应用于零售信贷业务中筛选最优征信数据产品的方法及系统
文献发布时间:2023-06-19 13:29:16
技术领域
本发明属于零售信贷金融技术领域,具体涉及一种应用于零售信贷业务中筛选最优征信数据产品的方法及系统。
背景技术
个人贷款又称零售信贷业务,在零售信贷业务中,当客户申请贷款时,银行等金融机构通常需要查询外部征信数据以辅助决策。因零售信贷业务具有笔数多、单笔金额小、数据丰富的特征,这决定了需要对其进行智能化、概率化的管理模式。
金融科技的核心就是和大数据技术有效结合,银行等金融机构通过有效利用大数据,在客户信用评级方面能很大程度提高效率和风控能力。目前,数据来源分内部征信数据和外部征信数据,外部征信数据多数依赖第三方数据服务公司,从数据服务公司采购超过一种数据产品。
由于使用外部征信数据需要花费大量成本,因此如何评估和选择最优的数据产品,是银行等金融机构有待解决的问题。
发明内容
本发明的目的是要解决上述的技术问题,提供一种应用于零售信贷业务中筛选最优征信数据产品的方法及系统。
为了解决上述问题,本发明按以下技术方案予以实现的:
第一方面,本发明提供了一种应用于零售信贷业务中筛选最优征信数据产品的方法,所述方法包括以下步骤:
获取至少一数据产品;
计算所有数据产品的缺失率:当数据产品的缺失率高于预设缺失率阈值,将该数据产品转人工判断;当数据产品的缺失率低于预设缺失率阈值,进入下一步骤;
判断所述数据产品是否纯评分产品:
当判断所述数据产品为纯评分产品,计算所述数据产品的评分的KS值,基于KS值判断所述数据产品是否建议使用;
当判断所述数据产品为非纯评分产品,检测数据产品是否含有自有评分,将所述数据产品的非评分变量输入机器学习模型中;
若所述数据产品不包含自有评分,且机器学习模型基于非评分变量可输出机器评分,计算所述机器评分的KS值,基于KS值判断所述数据产品是否建议使用;
若所述数据产品不包含自有评分,且机器学习模型基于非评分变量无法输出机器评分,计算所述数据产品的IV值,基于IV值判断所述数据产品是否建议使用。
结合第一方面,本发明还提供了第一方面的第1种优选实施方式,具体的,当判断所述数据产品为纯评分产品,计算所述数据产品的评分的KS值,具体包括以下步骤:
当数据产品包括多个评分时,计算各个评分的KS值;
以KS值最大的评分作为该数据产品的代表评分,以该代表评分的KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。
结合第一方面,本发明还提供了第一方面的第2种优选实施方式,具体的,当判断所述数据产品为非纯评分产品,检测数据产品是否含有自有评分,将所述数据产品的非评分变量输入机器学习模型中,还具体包括:
若所述数据产品包含自有评分,且机器学习模型基于非评分变量可输出机器评分时,分别计算自有评分和机器评分的KS值;将机器学习模型输出评分的KS值与自有评分的KS值进行比对,将KS值最大者作为该数据产品的代表评分,取该KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用;
若所述数据产品包含自有评分,且机器学习模型基于非评分变量无法输出评分时,计算自有评分的KS值;若自有评分有多个时,则取多个自有评分中的最大KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。
结合第一方面,本发明还提供了第一方面的第3种优选实施方式,具体的,所述方法还包括:
获取所有基于KS值和KS代表值判断建议使用的数据产品;
计算多个数据产品的代表评分之间的相关系数绝对值;
若所述相关系数绝对值大于预设系数阈值,则建议使用多个数据产品中KS值最高的数据产品;
若所述相关系数绝对值小于预设系数阈值,则多个数据产品均建议使用。
结合第一方面,本发明还提供了第一方面的第4种优选实施方式,具体的,基于KS值判断所述数据产品是否建议使用,具体包括以下步骤:
判断所述KS值是否大于预设KS阈值;
