一种基于无监督生成对抗网络的模糊图像复原方法
文献发布时间:2023-06-19 11:11:32
技术领域
本发明涉及计算机数字图像处理领域,尤其涉及一种基于无监督生成对抗网络的模糊图像复原方法。
背景技术
在日常摄影、空间遥感观测、医学影像检测等应用领域中,经常会由于目标物体与成像系统之间的相对运动而造成图像模糊,影响到图像的细节分辨能力,降低其使用价值。因此,设计相应的模糊图像复原算法,提升图像的分辨率显得尤为重要。
传统的模糊图像复原方法一般通过对模糊核进行估计后与模糊图像进行反卷积操作进而得到清晰图像,但是此类方法估计的模糊核通常无法表现真实的模糊情况,并且对噪声敏感。此外,目前比较流行的基于条件生成对抗网络的有监督学习网络往往受限于训练数据集,大量地收集有监督的模糊-清晰训练数据集费时费力,且容易出现网络泛化性不足的问题。
发明内容
发明目的:本发明的目的是提供一种基于无监督生成对抗网络的模糊图像复原方法,能够利用无监督的训练数据集对本发明的网络进行充分训练,使得网络的生成器具备复原模糊图像的能力,实现对模糊图像的复原。
技术方案:一种基于无监督生成对抗网络的模糊图像复原方法,包括如下步骤:
步骤1:构建无监督数据集,分别为模糊图像域图像数据集、清晰图像域图像数据集,分别记为S
步骤2:在生成对抗网络框架下,设置两条方向互逆的对偶生成路径,分别为:输入模糊图像-生成清晰图像-重构模糊图像(记为A方向),输入清晰图像-生成模糊图像-重构清晰图像(记为B方向),每条生成路径均使用生成器网络G
步骤3:在上述的生成方向上引入各自的判别器D
步骤4:引入L2像素重构损失以及感知损失,配合步骤3中所述的对抗损失构建网络的整体目标损失函数,并随机初始化网络参数;
步骤5:利用无监督数据集对网络进行前向计算,得到生成器网络和判别器网络输出的损失值;
步骤6:固定判别器的网络参数,利用优化器更新生成器网络的参数;
步骤7:固定生成器的网络参数,利用优化器更新判别器的网络参数;
步骤8:循环执行步骤5、步骤6和步骤:直至步骤5中计算的损失值收敛,此时可得到生成器网络参数的局部最优解,利用该训练完备的生成器,即可解算出模糊图像的复原图像估计值。
进一步地,步骤2中,A方向与B方向处于同等的地位,均用于约束网络的参数学习。其中,生成器G
进一步地,步骤2中G
步骤2.1:为了使得网络具有更好的特征抽取能力,本网络采用了在ImageNet上预训练过的Inception-resnet-v2网络结构以及其训练好的参数作为特征抽取的骨干网络,进行迁移学习,Inception-resnet-v2中包含了上述提及的用于拓展网络宽度的inception模块以及用于加深网络深度的res-block模块;
步骤2.2:在特征金字塔的构造方面,将Inception-resnet-v2网络的特征输出从底层到顶层进行截取,共分成5段,构成金字塔的5个层级,分别命名为enc0,enc1,enc2,enc3,enc4。其中enc0的特征尺寸最大,但是通道数最少;enc4的特征尺寸最小,但是通道数最多。除了enc0,对其余各层级进行横向连接并在通道上串接,之后与enc0在进行叠加,继而通过上采样以及卷积操作得到尺寸、通道数与输入图像相同的学习图像;
步骤2.3:通过全局残差学习,将输入图像与学习图像在通道上进行叠加,得到最终的生成清晰图像。
进一步地,步骤2中,基于res-6-blocks网络改进得到生成器G
进一步地,G
进一步地,步骤3中的判别器分为D
第一部分的作用是对输入图像进行尺寸减半、通道倍增操作。输入图像通过2个卷积模块后,尺寸缩减了4倍,通道的数量增加到原有的4倍。其中,每个卷积模块都包含了1个步长为2的卷积层、1个归一化层以及1个激活函数层LeakyReLU函数。
