机器人控制装置、方法和存储介质
文献发布时间:2023-06-19 10:55:46
技术领域
本发明涉及机器人控制装置、方法和存储介质。
背景技术
在工厂自动化(FA)领域中,已经引起了人们对使用机器人臂的工厂中的操作自动化的关注。使用机器人臂的任务的示例是拾取-放置操作。为了实现拾取-放置操作,需要创建被称为教导的用于控制机器人臂的程序。教导主要是以下处理:用2D或3D照相机拍摄工件,通过计算机视觉(Computer Vision)估计位置和形状,并将机器人臂控制成处于特定的位置和姿势(例如,专利文献1:日本特开2017-124450)。其中,估计位置和形状特别需要试验和错误,因此需要工时。然而,在工厂的实际现场中,存在具有各种形状的工件,因此需要针对各工件进行教导,并且诸如批量装载等的复杂任务使得教导更加困难。近年来,由于AI繁荣的到来,存在将AI用于机器人臂控制的技术。一个示例是非专利文献1,“LearningHand-Eye Coordination for Robotic Grasping with Deep Learning(Google)”。
然而,在专利文献1中,通过匹配3D模型来进行位置和姿势估计,但是需要使用相对昂贵的3D照相机以高精度地获取工件的位置和姿势信息。
发明内容
根据本发明的第一方面,提供一种机器人控制装置,用于控制被配置为进行预定操作的机器人,所述机器人控制装置包括:获取单元,其被配置为获取由多个摄像装置拍摄的多个图像,所述多个摄像装置包括第一摄像装置和与所述第一摄像装置不同的第二摄像装置;以及指定单元,其被配置为使用由所述获取单元获取到的多个拍摄图像作为神经网络的输入,并且被配置为基于来自神经网络的作为结果的输出来指定针对所述机器人的控制命令。
根据本发明的第二方面,提供一种机器人控制装置的控制方法,所述机器人控制装置用于控制被配置为进行预定操作的机器人,所述控制方法包括:获取由多个摄像装置拍摄的多个图像,所述多个摄像装置包括第一摄像装置和与所述第一摄像装置不同的第二摄像装置;以及使用在所述获取中获取到的多个拍摄图像作为神经网络的输入,并且基于来自神经网络的作为结果的输出来指定针对所述机器人的控制命令。
根据本发明的第三方面,提供一种计算机可读存储介质,其存储有程序,所述程序在由计算机读取并执行时,使得所述计算机执行机器人控制装置的控制方法的步骤,所述机器人控制装置用于控制被配置为进行预定操作的机器人,所述控制方法包括:获取由多个摄像装置拍摄的多个图像,所述多个摄像装置包括第一摄像装置和与所述第一摄像装置不同的第二摄像装置;以及使用在所述获取中获取到的多个拍摄图像作为神经网络的输入,并且基于作为来自神经网络的结果的输出指定针对所述机器人的控制命令。
根据本发明,通过提供可以从2D视频图像的输入进行机器人控制的神经网络,可以由机器人以直观且简单的配置进行预定的操作。
通过以下(参考附图)对典型实施例的描述,本发明的其它特征将变得明显。
附图说明
图1是根据实施例的被配置为进行神经网络的学习的控制装置的框图。
图2是实际机器人、摄像装置以及被配置为对其进行控制的控制装置的框图。
图3是示出模拟器上的机器人或实际机器人的结构的示意图。
图4A和图4B是示出由摄像装置拍摄的图像的示例的图。
图5是示出根据实施例的机器人要进行的强化学习的处理的示意图。
图6是示出根据实施例的奖励的发生条件和要获得的奖励的示例的图。
图7A和图7B是示出根据实施例的构建学习模型中的操作的流程图。
图8是根据实施例的神经网络的模型的示意图。
图9是根据实施例的神经网络的模型的示意图。
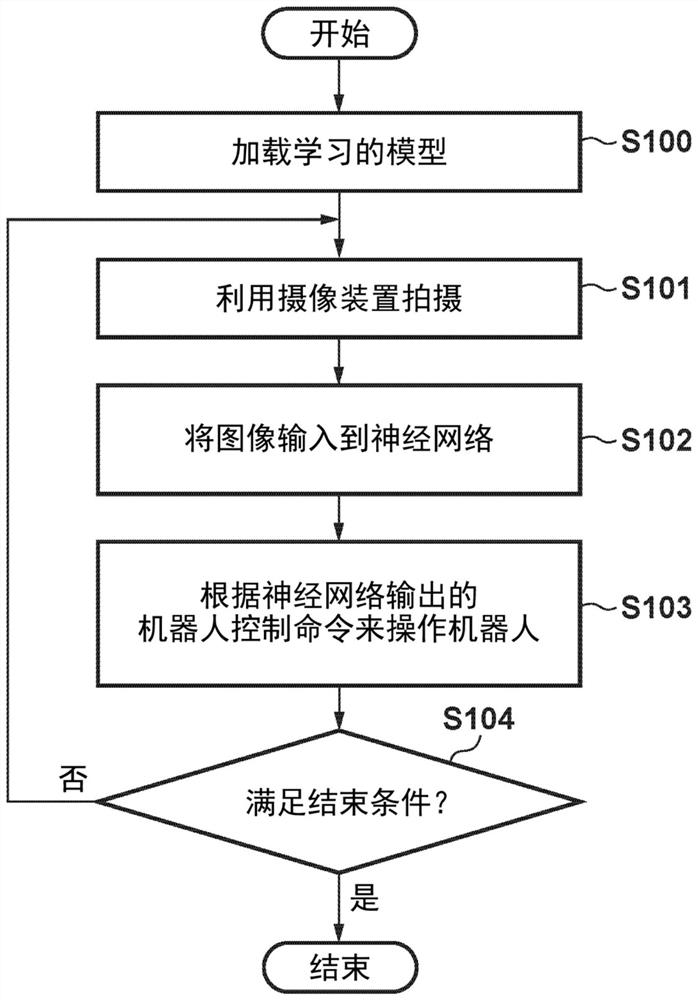
图10是根据实施例的基于学习的模型的机器人控制的流程图。
图11是示出根据实施例的创建热图的方法的示意图。
图12是示出根据实施例的各步骤的热图的示例的图。
