一种学生健康数据相关度分析方法及系统
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及数据处理技术领域,特别是涉及一种学生健康数据相关度分析方法及系统。
背景技术
在一些城市中,对于中小学生的体能测试是大规模开展的,在验证数据可信度时,由于大规模体能测试的特性,导致对中小学生进行重测的人力成本和时间成本太高,甚至无法进行重新测试,所以无法基于重测数据来体现学生体质健康数据的可信度,而只能通过其他方法来验证数据的可信度。因此,本发明提出一种学生健康数据相关度分析方法及系统,用于验证当前学生体质健康数据的可信度。
发明内容
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种学生健康数据相关度分析方法及系统,用于解决现有技术中无法对学生体质健康数据进行重新测量时数据可信度的验证问题。
为实现上述目的及其他相关目的,本发明提供一种学生健康数据相关度分析方法,包括以下步骤:
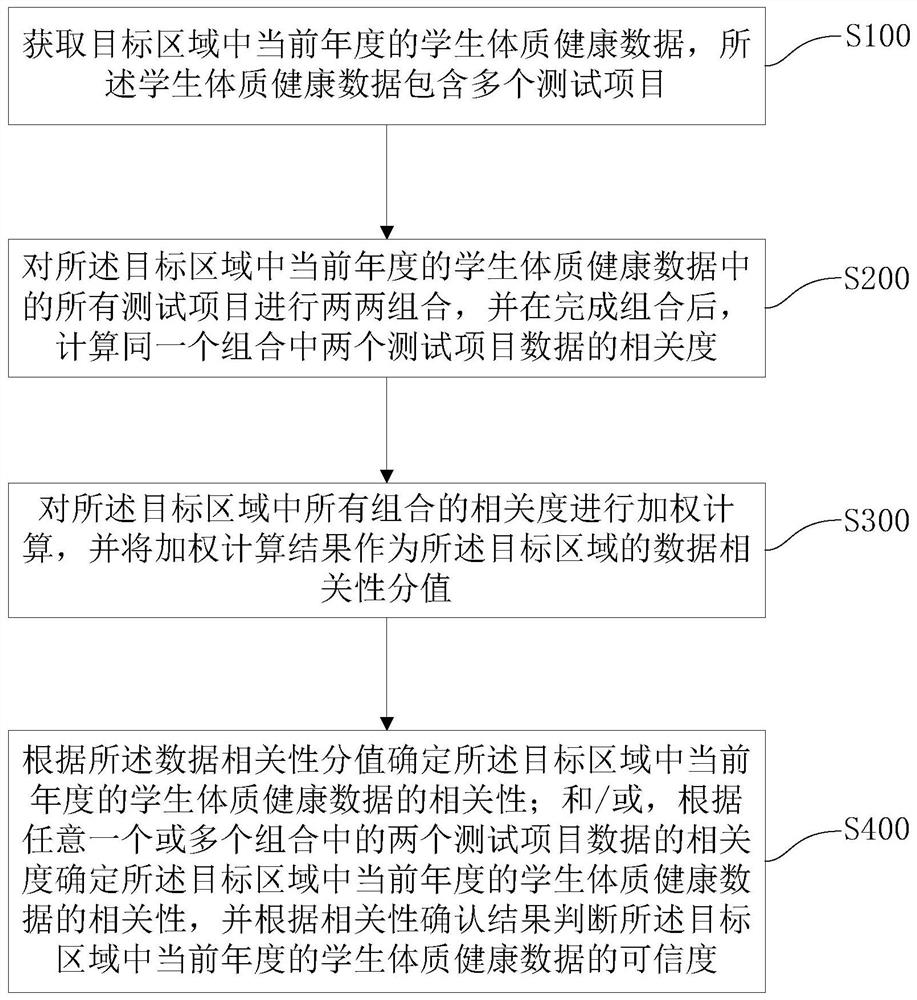
获取目标区域中当前年度的学生体质健康数据,所述学生体质健康数据包含多个测试项目;
对所述目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合,并在完成组合后,计算同一个组合中两个测试项目数据的相关度;
对所述目标区域中所有组合的相关度进行加权计算,并将加权计算结果作为所述目标区域的数据相关性分值;
根据所述数据相关性分值确定所述目标区域中当前年度的学生体质健康数据的相关性;和/或,根据任意一个或多个组合中的两个测试项目数据的相关度确定所述目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断所述目标区域中当前年度的学生体质健康数据的可信度。
可选地,同一个组合中两个测试项目数据的相关度的计算过程包括:
对所述目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合后,获取第i个组合;其中,i=1,2,3,…,n,n为正整数;
将第i个组合中的测试项目X所对应的测试项目数据记为X
计算第i个组合中的测试项目数据X
式中,
X
σ
Y
σ
可选地,还包括:将
将
将
将
可选地,还包括:将
若存在一个或多个组合中的两个测试项目数据的相关度为弱相关或极弱相关,则确定所述目标区域中当前年度的学生体质健康数据的不可信。
可选地,所述学生体质健康数据所包含的测试项目包括:身高测试、体重测试、一分钟跳绳评分测试、五十米短跑评分测试、坐体位前屈评分测试和肺活量评分测试。
本发明还提供了一种学生健康数据相关度分析系统,包括有:
数据采集模块,用于获取目标区域中当前年度的学生体质健康数据,所述学生体质健康数据包含多个测试项目;
测试项目组合模块,用于对所述目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合;
相关度计算模块,用于在测试项目完成两两组合后,计算同一个组合中两个测试项目数据的相关度;以及对所述目标区域中所有组合的相关度进行加权计算,并将加权计算结果作为所述目标区域的数据相关性分值;
相关度分析模块,用于根据所述数据相关性分值确定所述目标区域中当前年度的学生体质健康数据的相关性;和/或,根据任意一个或多个组合中的两个测试项目数据的相关度确定所述目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断所述目标区域中当前年度的学生体质健康数据的可信度。
可选地,同一个组合中两个测试项目数据的相关度的计算过程包括:
对所述目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合后,获取第i个组合;其中,i=1,2,3,…,n,n为正整数;