当所述KS值小于预设KS阈值,不建议使用该数据产品;
当所述KS值大于预设KS阈值,对该数据产品进行相关性分析;
若所述数据产品通过相关性分析,则建议使用该数据产品;若所述数据产品不通过相关性分析,则不建议使用该数据产品。
结合第一方面,本发明还提供了第一方面的第5种优选实施方式,具体的,计算所述数据产品的IV值,基于IV值判断所述数据产品是否建议使用,具体包括以下步骤:
计算所述数据产品的所有变量的IV值,取所有IV值中最大的三个IV值;
计算最大的三个IV值的IV均值,将IV均值作为该数据产品的IV代表值;
判断所述IV代表值是否大于预设IV阈值;
当所述IV代表值大于预设IV阈值,建议使用该数据产品;
当所述IV代表值小于预设IV阈值,不建议使用该数据产品。
结合第一方面,本发明还提供了第一方面的第6种优选实施方式,具体的,所述将该数据产品转人工判断的规则为,判断所述数据产品是否可用于风控拒绝规则,若是,则建议使用该数据产品;若否,则不建议使用该数据产品。
第二方面,本发明还提供了一种应用于零售信贷业务中筛选最优征信数据产品的系统,所述系统包括:
获取模块,其用于获取至少一数据产品;
缺失率计算模块,其用于计算所有数据产品的缺失率:当数据产品的缺失率高于预设缺失率阈值,将该数据产品转人工判断;当数据产品的缺失率低于预设缺失率阈值,指令判断处理模块执行下一步骤;
判断处理模块,其用于判断所述数据产品是否纯评分产品:
当判断所述数据产品为纯评分产品,计算所述数据产品的评分的KS值,基于KS值判断所述数据产品是否建议使用;
当判断所述数据产品为非纯评分产品,检测数据产品是否含有自有评分,将所述数据产品的非评分变量输入机器学习模型中;
若所述数据产品不包含自有评分,且机器学习模型基于非评分变量可输出机器评分,计算所述机器评分的KS值,基于KS值判断所述数据产品是否建议使用;
若所述数据产品不包含自有评分,且机器学习模型基于非评分变量无法输出评分,计算所述数据产品的IV值,基于IV值判断所述数据产品是否建议使用。
结合第二方面,本发明还提供了第二方面的第1种优选实施方式,具体的,判断处理模块判断所述数据产品为纯评分产品,计算所述数据产品的评分的KS值,所述判断处理模块具体执行以下步骤:
当数据产品包括多个评分时,计算各个评分的KS值;
以KS值至最大的评分作为该数据产品的代表评分,以该代表评分的KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。
结合第二方面,本发明还提供了第二方面的第2种优选实施方式,具体的,当判断所述数据产品为非纯评分产品,检测数据产品是否含有自有评分,将所述数据产品的非评分变量输入机器学习模型中,还执行以下步骤,具体包括:
若所述数据产品包含自有评分,且机器学习模型基于非评分变量可输出机器评分时,分别计算自有评分和机器评分的KS值;将机器学习模型输出评分的KS值与自有评分的KS值进行比对,将KS值最大者作为该数据产品的代表评分,取该KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用;
若所述数据产品包含自有评分,且机器学习模型基于非评分变量无法输出评分时,计算自有评分的KS值;若自有评分有多个时,则取多个自有评分中的最大KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。
与现有技术相比,本发明的有益效果是:
本发明提供的应用于零售信贷业务中筛选最优征信数据产品的方法及系统,该方法基于缺失率、IV值、KS值对各数据产品的效能进行量化评估,结合本申请的特定评估策略以筛选出最优征信数据产品,实现在进行用户信贷风险评估时成本更低,进一步可以获得更高的信贷收益。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的说明,其中:
图1是本发明的应用于零售信贷业务中筛选最优征信数据产品的方法的流程示意图;
