一种基于PCA的加速随机森林训练的视网膜分层方法
文献发布时间:2023-06-19 10:57:17
技术领域
本发明涉及图像处理技术领域,具体而言,涉及一种基于PCA的加速随机森林训练的视网膜分层方法。
背景技术
光学相干断层扫描(Optical Coherence tomography,OCT)技术是一项无创的眼底视网膜图像采集技术,也是目前眼科疾病的研究和诊断的基础之一。由于一些疾病如糖尿病、多发性硬化等会使病患的视网膜层厚度改变,病患的视网膜层厚度与正常视网膜层厚度有较明显的差异,因此视网膜层厚度是研究眼睛病理的一项重要指标,对视网膜分层算法的研究也是十分必要的。而在各种分层算法中,随机森林算法误差较低,与基于梯度的算法和主动轮廓法相比,其有着较强的稳定性。但在使用随机森林算法时,由于可选取的样本特征数量较多,算法所需时间较多,不可避免的导致了信息的丢失,其分层效率有待提高。
发明内容
基于此,为了解决在使用随机森林算法时,由于可选取的样本特征数量较多,算法所需时间较多,不可避免的导致了信息的丢失,其分层效率有待提高的问题,本发明提供了一种基于PCA的加速随机森林训练的视网膜分层方法,其具体技术方案如下:
一种基于PCA的加速随机森林训练的视网膜分层方法,包括如下步骤:
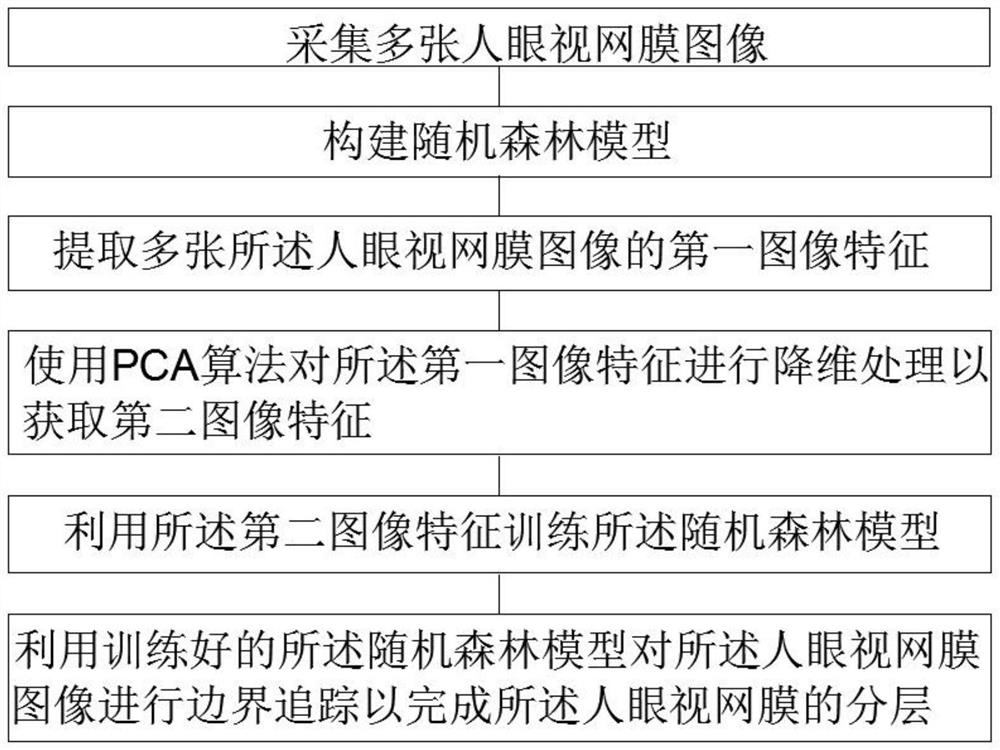
采集多张人眼视网膜图像;
构建随机森林模型;
提取多张所述人眼视网膜图像的第一图像特征;
使用PCA算法对所述第一图像特征进行降维处理以获取第二图像特征;
利用所述第二图像特征训练所述随机森林模型;
利用训练好的所述随机森林模型对所述人眼视网膜图像进行边界追踪以完成所述人眼视网膜的分层。
上述基于PCA(Principal Component Analysis,主成分分析)的加速随机森林训练的视网膜分层方法通过PCA重构随机森林模型所选取的视网膜特征,提取所述人眼视网膜图像的主要特征维度,降低了特征信息之间的冗余,减少了输入随机森林模型的特征信息,使得随机森林模型中的决策树每次都能得到更多的信息,减少了决策树的高度,提高了随机森林模型的执行效率。
即是说,上述基于PCA的加速随机森林训练的视网膜分层方法在最大程度保留特征信息的同时降低数据维度,减少了低权重的信息,提高了维度间的独立性,提高了随机森林模型对于视网膜图像的分层效率。
进一步地,所述第一图像特征共有27个视网膜维度特征,27个所述视网膜维度特征包括9个领域特征、3个角度的一阶和二阶高斯各向异性滤波与2个像素尺度的全部组合、3个环境特征、x维度特征、y维度特征以及z维度特征。
进一步地,所述随机森林模型的决策树数量为60,所述随机森林模型的随机特征数为10。
进一步地,多张所述人眼视网膜图像共分为40组,其中30组所述人眼视网膜图像为训练集,剩余10所述人眼视网膜图像为预测集,每组所述人眼视网膜图像共有128张。
进一步地,在提取多张所述人眼视网膜图像的第一图像特征前,先对以BM边界为基准线将所述人眼视网膜图像压平。
进一步地,所述利用训练好的所述随机森林模型对所述人眼视网膜图像进行边界追踪的具体方法包括如下步骤:
分别选取所述人眼视网膜图像每一列像素点范围内的最高预测点为当前行预测点;
