图像渲染的方法和装置
文献发布时间:2023-06-19 09:26:02
技术领域
本申请涉及图像处理技术领域,并且更具体地,涉及一种图像渲染的方法和装置。
背景技术
光线追踪是现代电影、游戏等领域用于产生或增强特殊视觉效果的技术,其通过追踪从摄像机发出的每条光线来实现如环境光遮蔽、间接反射、漫射等全局光照,能在渲染框架上保证图像与现实的无缝衔接。
目前主流的光线追踪技术主要分为三种模式,包括离线模式、交互模式、实时模式。其中离线模式的渲染效果最佳但耗时较长,交互模式在渲染效果和时间上做了平衡,而实时模式牺牲了部分渲染效果以满足实时性的要求。电影的呈现方式在其非互动性,所以制作时可以通过大量服务器离线渲染即可,而游戏需要实时的人机交互,因此游戏厂商只能通过实时渲染的方式来对每一帧画面进行计算,实时计算则带来庞大的计算量。在光线追踪领域,对每个像素点的光线采样值直接影响了渲染的效果,高采样值意味着庞大的计算量,而低采样值在保证实时渲染的前提下,引入了很多的噪点,使得渲染的图片质量下降。
现有技术中,基于Optix的路径追踪算法,在SponzaGlossy场景下每像素采样数(sample per pixel,spp)为1时的渲染耗时为70ms,在SanMiguel场景下1spp的渲染耗时为260ms,对于游戏行业每一帧渲染至多16ms的耗时而言,基于Optix的路径追踪算法无法满足需求。因此在有限的硬件条件下要实现实时渲染,需要使用低采样值并结合降噪算法。表1示出了现有的降噪算法在1至2spp低采样值条件下的优化效果:
表1
上表中,Titan XP、Intel i7-7700HQ、Nvidia Quadro M6000均为高性能的显卡,SBF(sure based filter)、AAF(axis aligned filter for both soft shadows)、LBF(learning based filter)、NFOR(nonlinearly weighted first order regression)、AE(interactive reconstruction of Monte carlo image sequences using a recurrentdenoising autoencoder)等降噪算法在低采样值的条件下获取720P分辨率的渲染图像耗时过长,无法满足需求;而KPCN(kernel predicting convolutional networks)降噪算法要获取较高分辨率1080P的渲染图像则需要较高的采样值,且耗时过长,也无法满足需求;时域方差引导滤波(spatiotemporal variance-guided filtering,SVGF)降噪算法在低采样值的的条件下获取720P分辨率的渲染图像的耗时满足时间需求,但是720P的分辨率无法保证游戏的流畅度。因此由上表可知,现有的实时光线追踪技术仍然存在计算量大、硬件要求高的缺陷,在低采样值条件下要达到较好的渲染效果,渲染耗时长,无法满足游戏渲染的耗时要求。因此,在不增加硬件成本的条件下,如何获得高帧率、高分辨率的实时渲染效果,则尤为重要。
发明内容
本申请提供一种图像渲染的方法和装置,可以实现在低采样值的条件下获得高分辨率、高帧率的渲染图像。
第一方面,提供了一种图像渲染的方法,该方法包括:获取第一图像、第二图像和第三图像,第一图像、第二图像和第三图像为连续的三帧图像;根据第一图像更新第二图像的光照图,以得到第二图像更新后的光照图;将第二图像更新后的光照图输入超分去噪网络,以得到第二图像的超分去噪图像;根据第二图像更新第三图像的光照图,以得到第三图像更新后的光照图;将第三图像更新后的光照图输入超分去噪网络,以得到第三图像的超分去噪图像;根据第二图像的超分去噪图像和第三图像的超分去噪图像获取目标时刻的初始插帧图像,目标时刻为第二图像和第三图像之间的时刻;将初始插帧图像输入双向插帧网络,以得到目标时刻的插帧图像。
本申请实施例的图像渲染方法可以对低采样值(例如1spp)的图像进行处理,极大降低了对硬件设备的要求;本申请实施例的图像渲染方法对像素点进行颜色值累加,更新低采样值的光照图,可以弥补采样信息量不足造成的噪点问题;本申请实施例的图像渲染方法使用超分去噪网络对图像进行处理,可以提高图像的分辨率;本申请实施例的图像渲染方法对连续两帧图像进行插帧,并使用双向插帧网络对插帧的图像进行处理,从而提高图像的帧率,保证图像渲染的流畅度。
结合第一方面,在第一方面的某些实现方式中,根据第一图像更新第二图像的光照图,以得到第二图像更新后的光照图,包括:获取第二图像的光照图,第二图像的光照图包括多个像素点的颜色值,第二图像的光照图为直接光照图或间接光照图;获取第一像素点在第一图像中对应的第二像素点,第一像素点为多个像素点中的任一个;根据第一像素点的颜色值与第二像素点的颜色值,更新第一像素点的颜色值,以得到更新后的光照图。
针对低采样值造成的噪点严重的问题,本申请实施例的图像渲染的方法通过累加时域信息,结合每个像素点的历史颜色信息更新该像素点的颜色值,从而更新图像的光照图,弥补采样值不足,从而减轻渲染的噪点。
结合第一方面,在第一方面的某些实现方式中,当第二像素点的位置不在第一图像的网格节点上时,该方法还包括:获取与第二像素点距离最近的四个像素点的颜色值,四个像素点在第一图像的网格节点上;根据四个像素点的颜色值获取第二像素点的颜色值。
本申请实施例的图像渲染的方法考虑到可能存在后一帧图像的像素点在前一帧图像中对应的像素点不在前一帧图像的网格节点上,此时在前一帧图像的像素点的颜色值不能直接获得,因此本申请实施例的图像渲染的方法根据双线性插值的方法来获取前一帧图像的像素点的颜色值。
结合第一方面,在第一方面的某些实现方式中,根据第一像素点的颜色值与第二像素点的颜色值,更新第一像素点的颜色值之前,方法还包括:判断第一像素点和第二像素点符合一致性,该判断第一像素点和第二像素点符合一致性包括:获取第一像素点的深度值、第一像素点的法向量值、第一像素点的面片ID和第二像素点的深度值、第二像素点的法向量值、第二像素点的面片ID;第一像素点的深度值与第二像素点的深度值的差的平方小于第一阈值;第一像素点的法向量值与第二像素点的法向量值的差的平方小于第二阈值;第一像素点的面片ID与第二像素点的面片ID相等。
为了保证第二像素点确实是第一像素点在第一图像中对应的像素点,在利用第二像素点的颜色值更新第一像素点的颜色值之前,本申请实施例的方法还包括,对第一像素点和第二像素点进行一致性判断。同样的,如果第一像素点在第一图像中对应的第二像素点的位置不在第一图像的网格节点上,此时第二像素点的深度值、法向量值、面片ID不能直接得到,与上述获得颜色值的方法类似,需要采用双线性插值算法得到第二像素点的深度值、法向量值、面片ID。
结合第一方面,在第一方面的某些实现方式中,根据第一像素点的颜色值与第二像素点的颜色值,更新第一像素点的颜色值,包括:第一像素点更新后的颜色值为将第一像素点的颜色值乘以第一系数与将第二像素点的颜色值乘以第二系数之和。
本申请实施例的图像渲染的方法提供了一种第一像素点的颜色值与第二像素点的颜色值,更新第一像素点的颜色值的方法,其中第一系数和第二系数为预设的值。
结合第一方面,在第一方面的某些实现方式中,将第二图像更新后的光照图输入超分去噪网络,还包括:获取第二图像的深度图、第二图像的法向量图;将第二图像的深度图、第二图像的法向量图、第二图像更新后的光照图融合,以得到第一融合结果;将第一融合结果输入超分去噪网络。
为了弥补非刚体运动和阴影运动的运动矢量估计不准确的问题,本申请实施例的图像渲染的方法还包括将深度图、法向量图和更新后的光照图进行特征融合。
结合第一方面,在第一方面的某些实现方式中,根据第二图像的超分去噪图像和第三图像的超分去噪图像获取目标时刻的初始插帧图像,包括:获取第三图像到第二图像的运动矢量;根据第三图像到第二图像的运动矢量确定目标时刻的初始插帧图像到第二图像的第一运动矢量,和目标时刻的初始插帧图像到第三图像的第二运动矢量;根据第二图像的超分去噪图像、第三图像的超分去噪图像、第一运动矢量和第二运动矢量获取目标时刻的初始插帧图像。
