一种基于自监督学习的三维人脸模型重建方法及系统
文献发布时间:2023-06-19 11:21:00
技术领域
本发明涉及三维人脸模型重建技术领域,特别是涉及一种基于自监督学习的三维人脸模型重建方法及系统。
背景技术
人脸三维重建在计算机视觉领域有着十分广泛的应用,比如辅助人脸识别、人脸表情识别以及在影视动画中角色面部的制作等。人脸三维重建分为主动式和被动式两个大类。主动式建模利用外部光照如激光和结构光进行建模,这种通过仪器采集的方法可以直接获得深度信息,但是设备搭建复杂,过程执行繁琐,因而成本较高。被动式建模一般利用拍摄得到的图片或者视频进行建模。由多个相机组成的阵列同时采集一个人同一时刻的多个视角的照片,利用立体视觉的方法建模,可以得到较为精细的人脸模型,但是同主动式建模的方法类似,其设备搭建和执行十分复杂,计算成本高且只适合用于实验室的光照环境,无法普及应用。随着手机等移动设备的普及,图片和视频的获取变得更加方便,利用单张图像来重建人脸三维模型有了更大的需求同时衍生出许多的应用。相比于其他的人脸重建方案,基于单张图片的人脸重建无需搭建采集设备,素材易获取;但同时输入信息十分有限,由二维图片恢复三维信息是典型的病态问题,因此基于单张图片重建三维人脸模型依旧是一个极具挑战性的课题。
目前最为流行的人脸三维重建方法是基于形变模型的三维人脸重建(3DMM),传统优化方法基于输入图像的人脸关键点,优化形变模型的几何参数(包括身份参数和表情参数)。这类方法通常需要迭代优化,在人脸模型点数较多的情况下往往十分耗时,而且常规的形变模型受限于参数化模型的低维度表示空间,其重建结果较为平滑,缺乏高频的细节信息。随着深度学习方法在计算机视觉领域的许多方面取得了超越传统优化方法的效果,近年来越来越多的人脸三维重建工作开始引入深度学习的方法。然而深度学习方法中神经网络的训练需要大量数据,不同于分类、识别等任务中易于获取的图片数据集,人脸三维重建任务难以获得大量的与人脸图片对应的真实人脸三维模型,缺乏足够的训练数据降低了深度学习方法的效果。一些方法提出利用参数化人脸模型通过仿真采样得到大量虚拟三维人脸模型,结合不同光照信息进行渲染得到人脸三维模型对应的人脸图片,将这样的虚拟数据作为训练集训练神经网络。然而由于渲染得到的虚拟图片和真实图片仍有差距,训练结果在对真实图片的泛化性较差。同时,虚拟数据集无法仿真人脸细节信息,最终的人脸重建结果不够精细。
发明内容
本发明的目的是提供一种基于自监督学习的三维人脸模型重建方法及系统,无需大量采集真实三维人脸模型的情况下,仅使用单张图片即可得到精细的三维人脸模型。
为实现上述目的,本发明提供了如下方案:
一种基于自监督学习的三维人脸模型重建方法,包括:
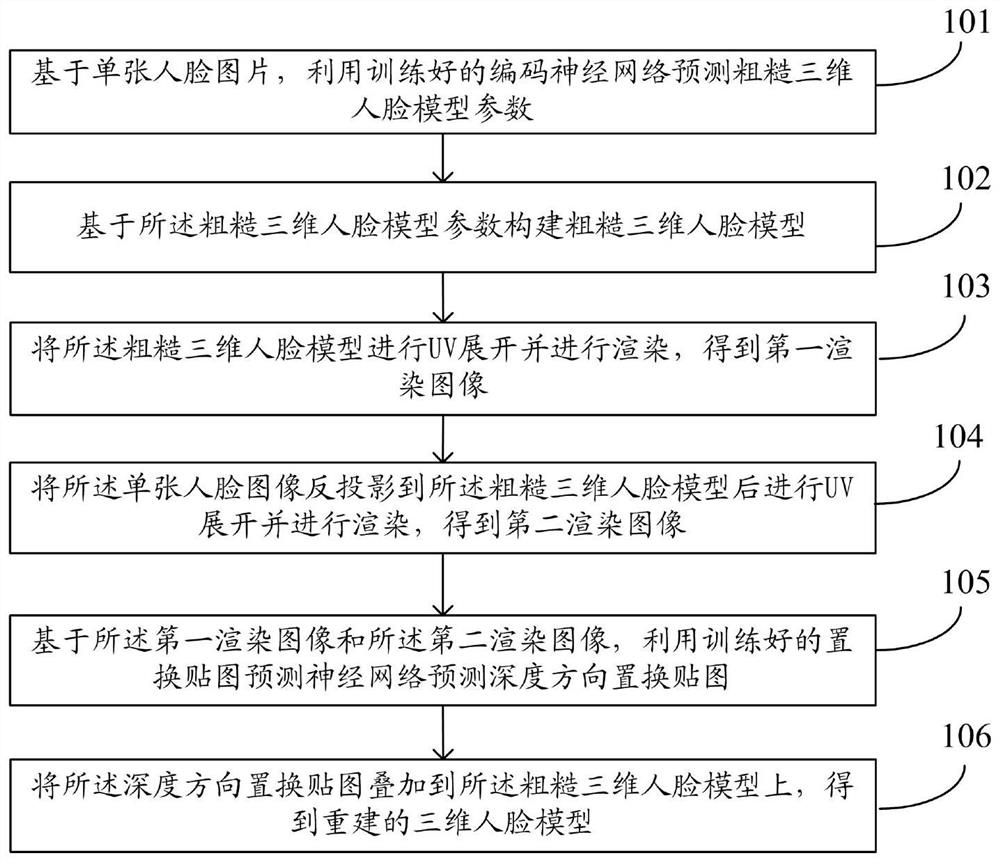
基于单张人脸图片,利用训练好的编码神经网络预测粗糙三维人脸模型参数;
基于所述粗糙三维人脸模型参数构建粗糙三维人脸模型;
将所述粗糙三维人脸模型进行UV展开并进行渲染,得到第一渲染图像;
将所述单张人脸图像反投影到所述粗糙三维人脸模型后进行UV展开并进行渲染,得到第二渲染图像;