第二部分的作用是对输入图像进行通道倍增操作,尺寸基本不变。输入图像经过该卷积模块后,尺寸基本不变,而通道数翻倍。该卷积模块由1个步长为1的卷积层、1个归一化层以及1个激活函数层LeakyReLU函数。
第三部分的作用是将通道数量转换为1,得到一个通道数量为1的输出特征图。该部分仅由一个卷积层构成,其中的输出滤波器数量为1,步长为1。
进一步地,步骤4中A方向的损失函数主要由对抗损失与重构损失组成,计算步骤如下:
步骤4.1.1:对抗损失指的是生成器G
步骤4.1.2:重构损失用于衡量重构模糊图像与原始输入的模糊图像之间的损失值。传统的L1和L2损失无法使重构损失收敛到一个有意义的状态,因此此处采用内容损失作为其重构损失。内容损失由两部分损失分量组成:视觉感知损失和L2损失。其中,视觉感知损失是由在ImageNet数据集上训练过的VGG-16分类网络给出的,将G
进一步地,步骤4中B方向的损失函数主要由对抗损失与重构损失组成,具体计算步骤如下:
步骤4.1.2:此对抗损失指的是生成器G
步骤4.2.2:此重构损失用于衡量重构清晰图像与原始输入清晰图像之间的损失值,采用内容损失作为其重构损失,内容损失包括视觉感知损失、L2损失。其中,视觉感知损失是由在ImageNet数据集上训练过的VGG-16分类网络给出的,将G
进一步地,步骤5中的前向计算具体包括:将模糊数据集与清晰数据集分别输入到步骤2和步骤3中A和B方向上的网络中,直至计算出步骤4中对应的损失值。
有益效果:与现有技术相比,本发明具有如下显著的优点:本发明在构建数据集时,不需要费时费力地构建匹配的模糊-清晰训练数据集,只需构建两个不同风格的图像域:模糊图像域以及清晰图像域,两个域之间的图像不需要一一对应。利用该训练数据集,对本发明提出的无监督网络进行训练,最终得到训练完毕的去模糊生成器。将模糊图像输入到该生成器即可得到高质量的复原图像。本发明的方法极大地减少了数据集构建的工作量,具有切实的实用价值。
附图说明
图1为本发明基于无监督生成对抗网络的模糊图像复原方法的流程图;
图2为本发明中去模糊方法的框架原理图;
图3为本发明中去模糊生成器G
图4为本发明中模糊生成器G
图5为本发明中判别器的网络结构图;
图6为本发明中去模糊图像与模糊图像的效果对比图。
具体实施方式
下面结合附图和实施例对本发明的技术方案做进一步的详细说明。
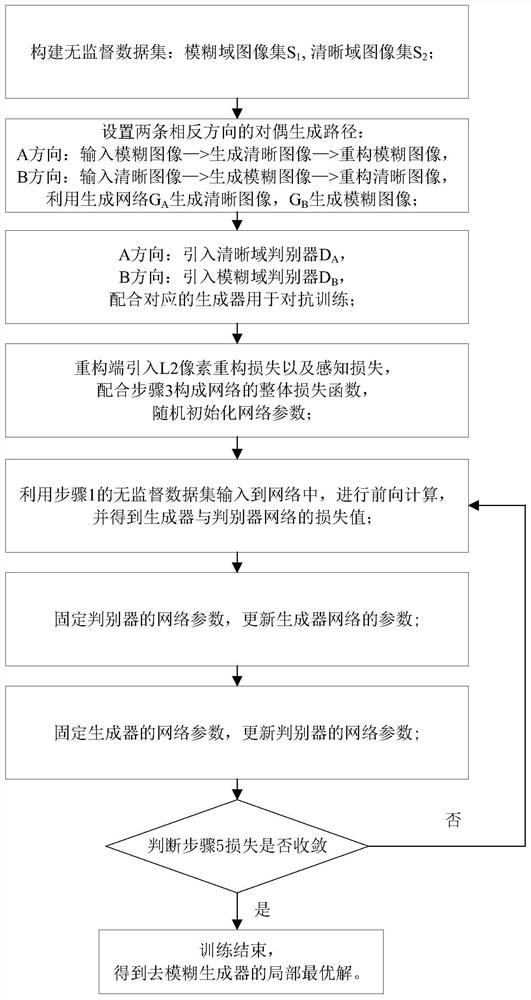
如图1,本发明的一种基于无监督生成对抗网络的模糊图像复原方法,包括如下步骤:
步骤1,构建无监督数据集,分别为模糊图像域图像数据集、清晰图像域图像数据集,分别记为S
步骤2,如图2所示,在生成对抗网络框架下,设置两条方向互逆的对偶生成路径,分别为:输入模糊图像-生成清晰图像-重构模糊图像(记为A方向),输入清晰图像-生成模糊图像-重构清晰图像(记为B方向)。每条生成路径均使用生成器网络G
步骤2-1,为了使得网络具有更好的特征抽取能力,本网络采用了在ImageNet上预训练过的Inception-resnet-v2网络结构以及其训练好的参数作为特征抽取的骨干网络,进行迁移学习,Inception-resnet-v2中包含了上述提及的用于拓展网络宽度的inception模块以及用于加深网络深度的res-block模块;