本申请实施例的图像渲染的方法对连续两帧图像进行插帧,从而提高图像渲染的帧率。
结合第一方面,在第一方面的某些实现方式中,将初始插帧图像输入双向插帧网络,还包括:获取第二图像的深度图、第二图像的法向量图、第三图像的深度图、第三图像的法向量图;将第二图像的深度图、第二图像的法向量图、第三图像的深度图、第三图像的法向量图与初始插帧图像融合,以得到第二融合结果;将第二融合结果输入双向插帧网络。
为了弥补非刚体运动和阴影运动的运动矢量估计不准确的问题,本申请实施例的图像渲染的方法还包括将深度图、法向量图和初始插帧图像进行特征融合。
结合第一方面,在第一方面的某些实现方式中,超分去噪网络为预先训练的神经网络模型,超分去噪网络的训练包括:获取多组超分去噪原始训练数据,多组超分去噪原始训练数据中的每组超分去噪原始训练数据包括连续两帧图像和连续两帧图像中后一帧图像对应的标准图像;判断连续两帧图像的像素点符合一致性;获取连续两帧图像中后一帧图像的深度图、后一帧图像的法向量图和后一帧图像的光照图,后一帧图像的光照图为直接光照图或间接光照图;根据连续两帧图像更新后一帧图像的像素点的颜色值,以得到后一帧图像更新后的光照图;将后一帧图像的深度图、后一帧图像法向量图和后一帧图像更新后的光照图融合,以得到更新后的图像;根据更新后的图像与标准图像,对超分去噪网络进行训练。
本申请实施例还提供超分去噪网络的训练方法,获取低采样值(例如1spp)图像,将后一帧图像在高采样值(例如4096spp)条件下的渲染结果作为标准图像,对神经网络进行训练。
结合第一方面,在第一方面的某些实现方式中,双向插帧网络为预先训练的神经网络模型,双向插帧网络的训练包括:获取多组双向插帧原始训练数据,多组双向插帧原始训练数据中每组双向插帧原始训练数据包括第四图像、第五图像、第六图像,第四图像、第五图像、第六图像为连续的三帧图像;根据第四图像和第六图像获取第四图像和第六图像中间时刻的插帧图像;根据中间时刻的插帧图像和第五图像,对双向插帧网络进行训练。
本申请实施例还提供双向插帧网络的训练方法,获取连续的第四图像、第五图像、第六图像,对第四图像、第六图像进行插帧,得到初始的插帧结果,然后将第五图像作为标准,对神经网络进行训练。
第二方面,提供了一种图像渲染的装置,该装置包括:获取模块,用于获取第一图像、第二图像和第三图像,第一图像、第二图像和第三图像为连续的三帧图像;处理模块,用于根据第一图像更新第二图像的光照图,以得到第二图像更新后的光照图;处理模块还用于将第二图像更新后的光照图输入超分去噪网络,以得到第二图像的超分去噪图像;处理模块还用于根据第二图像更新第三图像的光照图,以得到第三图像更新后的光照图;处理模块还用于将第三图像更新后的光照图输入超分去噪网络,以得到第三图像的超分去噪图像;处理模块还用于根据第二图像的超分去噪图像和第三图像的超分去噪图像获取目标时刻的初始插帧图像,目标时刻为第二图像和第三图像之间的时刻;处理模块还用于将初始插帧图像输入双向插帧网络,以得到目标时刻的插帧图像。
结合第二方面,在第二方面的某些实现方式中,处理模块根据第一图像更新第二图像的光照图,以得到第二图像更新后的光照图,包括:获取第二图像的光照图,第二图像的光照图包括多个像素点的颜色值,第二图像的光照图为直接光照图或间接光照图;获取第一像素点在第一图像中对应的第二像素点,第一像素点为多个像素点中的任一个;根据第一像素点的颜色值与第二像素点的颜色值,更新第一像素点的颜色值,以得到更新后的光照图。
结合第二方面,在第二方面的某些实现方式中,当第二像素点的位置不在第一图像的网格节点上时,处理模块还用于:获取与第二像素点距离最近的四个像素点的颜色值;根据四个像素点的颜色值获取第二像素点的颜色值。
结合第二方面,在第二方面的某些实现方式中,处理模块根据第一像素点的颜色值与第二像素点的颜色值,更新第一像素点的颜色值之前,处理模块还用于:判断第一像素点和第二像素点符合一致性,该判断第一像素点和第二像素点符合一致性包括:获取第一像素点的深度值、第一像素点的法向量值、第一像素点的面片ID和第二像素点的深度值、第二像素点的法向量值、第二像素点的面片ID;第一像素点的深度值与第二像素点的深度值的差的平方小于第一阈值;第一像素点的法向量值与第二像素点的法向量值的差的平方小于第二阈值;第一像素点的面片ID与第二像素点的面片ID相等。
结合第二方面,在第二方面的某些实现方式中,根据第一像素点的颜色值与第二像素点的颜色值,更新第一像素点的颜色值,包括:第一像素点更新后的颜色值为将第一像素点的颜色值乘以第一系数与将第二像素点的颜色值乘以第二系数之和。
结合第二方面,在第二方面的某些实现方式中,处理模块将第二图像更新后的光照图输入超分去噪网络,还包括:获取第二图像的深度图、第二图像的法向量图;
将第二图像的深度图、第二图像的法向量图、第二图像更新后的光照图融合,以得到第一融合结果;将第一融合结果输入超分去噪网络。
结合第二方面,在第二方面的某些实现方式中,处理模块根据第二图像的超分去噪图像和第三图像的超分去噪图像获取目标时刻的初始插帧图像,包括:获取第三图像到第二图像的运动矢量;根据第三图像到第二图像的运动矢量确定目标时刻的初始插帧图像到第二图像的第一运动矢量,和目标时刻的初始插帧图像到第三图像的第二运动矢量;根据第二图像的超分去噪图像、第三图像的超分去噪图像、第一运动矢量和第二运动矢量确定目标时刻的初始插帧图像。
结合第二方面,在第二方面的某些实现方式中,处理模块将初始插帧图像输入双向插帧网络,还包括:获取第二图像的深度图、第二图像的法向量图、第三图像的深度图、第三图像的法向量图;将第二图像的深度图、第二图像的法向量图、第三图像的深度图、第三图像的法向量图与初始插帧图像融合,以得到第二融合结果;将第二融合结果输入双向插帧网络。
结合第二方面,在第二方面的某些实现方式中,超分去噪网络为预先训练的神经网络模型,超分去噪网络的训练包括:获取多组超分去噪原始训练数据,多组超分去噪原始训练数据中的每组超分去噪原始训练数据包括连续两帧图像和连续两帧图像中后一帧图像对应的标准图像;判断连续两帧图像的像素点符合一致性;获取连续两帧图像中后一帧图像的深度图、后一帧图像的法向量图和后一帧图像的光照图,后一帧图像的光照图为直接光照图或间接光照图;根据连续两帧图像更新后一帧图像的像素点的颜色值,以得到后一帧图像更新后的光照图;将后一帧图像的深度图、后一帧图像法向量图和后一帧图像更新后的光照图融合,以得到更新后的图像;根据更新后的图像与标准图像,对超分去噪网络进行训练。
结合第二方面,在第二方面的某些实现方式中,双向插帧网络为预先训练的神经网络模型,双向插帧网络的训练包括:获取多组双向插帧原始训练数据,多组双向插帧原始训练数据中每组双向插帧原始训练数据包括第四图像、第五图像、第六图像,第四图像、第五图像、第六图像为连续的三帧图像;根据第四图像和第六图像获取第四图像和第六图像中间时刻的插帧图像;根据中间时刻的插帧图像和第五图像,对双向插帧网络进行训练。
第三方面,提供了一种图像渲染的装置,该装置包括:存储器,用于存储程序;处理器,用于执行存储器存储的程序,当存储器存储的程序被处理器执行时,处理器执行上述第一方面中的任意一种方式中的部分或全部操作。
第四方面,提供了一种电子设备,该电子设备包括上述第二方面中的任意一种方式中任一项的图像渲染的装置。
第五方面,提供了一种计算机可读存储介质,该计算机可读存储介质存储有可被处理器执行的计算机程序,当计算机程序被处理器执行时,处理器执行上述第一方面中的任意一种方式中的部分或全部操作。
第六方面,提供了一种芯片,该芯片包括处理器,处理器用于执行上述第一方面所描述的方法中的部分或全部操作。
第七方面,提供了一种计算机程序或计算机程序产品,该计算机程序或计算机程序产品包括计算机可读指令,当所述计算机可读指令被处理器执行时,处理器执行上述第一方面中的任意一种方式中的部分或全部操作。
附图说明
图1是本申请实施例的光线追踪和光栅化的示意性框图;
图2是本申请实施例的U-Net神经网络的示意性结构图;
图3是本申请实施例的电子设备的示意性框图;
图4是本申请实施例的现有的基于实时光线追踪技术的图像渲染方法的系统架构示意性框图;