具体实施方式
在下文中,将通过参考附图详细描述实施例。注意,以下实施例不限制根据权利要求的本发明。尽管在实施例中描述了多个特征,但是多个特征中的一些对于本发明可能不是必不可少的,并且可以任意地组合多个特征。此外,在附图中,相同或相似的组件由相同的附图标记表示,并且将省略冗余描述。
另外,实施例中引用的非专利文献2至5如下。
非专利文献2:Asynchronous Methods for Deep Reinforcement Learning(DeepMind)
非专利文献3:Reinforcement learning with unsupervised auxiliary tasks(DeepMind)
非专利文献4:Grad-CAM:Visual Explanations from Deep Networks viaGradient-based Localization(Virginia Tech,Georgia Institute of Technology)
非专利文献5:Domain Randomization for Transferring Deep NeuralNetworks from Simulation to the Real World(OpenAI)
以下要描述的两个实施例在机器学习的基本结构和执行方面是共同的,但是在学习的环境方面彼此不同。因此,将首先描述这两个实施例的概要。
在第一实施例中,将描述机器人控制系统,该机器人控制系统通过在计算机上的模拟器上进行神经网络的学习并将学习的模型应用于实际机器人来进行机器人控制。由于模拟器可以比实际机器人更快地操作,因此学习可以快速地收敛。
在第二实施例中,将描述在实际机器人上进行神经网络的学习的机器人控制系统。虽然在第一实施例中使用模拟器具有可以加速学习的优点,但是在将由模拟器学习获得的学习模型应用于实际机器人时,需要填补模拟器与实际机器人之间的差异的设计。可以在实际机器人上进行学习以消除学习与进行推断之间的环境的差异。
以上已经描述了这两个实施例的概要。现在将详细描述各实施例。注意,将省略对各实施例共同的部分的冗余描述。
在第一实施例中,将描述在机器人臂从初始状态移动并把持工件之前在拾取操作中构建并使用学习模型的处理。把持之后的操作不受特别限制,但是其示例包括移动到其它位置、对准和检查。把持之后的操作可在使用将在下文中描述的神经网络的结构中实现,或者可通过运动规划来进行移动和对准。
图1是进行神经网络的学习的控制装置的框图。控制装置10的示例包括PC或服务器。附图标记30表示存储装置,该存储装置为诸如存储(诸如应用软件或操作系统(OS)等的)各种控制程序的硬盘驱动器(HDD)等的辅助存储装置、诸如用于存储为了执行程序而临时需要的数据的随机存取存储器(RAM)等的主存储装置等等。控制单元20包括诸如中央处理单元(CPU)等的运算处理单元。另外,由于与学习相关联的计算量大,因此,例如,可以安装图形处理单元(GPU)。模拟器31是物理模拟器,可以在计算机上再现物理现象,并且作为应用软件被安装在存储装置30中。模拟精度越高,需要的计算量越多,这影响速度。也就是说,通过将模拟精度降低到一定程度,可以高速移动模拟器上的机器人。模拟器31的视频图像可在显示器上绘制和显示,或者可仅在存储器上展开。例如,还可以在云服务器上生成多个虚拟机以在不绘制模拟器的视频图像的情况下进行学习。神经网络40存储在存储装置30中,并且在学习的模型的情况下被存储为文件。神经网络40被部署在CPU或GPU的存储器上并且在进行推断或学习时使用。虚拟的机器人臂32、第一摄像装置33、第二摄像装置34和工件35存在于模拟器31上。
