基于并行化信息共享模块的多任务谣言检测模型及方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及自然语言处理技术领域,具体涉及一种基于并行化信息共享模块的多任务谣言检测模型及方法。
背景技术
基于并行化信息共享模块的谣言检测方法使用的主要技术是深度学习(DeepLearning)以及多任务学习技术(MTL:Multi-Task Learning),其主要目的是借助源推文以及其相关推文(这里指评论或转发推文)的写作风格特征、文本内容特征以及社会背景信息,社会背景信息由推文对应的转发数、点赞数以及用户的一些相关信息构成。
为了缓解数据量不足对深度学习模型的影响,MTL模型被设计了出来,它可以帮助用户重用现有数据进行学习并降低人工标注数据的成本。因为MTL模型利用来自不同任务的数据,可以学到更健壮、更通用和更强大的多任务模型,从而更好地实现任务之间的知识共享,提高模型性能以及降低过拟合风险,所以MTL模型的表现往往要优于单任务模型。在MTL的启发下,出现了基于多任务的谣言检测方法,这些多任务谣言检测方法往往是将立场检测任务和谣言检测任务组合在一起形成一个MTL模型,因为那些被证实为谣言的信息在对其的评论中往往会比真实的信息包含更多的质疑或否定内容。
中国专利“一种基于双向传播图的多任务谣言检测方法”(申请号:202110454550.0)公开的检测方法,用于检测社交网络帖子是否为谣言以及检测评论信息的立场。该专利根据帖子内容生成文本特征矩阵、用户特征矩阵和文本统计特征矩阵,之后构建谣言的双向传播图,通过计算双向图卷积并进行根节点特征增强抽取谣言的传播特征,最后进行传播特征的平均值池化和特征整合,训练softmax分类器获取立场检测和谣言检测结果。
中国专利“融合评论的多任务联合谣言检测方法”(申请号:202110337896.2)使用自注意力机制分别获取微博正文和用户评论丰富的上下文信息,之后使用带有过滤机制的门控单元和注意力机制对用户评论进行有效筛选,最后输出层采取线性变换和softmax函数去预测用户评论相关标签和微博事件标签。
现有的多任务谣言检测方法主要包含以下缺陷:
1)组成MTL模型的两个任务均是立场检测任务和谣言检测任务。但由于两个任务使用的是不同的数据集,并且两个任务所用数据结构差异较大,因此虽然模型在训练过程中能够共享一部分信息,但能够带来的提升也并不高;
2)现有多任务谣言检测模型都是借助其他的数据集、或其他任务中对谣言检测有帮助的信息来加强谣言的特征表示,但并未能够充分挖掘谣言检测数据集本身的信息。
3)基于传播结构的多任务谣言检测方法,需要花费大量时间来提取传播结构特征,即类似于基于传统机器学习算法的谣言检测方法需要大量时间用于特征工程一样。
发明内容
本发明的目的是提出一种既能够充分利用数据信息、又能够提升检测效果的基于并行化信息共享模块的多任务谣言检测模型及方法,该方法将基于写作风格特征的谣言检测方法、基于内容的谣言检测方法、以及基于社会背景信息的谣言检测方法以基于内容的检测方法为中心,通过多任务的形式组合在一起,形成一个具有并行信息共享结构的多任务谣言检测模型;并使用Yang Z et al.在会议论文“Hierarchical Attention Networksfor Document Classification,in the 2016conference of the North Americanchapter of the association for computational linguistics:human languagetechnologies.2016.p.1480-1489”中用于文档分类的层级注意力机制(Hierarchicalattention)来注意那些对谣言检测更为重要的词汇和推文,加快了模型的收敛速度,减轻了噪声带来的影响,克服了现有多任务谣言检测方法两个任务数据结果差异较大以及未能充分利用数据本身数据的缺陷。
