一种基于Stacking集成学习的碳足迹预测方法及终端
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及碳足迹预测领域,尤其涉及一种基于Stacking集成学习的碳足迹预测方法及终端。
背景技术
火电行业是消耗化石能源的主要行业,也是二氧化碳足迹最多的行业之一,科学预测火电行业碳足迹以及确定碳达峰时间和峰值具有重要意义。
现有技术中,通常采用二氧化碳当量计算表示碳足迹。目前,对于碳足迹预测的方法主要有两类。第一类方法是直接利用碳足迹历史数据对未来碳足迹趋势进行分析,该类方法对数据需求量少,但对数据波动的反应存在滞后现象,并且预测时无法反应未来已制定政策对数据的影响。第二类方法是考虑多因素建立碳足迹预测模型,其中机器学习方法逐渐成为热点工具。但存在单一模型学习性能弱、预测精度低的局限性。
发明内容
本发明所要解决的技术问题是:提供一种基于Stacking集成学习的碳足迹预测方法及终端,实现碳足迹预测的精度提高。
为了解决上述技术问题,本发明采用的一种技术方案为:
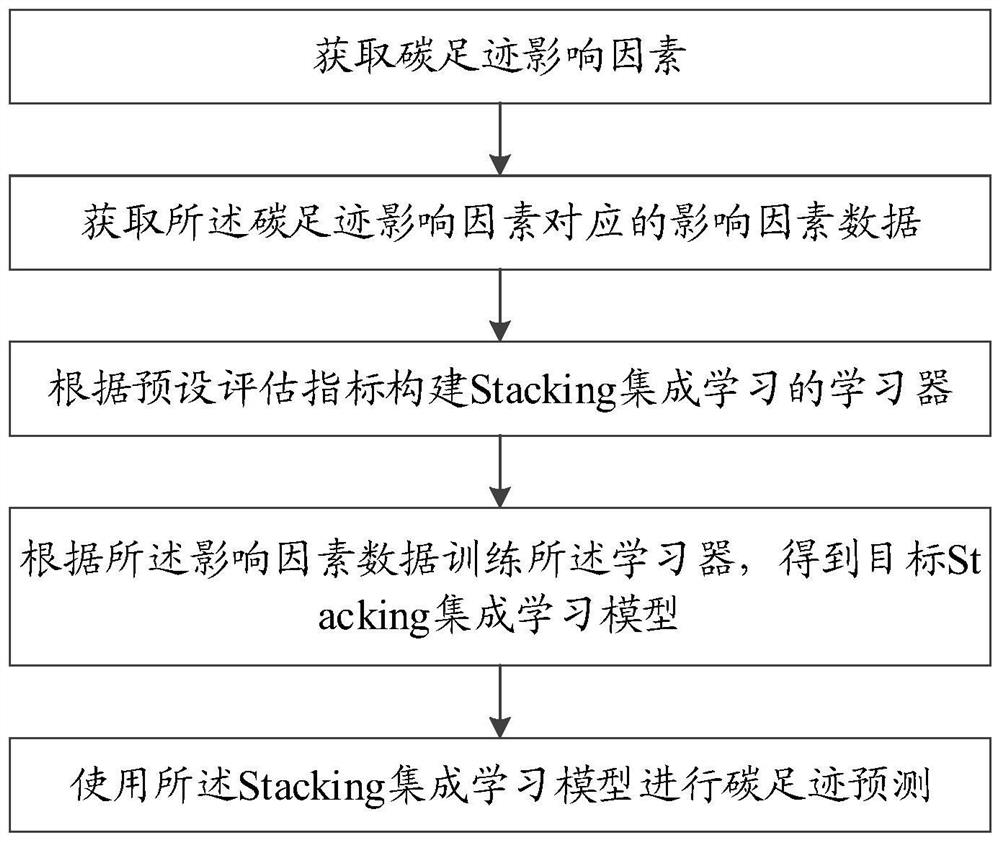
一种基于Stacking集成学习的碳足迹预测方法,包括步骤:
获取碳足迹影响因素;
获取所述碳足迹影响因素对应的影响因素数据;
根据预设评估指标构建Stacking集成学习的学习器;
根据所述影响因素数据训练所述学习器,得到目标Stacking集成学习模型;
使用所述Stacking集成学习模型进行碳足迹预测。
为了解决上述技术问题,本发明采用的另一种技术方案为:
一种基于Stacking集成学习的碳足迹预测终端,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
获取碳足迹影响因素;
获取所述碳足迹影响因素对应的影响因素数据;
根据预设评估指标构建Stacking集成学习的学习器;
根据所述影响因素数据训练所述学习器,得到目标Stacking集成学习模型;
使用所述Stacking集成学习模型进行碳足迹预测。
本发明的有益效果在于:引入能够组合不同模型并集成学习的Stacking集成学习模型,将不同模型进行融合,弥补了单一模型预测的不足,组合模型和集成学习能够有效提高预测的精度,并且在确认Stacking集成学习模型中的学习器时,通过预设评估指标进行筛选,进一步保证了最终所选择的学习器与需要预测的内容的适配性,从而提高预测的效果,并且根据重新确认的影响因素对Stacking集成学习模型进行训练,保证了模型的质量。
附图说明
图1为本发明实施例的一种基于Stacking集成学习的碳足迹预测方法的步骤流程图;
图2为本发明实施例的一种Stacking集成学习模型的结构示意图;
图3为本发明实施例的9个学习器单独预测结果评估示意图;
图4为本发明实施例的最优Stacking集成学习模型的预测结果评估示意图;
图5为本发明实施例的基于最优Stacking集成学习模型的不同情景下的预测结果示意图;
图6为本发明实施例的一种基于Stacking集成学习的碳足迹预测装置的结构图;
图7为本发明实施例的一种基于Stacking集成学习的碳足迹预测装置的另一结构图;
图8为本发明实施例的一种基于Stacking集成学习的碳足迹预测装置的另一结构图;
图9为本发明实施例的一种基于Stacking集成学习的碳足迹预测终端的结构示意图;
具体实施方式
为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
请参照图1,一种基于Stacking集成学习的碳足迹预测方法,包括步骤:
获取碳足迹影响因素;
获取所述碳足迹影响因素对应的影响因素数据;
根据预设评估指标构建Stacking集成学习的学习器;
根据所述影响因素数据训练所述学习器,得到目标Stacking集成学习模型;
使用所述Stacking集成学习模型进行碳足迹预测。
从上述描述可知,本发明的有益效果在于:引入能够组合不同模型并集成学习的Stacking集成学习模型,将不同模型进行融合,弥补了单一模型预测的不足,组合模型和集成学习能够有效提高预测的精度,并且在确认Stacking集成学习模型中的学习器时,通过预设评估指标进行筛选,进一步保证了最终所选择的学习器与需要预测的内容的适配性,从而提高预测的效果,并且根据重新确认的影响因素对Stacking集成学习模型进行训练,保证了模型的质量。
进一步地,所述获取碳足迹影响因素包括:
设置Kaya恒等公式:
其中,C表示目标行业的碳足迹总量;M
由上述描述可知,通过改进现有的Kaya恒等公式,使得更加符合电力行业现有的发电能源结构,从而提高后续预测的精度。
进一步地,在所述Kaya恒等公式中:
其中,C
由上述描述可知,将碳足迹总量分类为煤、石油和天然气分别对应的总量,分别进行计算,进一步提高了影响因素的全面性,从而提高了预测结果的精度。
进一步地,根据预设评估指标构建Stacking集成学习的学习器包括:
获取预设评估指标,并获取备选学习器;
将所述影响因素数据分别通过每一所述备选学习器,得到预测结果;
根据所述预测结果以及所述预设评估指标计算每一所述备选学习器对应的评估值,并根据所述评估值确认目标学习器。
由上述描述可知,Stacking集成学习模型中包括多个层级,且每个层级可以采用不同的基础模型进行构建,实现模型之间的融合,达到取长补短的效果,然而若认为确定哪些模型能够参与构建Stacking集成学习模型,难免会被人为主观因素影响,此处引入客观的评估指标,根据评估指标计算出的评估值确认能够参与构建Stacking集成学习模型的目标学习器,客观上保证了所构建的模型的质量,从而保证了模型预测结果的精度。
进一步地,所述学习器包括初级学习器以及元学习器;
则所述根据预设评估指标构建Stacking集成学习的学习器包括:
确认目标初级学习器后,获取备选元学习器;
将所述影响因素数据分别通过带有不同所述备选元学习器的Stacking集成学习模型,得到预测结果,每一所述Stacking集成学习模型均包括目标初级学习器;
根据所述预测结果以及所述预设评估指标计算每一所述备选元学习器对应的评估值,并根据所述评估值确认目标元学习器。
由上述描述可知,Stacking集成学习模型包括多层学习器,在确定了目标初级学习器之后,在计算评估值的过程中,使用带有目标初级学习器的Stacking 集成学习模型,能够在已经确认的最优目标初级学习器的基础上进一步确定出元学习器,即在确认学习器的过程中,将不同层级学习器之间的关联也进行考虑,进一步提高了Stacking集成学习模型的质量。
进一步地,所述评估指标包括决定系数以及平均绝对百分比误差。
由上述描述可知,决定系数和平均绝对百分比误差都能够评估预测值和实际值之间的差距,从而实现对模型预测效果的评估,能够知道不同模型预测准确性之间的差距。
进一步地,所述根据所述预测结果以及所述预设评估指标计算每一所述备选学习器对应的评估值,并根据所述评估值确认目标学习器包括:
式中:y
由上述描述可知,将不同模型预测的精度的不同计算出来成为数值进行对比,能够客观地对不同模型的预测精度进行评价,从而选择出合适的目标学习器,保证最终形成的Stacking集成学习模型的质量。
进一步地,使用所述Stacking集成学习模型进行碳足迹预测包括:
接收情景设置信息;
根据所述情景设置信息调整模型参数;
使用调整模型参数后的Stacking集成学习模型进行碳足迹预测。
由上述描述可知,在实际进行预测的过程中,因为未来的情景和当前的情景相比,会因为各种不同的发展趋势有不同的变化,故在进行对未来趋势的预测的过程中,引入情景设置,根据接收到的情景设置信息进行模型参数的调整,使得对未来的预测数据更加贴合实际情况。
进一步地,所述情景设置信息包括基准发展情景设置信息、产业优化情景设置信息、技术突破情景设置信息以及低碳发展情景设置信息。
由上述描述可知,根据对将来不同发展趋势的预测设置不同的情景,在对未来进行预测时能够直接调用这些情景得到输入值,简化了用户预测时的操作成本。
请参照图,一种基于Stacking集成学习的碳足迹预测终端,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的一种基于Stacking集成学习的碳足迹预测方法中的各个步骤。
本发明上述一种基于Stacking集成学习的碳足迹预测方法能够适用于需要对将来的碳足迹进行预测的场景中,特别适用于火电行业碳足迹的预测,以下通过具体实施方式进行说明。
请参照图1,本发明的实施例一为:
一种基于Stacking集成学习的碳足迹预测方法,具体包括:
S1、获取目标行业碳足迹影响因素,包括:
S11、设置Kaya恒等公式:
其中,C表示目标行业碳足迹总量,即目标行业的二氧化碳排放总量;M
其中,C
表1
S2、获取所述碳足迹影响因素对应的影响因素数据;
在一种可选的实施方式中,参照表1,在影响因素数据能够支撑的情况下,优先获取城镇化水平L作为人口数量进行计算,城镇对于碳足迹的影响更大,能够更加精准反应碳足迹水平;
在一种可选的实施方式中,对影响因素数据进行无量纲归一化处理,排除不同类型影响因素数据的不同计量单位对预测结果的影响,消除不同影响因素之间存在量纲不同,不具可比性的问题,例如,可以采用均值归一方式:
其中,
S3、根据预设评估指标构建Stacking集成学习的学习器,Stacking集成学习模型可以构建多层网络模型,每一层由一个或多个不同的学习器构成,其思想在于组合多个弱监督模型以期得到一个强监督模型,充分发挥不同学习器优势提高整个模型的预测准确率;两层结构的Stacking既能强化学习效果又不至于造成模型复杂化;因此,本实施例中构建两层Stacking集成学习预测模型,其结构如图2所示,模型分为两个层级,第一层中的学习器称为初级学习器,第二层中的学习器称为元学习器;包括:
S31、获取预设评估指标,并获取备选学习器;
在一种可选的实施方式中,从机器学习中的符号主义、连接主义和统计学习中常见的KNN(K-NearestNeighbor,邻近算法)、LR(Logistic Regression,回归模型)、DT(Decision Tree,决策树算法)、BP(backpropogation,反向传播算法)、SVM(supportvector machines,支持向量机),以及基于Bagging(套袋法)并行集成和Boosting(自助法)串行集成为代表的RF(Random Forest,随机森林)、AdaBoost(Adaptive Boosting,逐步增强法)、GBDT(Gradient Boosting Decision Tree,梯度增强决策树)和XGBoost(ExtremeGradient Boosting,极端梯度提升)作为备选学习器;
在一种可选的实施方式中,预设评估指标包括决定系数以及平均绝对百分比误差;
S32、将所述影响因素数据分别通过每一所述备选学习器,得到预测结果;