图2是物理机器人和摄像装置以及用于控制它们的控制装置的框图。控制装置10、控制单元20、存储装置30和神经网络40具有与图1中的控制装置10、控制单元20、存储装置30和神经网络40相同的结构。图2示出控制装置10经由诸如通用串行总线(USB)或局域网(LAN)等的接口连接至物理的机器人臂50、第一摄像装置60和第二摄像装置70的状态。
图3是示出模拟器上的机器人或物理机器人的结构的示意图。当图3被视为模拟器上的机器人的结构图时,应当理解,所示出的机器人臂100、第一摄像装置110、以及第二摄像装置120对应于图1中的机器人臂32、第一摄像装置33和第二摄像装置34。
此外,当图3被视为物理机器人的结构图时,应当理解,机器人臂100、第一摄像装置110、以及第二摄像装置120对应于图2中的机器人臂50、第一摄像装置60、以及第二摄像装置70。
此外,实际机器人100是通过铰接结构和伺服马达操作的机器人,并且包括臂。用于把持对象物的把持件101附接到机器人臂。注意,机器人臂100和把持件101的具体结构是本领域技术人员公知的,因此将省略其详细描述。
此外,第一摄像装置110和第二摄像装置120是可获取由各个二维RGB分量构成的彩色图像的照相机,但是也可包括除RGB等之外的距离信息。工件130是机器人臂100把持的对象物,并且可以获取模拟器上的位置坐标,以及可以任意地指定布置位置。
图4A和图4B是由第一摄像装置110和第二摄像装置120拍摄的图像的示例。图4A中的图像200是由第一摄像装置110拍摄的图像的示例。为了获取该图像200,第一摄像装置110安装在独立于机器人臂100的可移动部的移动的位置处,使得整个工件130和机器人臂100的一部分或整个机器人臂100进入视角,并且不受机器人臂100的移动的影响。为了观察把持件101的一部分把持工件130的状态,始终使用图4B的图像210。因此,第二摄像装置120安装在机器人臂100的预定位置(或预定部位)处。这里,当第二摄像装置120安装在机器人臂100的可移动部上时,第二摄像装置120也响应于机器人臂100的移动而移动。注意,上面已描述的机器人臂100、第一摄像装置110、第二摄像装置120和工件130可以在模拟器上以与真实物体的结构接近的结构再现。注意,通过使用作为机器人中间件的开源的机器人操作系统(ROS,http://wiki.ros.org/)、以及作为物理模拟器的开源的Gazebo(http://gazebosim.org/)等,可以利用基本上相同的控制程序来操作模拟器上的机器人和真实机器人。
图5是示出在本实施例中作为机器人进行学习时的算法的强化学习的处理的示意图。强化学习是处理代理310观察环境300中的当前状态320并确定要采取什么动作的问题的机器学习的类型。代理310选择该动作来从环境中获得奖励330。在强化学习中,通过一系列动作来学习用于获得最大奖励的策略350。在本实施例中,神经网络340用于进行强化学习,其还被称为深度强化学习。这里,环境300是安装机器人臂的实际工厂或模拟器。代理310是模拟器上的机器人臂或物理机器人臂。状态320是由第一摄像装置110和第二摄像装置120拍摄的图像。例如,状态320是图4A和图4B中所示的图像200和图像210。当满足条件时发生奖励330。
图6示出表示上述奖励的发生条件与要获得的奖励之间的关系的表400。注意,即使在实际机器人的情况下,也能够通过正向运动学确定把持件101的坐标位置。作业坐标在模拟器上是可获得的。图像200和210根据需要被调整大小和预处理,并且被输入到神经网络340。作为策略350,例如,在具有把持件的六轴机器人的情况下,限定了14次离散动作,在所述离散动作中,各轴在正方向或负方向上旋转一度,并且把持件被打开或关闭。作为神经网络340的输出的策略350是从14个动作的选项中选择哪个动作的可能性。基于该可能性,代理确定动作。
图7A和7B是示出构建学习模型中的操作的流程图。