图2是本发明的应用于零售信贷业务中筛选最优征信数据产品的系统的组成图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
申请人研究发现,在零售信贷业务中,当客户申请贷款时,银行等金融机构通常需要查询外部征信数据以辅助决策。银行等金融机构通常会抽取一小部分样本,同时查询多家数据源的产品,以评估需要使用的最佳数据产品。考虑到目前的零售信贷业务在进行信贷风险评估时,会一次性请求使用所有的数据产品,并将数据产品返回的信息进行风险评估,这样每次请求需要花费的数据成本就是所有数据产品价格之和,会导致风险评估的成本较高,且基于数据产品结构的复杂性,给评估带来很大的难度。
为此,本发明实施例提供了应用于零售信贷业务中筛选最优征信数据产品的方法及系统,基于缺失率、IV值、KS值对各数据产品的效能进行量化评估,结合本申请的特定评估策略以筛选出最优征信数据产品,实现在进行用户信贷风险评估时成本更低,进一步可以获得更高的信贷收益。
实施例1
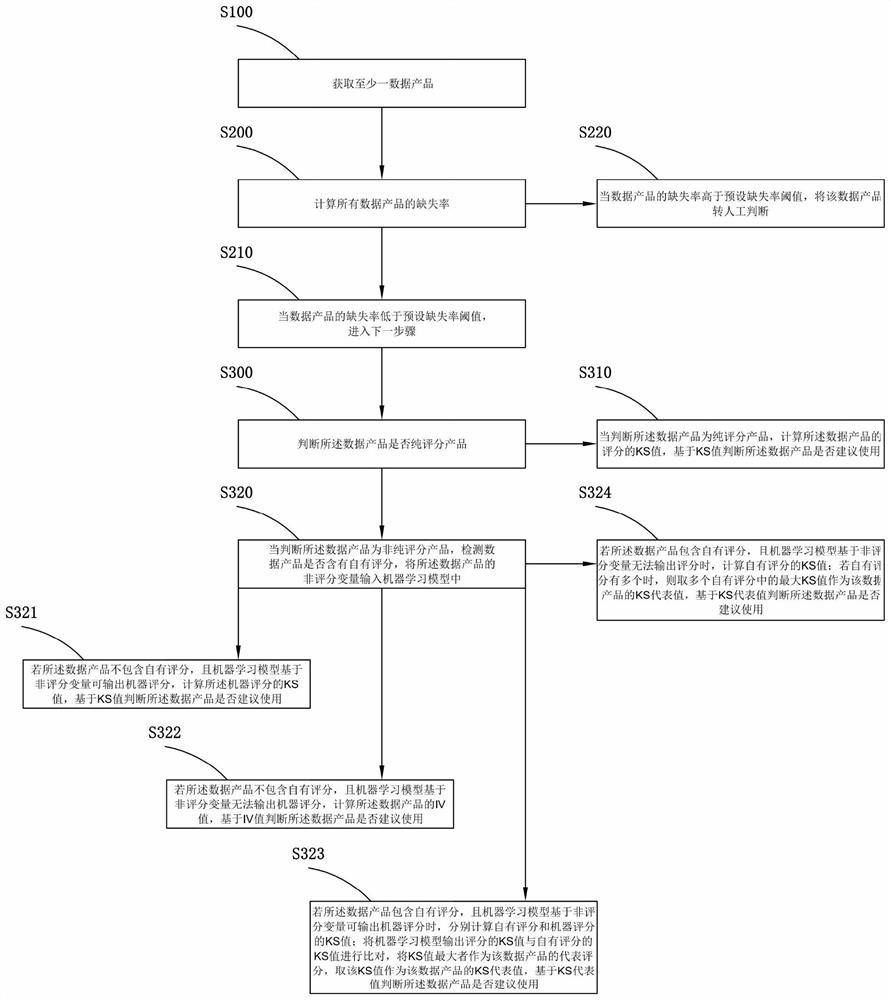
为便于理解,首先对本发明提供的应用于零售信贷业务中筛选最优征信数据产品的方法进行详细说明,参见图1所示,该方法主要包括以下步骤:
S100:获取至少一数据产品。
在本发明实施中,获取数据产品可基于用户的零售信贷业务请求触发。零售信贷业务请求也即用户向金融机构(诸如银行、信贷机构等)发起的零售信贷业务,诸如可以通过移动终端设备或者金融机构的终端设备进行操作发起。
在本发明中,零售信贷业务在金融风控预判时,往往需要通过数据服务公司采购超过一种数据产品(可以是同一数据服务公司的多个数据产品,也可以是不同数据服务公司提供的数据产品)。示例性的,本发明所述的数据产品分为纯评分数据产品和非纯评分数据产品,非纯评分数据产品分为包含自有评分的非纯评分产品和不包含自有评分的非纯评分产品。
在一种具体实施中,所述自有评分是指数据源直接输出的评分,是数据源整合了内部数据所给出的综合评分,其对坏客户的区分效果通常要远好于非评分变量。
基于此,数据产品结构的复杂性给评估带来很大的难度,且无法将自有评分和非评分变量直接对比,为此,本发明创新的给出基于缺失率、IV值、KS值的筛选评估策略。
S200:计算所有数据产品的缺失率:
S210:当数据产品的缺失率高于预设缺失率阈值,将该数据产品转人工判断。
S220:当数据产品的缺失率低于预设缺失率阈值,执行步骤S300。
在本发明步骤S200中,评估所有数据产品的查得率,以展现数据缺失的概貌。通过缺失率对数据产品作第一道筛选,对缺失率过高的数据产品,转入人工判断。
在一种具体实例中,缺失率指数据产品的整体缺失率,即,假设数据中的样本1000条,待评估的某数据产品共10个特征,如果10个特征均为缺失的样本有100条,那么缺失率为100/1000=10%。某数据产品缺失率=该数据产品所有变量或者评分均缺失的样本数/总样本数。
在一种具体实施中,所述将该数据产品转人工判断的规则为,判断所述数据产品是否可用于风控拒绝规则,若是,则建议使用该数据产品;若否,则不建议使用该数据产品。
本申请对于缺失率过高的数据产品,由于不能覆盖大部分样本,难以发掘该数据产品变量与坏客户之间的关系,因此通常可以不考虑使用该产品。但在此之前,需要了解该数据产品的适用场景及其本身的特性。
在一种业务场景中,如果样本是如收入这样的变量,只有缺失率低才有使用意义,如果缺失率过高,则不建议使用该产品。如果是黑名单类数据产品(如欺诈黑名单),可能变量取值绝大部分都是空缺,只有极少数是有命中。但只要该变量有命中,那么该客户就是高风险客户,这种数据产品则可考虑使用。因此对于缺失率过高的数据产品,需要人工去考察该数据产品的适用场景后再建议是否使用该产品。
S300:判断所述数据产品是否纯评分产品:
S310:当判断所述数据产品为纯评分产品,计算所述数据产品的评分的KS值,基于KS值判断所述数据产品是否建议使用。