若所述人眼视网膜图像其中一列像素点范围内的随机森林最高点不在所有当前预测点中,则采用三次样条拟合插值法添加相应列的最高预测点;
将所有当前预测点依次连接起来以对所述人眼视网膜图像进行边界追踪。
进一步地,所述人眼视网膜图像的像素大小为784×1024。
进一步地,所述利用所述第二图像特征训练所述随机森林模型的具体方法包括如下步骤:
在30组所述训练集中随机选取2组所述人眼视网膜图像;
在2组所述人眼视网膜图像中选择12张人眼视网膜图像进行标签;
其中,每个标签共有11层。
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,当所述计算机程序被处理器执行时实现如上述所述的基于PCA的加速随机森林训练的视网膜分层方法。
附图说明
从以下结合附图的描述可以进一步理解本发明。图中的部件不一定按比例绘制,而是将重点放在示出实施例的原理上。在不同的视图中,相同的附图标记指定对应的部分。
图1是本发明一实施例中一种基于PCA的加速随机森林训练的视网膜分层方法的整体流程示意图;
图2是本发明一实施例中一种基于PCA的加速随机森林训练的视网膜分层方法的人眼视网膜图像效果示意图;
图3是本发明一实施例中一种基于PCA的加速随机森林训练的视网膜分层方法的对人眼视网膜图像进行分层后的效果示意图。
具体实施方式
为了使得本发明的目的、技术方案及优点更加清楚明白,以下结合其实施例,对本发明进行进一步详细说明。应当理解的是,此处所描述的具体实施方式仅用以解释本发明,并不限定本发明的保护范围。
需要说明的是,当元件被称为“固定于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的,并不表示是唯一的实施方式。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施方式的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
本发明中所述“第一”、“第二”不代表具体的数量及顺序,仅仅是用于名称的区分。
如图1所示,本发明一实施例中的一种基于PCA的加速随机森林训练的视网膜分层方法,包括如下步骤:
采集多张人眼视网膜图像,如图2所示;
构建随机森林模型;
提取多张所述人眼视网膜图像的第一图像特征;
使用PCA算法对所述第一图像特征进行降维处理以获取第二图像特征;
利用所述第二图像特征训练所述随机森林模型;
利用训练好的所述随机森林模型对所述人眼视网膜图像进行边界追踪以完成所述人眼视网膜的分层,如图3所示。
上述基于PCA的加速随机森林训练的视网膜分层方法通过PCA重构随机森林模型所选取的视网膜特征,提取所述人眼视网膜图像的主要特征维度,降低了特征信息之间的冗余,减少了输入随机森林模型的特征信息,使得随机森林模型中的决策树每次都能得到更多的信息,减少了决策树的高度,提高了随机森林模型的执行效率。
即是说,上述基于PCA的加速随机森林训练的视网膜分层方法在最大程度保留特征信息的同时降低数据维度,减少了低权重的信息,提高了维度间的独立性,提高了随机森林模型对于视网膜图像的分层效率。