将第i个组合中的测试项目X所对应的测试项目数据记为X
计算第i个组合中的测试项目数据X
式中,
X
σ
Y
σ
可选地,还包括:将
将
将
将
可选地,还包括:将
若存在一个或多个组合中的两个测试项目数据的相关度为弱相关或极弱相关,则确定所述目标区域中当前年度的学生体质健康数据的不可信。
可选地,所述学生体质健康数据所包含的测试项目包括:身高测试、体重测试、一分钟跳绳评分测试、五十米短跑评分测试、坐体位前屈评分测试和肺活量评分测试。
如上所述,本发明提供一种学生健康数据相关度分析方法及系统,具有以下有益效果:本发明首先获取目标区域中当前年度的学生体质健康数据,然后对目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合,并在完成组合后,计算同一个组合中两个测试项目数据的相关度;再对目标区域中所有组合的相关度进行加权计算,并将加权计算结果作为目标区域的数据相关性分值;根据数据相关性分值确定目标区域中当前年度的学生体质健康数据的相关性;和/或,根据任意一个或多个组合中的两个测试项目数据的相关度确定目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断目标区域中当前年度的学生体质健康数据的可信度。本发明通过利用目标区域中当前年度的学生体质健康数据的相关性来验证当前年度的学生体质健康数据的可信度,从而不需要重新测试学生体质健康数据,减少了对学生体质健康数据可信度验证时的人力成本和时间成本。
附图说明
图1为一实施例提供的学生健康数据相关度分析方法的流程示意图;
图2为一实施例提供的身高与体重的标准差分布图;
图3为一实施例提供的学生健康数据相关度分析系统的硬件结构示意图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
请参阅图1,本实施例提供一种学生健康数据相关度分析方法,包括以下步骤:
S100,获取目标区域中当前年度的学生体质健康数据,所述学生体质健康数据包含多个测试项目;作为示例,本方法中的学生体质健康数据所包含的测试项目包括:身高测试、体重测试、一分钟跳绳评分测试、五十米短跑评分测试、坐体位前屈评分测试和肺活量评分测试等。
S200,对所述目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合,并在完成组合后,计算同一个组合中两个测试项目数据的相关度;
S300,对所述目标区域中所有组合的相关度进行加权计算,并将加权计算结果作为所述目标区域的数据相关性分值;
S400,根据所述数据相关性分值确定所述目标区域中当前年度的学生体质健康数据的相关性;和/或,根据任意一个或多个组合中的两个测试项目数据的相关度确定所述目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断所述目标区域中当前年度的学生体质健康数据的可信度。
由此可知,本实施例可以通过利用目标区域中当前年度的学生体质健康数据的相关性来验证当前年度的学生体质健康数据的可信度,从而不需要重新测试学生体质健康数据,减少了对学生体质健康数据可信度验证时的人力成本和时间成本。
在一示例性实施例中,同一个组合中两个测试项目数据的相关度的计算过程包括:对所述目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合后,获取第i个组合;其中,i=1,2,3,…,n,n为正整数;
将第i个组合中的测试项目X所对应的测试项目数据记为X
计算第i个组合中的测试项目数据X
式中,
X
σ
Y
σ
在本实施例中,还包括:将