图5是本申请实施例的基于实时光线追踪技术的图像渲染方法的系统架构示意性框图;
图6是本申请实施例的图像渲染方法的示意性流程图;
图7是本申请实施例的超分去噪网络的训练的示意性流程图;
图8是本申请实施例的双向插帧网络的训练的示意性流程图;
图9是本申请实施例的图像渲染方法的示意性框图;
图10是本申请实施例的获取数据集的示意性流程图;
图11是本申请实施例的光栅化过程的示意性框图;
图12是本申请实施例的利用双线性插值获取前一帧像素点的参数的示意性框图;
图13是本申请实施例中利用超分去噪网络对图像进行超分去噪的示意性框图;
图14是本申请实施例利用双向插帧网络对图像进行处理的示意性框图;
图15是本申请实施例的图像渲染的装置的示意性框图;
图16是本申请实施例的超分去噪网络的训练的装置的示意性框图;
图17是本申请实施例的双向插帧网络的训练的装置的示意性框图;
图18是本申请实施例的电子设备的结构示意图。
具体实施方式
以下实施例中所使用的术语只是为了描述特定实施例的目的,而并非旨在作为对本申请的限制。如在本申请的说明书和所附权利要求书中所使用的那样,单数表达形式“一个”、“一种”、“所述”、“上述”、“该”和“这一”旨在也包括例如“一个或多个”这种表达形式,除非其上下文中明确地有相反指示。还应当理解,在本申请以下各实施例中,“至少一个”、“一个或多个”是指一个、两个或两个以上。术语“和/或”,用于描述关联对象的关联关系,表示可以存在三种关系;例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B的情况,其中A、B可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。
在本说明书中描述的参考“一个实施例”或“一些实施例”等意味着在本申请的一个或多个实施例中包括结合该实施例描述的特定特征、结构或特点。由此,在本说明书中的不同之处出现的语句“在一个实施例中”、“在一些实施例中”、“在其他一些实施例中”、“在另外一些实施例中”等不是必然都参考相同的实施例,而是意味着“一个或多个但不是所有的实施例”,除非是以其他方式另外特别强调。术语“包括”、“包含”、“具有”及它们的变形都意味着“包括但不限于”,除非是以其他方式另外特别强调。
为了便于理解本申请的技术方案,首先对本申请涉及的概念做简要介绍。
光线追踪:三维计算机图形学中的特殊渲染算法,从视点开始发射一条射线通过视平面上的每一个像素点并不断进行光线与物体交叉判定,同时考虑反射折射等光学现象来渲染三维场景。
全局光照(global illumination,GI):指既考虑场景中来自光源的直接光照,又考虑经过场景中其他物体反射后的间接光照的一种渲染技术,表现了直接光照和间接光照的综合效果。
光栅化:是把顶点数据转换为片元的过程,具有将图转换为一个个栅格组成的图像的作用,是一种将几何图元转换为二维图像的过程。
刚体:一种有限尺寸、可以忽略形变的固体。无论是否受到外力,在刚体内部质点与质点之间的距离都不会改变。
图像超分:即图像超分辨率,将输入的低分辨率图像重建为高分辨率图像的技术。
深度学习:机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。
下面将结合附图,对本申请中的技术方案进行描述。
图1示出了本申请实施例中光线追踪和光栅化的示意性框图。光线追踪和光栅化都是渲染的技术,目的是将三维空间的物体经过计算着色投影到二维屏幕空间进行显示。光线追踪和光栅化的区别在于,光线追踪渲染是假设屏幕上每一个点是一条一条向前的射线,计算这些射线打到图形(如图1所示的三角形)上的哪些位置,然后再计算出这些位置处的纹理像素颜色;而光栅化渲染是先将图形(如图1所示的三角形)顶点进行坐标变换,然后在二维屏幕上的三角形内部填充纹理。相比于光栅化,光线追踪的计算量更大,但是渲染效果更加真实,本申请实施例的图像渲染方法为基于光线追踪的渲染方法。
然后对本申请实施例的图像渲染方法中涉及的卷积神经网络(convolutionalneuron network,CNN)——U-Net做介绍。U-Net最初应用在医疗影像分割任务上,由于效果很好,之后被广泛应用在各种分割任务中。U-Net支持少量的数据训练模型,通过对每个像素点进行分类,获得更高的分割准确率,U-Net用训练好的模型分割图像,速度快。图2示出了U-Net的示意性结构图,以下结合图2对U-Net作简要介绍。图2示出了U-Net的网络结构,左边为编码器部分,对输入进行下采样,下采样通过最大池化实现;右边为解码器部分,对编码器的输出进行上采样,恢复分辨率,上采样通过upsample实现;中间为跳跃连接(skip-connect),进行特征融合。由于整个网络结构形似“U”,因此称为U-Net。
其中,上采样和下采样可以增加对输入图像的一些小扰动的鲁棒性,例如图像平移、旋转等,减少过拟合的风险,降低运算量和增加感受野的大小。上采样的作用其实就是把抽象的特征再还原解码到原图的尺寸,最终得到清晰无噪点的图像。
本申请实施例中的图像渲染的方法可以由电子设备来执行。该电子设备可以是移动终端(例如,智能手机),电脑,个人数字助理,可穿戴设备,车载设备,物联网设备或者其他能够进行图像渲染处理的设备。该电子设备可以是运行安卓系统、IOS系统、windows系统以及其他系统的设备。
本申请实施例的图形渲染方法可以由电子设备执行,该电子设备的具体结构可以如图3所示,下面结合图3对电子设备的具体结构进行详细的介绍。
在一个实施例中,如图3所示,电子设备300可以包括:中央处理器(CPU)301、图形处理器(GPU)302、显示设备303和存储器304。可选地,该电子设备300还可以包括至少一个通信总线310(图3中未示出),用于实现各个组件之间的连接通信。
应当理解,电子设备300中的各个组件还可以通过其他连接器相耦合,其他连接器可包括各类接口、传输线或总线等。电子设备300中的各个组件还可以是以处理器301为中心的放射性连接方式。在本申请的各个实施例中,耦合是指通过相互电连接或连通,包括直接相连或通过其他设备间接相连。
中央处理器301和图形处理器302的连接方式也有多种,不局限于图3所示的方式。电子设备300中的中央处理器301和图形处理器302可以位于同一个芯片上,也可以分别为独立的芯片。
下面对中央处理器301、图形处理器302、显示设备303和存储器304的作用进行简单的介绍。
中央处理器301:用于运行操作系统305和应用程序307。应用程序307可以为图形类应用程序,比如游戏、视频播放器等等。操作系统305提供了系统图形库接口,应用程序307通过该系统图形库接口,以及操作系统305提供的驱动程序,比如图形库用户态驱动和/或图形库内核态驱动,生成用于渲染图形或图像帧的指令流,以及所需的相关渲染数据。其中,系统图形库包括但不限于:嵌入式开放图形库(open graphics library for embeddedsystem,OpenGL ES)、柯罗诺斯平台图形界面(the khronos platform graphicsinterface)或Vulkan(一个跨平台的绘图应用程序接口)等系统图形库。指令流包含一些列的指令,这些指令通常为对系统图形库接口的调用指令。
可选地,中央处理器301可以包括以下至少一种类型的处理器:应用处理器、一个或多个微处理器、数字信号处理器(digital signal processor,DSP)、微控制器(microcontroller unit,MCU)或人工智能处理器等。
中央处理器301还可进一步包括必要的硬件加速器,如专用集成电路(application specific integrated circuit,ASIC)、现场可编程门阵列(fieldprogrammable gate array,FPGA)、或者用于实现逻辑运算的集成电路。处理器301可以被耦合到一个或多个数据总线,用于在电子设备300的各个组件之间传输数据和指令。
图形处理器302:用于接收处理器301发送的图形指令流,通过渲染管线(pipeline)生成渲染目标,并通过操作系统的图层合成显示模块将渲染目标显示到显示设备303。