随机森林模型是一个包含多个决策树的分类器,通过统计随机森林模型中的所有投票的结果得出一个概率,最后确定分类的结果。决策树的构成采取有放回特征的抽样子数据集来构成决策树。决策树又分为根节点(包含样本全集),叶节点(对应决策结果)和内部节点(对应测试属性)。决策树如果由好的分类能力,则需要大的信息熵,其公式包括P(X=χ
设有随机变量(X,Y),其联合概率分布P(X=xi,Y=yi)=pij,i=1,2…,n;j=1,2…,m。条件熵H(X|Y)表示已知道随机变量X的条件下随机变量Y的不确定性,或者定义为在X给定的条件下Y条件的概率分布的熵对X的数学期望,即
假设特征A对训练集D的信息增益为g(D|A),定义训练集D的概念熵H(D)与综合特征A给定的条件下D的经验条件熵和H(D|A)之差,即g(D|A)=H(D)-H(D|A)。
所述随机森林模型以最大信息增益作为划分数据可得到最好的划分结果。
生成决策树的特征选择方法包括如下步骤:
第一步,计算所述训练集(或者子集)的每个特征的信息熵。
第二步,选择信息增益最大的特征并所述信息增益最大的特征划分数据。
第三步,对子节点递归的调用上面方法,构建决策数。
第四步,直到没有特征可以选择或者信息增益很小为止,得到最终的决策树。
第五步,通过构建多个决策树分类器形成最后的森林分类器模型。
所述PCA对于信息表示采用方差来表述,一个字段的方差可以看作每个元素和字段的均值的差的平方和的均值,即
为了在坐标轴上计算方便,所述PCA将每个字段减去其均值,使得其均值为0,故而一个字段的方差可以表示为
实际上所述PCA被表示为寻找一个维基,使得所有数据变换到这个基上后的方差值最大,且每个维度在下一个维度的选取上需要垂直。假设已经让所有的字段均值为0,则
为使
此时,协方差和方差就被统一到了一个矩阵熵,假设这个矩阵为
设最后优化后的矩阵为Y,且Y的协方差矩阵为D,则
矩阵降维就是寻找正交变换基,变为对角矩阵,且矩阵对角元素按照从大到小排列,然后用前几行组成的矩阵乘以原矩阵就得到了降维矩阵并且满足优化条件。所以,所述PCA将协方差矩阵对角化后,取前面特征值大的特征向量乘以原来的矩阵,得到的就是降维后的矩阵。如此,可以保留最大信息且降维。
通过选取降维后的PCA矩阵,然后乘上原来提取的27维特征,就可以得到降维后的特征。而经过PCA重构的特征矩阵,保留了将近98%的信息比。即是说,利用经过PCA重构后的所述随机森林模型,可以保证视网膜分层结果的精度,减少所述随机森林模型食物训练时间。
在其中一个实施例中,所述第一图像特征共有27个视网膜维度特征,27个所述视网膜维度特征包括9个领域特征、3个角度的一阶和二阶高斯各向异性滤波(-10°,0°,10°)与2个像素尺度σ(x_1,y_1)=(5,1)以及σ(x_2,y_2)=(10,2)的全部组合、3个环境像素特征、x维度特征、y维度特征以及z维度特征。其中,环境像素特征为前像素点下15,25,35位置的11×11大小的梯度平均值。
在其中一个实施例中,所述随机森林模型的决策树数量为60,所述随机森林模型的随机特征数为10。
在其中一个实施例中,在使用PCA算法对所述第一图像特征进行降维处理前,先设定PCA算法降维后的特征数目,以保证随机森林的加速效果以及精度。