在S10中,控制单元20将时刻T初始化为“0”。随后,在S11中,控制单元20初始化状态并开始情节(episode)。情节是从强化学习中的任务的开始到结束的一系列处理的单位。在本实施例中,机器人和工件的位置在情节的开始处于初始状态,并且情节在满足情节结束条件时结束。情节结束条件是诸如当代理使任务成功时或当发生错误时等。错误例如是机器人臂与自身或地板碰撞的情况等。状态的具体初始化是将机器人臂100移动到预定位置,将工件130放置在预定位置中,并将所获得的奖励的累积总数设置为“0”。在这种情况下,机器人臂100可以返回到固定位置,但是当工件130随机地配置在臂到达的范围内时,神经网络可以进行学习以能够考虑工件在输入图像中的位置并选择动作。在S12中,控制单元20将步骤数t初始化为“0”。
在S13中,控制单元20使第一摄像装置110和第二摄像装置120拍摄图像,并接收所拍摄的图像。在S14中,控制单元20将所拍摄的图像输入到神经网络340。在输入中,控制单元20将所拍摄到的各图像调整大小为具有例如84×84等的像素大小的缩小图像。在S15中,控制单元20根据由神经网络340输出的控制命令操作机器人臂100。作为神经网络的输出的机器人的控制命令是softmax函数的输出,并且由哪个轴要被移动的可能性来表示。根据该可能性操作机器人。注意,神经网络的输出不需要是控制命令本身,或者可以基于神经网络的输出来判断要使用哪个控制命令。例如,这通过保持神经网络的输出与控制命令彼此相关联的表等而成为可能。以这种方式,只要控制单元20能够基于神经网络的输出来识别控制命令,则可以采用各种形式。
在S16中,控制单元20判断是否满足奖励提供条件(见图6中的表400)。当判断为满足条件时,控制单元20使处理进入S17。在S17中,控制单元20提供奖励(更新奖励)。作为奖励,根据图6中的表400提供得分。例如,在实现表400中的编号1至5的相应项的情况下,可以最终获得“+5”的总奖励。在S18中,控制单元20使时刻T和步骤数t各自递增。
在S19中,控制单元20判断时刻T是否变为等于或大于预定阈值Th_a。当时刻T等于或大于阈值Th_a时,控制单元20存储作为学习的模型的神经网络的权重。这里,作为S19中的阈值Th_a,指定诸如10的8次幂的大值。这里,这是因为由于学习何时收敛是不可预测的,因此将大值指定为阈值以使得学习循环重复。然而,也可以判断为学习已经收敛并结束学习。
另一方面,在S19的判断结果指示时刻T小于阈值Th_a的情况下,控制单元20使处理进入S21。在S21中,控制单元20判断步骤数t是否等于或大于阈值Th_b。当步骤数t等于或大于阈值Th_b时,控制单元20使处理进入S22。在该S22中,控制单元20批量地进行多个步骤的学习。步骤数t的阈值Th_b是进行批量学习的单位,并且例如被指定为“20”。此后,控制单元20使处理返回到S12。
另外,在S21的判定结果指示步骤数t小于阈值Th_b的情况下,控制单元20使处理进入S23。在S23中,控制单元20判断是否满足情节结束条件。当控制单元20判断为不满足情节结束条件时,控制单元20使处理返回到S13。此外,当判断为满足情节结束条件时,控制单元20使处理进入S24。在S24中,控制单元20进行神经网络的学习。此时的学习的批量大小是步骤数t。在神经网络的学习中,通过被称为反向传播的技术调整权重值以减小各感知器的输出的误差。学习的详情被省略,因为它们是已知的。
这里,通过使用图8说明神经网络的结构的概要。在本实施例中,使用在非专利文献3中提出的无监督强化和辅助学习(UNREAL)的模型或者修改的模型作为神经网络的模型。在非专利文献3中已经描述了详情,因此将仅描述概要。UNREAL是扩展了非专利文献2中提出的被称为异步优势动作评价器(asynchronous advantage actor-critic)(A3C)的模型的神经网络。A3C被配置为如下。