可选地,图形处理器302可以包括执行软件的通用图形处理器,如GPU或其他类型的专用图形处理单元等。
显示设备303:用于显示由电子设备300生成的各种图像,该图像可以为操作系统的图形用户界面(graphical user interface,GUI)或由图形处理器302处理的图像数据(包括静止图像和视频数据)。
可选地,显示设备303可以包括任何合适类型的显示屏。例如液晶显示器(liquidcrystal display,LCD)或等离子显示器或有机发光二极管(organic light-emittingdiode,OLED)显示器等。
存储器304,是中央处理器301和图形处理器302之间的传输通道,可以为双倍速率同步动态随机存储器(double data rate synchronous dynamic random access memory,DDR SDRAM)或者其它类型的缓存。
渲染管线是图形处理器302在渲染图形或图像帧的过程中顺序执行的一些列操作,典型的操作包括:顶点处理(Vertex Processing)、图元处理(Primitive Processing)、光栅化(Rasterization)、片段处理(Fragment Processing)等等。
在本申请实施例的图形渲染方法中,会涉及将三维坐标转换为二维坐标,下面先对相关的基本概念进行简单的介绍。
三维坐标转换为二维坐标的过程会涉及到5种不同的坐标系统。
局部空间(Local Space,或者称为物体空间(Object Space));
世界空间(World Space);
观察空间(View Space,或者称为视觉空间(Eye Space));
裁剪空间(Clip Space);
屏幕空间(Screen Space)。
为了将坐标从一个坐标系变换到另一个坐标系,一般需要用到几个变换矩阵,最重要的几个变换矩阵分别是模型(Model)、观察(View)、投影(Projection)三个矩阵。顶点数据的坐标一般起始于局部空间(Local Space),在这里将局部空间的坐标称为局部坐标(Local Coordinate),局部坐标经过变换之后会变依次变为世界坐标(WorldCoordinate),观察坐标(View Coordinate),裁剪坐标(Clip Coordinate),并最后以屏幕坐标(Screen Coordinate)的形式结束。
在上述坐标变换过程中,局部坐标是对象相对于局部原点的坐标,也是物体起始的坐标。接下来,是将局部坐标变换为世界空间坐标,世界空间坐标是处于一个更大的空间范围的。这些坐标相对于世界的全局原点,它们会和其它物体一起相对于世界的原点进行摆放。然后将世界坐标变换为观察空间坐标,使得每个坐标都是从摄像机或者说观察者的角度进行观察的。当坐标到达观察空间之后,我们需要将其投影到裁剪坐标。裁剪坐标会被处理至-1.0到1.0的范围内,并判断哪些顶点将会出现在屏幕上。最后,再将裁剪坐标变换为屏幕坐标,接下来将使用一个叫做视口变换(Viewport Transform)的过程。视口变换将位于-1.0到1.0范围的坐标变换到由glViewport函数所定义的坐标范围内。最后变换出来的坐标将会送到光栅器,将其转化为片段(转换为片段之后,就可以根据该片段进行视频图像的显示了)。
在上述过程中,之所以将顶点变换到各个不同的空间是因为有些操作在特定的坐标系统中才有意义且更方便。例如,当需要对物体进行修改的时候,在局部空间中来操作会更说得通;如果要对一个物体做出一个相对于其它物体位置的操作时,在世界坐标系中来做这个才更说得通,等等。如果我们愿意,我们也可以定义一个直接从局部空间变换到裁剪空间的变换矩阵,但那样会失去很多灵活性。
接下来对各个坐标系统进行详细的介绍。
局部空间:
局部空间是指物体所在的坐标空间,即对象最开始所在的地方。想象你在一个建模软件(比如说Blender)中创建了一个立方体。你创建的立方体的原点有可能位于(0,0,0),即便它有可能最后在程序中处于完全不同的位置。甚至有可能创建的所有模型都以(0,0,0)为初始位置(然而它们会最终出现在世界的不同位置)。所以,该创建的模型的所有顶点都是在局部空间中:它们相对于你的物体来说都是局部的。
世界空间:
如果我们将我们所有的物体导入到程序当中,它们有可能会全挤在世界的原点(0,0,0)上,这并不是我们想要的结果。我们想为每一个物体定义一个位置,从而能在更大的世界当中放置它们。世界空间中的坐标正如其名:是指顶点相对于(游戏)世界的坐标。如果你希望将物体分散在世界上摆放(特别是非常真实的那样),这就是你希望物体变换到的空间。物体的坐标将会从局部变换到世界空间;该变换是由模型矩阵(Model Matrix)实现的。
模型矩阵是一种变换矩阵,它能通过对物体进行位移、缩放、旋转来将它置于它本应该在的位置或朝向。你可以将它想像为变换一个房子,你需要先将它缩小(它在局部空间中太大了),并将其位移至郊区的一个小镇,然后在y轴上往左旋转一点以搭配附近的房子。你也可以把上一节将箱子到处摆放在场景中用的那个矩阵大致看作一个模型矩阵;我们将箱子的局部坐标变换到场景/世界中的不同位置。
观察空间:
观察空间经常被人们称之跨平台的图形程序接口(open graphics library,OPENGL)的摄像机(有时也称为摄像机空间(Camera Space)或视觉空间(Eye Space))。观察空间是将世界空间坐标转化为用户视野前方的坐标而产生的结果。因此观察空间就是从摄像机的视角所观察到的空间。而这通常是由一系列的位移和旋转的组合来完成,平移/旋转场景从而使得特定的对象被变换到摄像机的前方。这些组合在一起的变换通常存储在一个观察矩阵(View Matrix)里,它被用来将世界坐标变换到观察空间。在下一节中我们将深入讨论如何创建一个这样的观察矩阵来模拟一个摄像机。
裁剪空间:
在一个顶点着色器运行的最后,OpenGL期望所有的坐标都能落在一个特定的范围内,且任何在这个范围之外的点都应该被裁剪掉(Clipped)。被裁剪掉的坐标就会被忽略,所以剩下的坐标就将变为屏幕上可见的片段。这也就是裁剪空间(Clip Space)名字的由来。
因为将所有可见的坐标都指定在-1.0到1.0的范围内不是很直观,所以我们会指定自己的坐标集(Coordinate Set)并将它变换回标准化设备坐标系,就像OPENGL期望的那样。
为了将坐标从观察变换到裁剪空间,我们需要定义一个投影矩阵(ProjectionMatrix),它指定了一个范围的坐标,比如在每个维度上的-1000到1000。投影矩阵接着会将在这个指定的范围内的坐标变换为标准化设备坐标的范围(-1.0,1.0)。所有在范围外的坐标不会被映射到在-1.0到1.0的范围之间,所以会被裁剪掉。在上面这个投影矩阵所指定的范围内,坐标(1250,500,750)将是不可见的,这是由于它的x坐标超出了范围,它被转化为一个大于1.0的标准化设备坐标,所以被裁剪掉了。
例如,如果只是图元(Primitive),例如三角形,的一部分超出了裁剪体积(Clipping Volume),则OpenGL会重新构建这个三角形为一个或多个三角形让其能够适合这个裁剪范围。
光线追踪通过追踪从摄像机发出的每条光线来获得精准的阴影、反射、漫反射的全局光照效果,因此模拟渲染极具真实感的虚拟场景需要极大的计算量和功耗。目前基于分辨率1920×1080、帧率30fps的实时光线追踪,由于GPU硬件条件的限制,针对每一个像素值只能提供1至2spp的采样值,低采样值会引入大量噪声,使得渲染的图片质量降低,如果对于4k或8k等更高的分辨率,采样值必须更低。因此需要在不增加硬件成本和维持实时光线追踪的前提下,优化低采样值条件下的渲染效果,去除由于采样不足引起的噪点,输出稳定的全局光照的图像。
现有的SVGF算法在1spp条件下,结合空间域和时间域的信息滤波去噪,同时计算空间域和时间域上的方差用于区分高频纹理信息和噪点区域,指导滤波器进行多层滤波。但是该方法无法准确估计非刚体运动和阴影部分的运动矢量,因此阴影部分去噪效果差;同时该方法采用传统的双边滤波,无法动态调整滤波权重,且多层滤波耗时较长,因此该方法时效性较差。
