一种计算机人像识别系统
文献发布时间:2023-06-19 09:44:49
技术领域
本发明涉及人脸识别系统,具体涉及一种计算机人像识别系统。
背景技术
目前,现有的人像识别系统普遍基于人脸的整体特征实现,一旦人脸的整体特征产生变化,比如存在人脸的某个部位存在遮挡物,即会导致人像识别的失败,存在较大的识别盲区,同时,在用于权限身份识别时,需要另外单独配置用于实现人像是否为活体检测的硬件装置。
发明内容
本发明的目的在于提供了一种计算机人像识别系统,基于眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域进行人脸的识别,尽可能的减少了人像识别的盲区,同时无需单独配置人像是否为活体检测的硬件装置。
为实现上述目的,本发明采取的技术方案为:
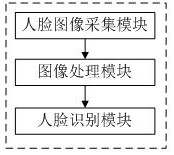
一种计算机人像识别系统,包括
人脸图像采集模块,用于获取待识别的实时动态人脸图像组;
图像处理模块,用于将人脸图像按五官所在位置分割为眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域;
人脸识别模块,首先基于Dssd_inception_V4 coco模型分别实现眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域身份信息的识别,然后基于支持向量机根据各区域的身份识别结果得出最终的人脸识别结果。
进一步地,所述人脸图像采集模块包括两种工作模式,一种是针对自由的人像检测,点击“身份识别”即可直接进入人脸图像视频采集过程,另一种是针对身份权限识别的,以随机调用人脸表情要求音频的方式获取动态人脸图像组,用户需根据人脸表情要求音频作出对应的人脸表情,该动态人脸图像组至少包括两个不同表情人脸图像。
进一步地,所述人脸图像采集模块通过记录相邻两个人脸表情图像之间产生的动态视频实现人脸图像组是否为活体人脸图像的检测,检测时,首先,调用视频取帧脚本,每隔一定帧数获取一张图像,然后通过识别相邻两张图像内载的人脸动态变化信息进行人脸图像是否为活体的检测。
进一步地,通过Dssd_inception_V4 coco模型实现相邻两张图像内载的人脸动态变化信息的识别,所述人脸动态变化信息为眼睛区域和嘴巴区域的形态变化信息,该Dssd_inception_V4 coco模型采用Dssd目标检测算法,用coco数据集预训练inception_V4深度神经网络,然后用先前准备好的不同表情变化所对应的眼睛区域变化图像集和嘴巴区域变化图像集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测眼睛区域、嘴巴区域形态变化信息的目标检测模型。
进一步地,所述图像处理模块基于Dssd_inception_V4 coco模型实现人脸图像中眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域的圈定。
进一步地,所述Dssd_inception_V4 coco模型采用Dssd目标检测算法,用coco数据集预训练inception_V4深度神经网络,然后用先前准备好的眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域目标检测模型。
进一步地,所述人脸识别模块内载的Dssd_inception_V4 coco模型采用Dssd目标检测算法,用coco数据集预训练inception_V4深度神经网络,然后用先前准备好的携带身份信息的眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域所对应的身份信息的目标检测模型。
本发明具有以下有益效果:
基于眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域和Dssd_inception_V4coco模型进行人脸的识别,尽可能的减少了人像识别的盲区;
运用于权限身份识别时,无需单独配置人像是否为活体检测的硬件装置,在图像采集同时可以实现人脸图像是否为活体的检测。
附图说明
图1为本发明实施例一种计算机人像识别系统的系统框图。
具体实施方式
为了使本发明的目的及优点更加清楚明白,以下结合实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明实施例提供了一种计算机人像识别系统,包括:
人脸图像采集模块,用于获取待识别的实时动态人脸图像组;
图像处理模块,用于将人脸图像按五官所在位置分割为眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域;
人脸识别模块,首先基于Dssd_inception_V4 coco模型分别实现眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域身份信息的识别,然后基于支持向量机根据各区域的身份识别结果得出最终的人脸识别结果。
本实施例中,所述人脸图像采集模块包括两种工作模式,一种是针对自由的人像检测,点击“身份识别”即可直接进入人脸图像视频采集过程,另一种是针对身份权限识别的,以随机调用人脸表情要求音频(比如:露齿微笑、抿嘴、嘟嘴、皱眉等)的方式获取动态人脸图像组,用户需根据人脸表情要求音频作出对应的人脸表情,该动态人脸图像组至少包括两个不同表情人脸图像;使用时,用户点击“身份识别”,人脸图像采集模块启动进行第一个人脸表情要求音频的播放,用户根据需要作出对应的表情,并点击“确认”按钮,在第一个人脸表情采集结束后,第二个人脸表情要求音频播放,值得注意的是,在第一个人脸表情采集结束后到第二个人脸表情采集完成前,人脸采集模块的图像采集功能始终处于运行状态。
本实施例中,所述人脸图像采集模块通过记录相邻两个人脸表情图像之间产生的动态视频实现人脸图像组是否为活体人脸图像的检测,检测时,首先,调用视频取帧脚本,每隔一定帧数获取一张图像,然后通过识别相邻两张图像内载的人脸动态变化信息进行人脸图像是否为活体的检测。在图像采集同时可以实现人脸图像是否为活体的检测。
本实施例中,通过Dssd_inception_V4 coco模型实现相邻两张图像内载的人脸动态变化信息的识别,所述人脸动态变化信息为眼睛区域和嘴巴区域的形态变化信息,该Dssd_inception_V4 coco模型采用Dssd目标检测算法,用coco数据集预训练inception_V4深度神经网络,然后用先前准备好的不同表情变化所对应的眼睛区域变化图像集和嘴巴区域变化图像集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测眼睛区域、嘴巴区域形态变化信息的目标检测模型。
本实施例中,所述图像处理模块首先基于Dssd_inception_V4 coco模型实现人脸图像中眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域的圈定,然后调用图像挖取程序,实现圈定区域的挖取,即可获取到对应的眼睛区域图像、眉毛区域图像、鼻子区域图像、嘴巴区域图像和人脸轮廓区域图像。
本实施例中,所述Dssd_inception_V4 coco模型采用Dssd目标检测算法,用coco数据集预训练inception_V4深度神经网络,然后用先前准备好的眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域目标检测模型。
本实施例中,所述人脸识别模块内载的Dssd_inception_V4 coco模型采用Dssd目标检测算法,用coco数据集预训练inception_V4深度神经网络,然后用先前准备好的携带身份信息的眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测眼睛区域、眉毛区域、鼻子区域、嘴巴区域和人脸轮廓区域所对应的身份信息的目标检测模型。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种计算机人像识别系统
- 一种计算机人像识别系统