本发明采取的技术方案为:
基于并行化信息共享模块的多任务谣言检测模型,该模型包括:
基于文本内容和社会背景信息的多任务模块,该模块包括:
特征向量D
特征向量D
特征向量I
检测对象第i个推文的社会背景特征向量,其为D
特征向量X
基于文本内容和写作风格的多任务模块,该模块包括:
特征向量S
特征向量S
特征向量X
基于文本内容的检测时,
S1:先将源推文以及相关推文文本内容特征向量X
S3:将得到的两组共享信息和原本的内文本内容信息结合在一起,并将其输入到基于文本内容检测任务独有层中,最后经过Sentence Attention得到最终的特征向量:H
S3:经过全连接层得到分类结果。
具体的计算公式如下:
X
其中:X
h
h
其中:h
其中:h
h
其中:
H
其中:h
Y
其中:W
基于社会背景信息的检测时,
Step1:将通过Sentence Encoder得到用户描述的特征向量D
Step2:将用户描述的特征向量D
Step3:先将社会背景信息特征向量输入到文本内容和社会背景信息共享模块中,得到同时包含文本内容信息和社会背景信息的特征,然后与原本的社会背景信息特征结合,输入到该任务独有层中;
Step4:经过Sentence Attention得到社会背景特征向量H
Step5:经过一个Sigmoid层得到最终的检测结果Y
具体的计算公式如下:
D
其中:D
其中:I
h
h
H
其中:h
Y
基于写作风格特征的谣言检测时,
A1:将S
A2:将A1中提取的特征输入到文本内容和写作风格共享模块中,得到同时包含文本内容信息以及写作风格信息的中间特征;
A3:将A1得到的中间特征与经过对齐层的特征相结合,输入到写作风格独有层中,
A4:将最后一个Bi-LSTM单元的输出作为写作风格特征H
具体的计算公式如下:
h
其中:h
h
其中:h
其中:h
H
其中:h
Y
其中:W
基于文本内容的谣言检测时,
B1:通过Sentence Encoder将每一个推文的词向量矩阵编码为一个特征向量X
B2:将X
B3:将得到的中间特征与本身的文本内容特征相结合,输入到内容层中;
B4:经过一个Sentence Attention,得到同时包含三种信息的文本内容特征向量Hcontent;
B5:经过全连接层进行分类。
具体的计算公式如下:
u
其中:u
H
基于并行化信息共享模块的多任务谣言检测方法,包括以下步骤:
步骤1:定义社会背景信息特征表示So,包括用户自描述信息D、离散的社会背景信息I;
所述步骤1中:
用户自描述信息D,为用户信息描述经过分词以及词嵌入得到的词向量矩阵经过Sentence Encoder编码后得到的特征向量。
离散的社会背景信息I={user_frc,user_folc,user_stac,user_ver,user_fac,t_attc,t_rec,time_gap},其中:user_frc,user_folc,user_stac,user_ver,user_fac分别表示用户的好友数量、粉丝数量、已发推文数量、是否认证以及关注数量;time_gap表示用户账户的注册时间和该推文发表时间的时间差;t_attc,t_rec分别表示推文的点赞数、转发数。
