方法。
一种基于模糊匹配算法的单位名称查找装置,该装置包括存储器和处理器,所述存储器用于存储计算机程序,所述处理器用于当执行所述的计算机程序时实现所述的基于模糊匹配算法的单位名称查找方法。
与现有技术相比,本发明具有如下优点:本发明匹配/查找方法更加精细,匹配/查找结果更加精准可靠,具体表现为:
(1)单位名称里面存在简称,本发明可识别并且匹配到有简称的单位名称;
(2)单位名称内包含了区域名称,本发明可以区别出需要匹配的单位名称里面的区域名,并且根据真实的区域名称进行匹配;
(3)单位名称内包含别名字段,本发明可以识别出别名并且做匹配;
(4)本发明会筛选掉无用词再进行匹配,提高了匹配的精确度;
(5)本发明对需要匹配的单位名称进行划分,划分为,区域,属性,别名。并且不同的分类可以独立设置匹配的权重,配置更为灵活。
附图说明
图1为本发明一种基于模糊匹配算法的单位名称匹配方法的流程框图;
图2为本发明一种基于模糊匹配算法的单位名称查找方法的流程框图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。注意,以下的实施方式的说明只是实质上的例示,本发明并不意在对其适用物或其用途进行限定,且本发明并不限定于以下的实施方式。
实施例1
本实施例1提供一种基于模糊匹配算法的单位名称匹配方法,该方法实现了一对一的模糊匹配,该方法包括如下步骤:
S1、获取待匹配的两个单位名称,分别记作A和B,判定是否互相包含或者完全匹配,若是则直接输出模糊匹配分值为100,否则执行步骤S2。
S2、对两个单位名称分别进行预处理,包括标准化处理和过滤处理,其中,标准化处理包括:基于简称词库将单位名称中的简称词替换为标准词;过滤处理包括:删除单位名称中无意义的字符,如:“!\%\$\#\&\*\'\《\》\:\:\+\,\。\,\”等无意义的字符,基于无效词库删除单位名称中的无效词。
S3、对两个单位名称分别进行自定义分词处理获取相应的自定义分词,自定义分词包括三类,分别为属性词、区域词和别名词,区域词表征单位名称中所表示的区域,属性词表征单位所代表的行业类型,如属于证券公司,电力公司等,除属性词、区域词以外其他的词则为别名词。其中区域词在分词前首先要恢复区域简称,补齐“省”,“市”字样,再做区域词提取,最终提取出[省,市,县]的区域分词集。
S4、基于自定义分词结果判定能否直接进行模糊匹配计算,若是则执行步骤S6,否则执行步骤S5,具体地,此步骤判定能够直接进行模糊匹配计算的条件包括其中任意一个:两个单位名称的分词结果中均包含区域词,且区域词不相同;其中一个单位名称的分词结果中包含别名词,另一个单位名称的分词结果中不包含别名词。
S5、对两个单位名称进行模糊匹配直接判定,若满足模糊匹配直接判定条件,则直接输出模糊匹配分值为100,否则执行步骤S6,此步骤S5具体为:
S51、若两个单位名称的分词结果中均包含别名词,且别名词不相同,则执行步骤S52,否则执行步骤S53;
S52、ES分词判定:利用ES词库自带的IK分词方法对两个单位名称分别进行ES分词得到两个分词结合,将较短的分词集合记作Aset,较长的分词集合记作Bset,若Aset内的所有分词都包含在Bset中,则直接输出模糊匹配分值为100,否则对两个分词集合中的重复分词进行计数记作Cnt,同时记Aset中的分词总数为Cnaset,若Cnaset≥esLen且Cnt/Cnaset≥esPct,则直接输出模糊匹配分值为100,否则执行步骤S53,其中,esLen、esPct为设置阈值;
S53、公共词判定:将字符数较少的单位名称记作A,字符数较多的单位名称记作B,将A中每个字符依次遍历到B中,取得一个最长的匹配到的字符串集合,称作公共词C,若公共词与其中一个单位名称完全匹配且公共词长度超过3位,则直接输出模糊匹配分值为100,否则:将公共词C与单位名称B重新进行自定义分词,若B和C的分词结果中属性词相同,并且别名词为空则直接输出模糊匹配分值为100,否则执行步骤S54;
S54、子集合判定:对步骤S2预处理后的单位名称进行子集判定,若两者互相包含,则直接输出模糊匹配分值为100,否则执行步骤S55;
S55、自定义分词判定:若两个单位名称分词结果中两个区域词集合非空并且相等并且两个别名词集合非空并且相等,则直接输出模糊匹配分值为100,否则执行步骤S6。
S6、基于自定义分词结果计算两个单位名称中各类自定义分词的模糊匹配分值,进而将各类自定义分词的模糊匹配分值进行加权处理获取两个单位名称的模糊匹配分值,模糊匹配分值的大小表征两个单位名称的匹配程度,模糊匹配分值越大,两个单位名称的匹配程度越高,反之,模糊匹配分值越小,两个单位名称的匹配程度越低。
步骤S6中各类自定义分词的模糊匹配分值通过如下方式获得:
对于i类别的自定义分词,将两个公司名称对应的该类别的自定义分词的集合通过最长公共子序列长度计算方法,计算得到i类别自定义分词的最长公共子序列长度maxSubSeq(A,B)
其中,|A|
两个单位名称的模糊匹配分值通过下式获得:
其中,mathScore表示两个单位名称的模糊匹配分值,
根据业务场景和个人权重比重,初始化区域词,属性词,别名词的权重,本实施例中权重设置为:区域词权重=0.3,属性词权重=0.15,别名词权重=0.55(此处可按个人情况进行调整初始权重);之后根据A和B分词得到的分词集合,分别调整初始化权重,比如,A和B获取到的没有别名分词,那么把别名权重的0.55初始值分别赋予区域和属性权重,区域权重修改为0.3+0.55/2=0.575,属性权重修改为0.15+0.55/2=0.425。
本实施例中以“华泰联合证券有限责任公司广州体育东路证券”和“华泰期货有限公司”为例来具体说明:
分别对两个公司名称进行分词,自定义分词结果分别为:
“华泰联合证券有限责任公司广州体育东路证券”的自定义分词结果为:([广东省,广州市],[体育,证券],[华泰联合东路]),其中,[广东省,广州市]为区域词集合,[体育,证券]为属性词集合,[华泰联合东路]为别名词集合;
“华泰期货有限公司”的自定义分词结果为:([],[期货],[华泰]),其中,区域词集合为空,[期货]为属性词集合,[华泰]为别名词集合;
提取区域后得到:
([广东省],[体育,证券],[华泰联合东路])
([],[期货],[华泰]);
经过步骤S4判定不能直接进行模糊匹配计算,进入步骤S5依次进行公共词判定、子集合判定、自定义分词判定,均无法直接输出模糊匹配分值,进而进入步骤S6进行模糊匹配分值计算,得到:
由于“华泰期货有限公司”中区域词集合为空,因此,两者区域词的模糊匹配得分:0;
[华泰联合东路],[华泰],别名词的模糊匹配分值得分:0.6666665;
[体育证券],[期货],属性词的模糊匹配分值得分:0;
权重值:区域词权重=0.3,别名词权重=0.55,属性词权重=0.15;
两个单位名称的模糊匹配分值=round(0.55*0.6666665*100,2)=37。
实施例2
如图2所示,本实施例一种基于模糊匹配算法的单位名称查找方法,该方法包括:
获取待查找的单位名称,通过ES模糊匹配确定单位名称词库中匹配度最高的待匹配名称;
将待查找的单位名称与待匹配名称采用权利要求1~7任意一项所述的基于模糊匹配算法的单位名称匹配方法进行匹配确定单位名称词库中待匹配名称与待查找的单位名称的模糊匹配分值。
此实施例中,基于模糊匹配算法的单位名称匹配方法与实施例1完全一致,在该实施例中不再赘述。
以下进行具体实例说明:
待查找的单位名称:江西省广电总局;
单位名称词库事先设置名称字段类型为keyword(精确查询),通过ES关键词精确查询匹配后获取到匹配分数最高的一个名称,再进行一对一匹配相似度计算,得到如下匹配到的单位名称和相似度分数:
江西省广播电视局(es匹配得分:18.56986),黑龙江省广播电视局山东省广播电视局(es匹配得分:14.986288),江西省总工会(es匹配得分:14.648104),广东省西江流域管理局(es匹配得分:13.420963),江西省水电工程局有限公司(es匹配得分:12.696965)
筛选出最高得分的匹配名称:江西省广播电视局,对“江西省广电总局”和关键词匹配命中的“江西省广播电视局”进行一对一匹配计算相似度,得到相似度100分。
以上可见,该查找方法实现了一对多的匹配,实现待查找的单位名称在单位名称词库中的匹配查找。
实施例3
本实施例基于实施例1提供一种基于模糊匹配算法的单位名称匹配装置,该装置包括存储器和处理器,所述存储器用于存储计算机程序,处理器用于当执行计算机程序时实现实施例1中基于模糊匹配算法的单位名称匹配方法。
实施例4
本实施例基于实施例2提供一种基于模糊匹配算法的单位名称查找装置,该装置包括存储器和处理器,所述存储器用于存储计算机程序,处理器用于当执行计算机程序时实现实施例2中基于模糊匹配算法的单位名称查找方法。
本发明通过自定义模糊匹配技术,提高了银行优质客群单位匹配的精确度。而且适用于输入单个单位名称匹配,以及输入两个单位名称互相匹配的业务场景。使模糊匹配场景更为灵活,模糊匹配结果更为精确。而且提供了区域,属性,别名的自定义分词技术,对每个种类的分词提供分值和权重,权重可以自定义调整,增加了业务主观能动性。
上述实施方式仅为例举,不表示对本发明范围的限定。这些实施方式还能以其它各种方式来实施,且能在不脱离本发明技术思想的范围内作各种省略、置换、变更。
- 一种基于模糊匹配算法的单位名称匹配、查找方法及装置
- 一种基于模糊匹配算法的印刷品仿制设计方法和系统