S320:当判断所述数据产品为非纯评分产品,检测数据产品是否含有自有评分,将所述数据产品的非评分变量输入机器学习模型中:
S321:若所述数据产品不包含自有评分,且机器学习模型基于非评分变量可输出机器评分,计算所述机器评分的KS值,基于KS值判断所述数据产品是否建议使用。
S322:若所述数据产品不包含自有评分,且机器学习模型基于非评分变量无法输出机器评分,计算所述数据产品的IV值,基于IV值判断所述数据产品是否建议使用。
S323:若所述数据产品包含自有评分,且机器学习模型基于非评分变量可输出机器评分时,分别计算自有评分和机器评分的KS值;将机器学习模型输出评分的KS值与自有评分的KS值进行比对,将KS值最大者作为该数据产品的代表评分,取该KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。
S324:若所述数据产品包含自有评分,且机器学习模型基于非评分变量无法输出评分时,计算自有评分的KS值;若自有评分有多个时,则取多个自有评分中的最大KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。
在步骤S323-S324中,自有评分可以直接计算KS值,非评分变量则需要通过机器学习模型综合成一个机器评分再计算KS值,从而对比自有评分的KS值和机器学习模型KS值,取他们最高者作为该数据产品的KS代表值。
申请人表示,在步骤S310-S324中,对评分进行效果对比使用KS指标,对单变量进行效果对比使用IV指标。但是,单变量的IV值不可与评分的KS横向对比。为此,本发明的策略优尽可能将所有数据产品都计算其KS值来进行横向对比。
另一方面,也有部分不包含自有评分的非纯评分数据产品,由于其缺失率过大、变量数较少、变量之间相似性高等原因无法综合成一个新的评分,无法通过KS值来和其他数据产品横向对比。为此,本发明通过计算该数据产品各个变量的IV值来补充考察其区分效果,或者人工检查该数据产品,以确认其是否可作为拒绝规则而应用于风控策略当中。
同时,步骤S323-S324,针对含有自有评分的非纯评分数据产品,也提供了量化其KS值的技术手段。
需要说明的是,本发明所述机器学习模型为有监督学习模型,入模候选变量为数据产品包含的字段,目标变量为银行等金融机构测试样本中设定的字段,比如是否不良客户。较常用的算法为Xgboost等。这是本领域技术人员根据本申请的记载可实现的,在此不过多说明。
通过机器学习模型的引入,如果数据产品是非纯评分数据产品,那么它给出的字段中,有两种情况:
1)有自有评分和非评分变量两类字段。比如某数据产品包含的字段如下:①置信分、②近3月申请次数、③近6月贷款金额、④近1月夜间申请次数…。其中,字段①是自有评分,是数据源已经综合了他们内部数据开发的评分,效果通常较好。②-④则是非评分变量,这些变量单个效果可能很差,但如果将他们综合成一个评分,则效果可能会很好,因此需要将他们开发模型并计算KS,对比两者取最高。
2)只有非评分变量,无自有评分,此时则对所有非评分变量开发机器学习模型,计算KS,以作为该产品的KS代表值。
实施例2
本实施例2所述的应用于零售信贷业务中筛选最优征信数据产品的方法,其方法步骤及原理与实施例1的相同,本实施例2提供了一种优选的实施方式。
在一种具体实施中,步骤S310、S321-S324等其他步骤中,基于KS值/KS代表值判断所述数据产品是否建议使用,具体包括以下步骤:
S300-1:判断所述KS值/KS代表值是否大于预设KS阈值。
在一种实例性中,通常认为,KS值<0.2时,评分预测能力较差,KS取值0.2~0.3时评分可用,KS>0.3时评分预测较好。为此,在一种优选实施中,取0.2为预设KS阈值。
S300-2:当所述KS值/KS代表值小于预设KS阈值,不建议使用该数据产品。
S300-3:当所述KS值/KS代表值大于预设KS阈值,对该数据产品进行相关性分析:
