基于GMM和粒子群算法的NOMA信号频谱感知方法
文献发布时间:2024-01-17 01:14:25
技术领域
本发明涉及一种认知无线电技术,尤其是涉及一种基于GMM(Gaussian MixtureModel,高斯混合模型)和粒子群算法的NOMA(Non-Orthogonal Multiple Access,非正交多址接入)信号频谱感知方法,其通过GMM和粒子群算法进行信道系数估计,以实现NOMA信号频谱感知。
背景技术
随着第五代无线通信技术的快速发展,需要通过无线电接入网络的无线设备数量急剧增加,人们对无线通信的需求越来越多。虽然目前对毫米波通信的研究逐渐增多,但是毫米波通信的频段较高存在穿透力差、覆盖范围小等缺点,使用毫米波通信若想实现大范围覆盖则需要很高的成本。因此,提高中低频段的频谱利用率对于5G和物联网的发展同样重要。为了提高中低频段的频谱利用率,当前已经设计了很多技术,包括非正交多址接入(NOMA)、认知无线电。非正交多址接入(NOMA)技术可以给多个用户分配相同的频率、时间或码域上的正交资源,可以在无需任何带宽扩展的情况下提高系统吞吐量;认知无线电技术的基本思想是频谱重用,次级用户可以通过频谱感知技术感知周围无线电环境、检测频谱空洞和在不影响主用户正常通信的情况下访问空闲频段。鉴于非正交多址接入(NOMA)技术与认知无线电技术可以在不同方面提高频谱利用率,因此两种技术的结合对频谱效率提高更有帮助。
基于NOMA在一个时频资源上可以分配给多个用户的理论,同一个频段中存在多个主用户和一个次级用户。传统的频谱感知中,次级用户感知一个主用户存在与否,转化为一个二元假设问题;但基于NOMA信号的频谱感知由于存在多个主用户,次级用户需要感知主用户存在的个数,所以这实际可转化为一个多重假设检验问题。由于同一信道中的不同主用户其功率不同,次级用户可以根据感知结果将功率调成与任意不工作的主用户功率一致,接入信道进行通信。
当前已有利用K-means和K-nearest-neighbor(KNN)等机器学习算法解决基于NOMA信号的频谱感知问题,研究人员对来自多个感知持续时间(或时隙)的多个次级用户接收的能量向量进行分类。这类方法基于聚类算法,将来自不同感知持续时间的信号划分为多个类别。因此,它们需要接收信号的多个感知持续时间来实现频谱感知,限制了它们的应用。
发明内容
本发明所要解决的技术问题是提供一种基于GMM和粒子群算法的NOMA信号频谱感知方法,在该方法中多个主用户利用NOMA技术共享同一个信道,通过建立高斯混合模型进行信道估计,感知信道中主用户工作的数量,并可以根据未工作的主用户的功率接入信道,能够有效提高频谱利用率,且无需多个感知持续时间,仅需单个感知持续时间接收到信号进行频谱感知。
本发明解决上述技术问题所采用的技术方案为:一种基于GMM和粒子群算法的NOMA信号频谱感知方法,其特征在于包括以下步骤:
步骤1:在认知无线电系统中,设定只存在一个次级用户,且利用NOMA技术共享同一个信道的最大主用户数为K,这些主用户从1开始编写序号;在任一个感知时隙内次级用户接收到一个连续信号作为NOMA信号,然后对在任一个感知时隙内次级用户接收到的NOMA信号进行N次采样,得到N个离散信号;其中,K≥2,N表示采样次数,N≥500;
步骤2:针对次级用户的N个离散信号,按采样的先后顺序依次遍历每个离散信号,将当前遍历的离散信号定义为当前离散信号;
步骤3:设定当前离散信号为第n个离散信号,并记为r(n),将r(n)描述为:
步骤4:令
步骤5:根据
步骤6:按采样的先后顺序依次遍历下一个离散信号,将下一个遍历的离散信号作为当前离散信号,然后返回步骤3继续执行,直至次级用户的N个离散信号均处理完毕,得到次级用户的每个离散信号的概率密度函数;
步骤7:计算次级用户的N个离散信号的联合概率密度函数,记为f(r),
;然后根据f(r)建立次级用户的N个离散信号的高斯混合模型,记为f
步骤8:根据
步骤9:对在任一个感知时隙内次级用户接收到的NOMA信号进行频谱感知,若|g
所述的步骤8中,利用粒子群算法求解
步骤8_1:设定粒子群中有L个粒子,且每个粒子的维度为K;设定粒子群中的所有粒子的位置边界值和速度边界值,其中,位置边界值根据粒子群所需搜索范围来确定,速度边界值为位置边界值的10%~20%;然后在位置边界值确定的范围内随机初始化粒子群中的L个粒子各自的位置值,并在速度边界值确定的范围内随机初始化粒子群中的L个粒子各自的速度值,将粒子群中的第α个粒子的位置值的初始值记为
步骤8_2:令q表示迭代次数,令Q表示预设的最大迭代次数;令g