在其中一个实施例中,所述PCA算法采用平均绝对误差作为训练精度的测量。
在其中一个实施例中,多张所述人眼视网膜图像共分为40组,其中30组所述人眼视网膜图像为训练集,剩余10所述人眼视网膜图像为预测集,每组所述人眼视网膜图像共有128张。
在其中一个实施例中,在提取多张所述人眼视网膜图像的第一图像特征前,先对以BM(Bruch's membrane,布鲁赫膜)边界为基准线将所述人眼视网膜图像压平,以方便提取多张所述人眼视网膜图像的第一图像特征,保证信息的一致性,提高视网膜分层结构的准确度。
在其中一个实施例中,所述利用训练好的所述随机森林模型对所述人眼视网膜图像进行边界追踪的具体方法包括如下步骤:
分别选取所述人眼视网膜图像每一列像素点范围内的最高预测点为当前行预测点;
若所述人眼视网膜图像其中一列像素点范围内的随机森林最高点不在所有当前预测点中,则采用三次样条拟合插值法添加相应列的最高预测点;
将所有当前预测点依次连接起来以对所述人眼视网膜图像进行边界追踪。
在其中一个实施例中,所述利用训练好的所述随机森林模型对所述人眼视网膜图像进行边界追踪的具体方法包括如下步骤:
分别设定第一搜索范围、第二搜索范围、第三搜索范围……第N搜索范围,并根据所述第一搜索范围、第二搜索范围、第三搜索范围……第N搜索范围获取相应的视网膜分层;
使用三次样条插值对视网膜分层中的当前预测点进行曲线拟合,对所述人眼视网膜图像进行边界追踪。
对于每个像素点随机森林投票的结果,无法将前后像素点都连接起来。通过采用三次样条插值法来拟合当前预测点,可使得分层结果最大程度上接近真实分界结果。同时,在找到某一条视网膜分层后,以该视网膜分层为基准,上下各屏蔽若干像素点,如此可以保证最终视网膜分层不会重合,提高了可视化结果和精度。
在其中一个实施例中,所述第一搜索范围对应的视网膜分层为视网膜肌样体带层。由于在所有视网膜分层中,视网膜肌样体带层最为明显。通过首先获取视网膜肌样体带层,可以提高所述基于PCA的加速随机森林训练的视网膜分层方法的工作效率。
在其中一个实施例中,所述人眼视网膜图像的像素大小为784×1024。
在其中一个实施例中,所述利用所述第二图像特征训练所述随机森林模型的具体方法包括如下步骤:
在30组所述训练集中随机选取2组所述人眼视网膜图像;
在2组所述人眼视网膜图像中选择12张人眼视网膜图像进行标签;
其中,每个标签共有11层。
具体而言,即每次在30组所述训练集中随机选取2组所述人眼视网膜图像,然后在2组所述人眼视网膜图像中选择12张人眼视网膜图像进行标签以利用所述第二图像特征训练所述随机森林模型,一共对所述随机森林模型进行15次训练,最终得出平均结果并完成所述随机森林模型的训练。
在其中一个实施例中,本发明提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,当所述计算机程序被处理器执行时实现如上述所述的基于PCA的加速随机森林训练的视网膜分层方法。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 一种基于PCA的加速随机森林训练的视网膜分层方法
- 一种基于OCT图像的视网膜分层方法