作为示例,例如以重庆市N区(即目标区域)中的25个小学二年级(即当前年度)的学生体质健康数据中的身高测试项目和体重测试项目为例;将身高测试项目定义为测试项目X,体重测试项目定义为测试项目Y。其中,N区中25个小学二年级的身高测试项目和体重测试项目的标准差如图2所示。对于身高测试项目而言,图2中25个学校的身高标准差分别为:6.5、6.75、6、7.5、6.5、7、5.5、6.5、6、6.5、6、5.5、6、6.5、5.5、6、6、6.5、4.5、5.5、6、6、6、6.5、6.25;体重标准差分别为:4.5、5.5、5、5、13、6、4、5.5、7、6.5、5、5.5、5.5、5、5.5、5、5.5、5.5、3.75、4.5、6、5、5.5、5.5、5.5。由此可知,第5个和第9个学校的身高与体重的相关度小于零,表明这2个学校中的身高测试项目数据和体重测试项目数据呈负相关。在本实施例中,根据任意一个或多个组合中的两个测试项目数据的相关度确定所述目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断所述目标区域中当前年度的学生体质健康数据的可信度时,以身高测试项目数据和体重测试项目数据为例,在正常情况下,身高数据与体重数据一定是呈正相关的,并且是强相关的。N区的第5个学校和第9个学校的身高与体重的相关度呈负相关,说明这两个学校在身高、体重的测试项目数据中,其中至少有一项测试项目数据是错误的,可能是身高测试项目数据是错误的,也可能是体重测试项目数据是错误的,还有可能身高测试项目数据和体重测试项目数据均是错误的。
在方法中,数据相关性是指数据之间的正相关与负相关的程度,体测项目中有很多项目之间是互相相关的,例如身高与体重一定是呈正相关的,并且应该是强相关的。那么,如果一个学校学生的身高体重之间的相关程度不是正相关,或者仅仅只是低相关,甚至是负相关,那么我们有理由怀疑这些数据的真实性,即可信度较低,因此数据间的相关性可以作为衡量数据内部一致性信度的主要指标。所以,在本实施例还包括:将
表1 N区所有测试项目数据相关性
从表1可以看出,N区女生八百米跑和仰卧起坐间的相关性高达0.961;男生一千米跑与引体向上间也是极强相关的。因此根据表1,我们可以按照相关度的高低进行划分梳理出各项评价指标。
根据上述记载,本方法根据相关性确认结果判断所述目标区域中当前年度的学生体质健康数据的可信度后,还可以利用所述数据可信度评价模型对当前年度的学生体质健康数据进行验证。其中,可信度评价模型的生成过程可以是:获取多个目标区域中历史年度和当前年度的学生体质健康数据;计算每个目标区域在两个相邻历史年度中学生体质健康数据的数据增长幅度,以及计算每个目标区域在同一历史年度中学生体质健康数据的数据离散程度;根据所有目标区域的数据增长幅度和数据离散程度建立数据可信度评价模型;利用所述数据可信度评价模型对当前年度中每个目标区域的学生体质健康数据进行验证,确定当前年度中每个目标区域的学生体质健康数据的可信度。本实施例可以基于同一批学生在相邻两个年度中的学生体质健康数据开始分析,从中选择学生在某些测量项目的增长幅度作为第一个衡量指标;其次,依据对同一年数据内部一致性信度的考虑,选择数据离散程度作为另外一个衡量指标,从而建立测评数据可信度评价模型;同时,再以当前年度的体测数据来对数据可信度模型进行验证,验证数据可信度模型是否合理可行;如果不可行,则继续对数据可信度评价模型进行新一轮的改进优化;如果可行,即可投入市场应用,从而确保学生体测数据的准确性。本实施例在建立数据可信度评价模型后,还可以构建数据可信度测评的软件系统,根据软件系统自动导出数据的可信度值。
作为一个具体示例,以部分体能测试项目为例,构建数据可信度评价模型。其中,数据可信度评价模型的评价指标包括定性指标和定量指标,定性指标包括:数据增长幅度和数据离散程度;定量指标为学生体质健康数据所包含的测试项目。例如数据增长幅度的定量指标可以是身高测试、体重测试、一分钟跳绳评分测试、五十米短跑评分测试、坐体位前屈评分测试和肺活量评分测试等;数据离散程度的定量指标可以是身高测试、体重测试、一分钟跳绳评分测试、五十米短跑评分测试、坐体位前屈评分测试和肺活量评分测试等。