步骤2-2,在特征金字塔的构造方面,将Inception-resnet-v2网络的特征输出从底层到顶层进行截取,共分成5段,构成金字塔的5个层级,分别命名为enc0,enc1,enc2,enc3,enc4。其中enc0的特征尺寸最大,但是通道数最少;enc4的特征尺寸最小,但是通道数最多。除了enc0,对其余各层级进行横向连接并在通道上串接,之后与enc0在进行叠加,继而通过上采样以及卷积操作得到尺寸、通道数与输入图像相同的学习图像;
步骤2-3,通过全局残差学习,将输入图像与学习图像在通道上进行叠加,得到最终的生成清晰图像。
生成器G
步骤3,在上述的生成方向上引入各自的判别器,用于图像所属域的判定,并配合生成器用于对抗训练。判别器分为D
第一部分的作用是对输入图像进行尺寸减半、通道倍增操作。输入图像通过2个卷积模块后,尺寸缩减了4倍,通道的数量增加到原有的4倍。其中,每个卷积模块都包含了1个步长为2的卷积层、1个归一化层以及1个激活函数层LeakyReLU函数。
第二部分的作用是对输入图像进行通道倍增操作,尺寸基本不变。输入图像经过该卷积模块后,尺寸基本不变,而通道数翻倍。该卷积模块由1个步长为1的卷积层、1个归一化层以及1个激活函数层LeakyReLU函数。
第三部分的作用是将通道数量转换为1,得到一个通道数量为1的输出特征图。该部分仅由一个卷积层构成,其中的输出滤波器数量为1,步长为1。
步骤4,引入L2像素重构损失以及感知损失,配合步骤2中所述的对抗损失构建网络的整体目标损失函数,并随机初始化网络各参数。损失包含A方向和B方向的损失,此处只以A方向的损失为例进行说明,B方向可以类推得到。A方向的损失函数主要由对抗损失与重构损失组成,其计算步骤如下:
步骤4-1,对抗损失指的是生成器G
步骤4-2,重构损失用于衡量重构图像与原始输入图像之间的损失值。传统的L1和L2损失无法使重构损失收敛到一个有意义的状态,因此此处采用内容损失作为其循环一致损失。内容损失由两部分损失分量组成:视觉感知损失和L2损失。其中,视觉感知损失是由在ImageNet数据集上训练过的VGG-16分类网络给出的,将生成图像与理想图像同时输入到VGG-16网络的前14层中,得到二者的特征值,继而计算二者特征值之间的L2损失值,此即视觉感知损失,可以缩小二者在分类网络中的隐层特征差距;L2损失用于缩小生成图像与理想图像之间的色彩即像素值的差距。上述重构损失的两个损失分量的系数分别是0.006和0.5。
步骤5,利用步骤1中构建的无监督数据集对网络进行前向计算,得到生成器网络和判别器网络输出的损失值。前向计算指的是将模糊数据集与清晰数据集分别输入到步骤2和步骤3所述A和B方向上的网络中,直至计算出步骤4中对应的损失值。网络将从两个循环生成方向进行前向计算。以A方向为例,将模糊图像输入到G
步骤6,固定判别器的网络参数,利用Adam优化器更新生成器网络的参数,优化器的动量项为0.5,衰减率为0.999,初始学习率为0.0002,且学习率使用的是线性缩减策略,当达到100次训练次数时,学习率开始从0.0002线性缩减,直到200次训练时缩减为0。
步骤7,固定生成器的网络参数,利用Adam优化器更新判别器的网络参数,优化器与学习率参数设置与步骤6相同。
步骤8,循环执行步骤5、步骤6和步骤7,直至步骤5中计算的损失值收敛,此时可得到生成器网络参数的局部最优解,利用该训练完备的去模糊生成器G
本发明提出了一种基于无监督生成对抗网络的模糊图像复原方法,该方法能够利用无监督的数据集进行无监督训练,不仅省去了收集制作有监督数据集花费的大量时间,还能对模糊图像进行高质量复原,显著改善图像质量,提升图像细节的分辨能力。本发明实验结果如图6所示,其中(a)为输入的模糊图像,(b)为G
- 一种基于无监督生成对抗网络的模糊图像复原方法
- 一种基于生成对抗网络的高斯模糊图像复原方法