例如,将表1中的6个碳足迹影响因素所对应的已知的影响因素数据作为特征变量,将已知的碳足迹量作为目标变量形成模型训练的数据集;已知的影响因素数据和碳足迹量即为历史数据中的影响因素数据和碳足迹量;将数据集按照7:3的比例划分为训练集和测试集,并采用K折交叉验证以及网格参数寻优的方法,分别建立上述9个学习器的碳足迹预测模型;
S33、根据所述预测结果以及所述预设评估指标计算每一所述备选学习器对应的评估值,并根据所述评估值确认目标学习器;
计算决定系数评估值:
计算平均绝对百分比误差评估值:
其中,y
此处,用于训练模型的数据集可直接从影响因素数据中获取;
在一种可选的实施方式中,根据评估值确认预设数量的目标学习器构建Stacking集成学习模型;
在一种可选的实施方式中,所述学习器包括初级学习器以及元学习器;
则执行步骤S31-S33构建初级学习器后,还包括:
重复执行S31-S33构建元学习器,并将其中的步骤S32替换为:将所述影响因素数据分别通过带有不同所述备选元学习器的Stacking集成学习模型,得到预测结果,每一所述Stacking集成学习模型均包括目标初级学习器;
例如,在模型根据数据集训练完毕后,得到模型的预测值,使用决策系数 (R
在Stacking集成学习的初级学习层确定的前提下,分别将最初的9个学习器作为元学习器进行预测模型的训练,同样以R
表2
由表2可知,当选取GBDT为元学习器时,R
S4、根据所述影响因素数据训练所述学习器,得到目标Stacking集成学习模型;
S5、使用所述Stacking集成学习模型进行碳足迹预测;
在一种可选的实施方式中,包括:。
S51、接收情景设置信息,包括基准发展情景设置信息、产业优化情景设置信息、技术突破情景设置信息以及低碳发展情景设置信息;
S52、根据所述情景设置信息调整模型参数;
在一种可选的实施方式中,为每一情景匹配好对应的模型参数,如下表3- 表4:
表3
表4
其中,请参照表4,其中的速率为相较于前一年数据的变化速率,因预测未来是基于现在,在步骤S2中已经获取到影响因素数据即历史上收集到的相应数据,例如历史数据到2020年,则对应表4,在基准发展情景下预测时,常驻人口在2021-2025的预测数据中,以0.60%的速率增长,经济产出以6.3%的速率增长,产业结构以-1.5%的速率减小,能源消费强度以-0.73%的速率减小,能源消费结构以-0.04%的速率减小;其他年份和情景下的数据变化在表4的基础上方式相同,在此不再赘述;
S53、使用调整模型参数后的Stacking集成学习模型进行碳足迹预测,碳足迹预测包括碳达峰时间和峰值;
4种低碳发展模式的未来碳达峰情景预测分析是基于已经建立的 Stacking-GBDT集成学习的碳足迹预测模型,可以对2021-2035年碳足迹进行预测;4种不同情景下的碳足迹预测结果示意图如图5所示。
由图5示意图可以分析出以下结论:
基准发展情景:该情景的设定是不考虑其他因素突变的前提下,大致按照政府相关文件的规划发展;由图5示意图所知,在此发展情景下,火电行业无法在2030年前达到碳达峰,碳达峰预期在2032年实现,最高碳足迹量峰值将达到298百万吨(t),之后逐年呈微弱下降趋势;因此,在此情景的前提下,仍需要采取一定的措施来控制火电企业碳足迹相关因素的发展速率;
产业优化情景:该情景的设定是通过优化产业结构、降低第二产业份额的发展模式;由图5示意图可知,在此发展情景下,火电行业能够在2029年达到碳达峰,最高碳足迹量峰值为296百万t,之后逐年呈微弱下降趋势;相比基准发展情景,碳足迹量峰值差距不大,但能够提前3年实现碳达峰;因此,可以考虑进一步依托核电、风电等优势,发展低碳无碳能源,培育储能产业、数字能源产业、先进制造业和现代服务产业,优化产业结构;