附图标记401和402表示提取图像特征量并被称为卷积(Conv)层的层,并且这些层将具有预定参数的滤波器应用于输入图像数据410。滤波器中的预定参数对应于神经网络的权重。附图标记403表示全连接(FC)层,并且全连接层将已通过卷积层提取了特征部分的数据组合到一个节点。具有附图标记404的长短期记忆(LSTM)是一种用以学习和保持时间序列数据的时间步长之间的长期依赖性的被称为长短期记忆神经网络的递归神经网络。附图标记405表示全连接层,并且其输出通过使用softmax函数而转换成可能性以用作策略。策略是在状态中采取任何动作的可能性。附图标记406表示全连接层,输出是状态值函数,并且是以状态为起点要获得的奖励的预测值。虽然上面已经描述了A3C结构,但是UNREAL被配置有除了A3C之外的三个辅助任务。附图标记420表示重放缓冲器,其保持最新几个步骤数的图像、奖励和动作。三个辅助任务的输入是从重放缓冲器420获得的图像。
辅助任务之一是奖励预测407,其根据已经获得奖励的过去信息估计即时奖励。通常,强化学习具有所谓的稀疏奖励问题,即代理只能从可以获得奖励的经验中进行学习,因此只有当任务成功时才能获得奖励。例如,同样在本实施例中,即使从初始状态起对机器人臂100进行了一步操作,也不能获得奖励。通过在这样的环境下使用奖励预测的任务,从重放缓冲器中检索并生成任意发生奖励的事件。辅助任务中的第二个是值功能重放,并且具有与全连接层406的输出相同的功能,并且输入图像从重放缓冲器输入。然后,第三个是像素控制408,并且学习一种动作,使得输入图像发生很大变化。输出是动作值函数,并且估计在采取动作之后像素的变化量。
图8中的输入图像410是由第一摄像装置110和第二摄像装置120拍摄的两个图像的合成图像,并且示出合成图像被输入到作为输入层的一个卷积层401。
图9示出第一摄像装置110和第二摄像装置120拍摄并获得的图像分别作为输入图像510和520输入到卷积层501和503的示例。然后,卷积层502和504的输出在全连接层505处进行组合。全连接层505的输入/输出大小是全连接层403的输入/输出大小的两倍。用于输出奖励预测的全连接层506的输入大小是全连接层407的输入大小的两倍,以及卷积层502和504的输出的组合被输入到全连接层506。像素控制507是估计输入图像520的变化量的任务。这是因为输入图像520的像素的变化被认为与任务的成功有关,因为像素控制具有选择动作以使得输入图像的像素值变大的特征,并且在工件进入利用第二摄像装置的视频图像的视角时,任务接近成功。注意,也可以在图8和图9的神经网络这两者中学习任务。另外,该模型仅是示例,并且只要模型具有图像的输入和针对机器人的控制命令的输出,也可以使用其它结构。
以上述方式,学习输入数据的特征,并且递归获得用于从输入估计针对机器人臂的控制命令的学习模型。
本第一实施例将已经在模拟器上学习的神经网络的学习的模型应用于实际机器人。
图10是当加载学习的模型以控制实际机器人时的流程图。
在S100中,控制单元20加载已在图7A的S20中存储的学习模型。在S101中,控制单元20使得通过第一摄像装置60和第二摄像装置70来拍摄图像。在S102中,控制单元20将通过图像拍摄所获得的拍摄图像输入到神经网络340。然后,在S103中,控制单元20根据神经网络340输出的机器人控制命令来操作物理机器人臂50。在S104中,控制单元20判断是否满足结束条件。当判断为“否”时,控制单元20使处理返回到S101。结束条件的示例是通过诸如计算机视觉等的识别技术检查在配置要进行拾取的工件的带输送器上或盒子中是否存在工件、并且不存在工件的情况。然而,结束条件可以与此不同。