现有的另一种KPCN算法将图像分为镜面反射部分和漫反射部分,然后利用神经网络自适应调整镜面反射部分和漫反射部分的滤波核权重,最后联合该两部分得到联合去噪结果。该方法的缺点在于采样值大(通常为32spp),模型结构庞大但效果单一(只具备去噪功能),计算量大、耗时长,也没有充分利用时域信息进行补充,因此该算法几乎无法满足实时性要求。
现有的第三种算法为了解决阴影部分和非刚体运动矢量估计不准造成去噪效果差的问题,利用像素表面信息以及阴影信息计算梯度变化值,若梯度值越大,则代表像素点移动越大,因此丢弃该像素点相应的历史信息。该方法提出了基于梯度判断运动的剧烈性,用于缓解大幅位移无法准确估计运动矢量所造成的重影现象,但无法作为单独的去噪模块。该方法可以与上述的SVGF算法相结合,也可以与本申请实施例的图像渲染方法相结合使用。
现有的GPU硬件的功耗和计算能力有限,在高采样值的条件下计算量十分庞大,无法达到30fps的实时性要求。如果对于每个像素点只追踪1至2条光线,虽然大大降低了计算量,但引入大量噪声。且不同材质表面的噪点特性不同,如果使用相同的去噪流程,去噪效果不佳,进一步加大了低采样值下降噪算法的难度。根据几何缓冲区(geometry buffer,G-buffer)渲染管线中的相关信息,可以准确得到刚体运动的运动矢量,G-buffer是指包含颜色、法向、世界空间坐标的缓冲区。但是非刚体和阴影部分的运动矢量估计不准确,会造成渲染效果下降。此外降噪算法的实时性进一步受到图像分辨率大小的影响,高分辨率、高帧率下的光线追踪降噪算法的实时性面临更大的挑战。
因此现有的图像渲染技术面临如下问题:
(1)高采样值计算量庞大,无法满足实时性要求,低采样值噪点严重;
(2)不同材质表面的噪点特性不同,如果使用相同的去噪流程,去噪效果不佳;
(3)对于游戏画面渲染,需要实现高分辨率、高帧率条件下的实时光线追踪,实时性难度大;
(4)非刚体和阴影部分的运动矢量估计不准确。
因此,本申请实施例提出一种图像渲染的方法,在有限的硬件条件下,采用低采样值,并结合时域信息,就不同材质产生的不同噪点采取不同的优化策略,以实现高帧率和高分辨率的实时的光线追踪图像渲染。
图4示出了现有的基于实时光线追踪技术的图像渲染方法的系统架构示意性框图,如图4所示,包括模型材质加载模块401、生成光线模块402、光线求交模块403、去噪模块404、后处理模块405、显示模块406等六个部分。
基于实时光线追踪技术的图像渲染的第一步是模型材质的加载,主要涉及两个部分,第一部分是将需要渲染的模型添加到场景中,第二部分是给场景中的模型添加各自的材质信息和纹理信息。该步骤由型材质加载模块401实现。
生成光线是指从光源向成像维平面发射光线的过程。针对每个像素点发射光线的数目极大程度上影响最终的渲染效果,采样值低,图像模糊、噪点多;采样值高,图像清晰、效果好。但是由于硬件条件有限,为了确保光线追踪的实时性,一般对于一个像素点只发射1至2条光线。该步骤由生成光线模块402实现。
光线追踪把一个场景的渲染任务拆分成考虑从摄像机发出的若干条光线对场景的影响,这些光线不知道彼此,却知道整个场景模型的信息。光线求交是指追踪摄像机发射的光线,求出和场景模型的交点,并且根据交点位置获取场景模型表面的材质、纹理等信息,结合光源信息计算反射光线。反射光线的计算基于蒙特卡洛重要性采样,在采样值1spp的条件下,即对每个交点也只追踪1条光线。与光线生成部分相应,反射光线的采样值也会影响最终的渲染效果。光线求交由生成光线求交模块403实现。
去噪模块404用于降低由于低采样值产生的噪点,在保证光线追踪的实时性的同时确保渲染效果。
后处理模块405用于采取色调映射(tone mapping)、抗锯齿(temporal antialiasing,TAA)技术对渲染效果进行完善。其中色调映射技术用于对图像颜色进行映射变换,调整图像的灰度,使得处理后的图像能更好表达原图的信息与特征;TAA技术应用调色技术将图像边缘的“锯齿”缓和,使图像边缘更加平滑。
显示模块406用于显示最终渲染好的图像。
图5示出了本申请实施例的基于实时光线追踪技术的图像渲染方法的系统架构示意性框图,如图5所示,包括模型材质加载模块501、下采样生成光线模块502、光线求交模块503、去噪模块504、插帧模块505、后处理模块506、显示模块507等七个部分。
与图4中现有的基于实时光线追踪技术的图像渲染方法不同,本申请实施例的基于实时光线追踪技术的图像渲染方法中,假设最终成像的二维平面大小为w×h,下采样图像为最终成像平面大小的1/2,则只对其中的(1/2)w×(1/2)h个像素点发射光线,如此可以极大减少光线求交的计算量。
由于生成光线时进行了下采样,因此本申请实施例的基于实时光线追踪技术的图像渲染方法中,在去噪模块504融合了超分技术,对图像进行了恢复。
此外,在去噪模块504后加入了插帧模块505,以解决高帧率场景下的实时性问题。
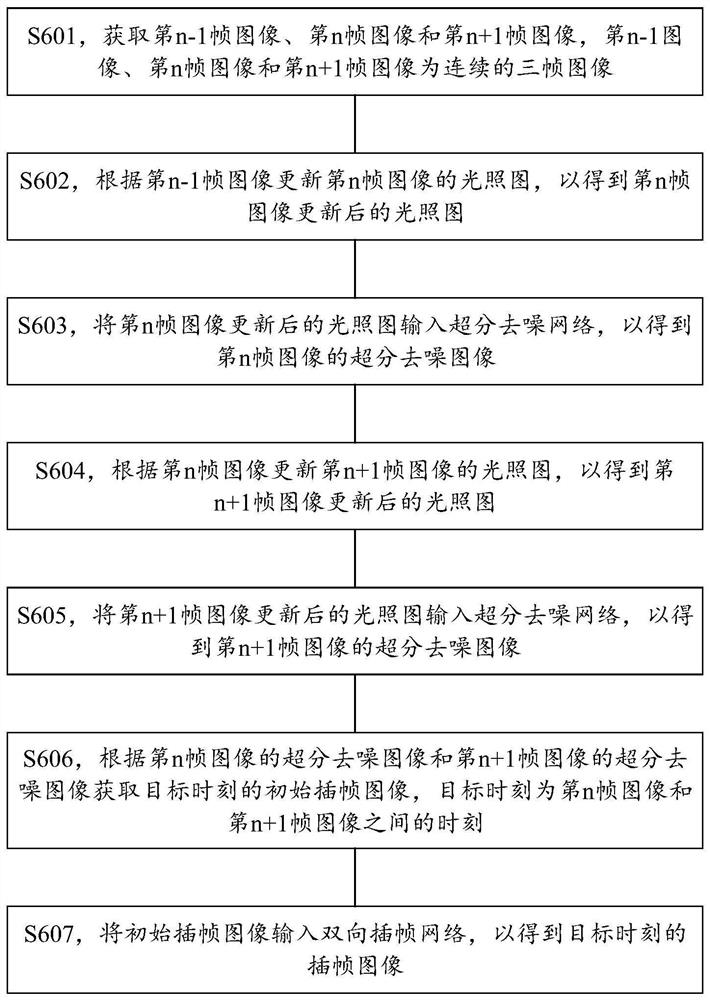
图6示出了本申请实施例的图像渲染方法的示意性流程图,如图6所示,包括步骤601至步骤607,以下分别对这些步骤做详细介绍。
S601,获取第n-1帧图像、第n帧图像、第n+1帧图像,应理解,第n-1帧图像、第n帧图像、第n+1帧图像为连续的三帧图像,且这里的连续是指第n-1帧图像在第n帧图像之前,第n帧图像在第n+1帧图像之前。其中,第n-1帧图像、第n帧图像、第n+1帧图像为图5中通过模型材质加载模块501、下采样生成光线模块502、光线求交模块503生成的低采样值(例如1spp)的图像。
S602,根据第n-1帧图像更新所述第n帧图像的光照图,以得到第n帧图像更新后的光照图。该步骤可以由图5中的去噪模块504执行。
光照图包括直接光照图和间接光照图,其中直接光照图为光源直接照射到被观察物体上,光线经过被观察物体反射到用户眼睛里而得到的光照图;间接光照图为光源先照射到其他物体上,经过一次或多次反射后,光线最终到达被观察的物体,经过被观察物体反射到用户眼睛里而得到的光照图。
应理解,图像由多个像素点组成,其中每个像素点具有各自的颜色值,一张图像上所有的像素点的颜色值的总和为这张图像的光照图。
具体的,光照图包括直接光照图和间接光照图,直接光照即光源的光直接照射在物体上,间接光照即光源的光经过一次或多次反射后照射在物体上,以下以直接光照图为例进行说明。
对于第n帧图像中的任一个像素点,记为第一像素点,获取第一像素点在第n-1帧图像中对应的像素点记为第二像素点。也就是说第二像素点是第一像素点在第n-1帧图像中对应的像素点。然后根据第一像素点的颜色值和第二像素点的颜色值,更新第一像素点的颜色值,具体的,可以将第一像素点的颜色值乘以第一系数,得到第一结果,将第二像素点的颜色值乘以第二系数,得到第二结果,然后将第一结果与第二结果相加,得到第一像素点更新后的颜色值。其中,第一系数和第二系数可以是人为预设的值,本申请实施例在此不做具体限定。
可选的,如果第一像素点在第n-1帧图像中对应的第二像素点的位置不在第n-1帧图像的网格节点上,此时第二像素点的颜色值不能直接得到,需要采用双线性插值算法得到第二像素点的颜色值。具体的,先找到与第二像素点距离最近的四个像素点的颜色值,这四个像素点需要在第n-1帧图像的网格节点上;然后获取这四个像素点的颜色值;利用这四个像素点的颜色值结合双线性插值算法,即可计算得到第二像素点的颜色值。
可选的,为了保证第二像素点确实是第一像素点在第n-1帧图像中对应的像素点,在利用第二像素点的颜色值更新第一像素点的颜色值之前,本申请实施例的方法还包括,对第一像素点和第二像素点进行一致性判断。具体的,先获取第一像素点的深度值、第一像素点的法向量值、第一像素点的面片ID和第二像素点的深度值、第二像素点的法向量值、第二像素点的面片ID;如果第一像素点和第二像素点满足:第一像素点的深度值与第二像素点的深度值的差的平方小于第一阈值,第一像素点的法向量值与第二像素点的法向量值的差的平方小于第二阈值,第一像素点的面片ID与第二像素点的面片ID相等,则认为第一像素点与第二像素点满足一致性,则可以将第二像素点的颜色值用于更新第一像素点的颜色值。如果第一像素点与第二像素点不满足一致性,则不用第二像素点的颜色值更新第一像素点的颜色值,则令第一像素点更新后的颜色值为第一像素点当前的颜色值。