S300-3.1:若所述数据产品通过相关性分析,则建议使用该数据产品。S300-3.2:若所述数据产品不通过相关性分析,则不建议使用该数据产品。
由于有自有评分或者可开发机器学习评分的数据产品,均有一个代表评分,可以该代表评分来计算各个数据产品两两之间的相关系数,对于相关系数过高的两个数据产品,仅保留KS较高者。对于过于相似的数据产品,只需要采购其一即可,不需要全部采购。
示例性的,本发明使用KS(Kolmogorov-Smirnov)来评估数据产品的评分进行效果比对。通过KS值,可得到以量化方式表示的评分效果比对的指标。KS值越大,代表数据产品的对坏客户的区分能力越强。
具体的,本发明提供了一种计算数据产品的KS值的步骤流程,具体包括:
1)将数据产品中的所有样本按照评分从小到大进行排序,并划分成10~20个组;
2)计算每组中的累计坏客户数(Cum Bi)和累计好客户数(Cum Gi);
3)计算每组累计坏客户数占全部坏客户数比例,以及累计好客户数占全部好客户数比例,并计算两者之间的差值;
4)取各组中差值最大者为该数据产品的KS值。KS值的计算公式如下:
在一种具体实施中,在步骤S310中,当判断所述数据产品为纯评分产品,计算所述数据产品的评分的KS值,具体包括以下步骤:
S311:当数据产品包括多个评分时,计算各个评分的KS值。
S312:以KS值最大的评分作为该数据产品的代表评分,以该代表评分的KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。在一种具体实施中,步骤S322中,计算所述数据产品的IV值,基于IV值判断所述数据产品是否建议使用,具体包括以下步骤:
S322-1:计算所述数据产品的所有变量的IV值,取所有IV值中最大的三个IV值;
S322-2:计算最大的三个IV值的IV均值,将IV均值作为该数据产品的IV代表值;
S322-3:判断所述IV代表值是否大于预设IV阈值;
S322-3.1:当所述IV代表值大于预设IV阈值,建议使用该数据产品;
S322-3.2:当所述IV代表值小于预设IV阈值,不建议使用该数据产品。
示例性的,在评估中,衡量变量重要性的工作是一项必要的工作。在特征工程的初期往往能衍生出数量较多的变量,但并不能保证对于模型开发都很重要。通过衡量变量重要性,能够从中挑选出相对更加重要的变量,为后续分析提供降维作用。通过计算IV值来衡量变量重要性。IV的全称是Information Value,中文意思是信息价值,或者信息量。
本发明对于无自有评分又无法开发机器学习模型进行评分的数据产品,就不能计算其KS值,因为该数据产品没有KS代表值与其他数据产品横向对比。此时,通过从IV值的角度来考察数据的效能,方法是:对其的每一个变量计算IV值,并计算top3变量的IV均值,如果IV均值较高,IV值越大,代表数据产品的效能越高,则建议使用。
IV值的计算,是本领域的技术人员依据本申请的记载可实现的。
在一种具体实例中,预设IV阈值优选为0.02。
实施例3
本实施例3所述的应用于零售信贷业务中筛选最优征信数据产品的方法,其方法步骤及原理与实施例1的相同,本实施例3提供了一种优选的实施方式,所述方法还包括:
S400:获取所有基于KS值判断建议使用的数据产品;
S500:计算多个数据产品的代表评分之间的相关系数绝对值:
S510:若所述相关系数绝对值大于预设系数阈值,则建议使用多个数据产品中KS值最高的数据产品;
S520:若所述相关系数绝对值小于预设系数阈值,则多个数据产品均建议使用。
需要说明的是,由于有自有评分或者可开发机器学习评分的数据产品,均有一个代表评分,可以该代表评分来计算各个数据产品两两之间的相关系数,对于相关系数过高的两个数据产品,仅保留KS较高者。从而缩小数据产品量。
在一种具体实施中,由于评分均为数值型的,因此可以用皮尔逊相关系数来衡量各评分之间的相关关系,度量两个数据产品之间的相关(线性相关),其值介于-1与1之间。
