一种新冠病毒肺炎重症化预测系统及方法
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及疾病预测技术领域,具体涉及一种新冠病毒肺炎重症化预测系统及方法。
背景技术
新冠病毒肺炎,是“新型冠状病毒肺炎”的简称,又称COVID-19,是世界性的重大公共卫生问题。新冠病毒肺炎,为新发呼吸道传染病,具有传播范围广、传播速度快等特点,极易造成公共卫生事件。新冠病毒肺炎全球大流行,截至2020年1月1日,全球累计确诊超8000万例,死亡超170万例,给全人类造成了极大危害。
新冠病毒肺炎患者分为轻型和重型:轻型只需隔离观察,不需特殊处理;而重型病情变化快,迅速进展为重症呼吸衰竭,死亡率高。快速高效地进行轻型患者和重型患者分诊,是急诊高效救治的关键。现在分诊,主要是根据病人的主诉及主要症状和体征,分清疾病的轻重缓急,安排救治程序,使患者得以迅速有效的救治;同时使有限的急诊空间得到充分利用。然而,新冠病毒肺炎发病隐匿,症状不典型,急诊医生难以识别;且传播能力强,短期内出现大量患者,形成巨大压力,导致医疗资源严重挤兑,急诊分诊救治系统瘫痪,因此,新冠病毒肺炎爆发初期是患者死亡率最高的时期,亟待寻找一种有效的方法和系统快速响应,维持急诊分诊高效率运行。
发明内容
本发明意在提供一种新冠病毒肺炎重症化预测方法,用来解决现在急诊医生无法准确快速地进行新冠病毒肺炎患者轻症和重症分诊的问题。
本发明提供的基础方案为:一种新冠病毒肺炎重症化预测方法,包括以下步骤:
包括以下步骤:
步骤一,采集患者血常规信息和用户信息;
步骤二,将患者血常规信息按照用户信息进行等级分类;
步骤三,将已经等级分类的患者血常规信息与对应等级的标准信息进行比较;
步骤四,当患者血常规信息在标准信息范围内则判定患者为轻症患者,当患者血常规信息在标准信息范围外则判定患者为重症患者。
本方法的优点在于:
利用日常检查的血常规项目,通过用户信息分类,将对应的血常规信息与对应等级的标准信息进行比较,能通过比较结果快速判断出患者是轻症还是重症,能够达到快速准确分诊的目的,有助于以此为基础,建立新冠病毒肺炎重症化预测体系,可合理优化医疗资源分配,提升救治效率。
进一步,在步骤一和步骤二之间,对采集到的血常规信息和用户信息进行数据清洗。
有助于从源头上保证输入数据的准确性,使预测判断结果更加准确。
进一步,对在步骤二中,所述将患者血常规信息按照用户信息进行等级分类具体为,对血常规信息中的各项参数进行重要程度分类,血常规信息重要程度依次减弱的信息分类为关键信息、重要信息和一般信息。
血常规信息包含多项不同的参数,不同参数对于新冠病毒肺炎的预测相关度不同,合理划分重要程度,能够便于准确进行轻症和重症区分判断。
进一步,所述对采集到的血常规信息和用户信息进行数据清洗具体为,对于缺失信息的处理,若缺失信息为关键信息时,采用拉格朗日插值法按照预设样本模型进行缺失数据补充。
采用拉格朗日插值法,按照预设样本模型进行缺失数据补充,能够尽可能修补缺失的关键信息,保证预测判断的准确性。
进一步,所述预设样本模型为武汉初期病人轻症转重症的血常规信息变化模型。
以此建立预设样本模型,能够尽可能准确地完成缺失关键信息的补充。
所述对采集到的血常规信息和用户信息进行数据清洗具体为,对于缺失信息的处理,若缺失信息为重要信息时,采用均值插补进行缺失数据补充。
采用均值插补法对重要信息进行补充,在不影响预测判断结果的前提下,使数据清洗速度更快。
所述对采集到的血常规信息和用户信息进行数据清洗具体为,对于缺失信息的处理,若缺失信息为一般信息时,直接删除缺失信息。