可选的,如果第一像素点在第n-1帧图像中对应的第二像素点的位置不在第n-1帧图像的网格节点上,此时第二像素点的深度值、法向量值、面片ID不能直接得到,与上述获得颜色值的方法类似,需要采用双线性插值算法得到第二像素点的深度值、法向量值、面片ID。具体的,先找到与第二像素点距离最近的四个像素点的深度值、法向量值、面片ID,这四个像素点需要在第n-1帧图像的网格节点上;然后获取这四个像素点的深度值、法向量值、面片ID;利用这四个像素点的深度值、法向量值、面片ID结合双线性插值算法,即可计算得到第二像素点的深度值、法向量值、面片ID。
在对第n帧图像中每个像素点按照如上方式进行颜色值更新后,即可得到第n帧图像更新后的直接光照图。
本申请实施例中对直接光照图和间接光照图的处理方式相同,间接光照图的处理方式可以参照上述对直接光照图的处理方式,为了简洁,本申请实施例在此不再赘述。
S603,将第n帧图像更新后的光照图输入超分去噪网络,以得到第n帧图像的超分去噪图像。该步骤可以由图5中的去噪模块504执行。
应理解,更新后的光照图包括更新后的直接光照图和更新后的间接光照图。具体的,首先获取第n帧图像的深度图和法向量图,应理解,第n帧图像的深度图为第n帧图像中所有像素点的深度值的总和,第n帧图像的法向量图为第n帧图像中所有像素点的法向量值的总和;然后将第n帧图像更新后的直接光照图、更新后的间接光照图、深度图、法向量图融合,从而得到第一融合结果,其中融合的方式可以是现有的特征融合方式,例如concate或者add等方式,本申请实施例在此不做具体限定;最后将第一融合结果输入超分去噪网络,从而得到第n帧图像的超分去噪图像。其中超分去噪网络为预先训练好的神经网络模型,超分去噪网络可以具有如图2所示的U-Net网络结构,超分去噪网络的训练过程在下文具体介绍。
S604,根据第n帧图像更新第n+1帧图像的光照图,以得到第n+1帧图像更新后的光照图。该步骤可以由图5中的去噪模块504执行。
根据第n帧图像更新第n+1帧图像的光照图的过程与根据第n-1帧图像更新第n帧图像的光照图的过程类似,具体可以参照上述对于根据第n-1帧图像更新所述第n帧图像的光照图,以得到第n帧图像更新后的光照图的过程的描述,为了简洁,本申请实施例在此不再赘述。
S605,将第n+1帧图像更新后的光照图输入超分去噪网络,以得到第n+1帧图像的超分去噪图像。该步骤可以由图5中的去噪模块504执行。
将第n+1帧图像更新后的光照图输入超分去噪网络的过程与将第n帧图像更新后的光照图输入超分去噪网络的过程类似,具体可以参照上述对于将第n帧图像更新后的光照图输入超分去噪网络,以得到第n帧图像的超分去噪图像的过程的描述,为了简洁,本申请实施例在此不再赘述。
S606,根据第n帧图像的超分去噪图像和第n帧图像的超分去噪图像获取目标时刻的初始插帧图像,目标时刻为第n帧图像和第n+1帧图像之间的时刻。该步骤可以由图5中的插帧模块505执行。
在按照上述方法获取了第n帧图像的超分去噪图像和第n+1帧图像的超分去噪图像之后,则根据第n帧图像的超分去噪图像和第n+1帧图像的超分去噪图像获取目标时刻的初始插帧图像,其中目标时刻为第n帧图像和第n+1帧图像之间的时刻,优选地,目标时刻为第n帧图像和第n+1帧图像之间的中间时刻。具体的,首先获取第n+1帧图像到第n帧图像的运动矢量,应理解,第n+1帧图像中的每个像素点到第n帧图像中对应的像素点都有一个运动矢量,所有像素点的运动矢量之和即为第n+1帧图像到第n帧图像的运动矢量;然后根据第n+1帧图像到第n帧图像的运动矢量确定目标时刻的初始插帧图像到第n帧图像的第一运动矢量,和目标时刻的初始插帧图像到第n+1帧图像的第二运动矢量,例如,假设第n+1帧图像到第n帧图像的运动矢量为M
M
目标时刻的初始插帧图像到第n+1帧图像的第二运动矢量为:
M
最后根据第n帧图像的超分去噪图像、第n+1帧图像的超分去噪图像、第一运动矢量和第二运动矢量可以获得目标时刻的初始插帧图像。假设第n帧图像的超分去噪图像为I
I
其中函数g()表示映射操作。
S607,将初始插帧图像输入双向插帧网络,以得到目标时刻的插帧图像。该步骤可以由图5中的插帧模块505执行。
本申请实施例的方法可以直接将初始插帧图像输入双向插帧网络,但是为了弥补非刚体运动和阴影运动的运动矢量估计不准确的问题,本申请实施例的方法还包括:首先获取第n帧图像的深度图、第n帧图像的法向量图、第n+1帧图像的深度图、第n+1帧图像的法向量图;然后将第n帧图像的深度图、第n帧图像的法向量图、第三图像的深度图、第三图像的法向量图与初始插帧图像融合,以得到第二融合结果,其中融合的方式可以是现有的特征融合方式,例如concate或者add等方式,本申请实施例在此不做具体限定;最后将第二融合结果输入双向插帧网络。其中双向插帧网络为预先训练好的神经网络模型,双向插帧网络可以具有如图2所示的U-Net网络结构,双向插帧网络的训练过程在下文具体介绍。
本申请实施例的图像渲染方法可以对低采样值(例如1spp)的图像进行处理,极大降低了对硬件设备的要求;本申请实施例的图像渲染方法对像素点进行颜色值累加,更新低采样值的光照图,可以弥补采样信息量不足造成的噪点问题;本申请实施例的图像渲染方法使用超分去噪网络对图像进行处理,可以提高图像的分辨率;本申请实施例的图像渲染方法对连续两帧图像进行插帧,并使用双向插帧网络对插帧的图像进行处理,从而提高图像的帧率,保证图像渲染的流畅度。
图7示出了本申请实施例的超分去噪网络的训练的示意性流程图,如图7所示,包括步骤701至步骤706,以下分别对这些步骤进行介绍。
S701,获取多组超分去噪原始训练数据,多组超分去噪原始训练数据中的每组超分去噪原始训练数据包括连续两帧图像和连续两帧图像中后一帧图像对应的标准图像。
具体的,这里的连续两帧图像为低采样值(例如1spp)的图像,而后一帧图像对应的标准图像为后一帧图像在高采样值(例如4096spp)条件下的渲染结果。标准图像用于作为低采样值图像的训练标准。
S702,判断连续两帧图像的像素点符合一致性。
具体的,对于后一帧图像中的每个像素点,判断前一帧图像中对应的像素点是否与其符合一致性。其中,判断像素点一致性的方法可以参照上述S602中的描述,为了简洁,本申请实施例在此不再赘述。
S703,获取连续两帧图像中后一帧图像的深度图、后一帧图像的法向量图和后一帧图像的光照图,后一帧图像的光照图为直接光照图或间接光照图。
S704,根据连续两帧图像更新后一帧图像的像素点的颜色值,以得到后一帧图像更新后的光照图。
具体的,对于符合一致性的像素点,则根据连续两帧图像更新后一帧图像的像素点的颜色值,更新像素点颜色值的方法可以参照上述S602中的描述,为了简洁,本申请实施例在此不再赘述。对于不符合一致性的像素点,则将后一帧图像的像素点当前的颜色值作为该像素点更新后的颜色值。在对后一帧图像中的每个像素点进行颜色值更新后,可以得到后一帧图像更新后的光照图。
S705,将后一帧图像的深度图、后一帧图像法向量图和后一帧图像更新后的光照图融合,以得到更新后的图像。
具体的融合方法可以参照上述对于S603的描述,为了简洁,本申请实施例在此不再赘述。
S706,根据更新后的图像与所述标准图像,对超分去噪网络进行训练。
应理解,这里对于超分去噪网络的训练与一般的神经网络的训练方法相同,将高采样值图像作为标准,使得低采样值的图像的训练结果逼近高采样值图像,当训练结果与标准图像的差距小于预设值时,认为此时的超分去噪网络训练完成。
图8示出了本申请实施例的双向插帧网络的训练的示意性流程图,如图8所示,包括步骤801至步骤803,以下分别对这些步骤进行介绍。
S801,获取多组双向插帧原始训练数据,多组双向插帧原始训练数据中每组双向插帧原始训练数据包括第四图像、第五图像、第六图像,第四图像、第五图像、第六图像为连续的三帧图像。
第四图像、第五图像、第六图像可以是通过上述步骤得到的超分去噪图像,也可以是其他图像,本申请实施例在此不做限定。
