电力负荷预测方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及电力运维技术领域,具体涉及一种电力负荷预测方法。
背景技术
负荷预测是保证电力供需平衡的基础,并为电网、电源的规划建设以及电网企业、电网使用者的经营决策提供信息和依据,直接关系到电力系统的需求调度。准确的负荷预测可以有效地提高电网的规划调度能力,提高电网运行的稳健性。现有的负荷预测技术有时间序列预测法易于应用,但对检测数据的稳定性要求高。神经网络法则存在学习的时候容易陷入局部最优、迭代次数不好确定、泛化误差比较大以及隐层神经元难以确定等缺陷。
而负荷预测属于典型的针对数据支持量相对较少、随机不确定的信息数列进行的预测,且信息数列特征上有一定的周期性。但目前所有的负荷预测模型单从数列信息数据本身进行建模,忽略其周期性的特点,造成了负荷预测的数据冗余及周期性的预测值修正等行为,既增加了社会经济成本,也使得现有系统存在一定的安全隐患。
发明内容
本发明要解决的技术问题是:克服现有技术的不足,提供一种电力负荷预测方法。
本发明为解决其技术问题所采用的技术方案为:电力负荷预测方法,包括以下步骤:
步骤一:数据获取;
步骤二:确定序列周期性参数M,进行采样序列的周期性累加,获得新的周期性累加序列H1;
步骤三:生成负荷预测模型;
步骤四:模型待定预估参数值;
步骤五:获取新的预测模型;
步骤六:进行负荷模型可靠性验证。
所述步骤一中获得不少于4天内的初始采样数列H0={h0(1),h0(2),…,h0(i),…,h0(N)},其中i为序列采样点,i∈[1,N],N≥16,表示负荷采样总数。
所述步骤二中,新的周期性累加序列H1表示如下:
H1={∑h0(1+j-1),∑h0(2+j-1),…,∑h0(i+j-1),…,∑h0(N+j-1)},其中,j∈[1,M],M以小时为最小周期单位,且h1(1)=∑h0(1+j-1),h1(b)=∑h0(b+j-1),其中b为待预测负荷数列点,b∈[1,L],L为周期性累加序列H1元素总个数,L≤N,h1整体表示1次数据累加生成的序列代号符号。
所述步骤三中按照以下公式生成负荷预测模型:
h1(b+1)=d1h1(b)+d2;
式中,d1,d2为模型待定预估参数值,通过最小二乘拟合原理由周期性数列获得。
所述模型待定预估参数值d1,d2的计算公式如下:
[d1,d2]
式中,R=[h1(1),h1(2),…,h1(L-M);1,1,…,1]
W=[hl(2),hl(3),...,hl(L-M+l)]
所述步骤五中包括以下子步骤:
5-1:采用数据序列就近取值的原则,获得新的预测模型,其计算如下:
式中,u为周期数列修正系数;u=∑[h1(k+1)-d1h1(k)-d2]/d1h1(k-1),k∈[1,b];
5-2:根据既有数列模型参数,获得负荷预测模型如下:
所述步骤六中基于误差系数P1进行负荷模型可靠性验证;
若误差系数P1小于等于5%,则进行负荷预测;否则返回步骤一重新采集下一组数据进行模型生成。
所述误差系数P1的计算公式如下:
式中,S表示预计预测负荷点的总个数,S∈[1,N],p∈[1,S]。
与现有技术相比,本发明具有以下有益效果:
本发明提供一种电力负荷预测方法,改变了传统的负荷预测数列建模方式,通过进行数列的周期性特征提取和分析,提高了预测精度,减少了冗余数列数据信息的生成,降低了社会经济成本,并利用适当的修正系数来进一步提高负荷预测的稳健性和精确度,大大降低运行系统的风险性。