基于所述第一渲染图像和所述第二渲染图像,利用训练好的置换贴图预测神经网络预测深度方向置换贴图;
将所述深度方向置换贴图叠加到所述粗糙三维人脸模型上,得到重建的三维人脸模型。
进一步地,编码神经网络的训练过程包括:
对所述单张人脸图像进行预处理,得到二维人脸关键点以及人脸皮肤掩膜;
通过所述单张人脸图像、所述二维人脸关键点以及所述人脸皮肤掩膜对编码神经网络进行迭代训练,使所述编码神经网络的损失函数达到最小。
进一步地,所述编码神经网络的损失函数包括第一图像重建损失函数、人脸关键点损失函数、第一感知损失函数以及第一正则项损失函数。
进一步地,所述置换贴图预测神经网络的训练过程包括:
通过所述第一渲染图像和所述第二渲染图像对置换贴图预测神经网络进行迭代训练,使所述置换贴图预测神经网络的损失函数达到最小。
进一步地,所述置换贴图预测神经网络的损失函数包括第二图像重建损失函数、第二感知损失函数、邻域平滑约束以及第二正则项损失函数。
本发明还提供了一种基于自监督学习的三维人脸模型重建系统,包括:
粗糙三维人脸模型参数预测模块,用于基于单张人脸图片,利用训练好的编码神经网络预测粗糙三维人脸模型参数;
粗糙三维人脸模型构建模块,用于基于所述粗糙三维人脸模型参数构建粗糙三维人脸模型;
第一渲染图像确定模块,用于将所述粗糙三维人脸模型进行UV展开并进行渲染,得到第一渲染图像;
第二渲染图像确定模块,用于将所述单张人脸图像反投影到所述粗糙三维人脸模型后进行UV展开并进行渲染,得到第二渲染图像;
深度方向置换贴图预测模块,用于基于所述第一渲染图像和所述第二渲染图像,利用训练好的置换贴图预测神经网络预测深度方向置换贴图;
三维人脸模型重建模块,用于将所述深度方向置换贴图叠加到所述粗糙三维人脸模型上,得到重建的三维人脸模型。
进一步地,还包括:
预处理模块,用于对所述单张人脸图像进行预处理,得到二维人脸关键点以及人脸皮肤掩膜;
第一训练模块,用于通过所述单张人脸图像、所述二维人脸关键点以及所述人脸皮肤掩膜对编码神经网络进行迭代训练,使所述编码神经网络的损失函数达到最小。
进一步地,所述编码神经网络的损失函数包括第一图像重建损失函数、人脸关键点损失函数、第一感知损失函数以及第一正则项损失函数。
进一步地,还包括:
第二训练模块,用于通过所述第一渲染图像和所述第二渲染图像对置换贴图预测神经网络进行迭代训练,使所述置换贴图预测神经网络的损失函数达到最小。
进一步地,所述置换贴图预测神经网络的损失函数包括第二图像重建损失函数、第二感知损失函数、邻域平滑约束以及第二正则项损失函数。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明利用输入图像自身作为监督,结合现有人脸关键点检测技术和人脸皮肤分割技术,无需真实三维人脸模型作为监督参与神经网络训练,缓解了缺乏大量训练数据集的问题。于算法上,利用神经网络预测UV域上人脸深度方向的置换贴图,将其与参数化人脸模型组合,进而得到含有几何细节的三维人脸模型。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例基于自监督学习的三维人脸模型重建方法的流程图;