S802,根据第四图像和第六图像获取第四图像和第六图像中间时刻的插帧图像。
获取中间时刻的插帧图像可以参照上述对于S606的描述,为了简洁,本申请实施例在此不再赘述。
S803,根据中间时刻的插帧图像和所述第五图像,对双向插帧网络进行训练。
将第五图像作为标准图像,使得对于中间时刻的插帧图像的训练结果逼近第五图像,当训练结果与第五图像的差距小于预设值时,认为此时的双向插帧网络训练完成。
本申请实施例的图像渲染方法主要针对低采样值(例如1spp)条件下的噪点去除和实现高分辨率、高帧率的实时光线追踪。图9示出了本申请实施例的图像渲染方法的示意性框图,以下结合图9对本申请实施例的图像渲染方法做详细介绍。
本申请实施例的图像渲染方法涉及超分去噪网络和双向插帧网络,超分去噪网络和双向插帧网络具有上述图2中的U-Net网络模型结构,超分去噪网络和双向插帧网络需要预先训练得到。
其中,超分去噪网络的训练包括:通过光线追踪将获取的光照信息分为直接光照和间接光照,结合G-buffer中的运动矢量和一致性判断,更新直接光照和间接光照的颜色信息。将更新后的直接光照和间接光照的颜色信息融合G-buffer中对应的深度信息和法向信息,其中融合方式可以是concate方式或者add方式。将融合后的直接光照和间接光照输入到超分去噪网络中,分别得到直接光照的超分去噪结果和间接光照的超分去噪结果。最后将直接光照的超分去噪结果和间接光照的超分去噪结果融合,得到最终的超分去噪结果。超分去噪网络的真实值(Ground Truth)为采样值4096app的光线追踪渲染结果。
双向插帧网络的训练包括:将超分去噪网络输出的连续三帧图像记为I
图9所示的光栅化渲染是将三维物体的一系列坐标值映射到二维平面中。从三维坐标到二维坐标的过程通常是分步进行,需要多个坐标系进行过渡,包括:局部空间、世界空间、观察空间、裁剪空间、平面空间等。将坐标从一个坐标系变换到另一个坐标系,是通过变换矩阵实现的,其中,从局部空间坐标到世界空间坐标的变换矩阵为模型矩阵M
如图9所示,通过光线追踪将获取的光照信息分为直接光照和间接光照。通过访问历史颜色缓冲区并结合当前帧中对应的像素点的颜色值,可以实现颜色值在时域上的连续积累,这是由于采样值较少的情况下,图像会产生较多噪点,将历史颜色值与当前颜色值累加相当于增加采样值。但是,由于阴影等非刚体的运动矢量估计存在不准确性,因此需要根据G-buffer中的法向信息、深度信息和meshid来进行一致性判断,当且仅当该像素的法向信息、深度信息和meshid同时满足一致性时,历史信息才会被累加。具体的,根据运动矢量,将当前帧的像素点的位置投影到前一帧中,并使用双线性插值获取前一帧中该像素点的法向信息、深度信息和meshid,然后进行一致性判断,根据判断结果更新直接光照和间接光照的颜色缓存。最后,将直接光照和间接光照的颜色信息以及对应的深度信息和法向信息分别进行融合,输入超分去噪网络,可以得到超分去噪图像,分别记为第0帧和第1帧,第0帧和第1帧为连续的两帧图像。
根据G-buffer中的运动矢量信息,通过线性运算可以得到第0帧和第1帧的中间时刻t对应的双向运动矢量,联合第0帧和第1帧的超分去噪图像与中间时刻t对应的双向运动矢量进行映射操作,可以得到初始的插帧结果。将初始的插帧结果和G-buffer中对应的深度信息和法向信息融合,然后输入双向插帧网络中,可以得到最终的插帧结果,即最终的第t帧图像。
本申请实施例的图像渲染方法结合了超分技术和插帧技术,实现在低采样值的条件下获取高帧率和给分辨率的图像,同时降低渲染时间。以上结合图9对本申请实施例的图像渲染方法做了介绍,以下结合具体示例对本申请实施例的图像渲染方法做进一步详细介绍。
(一)数据集的获取
图10示出了本申请实施例获取数据集的示意性流程图,如图10所示,本申请实施例中用于训练神经网络的模型场景数据集可以是已有的公开渲染模型的集合,也可以是自行研发构建的模型场景的集合。不过,为了保证神经网络的均衡性和训练效果的可靠性,在获取渲染场景数据源时,应该筛选出不同种类的渲染场景,例如建筑、汽车、家居、游戏、动物、人物、塑像等不同场景。除了数据源内容的丰富,还必须确保数据本身特征的丰富性,包括不同细节纹理丰富程度、不同材质、不同光照的图像等。数据集中应该尽可能包含平滑区域和复杂区域,其中复杂区域由于纹理多,噪点去除的难度比平滑区域大。在获取不同内容和不同特征的数据后,本申请实施例的方法还包括对获取的图像采取翻转、旋转、拉伸和缩小等一系列操作,从而尽可能的扩充数据集。
(二)运动矢量估计和反向投影
图11示出了本申请实施例的光栅化过程的示意性框图,如图11所示,光栅化的过程就是将三维坐标经过局部空间、世界空间、观察空间、裁剪空间、屏幕空间转换为二维坐标的过程。为了将坐标从一个坐标系变换到另一个坐标系,一般需要用到几个变换矩阵,最重要的几个变换矩阵分别是模型(Model)矩阵M
以下介绍连续两帧图像中同一像素点的运动矢量的计算过程。假设连续两帧图像I、J,像素
M=(x
则从光栅化G-buffer中得到运动矢量的计算过程如下所示:
计算前一帧转换矩阵:M
计算当前帧转换矩阵:M
计算运动矢量:M=M
其中,aPos表示局部坐标系下的三维坐标。
上述方法的局限性在于只针对刚体运动,因此,本申请实施例的方法还需要利用上述计算出的运动矢量和双线性插值的方法,找到当前帧图像I中的像素点u在前一帧J中的对应像素点v位置,以及对应的深度信息、法向量、meshid等参数。如图12所示,如果前帧图像I中的像素点u在前一帧J中的对应像素点v的位置不在顶点位置处,此时该位置的深度信息、法向量、meshid等参数不能直接获取,则可以利用双线性插值的方法,根据像素点v周围的定点P1、P2、P3、P4得到P’位置对应的法向量、深度信息、meshid等参数,作为像素点v的深度信息、法向量、meshid等参数,用于后续的一致性判断。
(三)一致性判断
本申请实施例中将当前帧中的像素点u投影到前一帧中对应位置,以获取对应位置处的像素点v,然后将像素点u和v进行一致性判断。判断一致性的公式如下所示:
(W
(W
W
其中,W
当且仅当上述三个条件成立时,认为像素点通过一致性判断,此时像素点的颜色值可以累加,累加公式为:
C
其中,C
可选的,如果像素点u和像素点v不满足一致性,则认为没有在前一帧中找到与像素点u对应的像素点,则将像素点u当前的颜色值作为更新后的颜色值。
(四)超分去噪网络
超分去噪网络的数据集的第一部分为从渲染管线中获取的直接光照图,在进行一致性判断后,累加历史缓存中的直接光照颜色值到当前的直接光照图中,公式表示如下:
C
其中,C
超分去噪网络的数据集的第二部分为从渲染管线中获取的间接光照图,在进行一致性判断后,累加历史缓存中的间接光照颜色值到当前的间接光照图中,公式表示如下:
C
其中,C
超分去噪网络数据集的第三部分为从G-buffer中获取的当前帧的深度图I
综上所述,超分去噪网络的训练数据集Dataset一共包括四个部分:
Dataset=C
图13示出了本申请实施例中利用超分去噪网络对图像进行超分去噪的示意性框图,如图13所示,以对某一像素点的直接光照图进行处理为例进行说明,对间接光照图的处理与对直接光照图的处理过程类似,具体可以参照对直接光照图的处理过程,本申请实施例不再赘述。如图13所示,首先获取当前帧缓存和前一帧缓存,其中当前帧缓存包括该像素点从当前帧到前一帧的运动矢量、像素点在当前帧的深度信息、法向信息和meshid等参数;前一帧缓存包括该像素点的历史颜色值、像素点在当前帧的深度信息、法向信息和meshid等参数。然后利用运动矢量将前一帧缓存投影到当前帧的空间,根据深度信息、法向信息和meshid等参数进行一致性判断。如果判断结果为一致,则将历史颜色值与当前颜色值累加,更新当前帧的颜色值;如果判断结果不一致,则保留当前颜色值。根据更新后的颜色值,更新历史颜色值。最后将更新后的颜色值与当前帧的深度信息、法向信息融合,将融合的结果输入超分去噪网络,从而得到超分去噪后的图像。
(五)双向插帧网络
双向插帧网络的数据集的获取包括:将超分去噪网络输出的连续三帧图像记为I
I
其中,I
将插帧结果I