技术突破情景:该情景的设定是通过改进能源技术降低能源消耗的发展模式;由图5示意图可知,在此发展情景下,火电行业能够在2028年达到碳达峰,最高碳足迹量峰值为288百万t,之后逐年呈微弱下降趋势;相比产业优化情景,改进能源技术的方式能够更有效地降低碳足迹,也能够更早地实现碳达峰;因此,可以考虑进一步构建以新能源为主体的新型电力系统,推进低碳、无碳、负碳技术的发展;
低碳发展情景:该情景的设定是对人口、经济、产业和能源角度全方面干预控制的发展模式;由图5示意图可知,在此发展情景下,火电行业能够在2027 年达到碳达峰,最高碳足迹量峰值为278百万t,之后逐年呈微弱下降趋势;相比技术突破情景,全面干预方式能够更有效地降低碳足迹,也能够更早地促进碳达峰的实现;但同时需要考虑,全面干预方式是否会带来额外的负面效应,例如将影响到火电行业的经济效益。
请参照图6,本发明的实施例二为:
一种基于Stacking集成学习的碳足迹预测装置,能够实现上述的一种基于Stacking集成学习的碳足迹预测方法,包括影响因素确定模块601,数据处理模块602,集成学习学习器选择模块603,碳情景预测模块604。
所述的影响因素确定模块601,用于基于改进Kaya恒等式识别火电厂碳足迹的影响因素;根据需求,可以继续扩展Kaya恒等式识别的相关因素,不限于表1中的已有影响因素。
所述的数据处理模块602,用于碳足迹影响因素对应的影响因素数据输入与存储,并能够对数据进行无量纲归一化处理,方便下面预测模型的训练。
所述的集成学习学习器选择模块603,用于Stacking集成学习模型的碳足迹预测模型训练;如图7所示,集成学习学习器选择模块603包括:指标单元701、初级学习器选择单元702、元学习器选择单元703和预测结果显示单元704。
进一步的,所述的指标单元701,用于选取评判预测模型好坏的评估指标,可以只选择评估指标为R2(决定系数)、MAPE(平均绝对百分比误差)之中的一个,也可以同时选取。同时,也可以嵌入更多的其他评估指标。
进一步的,所述的初级学习器选择单元702,用于从多种学习器中选择几种学习器完成Stacking集成学习初级层的建立。初级学习器的数量可以根据需求增减。该单元提供默认的初级层供使用者参考使用。
进一步的,所述的元学习器选择单元703,用于从多种学习器中选择一种学习器完成Stacking集成学习元级层的建立。该单元提供默认的初级层供使用者参考使用。
进一步的,所述的预测结构显示单元,用于预测模型结果的输出。结果输出有两方面:一方面是指标数值的输出;另一方面是“年份—碳足迹量数值”的输出。
所述的碳情景预测模块604,用于选择不同的碳足迹发展路线下进行碳情景预测。如图8所示,该模块默认设计了四种发展模式单元,包括:基准发展情景单元801、产业优化情景单元802、技术突破情景单元803和低碳发展情景单元804;发展模式还可以根据用户需求,调整发展影响因素的速率进行更改,以满足时效性,形成了自定义单元803。
进一步的,所述的基准发展情景单元801,是根据过去火电行业发展的特点,假设当前经济技术环境不变,且政府不会出台新的减排措施,发展的主要驱动力仍然是经济生产,以此推动社会和技术的发展。
进一步的,所述的产业优化情景单元802,是在现有政策的基础上,产业结构进一步优化和现代化,进行产业结构调整,减少第二产业的发展参与度,降低传统产业比重,让高新技术产业和服务业成为主导产业。