图2为本发明实施例基于自监督学习的三维人脸模型重建方法的原理图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于自监督学习的三维人脸模型重建方法及系统,无需大量采集真实三维人脸模型的情况下,仅使用单张图片即可得到精细的三维人脸模型。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1-2所示,一种基于自监督学习的三维人脸模型重建方法包括以下步骤:
步骤101:基于单张人脸图片,利用训练好的编码神经网络预测粗糙三维人脸模型参数。
步骤102:基于所述粗糙三维人脸模型参数构建粗糙三维人脸模型。
步骤103:将所述粗糙三维人脸模型进行UV展开并进行渲染,得到第一渲染图像。
步骤104:将所述单张人脸图像反投影到所述粗糙三维人脸模型后进行UV展开并进行渲染,得到第二渲染图像。
步骤105:基于所述第一渲染图像和所述第二渲染图像,利用训练好的置换贴图预测神经网络预测深度方向置换贴图。
步骤106:将所述深度方向置换贴图叠加到所述粗糙三维人脸模型上,得到重建的三维人脸模型。
其中,编码神经网络的训练过程包括:
对所述单张人脸图像进行预处理,得到二维人脸关键点以及人脸皮肤掩膜;通过所述单张人脸图像、所述二维人脸关键点以及所述人脸皮肤掩膜对编码神经网络进行迭代训练,使所述编码神经网络的损失函数达到最小。所述编码神经网络的损失函数包括第一图像重建损失函数、人脸关键点损失函数、第一感知损失函数以及第一正则项损失函数。
将参与网络训练的人脸图片进行基本的对齐和裁剪,同时利用现有的人脸关键点检测技术得到图片对应的二维人脸关键点;利用图像分割技术得到图片对应的人脸皮肤掩膜。
输入无约束的单张人脸图像,在训练过程中同时输入图像检测的二维人脸关键点和对应的皮肤区域掩膜,需要注意的是,二维特征点和皮肤区域掩膜只在训练阶段输入,测试时无需输入,且这两部分均可由已有算法得到,无需昂贵的采集。
训练的编码网络以人脸图片作为输入,以参数化人脸模型参数、相机外参和光照信息作为输出。该过程具体为:
首先引入三维可形变模型(3DMM),表示为:
记该模型有n个点,X是将n个点的三维坐标按顺序堆叠而成的大小为3n的向量,X表征三维模型的几何形态。
接下来引入球谐光照模型,这里本发明可以粗略地假定人脸是一个朗伯体,即仅具有漫反射的特性,而不具有高频的高光反射特性。那么RGB三通道的场景光照可以由一个3×9的矩阵L表征,称为球谐光照系数。
S
其中S
关于相机内外参,本发明应用透视投影p=KΠ(Rv+t),其中
综上,本发明利用Resnet50的网络结构构建一个L编码网络,预测参数包括3DMM模型参数x
渲染过程需要引入本征图像的概念I=R*S,即对于一张图像,可以将其分解为反射率R和光影S两部分的乘积,其中
下面本发明详细说明为训练编码神经网络所设计的自监督约束:
L
其中[ω
下面分别介绍首先每一项约束的含义,首先利用输入图像I和渲染图像I
其中M为利用已有人脸分割技术获得的输入图像皮肤区域,(i,j)是表示皮肤区域的每一个像素点,图像重建损失函数计算输入图像和渲染图像在输入图像皮肤区域每个像素点的二范数。