附图说明
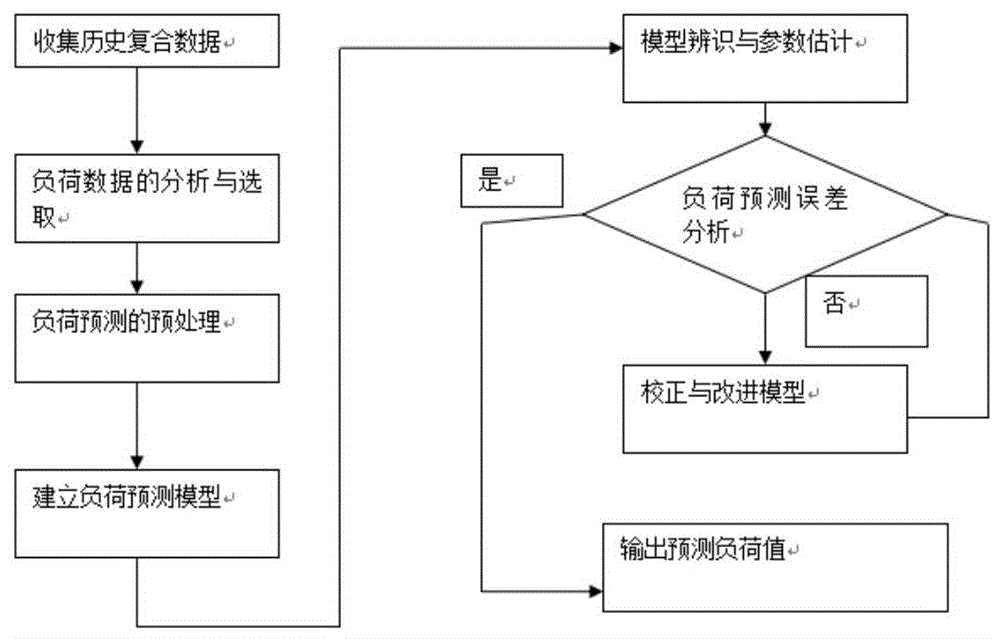
图1是本发明流程图。
图2是本发明运行展示图。
具体实施方式
下面结合附图对本发明实施例做进一步描述:
实施例1
如图1及图2所示,电力负荷预测方法包括以下步骤:
步骤一:数据获取;所述步骤一中获得不少于4天内的初始采样数列H0={h0(1),h0(2),…,h0(i),…,h0(N)},其中i为序列采样点,i∈[1,N],N≥16,表示负荷采样总数。电力SCADA系统数据库中存储有电力负荷数据,系统终端从系统数据库中获取上述数据。
步骤二:确定序列周期性参数M,进行采样序列的周期性累加,获得新的周期性累加序列H1;所述步骤二中,新的周期性累加序列H1表示如下:
H1={∑h0(1+j-1),∑h0(2+j-1),…,∑h0(i+j-1),…,∑h0(N+j-1)},其中,j∈[1,M],M以小时为最小周期单位,且h1(1)=∑h0(1+j-1),h1(b)=∑h0(b+j-1),其中b为待预测负荷数列点,b∈[1,L],L为周期性累加序列H1元素总个数,L≤N,为确保数列稳健性,一般取值L=N。h1整体表示1次数据累加生成的序列代号符号。
步骤三:生成负荷预测模型;所述步骤三中按照以下公式生成负荷预测模型:
h1(b+1)=d1h1(b)+d2;
式中,d1,d2为模型待定预估参数值,通过最小二乘拟合原理由周期性数列获得。
步骤四:模型待定预估参数值;所述模型待定预估参数值d1,d2的计算公式如下:
[d1,d2]
式中,R=[h1(1),h1(2),…,h1(L-M);1,1,…,1]
W=[hl(2),hl(3),...,hl(L-M+l)]
步骤五:获取新的预测模型;所述步骤五中包括以下子步骤:
5-1:采用数据序列就近取值的原则,获得新的预测模型,其计算如下:
式中,u为周期数列修正系数;u=∑[h1(k+1)-d1h1(k)-d2]/d1h1(k-1),k∈[1,b];
5-2:根据既有数列模型参数,获得负荷预测模型如下:
步骤六:进行负荷模型可靠性验证。所述步骤六中基于误差系数P1进行负荷模型可靠性验证;
若误差系数P1小于等于5%,则进行负荷预测;否则返回步骤一重新采集下一组数据进行模型生成。
所述误差系数P1的计算公式如下:
式中,S表示预计预测负荷点的总个数,S∈[1,N],p∈[1,S]。
实施例2
以国内鲁北某电力公司10天的电力历史运行每2小时的有功负荷采样数据为例,并将其与神经网络自学习模型和自回归模型的负荷预测结果做对比。
具体历史运行数据如下表:
运行展示如图1所示。图中可以看出,历史运行数据的周期性规律主要体现在每天的不同时段,10天的运行数据基本处于平稳状态,每8小时会产生周期性数据的变化。采用本发明方法实现负荷预测的基本流程如图1所示,其中,负荷预测模型为采用本发明的步骤方法实现,结合其他神经网络自学习模型和自回归模型的负荷预测结果的对比结果如下:针对下周期8小时的运行数据结果预测对比如下(每2小时采样):
本发明方法的负荷预测相对误差率均在5%以内,模型预测符合预期精度。借助MATLAB工具进行数据分析,获得的其他方法的平均预测相对误差率的对比如下表所示:
可见本发明方法具备较低的负荷预测平均相对误差率。
- 电力负荷预测模型的构建方法与电力负荷预测方法
- 电力负荷预测模型的训练方法、装置及电力负荷预测方法