进一步的,所述的技术突破情景单元803,在基准发展情景的基础上,通过系统设计、技术进步和结构转型,加强科技研发,促进火电行业资源循环和高效利用,调整能源消耗强度和能源消费结构变化率取值。
进一步的,所述的产业优化情景单元804,是火电行业在现有政策基础上,强化能源政策,实施一系列节能减排措施,积极调整发电端能源结构,从而实现低碳足迹。
进一步的,所述的自定义情景,是根据用户需求,重新定义各个影响因素的发展速率。
请参照图9,本发明的实施例三为:
一种基于Stacking集成学习的碳足迹预测终端900,包括处理器901、存储器902及存储在存储器902上并可在所述处理器901上运行的计算机程序,所述处理器2执行所述计算机程序时实现实施例一中的各个步骤;
具体的,一种基于Stacking集成学习的碳足迹预测终端900,可以包括以下一个或多个组件:处理组件901,存储器902,电源组件903,输入/输出(I/O) 的接口904,以及通信组件905。
进一步的,处理组件901通常控制预测装置900的整体操作,诸如与显示,数据通信,和记录操作相关联的操作。处理组件901可以包括一个或多个处理器920来执行指令,以完成上述的方法的全部或部分步骤。处理器可以是中央处理单元,还可以是其他通用处理器、数字信号处理器、专用集成电路等。
进一步的,存储器902被配置为存储各种类型的数据以支持在预测装置900 的操作。这些数据的示例包括用于在终端设备900上操作的任何应用程序或方法的指令,数据,消息,图片等。存储器902可以由任何类型的易失性或非易失性存储设备或者它们的组合实现。
进一步的,电源组件903为终端设备900的各种组件提供电力。电源组件 903可以包括电源管理系统,一个或多个电源,及其他与为预测装置900生成、管理和分配电力相关联的组件。
进一步的,I/O接口904为处理组件901和外围接口模块之间提供接口,上述外围接口模块可以是键盘,点击轮,按钮等。这些按钮可包括但不限于:主页按钮、音量按钮、启动按钮和锁定按钮。
进一步的,通信组件905被配置为便于预测装置900和其他设备之间有线或无线方式的通信。预测装置900可以接入基于通信标准的无线网络,如WiFi, 4G或5G,或它们的组合。
综上所述,本发明提供了一种基于Stacking集成学习的碳足迹预测方法及终端,引入了Stacking集成学习模型,能够集成多种机器学习模型进行预测,避免了单一模型预测偏颇,不全面的问题,并且在选择作为Stacking集成学习模型中的学习器的模型时,引入了决策系数和平均绝对百分比误差两个客观评估指标进行模型预测优劣的判断,将表现相对更加优秀的模型加入Stacking集成学习模型,进一步保证了Stacking集成学习模型的质量,同时,Stacking集成学习模型可以有多层,本发明中采用两层结构,在充分利用模型融合特性的前提下,避免了模型过于复杂,训练效率慢的问题,并且,在确定元学习器时,是在已经确定的优选的初级学习器的基础上进行,在Stacking集成学习模型的构建过程中就考虑到了不同层的模型之间的联动对模型最终预测效果的影响,进一步提高了最终Stacking集成学习模型的质量;并且,在进行预测的过程中,提供了设定的情景模式以供选择,能够根据对未来的不同趋势预测出不同的结果,增加了预测结果的全面性的同时保证了精确性,同时,用户也能够根据自身对趋势的理解进行情景参数的调整,使得最终对Stacking集成学习模型的使用更加灵活。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
- 一种基于特征提取和Stacking集成学习的软件缺陷预测方法
- 一种基于Stacking集成学习的软件缺陷预测方法