步骤8_3:针对第q次迭代,当q=1时将粒子群中的每个粒子的位置值的初始值代入视为适应度函数的
当q≠1时将粒子群中的每个粒子第q-1次迭代的位置值代入视为适应度函数的
步骤8_4:计算粒子群中的每个粒子第q次迭代的位置值,将粒子群中的第α个粒子第q次迭代的位置值记为
步骤8_5:计算粒子群中的每个粒子第q次迭代的速度值,将粒子群中的第α个粒子第q次迭代的速度值记为
步骤8_6:判断q是否大于或等于Q或者g
步骤8_7:将收敛的g
与现有技术相比,本发明的优点在于:
1)本发明方法在多个主用户利用NOMA技术共享同一个信道时,次级用户进行频谱感知,能够识别繁忙信道上的主用户的数量。
2)本发明提出了一种新颖的频谱感知方法,它只需要一个感知持续时间信号就能够有效地进行频谱感知,而不像传统聚类算法那样需要多个信号。这种方法可以大大提高频谱感知的速度和效率。
附图说明
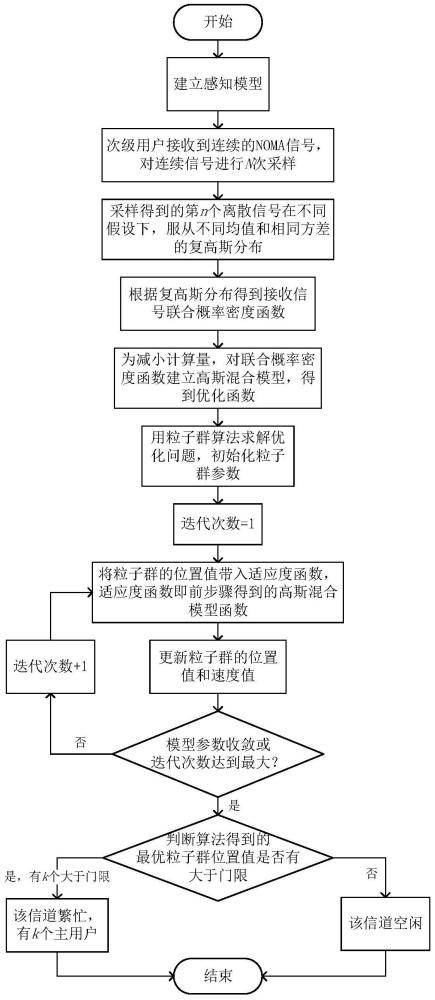
图1为本发明方法的总体实现框图;
图2为分别利用本发明方法以及常用的聚类算法(K-means方法、GMM方法、KNN方法)得到的错检概率随着信噪比的变化对比图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种基于GMM和粒子群算法的NOMA信号频谱感知方法,其总体实现框图如图1所示,其包括以下步骤:
步骤1:在认知无线电系统中,设定只存在一个次级用户,且利用NOMA技术共享同一个信道的最大主用户数为K,这些主用户从1开始编写序号;在任一个感知时隙内次级用户接收到一个连续信号作为NOMA信号,然后对在任一个感知时隙内次级用户接收到的NOMA信号进行N次采样,得到N个离散信号;其中,K≥2,从理论上来说主用户越多越好,但是数量越多接收端解调复杂性就越大,通常研究人员考虑功率域NOMA上存在两个主用户,即K=2,因此本实施例中取K=2,未采用NOMA技术时K=1,N表示采样次数,N≥500,本实施例中取N=1000。
步骤2:针对次级用户的N个离散信号,按采样的先后顺序依次遍历每个离散信号,将当前遍历的离散信号定义为当前离散信号。
步骤3:设定当前离散信号为第n个离散信号,并记为r(n),将r(n)描述为:
步骤4:频谱感知的目的是确定r(n)属于哪个假设,即属于H
步骤5:与传统的信道估计不同,此情况导频信号是不可用的,频谱感知问题的关键是用
步骤6:按采样的先后顺序依次遍历下一个离散信号,将下一个遍历的离散信号作为当前离散信号,然后返回步骤3继续执行,直至次级用户的N个离散信号均处理完毕,得到次级用户的每个离散信号的概率密度函数。
步骤7:计算次级用户的N个离散信号的联合概率密度函数,记为f(r),
;然后根据f(r)建立次级用户的N个离散信号的高斯混合模型,记为f
步骤8:由于高斯混合模型中未知参数只有
在此具体实施例中,步骤8中,利用粒子群算法求解
步骤8_1:设定粒子群中有L个粒子,且每个粒子的维度为K;设定粒子群中的所有粒子的位置边界值和速度边界值,其中,位置边界值根据粒子群所需搜索范围来确定,速度边界值一般为位置边界值的10%~20%;然后在位置边界值确定的范围内随机初始化粒子群中的L个粒子各自的位置值,并在速度边界值确定的范围内随机初始化粒子群中的L个粒子各自的速度值,将粒子群中的第α个粒子的位置值的初始值记为
步骤8_2:令q表示迭代次数,令Q表示预设的最大迭代次数;令g
步骤8_3:针对第q次迭代,当q=1时将粒子群中的每个粒子的位置值的初始值代入视为适应度函数的
当q≠1时将粒子群中的每个粒子第q-1次迭代的位置值代入视为适应度函数的
步骤8_4:计算粒子群中的每个粒子第q次迭代的位置值,将粒子群中的第α个粒子第q次迭代的位置值记为
步骤8_5:计算粒子群中的每个粒子第q次迭代的速度值,将粒子群中的第α个粒子第q次迭代的速度值记为
步骤8_6:判断q是否大于或等于Q或者g
步骤8_7:将收敛的g
步骤9:对在任一个感知时隙内次级用户接收到的NOMA信号进行频谱感知,若|g
通过以下仿真来进一步说明本发明方法的可行性和有效性。
在仿真中,利用NOMA技术共享同一个信道的最大主用户数K=2,两个主用户的发射信号的功率系数比为Ω
用于比较的常用的聚类算法有K-means方法、GMM方法、KNN方法,比较时各方法在每次蒙特卡洛试验中使用6400个感知持续时间。
图2给出了分别利用本发明方法以及常用的聚类算法(K-means方法、GMM方法、KNN方法)得到的错检概率随着信噪比的变化对比图。图2中,虚线
- NOMA系统中基于机器学习的频谱感知方法和装置
- NOMA系统中基于机器学习的频谱感知方法和装置