图14示出了本申请实施例利用双向插帧网络对图像进行处理的示意性框图。M
M
M
得到时刻t的双向运动矢量估计结果后,分别对前一帧图像I
I
其中,I
从G-buffer中获取前一帧图像与后一帧图像的深度信息、法向信息,与初始插帧结果融合,以弥补非刚体运动或阴影运动的运动矢量估计不准确的问题。将融合后的结果输入双向插帧网络,从而得到最终的插帧结果。
上文结合图7至14对本申请实施例的图像渲染方法进行了详细的描述,下面结合图15至18对本申请实施例的图形渲染装置进行详细的介绍。应理解,图15至18的图像渲染装置能够执行本申请实施例的图像渲染方法的各个步骤,下面在对图15至18所示的图像渲染装置进行描述时,适当省略重复的描述。
图15是本申请实施例的图像渲染的装置的示意性框图,如图15所示,包括获取模块1501和处理模块1502,以下进行简要介绍。
获取模块1501,用于获取第一图像、第二图像和第三图像,第一图像、第二图像和第三图像为连续的三帧图像。
处理模块1502,用于根据第一图像更新第二图像的光照图,以得到第二图像更新后的光照图。
处理模块1502还用于将第二图像更新后的光照图输入超分去噪网络,以得到第二图像的超分去噪图像。
处理模块1502还用于根据第二图像更新第三图像的光照图,以得到第三图像更新后的光照图。
处理模块1502还用于将第三图像更新后的光照图输入超分去噪网络,以得到第三图像的超分去噪图像。
处理模块1502还用于根据第二图像的超分去噪图像和第三图像的超分去噪图像获取目标时刻的初始插帧图像,目标时刻为第二图像和第三图像之间的时刻。
处理模块1502还用于将初始插帧图像输入双向插帧网络,以得到目标时刻的插帧图像。
可选的,处理模块1502还用于执行上述图6中的S602至S607的方法的各个步骤,具体可以参照上述对于图6的描述,为了简洁,本申请实施例在此不再赘述。
图16示出了本申请实施例的超分去噪网络的训练的装置的示意性框图,如图16所示,包括获取模块1601和处理模块1602,以下进行简要介绍。
获取模块1601,用于获取多组超分去噪原始训练数据,多组超分去噪原始训练数据中的每组超分去噪原始训练数据包括连续两帧图像和连续两帧图像中后一帧图像对应的标准图像;
获取模块1601还用于获取连续两帧图像中后一帧图像的深度图、后一帧图像的法向量图和后一帧图像的光照图,后一帧图像的光照图为直接光照图或间接光照图;
处理模块1602,用于判断连续两帧图像的像素点符合一致性;
处理模块1602还用于根据连续两帧图像更新后一帧图像的像素点的颜色值,以得到后一帧图像更新后的光照图;
处理模块1602还用于将后一帧图像的深度图、后一帧图像法向量图和后一帧图像更新后的光照图融合,以得到更新后的图像;
处理模块1602还用于根据更新后的图像与标准图像,对超分去噪网络进行训练。
图17示出了本申请实施例的双向插帧网络的训练的装置的示意性框图,如图17所示,包括获取模块1701和处理模块1702,以下进行简要介绍。
获取模块1701,用于获取多组双向插帧原始训练数据,多组双向插帧原始训练数据中每组双向插帧原始训练数据包括第四图像、第五图像、第六图像,第四图像、第五图像、第六图像为连续的三帧图像;
处理模块1702,用于根据第四图像和第六图像获取第四图像和第六图像中间时刻的插帧图像;
处理模块1702还用于根据中间时刻的插帧图像和第五图像,对双向插帧网络进行训练。
图18是本申请实施例的电子设备的结构示意图。
应理解,上文中图15所示的装置1500的具体结构可以如图18所示。
图18中的电子设备包括通信模块3010、传感器3020、用户输入模块3030、输出模块3040、处理器3050、存储器3070以及电源3080。其中,处理器3050可以包括一个或者多个CPU。
图18所示的电子设备可以执行本申请实施例的图形渲染方法的各个步骤,具体地,处理器3050中的一个或者多个CPU可以执行本申请实施例的图形渲染方法的各个步骤。
下面对图18中的电子设备的各个模块进行详细的介绍。
通信模块3010可以包括至少一个能使该电子设备与其他电子设备之间进行通信的模块。例如,通信模块3010可以包括有线网络接口、广播接收模块、移动通信模块、无线因特网模块、局域通信模块和位置(或定位)信息模块等其中的一个或多个。
例如,通信模块3010能够从游戏服务器端实时获取游戏画面。
传感器3020可以感知用户的一些操作,传感器3020可以包括距离传感器,触摸传感器等等。传感器3020可以感知用户触摸屏幕或者靠近屏幕等操作。例如,传感器3020能够感知用户在游戏界面的一些操作。
用户输入模块3030,用于接收输入的数字信息、字符信息或接触式触摸操作/非接触式手势,以及接收与系统的用户设置以及功能控制有关的信号输入等。用户输入模块3030包括触控面板和/或其他输入设备。例如,用户可以通过用户输入模块3030对游戏进行控制。
输出模块3040包括显示面板,用于显示由用户输入的信息、提供给用户的信息或系统的各种菜单界面等。
可选的,可以采用液晶显示器(liquid crystal display,LCD)或有机发光二极管(organic light-emitting diode,OLED)等形式来配置显示面板。在其他一些实施例中,触控面板可覆盖显示面板上,形成触摸显示屏。
另外,输出模块3040还可以包括视频输出模块、告警器以及触觉模块等。该视频输出模块可以显示图形渲染后的游戏画面。
电源3080可以在处理器3050的控制下接收外部电力和内部电力,并且提供整个电子设备各个模块运行时需要的电力。
处理器3050可以包括一个或者多个CPU,处理器3050还可以包括一个或者多个GPU。
当处理器3050包括多个CPU时,该多个CPU可以集成在同一块芯片上,也可以分别集成在不同的芯片上。
当处理器3050包括多个GPU时,该多个GPU既可以集成在同一块芯片上,也可以分别集成在不同的芯片上。
当处理器3050既包括CPU又包括GPU时,CPU和GPU可以集成在同一块芯片上。
例如,当图18所示的电子设备为智能手机时,智能手机的处理器内部一般与图像处理相关的是一个CPU和一个GPU。这里的CPU和GPU均可以包含多个核。
存储器3070可以存储计算机程序,该计算机程序包括操作系统程序3072和应用程序3071等。其中,典型的操作系统如微软公司的Windows,苹果公司的MacOS等用于台式机或笔记本的系统,又如谷歌公司开发的基于
存储器3070可以是以下类型中的一种或多种:闪速(flash)存储器、硬盘类型存储器、微型多媒体卡型存储器、卡式存储器(例如SD或XD存储器)、随机存取存储器(randomaccess memory,RAM)、静态随机存取存储器(static RAM,SRAM)、只读存储器(read onlymemory,ROM)、电可擦除可编程只读存储器(electrically erasable programmable read-only memory,EEPROM)、可编程只读存储器(programmable ROM,PROM)、磁存储器、磁盘或光盘。在其他一些实施例中,存储器3070也可以是因特网上的网络存储设备,系统可以对在因特网上的存储器3070执行更新或读取等操作。
例如,上述存储器3070可以存储一种计算机程序(该计算机程序是本申请实施例的图形渲染方法对应的程序),当处理器3050执行该计算机程序时,处理器3050能够执行本申请实施例的图形渲染方法。
存储器3070还存储有除计算机程序之外的其他数据3073,例如,存储器3070可以存储本申请的图形渲染方法处理过程中的数据。
图18中各个模块的连接关系仅为一种示例,本申请任意实施例提供的电子设备也可以应用在其它连接方式的电子设备中,例如所有模块通过总线连接。
本申请实施例还提供一种计算机可读存储介质,该计算机可读存储介质存储有可被处理器执行的计算机程序,当计算机程序被所述处理器执行时,所述处理器执行如图6至图8中任一项所述的方法。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
- 图像渲染模型训练、图像渲染方法及装置
- 一种图像渲染方法及图像渲染装置