在本第一实施例中,已经将模拟器学习的模型照原样应用于实际机器,但是模拟器上的视频图像的呈现与真实世界中的视频图像的呈现在接收光的方式或物体的质感等方面并不完全相同。因此,即使在S102中将真实世界中的图像输入到神经网络340时,也可能不会输出期望的控制命令。在非专利文献5中的称为域随机化的方法中,通过改变在模拟器上进行学习时的各种各样的变量中的诸如背景、工件的质感、光源的位置、亮度、颜色、照相机的位置以及噪声等的参数,可以构建适应真实世界中的视频图像的强大的广义神经网络。在本第一实施例的情况下,例如,通过针对各情节随机更改这些参数以及更改环境的呈现,可以构建减小了模拟器上和真实世界中的视频图像之间的呈现差异的神经网络的模型。
根据上述操作,可以通过简单地仅将二维摄像装置的视频图像输入到神经网络来控制机器人控制。
这里,通过使用指示神经网络的卷积层在图像中关注的位置的被称为Grad-CAM(非专利文献4)的技术,可以使图像中的神经网络关注的位置可视化以进行判断。深度学习通常在神经网络内具有黑盒并且不容易分析。此外,即使任务成功/失败,也很难理解任务为什么成功/失败。因此,使神经网络的关注点(或关注区域)可视化非常重要。通常,卷积层保留空间信息,该信息在全连接层中丢失。然后,由于随着阶段在卷积层中进一步向后侧前进,更多的抽象信息被保持,因此在Grad-CAM中使用卷积层中的最后层的信息来创建热图。如在非专利文献4中描述的详情,将省略其描述,但是将简要描述将Grad-CAM应用于神经网络的方法,即在本实施例中使用的方法。
图11是示出创建热图的方法的图。当基于图8中的神经网络创建热图时,在从神经网络输出策略之后,创建一个热矢量,在该热矢量中将实际采用的动作设置为1,将其它动作设置为零,并且进行反向传播。进行反向传播直到卷积层610计算梯度640。卷积层610针对输入图像600的输出是特征量图630,并且计算特征量图630和梯度640的组合数的乘积,使乘积相加并使其通过激活函数650以创建热图660。图12是示出针对各步骤的热图的示例的图。虚线圆表示热图中的受到关注的区域。当观看针对输入图像700的热图710时,在多个步骤中的初始步骤中,在第一摄像装置110的视频图像中臂前端和工件受到关注。在随后的步骤中,可以看到,当工件进入第二摄像装置120的视角时,第二摄像装置120的视频图像中的该工件受到关注。由此,可以看到主要根据第一摄像装置110的视频图像来选择动作,直到臂接近工件为止,并且根据第二摄像装置120的视频图像来选择动作,直到臂接近工件之后工件被把持为止,并且可以说机器人臂采取了预期的动作。
接着,将描述第二实施例。注意,在第二实施例和第一实施例中,基本结构和操作是共同的,因此将省略这些点的冗余描述。在第二实施例中,神经网络的学习也利用实际机器。因此,不需要模拟器上的学习所需的域随机化。同样关于奖励,在模拟器上,容易确定工件和末端执行器之间的距离,但实际上,末端执行器的绝对位置是根据运动学确定的,不能机械地确定工件的位置,因此手动放置工件,并且需要诸如输入位置等的操作。当在第一实施例中在实际机器中进行微调时,这是相同的。
根据上述操作,可以通过简单地仅将二维摄像装置的视频图像输入到神经网络来控制机器人控制。
在上述实施例中,已经描述了移动机器人臂以把持工件的所谓的拾取操作,但是本发明也可以应用于其它操作。例如,可以将不同的作业装置附接到机器人臂的前端,例如,以应用于焊接、测量、测试和手术等。
本发明的实施例还可以通过如下的方法来实现,即,通过网络或者各种存储介质将执行上述实施例的功能的软件(程序)提供给系统或装置,该系统或装置的计算机或是中央处理单元(CPU)、微处理单元(MPU)读出并执行程序的方法。
虽然已经参考典型实施例描述了本发明,但是应当理解,本发明不限于所公开的典型实施例。所附权利要求的范围应被赋予最宽泛的解释,以涵盖所有这样的修改以及等同的结构和功能。
- 机器人控制装置、学生机器人、教师机器人、机器人控制方法、学习支援系统以及存储介质
- 机器人的控制装置、机器人的控制方法、计算机可读存储介质及机器人