采用直接删除一般信息的方式,使在不影响预测判断结果的前提下,使数据清洗速度更快,进而使整个预测速度更快,有助于快速进行分诊。
本发明还提供了一种新冠病毒肺炎重症化预测系统,用来解决现在急症仅凭医生经验判断,新冠病毒肺炎分诊慢的问题。
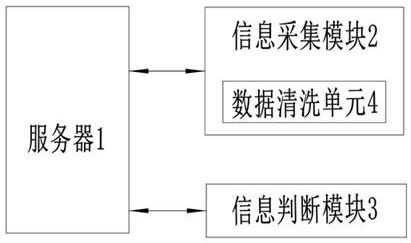
本方案中的新冠病毒肺炎重症化预测系统,包括服务器以及与服务器分别连接的信息采集模块和信息判断模块;所述信息采集模块,用来采集患者血常规信息和用户信息;所述信息判断模块,用来将患者血常规信息与预设标准信息进行对比,信息判断模块根据对比结果判断患者为轻症或者重症。
本方案的优点在于:
采用这种系统,能够有效避免现在仅凭医生经验进行分诊带来的各种问题,便于从分诊环节入手建立系统化高效化的新冠病毒肺炎重症化预测体系,可合理优化医疗资源分配,提升救治效率。
进一步,所述信息采集模块包括数据清洗单元,所述数据清洗单元用来对缺失信息进行处理。
通过数据清洗单元能够对缺失信息进行处理,从源头上控制输入数据质量。
进一步,所述服务器内预设有血常规信息分类表,所述血常规信息分类表将各项血常规参数按照重要程度依次减小分为关键信息、重要信息和一般信息。
通过重要程度分类,便于对不同的血常规信息中的各项参数进行分类。
进一步,所述服务器内设置有预设样本模型,当缺失信息为关键信息时,数据清洗单元按照预设样本模型进行缺失信息补充。
通过预设样本模型,能够更加精准地进行缺失信息补充。
进一步,所述服务器内设有用户信息等级表,所述信息判断模块用来根据用户信息等级表,将用户信息分级,并将对应的患者血常规信息与对应等级的标准信息进行对比。
不同等级的患者血常规信息与标准信息进行对比,能够更加精准地进行预测判断。
附图说明
图1为本发明新冠病毒肺炎重症化预测系统实施例的结构示意图。
图2为本发明新冠病毒肺炎重症化预测系统实施例中血常规信息表。
图3为本发明新冠病毒肺炎重症化预测系统实施例中血常规信息和用户信息组成的关键信息。
具体实施方式
下面通过具体实施方式进一步详细的说明:
说明书附图中的附图标记包括:服务器1、信息采集模块2、信息判断模块3、数据清洗单元4。
实施例一
实施例基本如附图1所示:新冠病毒肺炎重症化预测系统,包括服务器1以及与服务器1分别连接的信息采集模块2和信息判断模块3;信息采集模块2,用来采集患者血常规信息和用户信息;信息判断模块3,用来将患者血常规信息与预设标准信息进行对比,信息判断模块3根据对比结果判断患者为轻症或者重症。
信息采集模块2包括数据清洗单元4,数据清洗单元4用来对缺失信息进行处理,用来对错误信息进行清理。在对错误信息进行识别时,采用现有技术手段,通过对临近信息进行比较,将与临近信息偏离超过百分之七十以上的异常信息数据判断为错误信息进行清理;本方案申请人付出创造性劳动的地方之一在于,通过数据清洗单元4能够对缺失信息进行处理和弥补,从源头上控制输入数据质量。
服务器1内预设有血常规信息分类表,血常规信息分类表将各项血常规参数按照重要程度依次减小分为关键信息、重要信息和一般信息。通过重要程度分类,便于对不同的血常规信息中的各项参数进行分类。如图2所示,在血常规信息中,以下参数项“WBC: 白细胞计数, LYMC: 淋巴细胞计数, LYMPH: 淋巴细胞百分比”为关键信息,以下参数项“NEUT:中性粒细胞计数, NEU: 中性粒细胞百分比”为重要信息,以下参数项“NLR: 中性粒/淋巴细胞比值”为一般信息。如图3所示,信息采集模块中,血常规信息和用户信息,同时采集的各项参数项依次为性别、年龄、白细胞数、淋巴细胞数、淋巴细胞百分比、中性粒细胞数、中性粒细胞百分比、NLR、新冠患者轻症/重症的初步分类。其中,年龄是用户信息占影响比重最重要的参数项,而白细胞数是血常规信息中占影响比重最重要的参数项。