对N区中当前年度第前两年和当前年度第前一年的学生体质健康数据进行分析,确定N区的数据增长幅度。作为示例,例如N区中的所有学生在当前年度第前两年的平均身高为1.20米,N区中的所有学生在当前年度第前一年的平均身高为1.32米,则N区的身高增长幅度为:(1.32-1.20)÷1.20×100%=10%。同理,分别获取N区中所有学生的体重测试数据、一分钟跳绳评分测试数据、五十米短跑评分测试数据、坐体位前屈评分测试数据和肺活量评分测试数据,然后分别计算体重、一分钟跳绳评分、五十米短跑评分、坐体位前屈评分和肺活量评分的数据增长幅度,然后根据身高、体重、一分钟跳绳评分、五十米短跑评分、坐体位前屈评分和肺活量评分的数据增长幅度形成一个数据集合,并将所形成的数据集合作为N区的数据增长幅度。
计算N区当前年度中二年级学生的身高、体重的标准差,并根据计算出的数值形成对应的身高和体重的标准差分布图,如图2所示。从图2中可以看出,N区中当前年度二年级学生的身高在区间[4,8]之间,并且基本在多个数值靠近数值6;而大部分体重的标准差取值范围为[4,6],但是N区中第五个学校中的二年级学生的体重超过了数值12,则说明N区中第五个学校的学生体质健康数据可能存在错误或不真实,因为同一年龄段的孩子身高体重的差异不会这么大。所以,本实施例可以依据对应测试项目的标准差范围衡量数据的真实性,如果有数据超出了该范围,则说明对应的数据不合理,进而认为对应学校的学生体质健康数据可能存在错误或不真实。
综上所述,本发明提供一种学生健康数据相关度分析方法,首先获取目标区域中当前年度的学生体质健康数据,然后对目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合,并在完成组合后,计算同一个组合中两个测试项目数据的相关度;再对目标区域中所有组合的相关度进行加权计算,并将加权计算结果作为目标区域的数据相关性分值;根据数据相关性分值确定目标区域中当前年度的学生体质健康数据的相关性;和/或,根据任意一个或多个组合中的两个测试项目数据的相关度确定目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断目标区域中当前年度的学生体质健康数据的可信度。本发明通过利用目标区域中当前年度的学生体质健康数据的相关性来验证当前年度的学生体质健康数据的可信度,从而不需要重新测试学生体质健康数据,减少了对学生体质健康数据可信度验证时的人力成本和时间成本。同时,本方法在根据相关性确认结果判断目标区域中当前年度的学生体质健康数据的可信度后,还可以根据建立可信度评价模型来验证当前年度的学生体质健康数据,从而达到双重验证的效果。
如图3所示,本发明还提供一种学生健康数据相关度分析系统,包括有:
数据采集模块M10,用于获取目标区域中当前年度的学生体质健康数据,所述学生体质健康数据包含多个测试项目;
测试项目组合模块M20,用于对所述目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合;
相关度计算模块M30,用于在测试项目完成两两组合后,计算同一个组合中两个测试项目数据的相关度;以及对所述目标区域中所有组合的相关度进行加权计算,并将加权计算结果作为所述目标区域的数据相关性分值;
相关度分析模块M40,用于根据所述数据相关性分值确定所述目标区域中当前年度的学生体质健康数据的相关性;和/或,根据任意一个或多个组合中的两个测试项目数据的相关度确定所述目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断所述目标区域中当前年度的学生体质健康数据的可信度。