进一步的,人脸关键点损失函数:
其中p
感知损失函数用来衡量两张图片的相似程度,表示为:
其中
正则项损失函数是对网络输出的3DMM模型参数进行约束的函数,使得输出系数重建的人脸在一个合理范围内,表示为:
L
其中x
综上,通过训练网络最小化损失函数L
其中,所述置换贴图预测神经网络的训练过程包括:通过所述第一渲染图像和所述第二渲染图像对置换贴图预测神经网络进行迭代训练,使所述置换贴图预测神经网络的损失函数达到最小。所述置换贴图预测神经网络的损失函数包括第二图像重建损失函数、第二感知损失函数、邻域平滑约束以及第二正则项损失函数。
将上一阶段得到的参数化模型表示的粗糙人脸模型以及输入图片进行UV展开,置换贴图预测网络以二者的UV展开渲染图作为输入,输出为UV域上的人脸深度方向的置换贴图。具体的:
对已经获得的粗糙三维人脸模型X
z′←y
将展开图进行渲染得到UV域的渲染图片
L
其中[ω
下面分别介绍首先每一项约束的含义,首先利用输入图像I和渲染图像
其中M为利用已有人脸分割技术获得的输入图像皮肤区域,(i,j)是表示皮肤区域的每一个像素点,图像重建损失函数计算输入图像和渲染图像在输入图像皮肤区域每个像素点的二范数。
感知损失函数用来衡量两张图片的相似程度,表示为:
其中
对于置换贴图ΔZ,为了使其与粗粒度模型叠加后生成合理的三维人脸,对ΔZ添加邻域平滑约束L
其中V
强度正则项L
综上,通过训练网络最小化L
置换贴图预测神经网络输出为对应人脸深度方向上的置换贴图ΔZ。将ΔZ叠加在粗粒度三维人脸模型X
本发明还提供了一种基于自监督学习的三维人脸模型重建系统,包括:
粗糙三维人脸模型参数预测模块,用于基于单张人脸图片,利用训练好的编码神经网络预测粗糙三维人脸模型参数。
粗糙三维人脸模型构建模块,用于基于所述粗糙三维人脸模型参数构建粗糙三维人脸模型。
第一渲染图像确定模块,用于将所述粗糙三维人脸模型进行UV展开并进行渲染,得到第一渲染图像。
第二渲染图像确定模块,用于将所述单张人脸图像反投影到所述粗糙三维人脸模型后进行UV展开并进行渲染,得到第二渲染图像。
深度方向置换贴图预测模块,用于基于所述第一渲染图像和所述第二渲染图像,利用训练好的置换贴图预测神经网络预测深度方向置换贴图。
三维人脸模型重建模块,用于将所述深度方向置换贴图叠加到所述粗糙三维人脸模型上,得到重建的三维人脸模型。
还包括:
预处理模块,用于对所述单张人脸图像进行预处理,得到二维人脸关键点以及人脸皮肤掩膜。
第一训练模块,用于通过所述单张人脸图像、所述二维人脸关键点以及所述人脸皮肤掩膜对编码神经网络进行迭代训练,使所述编码神经网络的损失函数达到最小。
第二训练模块,用于通过所述第一渲染图像和所述第二渲染图像对置换贴图预测神经网络进行迭代训练,使所述置换贴图预测神经网络的损失函数达到最小。
进一步地,所述置换贴图预测神经网络的损失函数包括第二图像重建损失函数、第二感知损失函数、邻域平滑约束以及第二正则项损失函数。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种基于自监督学习的三维人脸模型重建方法及系统
- 一种基于参数化模型和位置图的多度量三维人脸重建方法