步骤2:基于一个大型语料库训练一个Word2Vec词向量嵌入模型,然后,将每一个推文处理为{Word
步骤3:使用写作风格表示S={lenght,qu_sys,uh_sys,w
然后,得到每个推文对应的风格特征表示S
步骤4:建立基于并行化信息共享模块的多任务谣言检测模型,并对该模型进行训练。
所述步骤4中,模型训练包括以下步骤:
步骤4.1:将文本编码的向量矩阵、用户信息描述矩阵以及用户离散信息、相对应的写作风格特征输入到模型中得到Y
步骤4.2:再根据对应的真实标签以及上一步骤中得到的结果计算对应的损失函数Loss
步骤4.3:计算模型总体损失Loss
步骤4.4:根据Loss
步骤4.5:如果迭代次数少于Epoch,则回到步骤4.1。否则到下一步。
步骤4.5:得到模型参数在训练集上进行验证,得到相应的验证结果。
本发明一种基于并行化信息共享模块的多任务谣言检测模型及方法,技术效果如下:
1)本发明将基于文本内容、写作风格以及社会背景的三个基本的谣言检测任务以基于文本内容为中心的多任务方式组织在一起;其次,在这基础之上通过两个信息共享模块构成一个基于并行化共享模块的多任务谣言检测方法,优点是:相较于传统的一个共享模块连接多个任务的多任务学习方法而言,可以减少由于多种信息投影到相同的特征空间时所造成的信息干扰。
2)本发明由于在训练过程中使用了同一数据集,可以更加充分地挖掘和利用数据本身的信息进行检测。
3)本发明使用了层级注意力机制,来重点关注那些对谣言检测更有帮助的词汇和推文,能够有效的加速模型收敛、减少噪声的干扰,从而达到提升模型的检测效果。
附图说明
图1是本发明所提基于并行化信息共享模块的多任务谣言检测方法的模型总体结构图。
图2是基于文本内容和社会背景信息谣言检测模块的结构图。
图3是基于文本内容和写作风格的谣言检测模块的结构图。
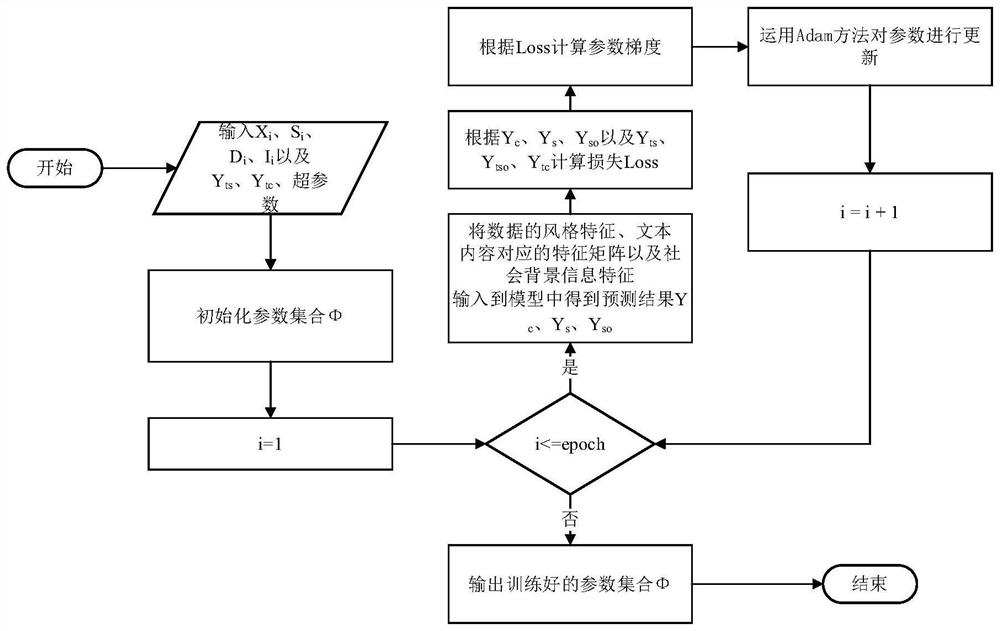
图4是模型训练流程图。
具体实施方式
1)定义社会背景信息特征So,其由用户自描述信息D以及其他些离散的社会背景信息I={user_frc,user_folc,user_stac,user_ver,user_fac,t_attc,t_rec,time_gap},用户自描述信息D为用户信息描述经过分词以及词嵌入得到的词向量矩阵经过Sentence Encoder编码后得到的特征向量。
其中:user_frc,user_folc,user_stac,user_ver,user_fac分别为用户的好友数量、粉丝数量、已发推文数量、是否认证以及关注数量;time_gap表示用户账户的注册时间和该推文发表时间的时间差,t_attc,t_rec则表示推文的点赞数和转发数。
2)基于一个大型语料库训练一个Word2Vec词向量嵌入模型,然后,将每一个推文处理为{Word
大型语料库采用采用的是维基百科的中英文语料库。
Word2Vec词向量嵌入模型是谷歌2013年提出的一个将文本转换成向量或矩阵的一个语言模型。
3)使用写作风格表示S={lenght,qu_sys,uh_sys,w
4)设计并定义基于并行化信息共享模块的多任务谣言检测模型及其计算过程,其模型总体结构如图1所示。主要由以下部分组成:
(一):基于文本内容和社会背景信息的多任务模块:
本部分是包括基于文本内容的谣言检测任务和基于社会背景信息的谣言检测任务,这两部分是通过基于注意力的共享方法实现信息共享,在信息共享的过程中能够有效的加强各自的检测效果。因为在共享空间中,那些谣言传播过程中那些异常的社会背景信息特征会被投影到虚假信息的文本内容特征附近,在各自经过共享层后带着共享空间信息返回各个任务独有的层,从而加强各自任务的特征表示。该部分的整体结构如图2所示。
其中:D
X
其中:所述相关推文为对原推文进行转发或者评论的推文;
Sentence Encoder模块,是将原本表示为一个词向量矩阵的文本特征编码为一个固定维度向量的编码器。
对于基于文本内容的检测任务来说,先将源推文以及相关推文内容特征向量X
所述原本的文本为原推文经过Sentence Encoder编码后得到的特征向量。
所述文本内容和社会背景信息共享模块,用于提取基于文本内容和基于社会背景信息检测任务共享信息;
所述文本内容和写作风格共享模块则,用于提取基于文本内容和基于写作风格检测任务共享信息;
所述基于文本内容检测任务独有层,用于进一步提取基于文本内容特征的层。
所述全连接层,将得到的向量表示转换为一个只包含一个数的向量,以供Sigmoid函数计算。
具体的计算公式如下:
X
h
h
h
H
Y
其中:W
对于基于社会背景信息的检测任务而言,先将通过Sentence Encoder得到用户描述的特征向量D
D
h
h
H
Y
其中:W
(二):基于文本内容和写作风格的多任务模块:
基于文本内容和写作风格的信息共享方法,是通过基于文本内容的谣言检测任务以及基于写作风格的谣言检测任务通过共享参数的形式实现信息交互和共享的,同时也使用了基于注意力机制的信息共享方法来减少噪声干扰,从而起到有效提高各自检测效果的作用。因为在共享的特征空间中,虚假信息的文本内容特征的投影往往会与其对应的写作风格特征很接近,其各自通过共享层进行计算之后会携带者丰富的共享信息返回到自己任务的独有层中,进而提高各自特征的质量,其总体结构如图3所示。
其中:S
对于基于写作风格特征的谣言检测任务,先将S
所述对齐层,将写作风格特征向量进行初步特征提取并使S
所述写作风格独有层,用于进一步提取写作风格特征。
其计算公式如下:
h
h
H
Y
其中,h
基于文本内容的谣言检测任务,先通过Sentence Encoder将每一个推文的词向量矩阵编码为一个特征向量X
所述本身的文本内容,为经过Sentence Encoder后得到的文本特征向量X
所述Sentence Attention,用于产生每一个X
u
其中:u
5)模型训练:本发明提出模型的训练过程如图4所示。其中:Y
实施例:
为了验证本发明方法的有效性,本发明在收集自Twitter和Pheme数据集以及中文微博数据集上进行了实验并验证。本发明采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1分数四个评价指标来反映本发明方法的有效性。其对应的计算公式如下:
其中:TP表示真阳率,TN表示真阴率,FP表示假阳率而FN则表示假阴率。准确率可以反映方法精度、精确率和召回率则是反映本发明方法对应正样本的检测效果,而F1则是反映了模型的综合性能。本发明的实验结果如表1所示:
表1 Pheme数据集和中文微博数据集实验结果表
从上述表1可以看出,无论是在英文的Pheme数据集还是中文的微博数据集上都取得了良好的检测结果。
- 基于学习模型的谣言检测方法、系统及存储介质
- 一种基于写作风格的多任务谣言检测方法、装置及设备
- 一种基于多任务学习的社交媒体谣言检测方法