由此可知,本实施例可以通过利用目标区域中当前年度的学生体质健康数据的相关性来验证当前年度的学生体质健康数据的可信度,从而不需要重新测试学生体质健康数据,减少了对学生体质健康数据可信度验证时的人力成本和时间成本。
在一示例性实施例中,同一个组合中两个测试项目数据的相关度的计算过程包括:对所述目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合后,获取第i个组合;其中,i=1,2,3,…,n,n为正整数;
将第i个组合中的测试项目X所对应的测试项目数据记为X
计算第i个组合中的测试项目数据X
式中,
X
σ
Y
σ
在本实施例中,还包括:将
作为示例,例如以重庆市N区(即目标区域)中的25个小学二年级(即当前年度)的学生体质健康数据中的身高测试项目和体重测试项目为例;将身高测试项目定义为测试项目X,体重测试项目定义为测试项目Y。其中,N区中25个小学二年级的身高测试项目和体重测试项目的标准差如图2所示。对于身高测试项目而言,图2中25个学校的身高标准差分别为:6.5、6.75、6、7.5、6.5、7、5.5、6.5、6、6.5、6、5.5、6、6.5、5.5、6、6、6.5、4.5、5.5、6、6、6、6.5、6.25;体重标准差分别为:4.5、5.5、5、5、13、6、4、5.5、7、6.5、5、5.5、5.5、5、5.5、5、5.5、5.5、3.75、4.5、6、5、5.5、5.5、5.5。由此可知,第5个和第9个学校的身高与体重的相关度小于零,表明这2个学校中的身高测试项目数据和体重测试项目数据呈负相关。在本实施例中,根据任意一个或多个组合中的两个测试项目数据的相关度确定所述目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断所述目标区域中当前年度的学生体质健康数据的可信度时,以身高测试项目数据和体重测试项目数据为例,在正常情况下,身高数据与体重数据一定是呈正相关的,并且是强相关的。N区的第5个学校和第9个学校的身高与体重的相关度呈负相关,说明这两个学校在身高、体重的测试项目数据中,其中至少有一项测试项目数据是错误的,可能是身高测试项目数据是错误的,也可能是体重测试项目数据是错误的,还有可能身高测试项目数据和体重测试项目数据均是错误的。
在系统中,数据相关性是指数据之间的正相关与负相关的程度,体测项目中有很多项目之间是互相相关的,例如身高与体重一定是呈正相关的,并且应该是强相关的。那么,如果一个学校学生的身高体重之间的相关程度不是正相关,或者仅仅只是低相关,甚至是负相关,那么我们有理由怀疑这些数据的真实性,即可信度较低,因此数据间的相关性可以作为衡量数据内部一致性信度的主要指标。所以,在本实施例还包括:将
根据上述记载,本系统根据相关性确认结果判断所述目标区域中当前年度的学生体质健康数据的可信度后,还可以利用所述数据可信度评价模型对当前年度的学生体质健康数据进行验证。其中,可信度评价模型的生成过程可以是:获取多个目标区域中历史年度和当前年度的学生体质健康数据;计算每个目标区域在两个相邻历史年度中学生体质健康数据的数据增长幅度,以及计算每个目标区域在同一历史年度中学生体质健康数据的数据离散程度;根据所有目标区域的数据增长幅度和数据离散程度建立数据可信度评价模型;利用所述数据可信度评价模型对当前年度中每个目标区域的学生体质健康数据进行验证,确定当前年度中每个目标区域的学生体质健康数据的可信度。本实施例可以基于同一批学生在相邻两个年度中的学生体质健康数据开始分析,从中选择学生在某些测量项目的增长幅度作为第一个衡量指标;其次,依据对同一年数据内部一致性信度的考虑,选择数据离散程度作为另外一个衡量指标,从而建立测评数据可信度评价模型;同时,再以当前年度的体测数据来对数据可信度模型进行验证,验证数据可信度模型是否合理可行;如果不可行,则继续对数据可信度评价模型进行新一轮的改进优化;如果可行,即可投入市场应用,从而确保学生体测数据的准确性。本实施例在建立数据可信度评价模型后,还可以构建数据可信度测评的软件系统,根据软件系统自动导出数据的可信度值。