服务器1内设置有预设样本模型,当缺失信息为关键信息时,数据清洗单元4按照预设样本模型进行缺失信息补充。通过预设样本模型,能够更加精准地进行缺失信息补充。
服务器1内设有用户信息等级表,信息判断模块3用来根据用户信息等级表,将用户信息分级,并将对应的患者血常规信息与对应等级的标准信息进行对比。不同等级的患者血常规信息与标准信息进行对比,能够更加精准地进行预测判断。本实施例中,用户信息一般包括性别和年龄,针对不同性别和年龄分成不同的等级,通过服务器1内预设的用户信息等级表,根据患者的用户信息,将患者分成对应等级,对应的患者血常规信息,和对应等级的标准信息进行对比。
采用以上系统,能够有效避免现在仅凭医生经验进行分诊带来的各种问题,便于从分诊环节入手建立系统化高效化的新冠病毒肺炎重症化预测体系,可合理优化医疗资源分配,提升救治效率。
采用以上系统,进行新冠病毒肺炎预测的时候,一种新冠病毒肺炎重症化预测方法,包括以下步骤:
步骤一,采集患者血常规信息和用户信息;本实施例中患者血常规信息包括WBC:白细胞计数, LYMC: 淋巴细胞计数, LYMPH: 淋巴细胞百分比 , NEUT: 中性粒细胞计数,NEU: 中性粒细胞百分比, NLR: 中性粒/淋巴细胞比值;用户信息至少包括年龄和性别。
步骤二,将患者血常规信息按照用户信息进行等级分类;在预设的用户信息等级表中,根据不同年龄和性别,分成不同的等级分类,本实施例中区分男女均包括以下几个等级类别: 0-3岁婴幼儿易感人群、4-18青年较易感人群、19-50青壮年较易感人群、51-60岁老年易感人群以及61岁以上的老年极易感人群,不同的等级分类,对应的各项血常规参数项预设在服务器中的标准信息不同。
步骤三,将已经等级分类的患者血常规信息与对应等级的标准信息进行比较。
步骤四,当患者血常规信息在标准信息范围内则判定患者为轻症患者,当患者血常规信息在标准信息范围外则判定患者为重症患者。
在步骤一中,在采集患者血常规信息和用户信息的同时,对采集到的血常规信息和用户信息进行数据清洗和补充。有助于从源头上保证输入数据的准确性,使预测判断结果更加准确。
对血常规信息中的各项参数进行重要程度分类,血常规信息重要程度依次减弱的信息分类为关键信息、重要信息和一般信息。血常规信息包含多项不同的参数,不同参数对于新冠病毒肺炎的预测相关度不同,合理划分重要程度,能够便于准确进行轻症和重症区分判断。
在数据清洗时,对于缺失信息的处理,若缺失信息为关键信息时,采用拉格朗日插值法按照预设样本模型进行缺失数据补充。采用拉格朗日插值法,按照预设样本模型进行缺失数据补充,能够尽可能修补缺失的关键信息,保证预测判断的准确性。
预设样本模型为武汉初期病人轻症转重症的血常规信息变化模型。以此建立预设样本模型,能够尽可能准确地完成缺失关键信息的补充。
具体在使用拉格朗日插值法时,拉格朗日插值法的核心思想是通过已有的数据建立相应的模型函数,最后通过缺失值坐标代入算得一个估计值。大概步骤如下:
第一步:将武汉初期病人轻症转重症的血常规信息变化模型作为预设样本模型,通过采集到的同一区域同年龄段同性别同一症状患者的血常规信息,找到n个人各个参数项的完整信息作为n个点找到一个n-1次多项式,如公式(3-1)所示:
第二步:将n个点坐标
第三步:通过上式,可以得到拉格朗日多项式为,如式(3-2)所示:
这样,当在不可抗力条件下,采集到的血常规信息存在缺失或者错误信息的时候,能够充分利用预设样本模型来进行关键信息的补充和修复。而为了在保证准确度的基础上,使计算量不至于过大,本实施例中n的取值范围为850-2350,在此范围内,能够快速计算出各个参数项的缺失信息,而因为即使是关键信息,每个参数项占用的影响比重也是有区别的,比重越高的,n的取值越大,而通常在缺失信息很少或者没有的时候,也能通过n=1350的数值进行快速计算,用来核对采集数据信息,辅助判断采集数据信息是否正确,是否为错误信息。
在数据清洗时,对于缺失信息的处理,若缺失信息为重要信息时,采用均值插补进行缺失数据补充。采用均值插补法对重要信息进行补充,在不影响预测判断结果的前提下,使数据清洗速度更快。
在数据清洗时,对于缺失信息的处理,若缺失信息为一般信息时,直接删除缺失信息。采用直接删除一般信息的方式,使在不影响预测判断结果的前提下,使数据清洗速度更快,进而使整个预测速度更快,有助于快速进行分诊。
本实施例中,利用日常检查的血常规项目,通过用户信息分类,将对应的血常规信息与对应等级的标准信息进行比较,能通过比较结果快速判断出患者是轻症还是重症,能够达到快速准确分诊的目的,有助于以此为基础,建立新冠病毒肺炎重症化预测体系,可合理优化医疗资源分配,提升救治效率。
实施例二
本实施例中,预设样本模型,为武汉初期病人轻症转重症的血常规信息变化模型,具体地为不同年龄和性别的等级分类中,血常规信息WBC: 白细胞计数, LYMC: 淋巴细胞计数, LYMPH: 淋巴细胞百分比 , NEUT: 中性粒细胞计数, NEU: 中性粒细胞百分比,NLR: 中性粒/淋巴细胞比值各项参数在单位时间内的变化拟合曲线,尤其是在确认由轻症变为重症时候,各项参数单位时间的变化量,在转变时间内的变化量精确到每10-20分钟各项参数的变化量。
本实施例中的预设样本模型,与各个等级的标准信息相匹配。
通过这样的预设样本模型,能够快速地对患者血常规信息和预设样本模型进行对比,不仅方便进行缺失的关键信息进行补充,还方便进行血常规信息和标准信息的对比,进而判断出轻症和重症。
实施例三
本实施例中,在进行关键信息补充的时候,会参考患者周围接触的人的身体变化情况,对轻症转变重症的速度进行预判,通过该预判速度,与轻症转重症的平均时间相结合,得到预测的该患者轻症转重症的预测时间范围。通过精准预测出转换时间,便于提前进行转换准备和预防,能够有效避免轻症转重症。
实施例四
本实施例中,在采用均值插补的时候,同样能够参考预设样本模型中各个用户等级分类中的平均值进行参考,上下浮动不能超过本地实际采集结果中至少三个用户等级分类差异值范围的平均值。
实施例五
本实施例中,在对用户信息进行等级分类时,除了优先考虑性别、年龄等通用因素外,还需要考虑行为习惯和环境因素,其中行为习惯因素的比重大于环境因素,对于行为习惯和环境因素差异的同样年龄段和同样性别的用户信息等级进行再细化分类,尤其是对于0-3岁婴幼儿易感人群、51-60岁老年易感人群以及61岁以上的老年极易感人群,其对应的标准信息差异大。本实施例中的行为习惯因素,主要通过饮食习惯信息、睡眠习惯信息和运动习惯信息进行体现,环境因素主要通过温度信息、湿度信息和光照度信息进行体现。这样能够通过充分考虑到行为习惯因素和环境因素,区分开个体差异,更加精准地预测出每个患者的重症转化情况。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 一种新冠病毒肺炎重症化预测系统及方法
- 一种基于机器学习算法的新冠肺炎重症化预测方法及系统