在一种优选实施中,所述预设系数阈值可以为0.4。
实施例3
本实施例3提供了应用于零售信贷业务中筛选最优征信数据产品的系统,所述系统用于执行并实现上述实施例1-2所述的应用于零售信贷业务中筛选最优征信数据产品的方法,所述系统包括:
获取模块,其用于获取至少一数据产品;
缺失率计算模块,其用于计算所有数据产品的缺失率:当数据产品的缺失率高于预设缺失率阈值,将该数据产品转人工判断;当数据产品的缺失率低于预设缺失率阈值,指令判断处理模块执行下一步骤;
判断处理模块,其用于判断所述数据产品是否纯评分产品:
当判断所述数据产品为纯评分产品,计算所述数据产品的评分的KS值,基于KS值判断所述数据产品是否建议使用;
当判断所述数据产品为非纯评分产品,检测数据产品是否含有自有评分,将所述数据产品的非评分变量输入机器学习模型中;
若所述数据产品不包含自有评分,且机器学习模型基于非评分变量可输出评分,计算所述评分的KS值,基于KS值判断所述数据产品是否建议使用;
若所述数据产品不包含自有评分,且机器学习模型基于非评分变量无法输出评分,计算所述数据产品的IV值,基于IV值判断所述数据产品是否建议使用;
若所述数据产品包含自有评分,且机器学习模型基于非评分变量可输出机器评分时,分别计算自有评分和机器评分的KS值;将机器学习模型输出评分的KS值与自有评分的KS值进行比对,将KS值最大者作为该数据产品的代表评分,取该KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用;
若所述数据产品包含自有评分,且机器学习模型基于非评分变量无法输出评分时,计算自有评分的KS值;若自有评分有多个时,则取多个自有评分中的最大KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。
在一种实施中,判断处理模块判断所述数据产品为纯评分产品,计算所述数据产品的评分的KS值,所述判断处理模块具体执行以下步骤:
当数据产品包括多个评分时,计算各个评分的KS值;
以KS值至最大的评分作为该数据产品的代表评分,以该代表评分的KS值作为该数据产品的KS代表值,基于KS代表值判断所述数据产品是否建议使用。
在一种实施中,所述系统还包括筛选模块,请用于执行如下步骤:
获取所有基于KS值判断建议使用的数据产品;
计算多个数据产品的代表评分之间的相关系数绝对值;
若所述相关系数绝对值大于预设系数阈值,则建议使用多个数据产品中KS值最高的数据产品;
若所述相关系数绝对值小于预设系数阈值,则多个数据产品均建议使用。、
在一种实施中,所述判断处理模块基于KS值判断所述数据产品是否建议使用,具体执行如下步骤:
判断所述KS值是否大于预设KS阈值;
当所述KS值小于预设KS阈值,不建议使用该数据产品;
当所述KS值大于预设KS阈值,对该数据产品进行相关性分析;
若所述数据产品通过相关性分析,则建议使用该数据产品;若所述数据产品不通过相关性分析,则不建议使用该数据产品。
在一种实施中,所述判断处理模块计算所述数据产品的IV值,基于IV值判断所述数据产品是否建议使用,具体执行如下步骤:
计算所述数据产品的所有变量的IV值,取所有IV值中最大的三个IV值;
计算最大的三个IV值的IV均值,将IV均值作为该数据产品的IV代表值;
判断所述IV代表值是否大于预设IV阈值;
当所述IV代表值大于预设IV阈值,建议使用该数据产品;
当所述IV代表值小于预设IV阈值,不建议使用该数据产品。
本实施例所述应用于零售信贷业务中筛选最优征信数据产品的方法及系统的其它结构参见现有技术。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,故凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 应用于零售信贷业务中筛选最优征信数据产品的方法及系统
- 监测服饰产品在零售市场中的组合搭配的方法