作为一个具体示例,以部分体能测试项目为例,构建数据可信度评价模型。其中,数据可信度评价模型的评价指标包括定性指标和定量指标,定性指标包括:数据增长幅度和数据离散程度;定量指标为学生体质健康数据所包含的测试项目。例如数据增长幅度的定量指标可以是身高测试、体重测试、一分钟跳绳评分测试、五十米短跑评分测试、坐体位前屈评分测试和肺活量评分测试等;数据离散程度的定量指标可以是身高测试、体重测试、一分钟跳绳评分测试、五十米短跑评分测试、坐体位前屈评分测试和肺活量评分测试等。
对N区中当前年度第前两年和当前年度第前一年的学生体质健康数据进行分析,确定N区的数据增长幅度。作为示例,例如N区中的所有学生在当前年度第前两年的平均身高为1.20米,N区中的所有学生在当前年度第前一年的平均身高为1.32米,则N区的身高增长幅度为:(1.32-1.20)÷1.20×100%=10%。同理,分别获取N区中所有学生的体重测试数据、一分钟跳绳评分测试数据、五十米短跑评分测试数据、坐体位前屈评分测试数据和肺活量评分测试数据,然后分别计算体重、一分钟跳绳评分、五十米短跑评分、坐体位前屈评分和肺活量评分的数据增长幅度,然后根据身高、体重、一分钟跳绳评分、五十米短跑评分、坐体位前屈评分和肺活量评分的数据增长幅度形成一个数据集合,并将所形成的数据集合作为N区的数据增长幅度。
计算N区当前年度中二年级学生的身高、体重的标准差,并根据计算出的数值形成对应的身高和体重的标准差分布图,如图2所示。从图2中可以看出,N区中当前年度二年级学生的身高在区间[4,8]之间,并且基本在多个数值靠近数值6;而大部分体重的标准差取值范围为[4,6],但是N区中第五个学校中的二年级学生的体重超过了数值12,则说明N区中第五个学校的学生体质健康数据可能存在错误或不真实,因为同一年龄段的孩子身高体重的差异不会这么大。所以,本实施例可以依据对应测试项目的标准差范围衡量数据的真实性,如果有数据超出了该范围,则说明对应的数据不合理,进而认为对应学校的学生体质健康数据可能存在错误或不真实。
综上所述,本发明提供一种学生健康数据相关度分析系统,首先获取目标区域中当前年度的学生体质健康数据,然后对目标区域中当前年度的学生体质健康数据中的所有测试项目进行两两组合,并在完成组合后,计算同一个组合中两个测试项目数据的相关度;再对目标区域中所有组合的相关度进行加权计算,并将加权计算结果作为目标区域的数据相关性分值;根据数据相关性分值确定目标区域中当前年度的学生体质健康数据的相关性;和/或,根据任意一个或多个组合中的两个测试项目数据的相关度确定目标区域中当前年度的学生体质健康数据的相关性,并根据相关性确认结果判断目标区域中当前年度的学生体质健康数据的可信度。本发明通过利用目标区域中当前年度的学生体质健康数据的相关性来验证当前年度的学生体质健康数据的可信度,从而不需要重新测试学生体质健康数据,减少了对学生体质健康数据可信度验证时的人力成本和时间成本。同时,本系统在根据相关性确认结果判断目标区域中当前年度的学生体质健康数据的可信度后,还可以根据建立可信度评价模型来验证当前年度的学生体质健康数据,从而达到双重验证的效果。
所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
应当理解的是,尽管在本发明实施例中可能采用术语第一、第二、第三等来描述预设范围等,但这些预设范围不应限于这些术语。这些术语仅用来将预设范围彼此区分开。例如,在不脱离本发明实施例范围的情况下,第一预设范围也可以被称为第二预设范围,类似地,第二预设范围也可以被称为第一预设范围。