FAQ系统的答案检索方法及装置、电子设备、存储介质
文献发布时间:2023-06-19 13:46:35
技术领域
本申请涉及自然语言处理技术领域,特别涉及一种FAQ系统的答案检索方法及装置、电子设备、计算机可读存储介质。
背景技术
FAQ(Frequently Asked Questions,常见问题解答)系统可以针对用户提交的问题,回复确定的答案。搭建FAQ问答系统,首先要整理FAQ语料库。FAQ语料库可以由三部分组成:标准问、标准答、相似问。标准问是语言比较正式和规范的问题,FAQ语料库中可以包括多个标准问,不同标准问之间的区分度较高,标准问涵盖了用户可能问到的多种不同问题。标准答是对标准问的回复,如果不考虑维度等复杂情况,一般标准问与标准答一一对应。例如:标准问为“科创板开通后是否有有效期?”映射的标准答为“您好,科创板开通成功后,将一直生效。”相似问是对标准问的扩展,一个标准问可以对应多个相似问,相似问与对应的标准问表达同一个意思,但相似问的语言往往并不规范,且会尽量覆盖标准问的各种不同问法。例如:标准问为“科创板开通后是否有有效期?”对应的相似问为“开通科创板多久失效”、“科创板能用多长时间”。
参见图1,为本申请一实施例提供的FAQ语料库的组织形式示意图,如图1所示,每一标准问映射一个标准答,且标准问对应多个相似问。
FAQ检索问答系统是FAQ系统的一种形式。FAQ检索问答系统在接收用户问之后,可以将用户问与FAQ语料库中标准问和相似问进行相似度匹配。当与用户问最相似的是标准问时,将标准问映射的标准答作为系统答复;当与用户问最相似的是相似问时,将相似问对应标准问映射的标准答作为系统答复。
然而,标准问的语言正规,区分度高,检索标准问具有精度特性。当用户问的问法较为常见时,找到标准问的错误机率更低。相似问的个数多,覆盖的问法广,检索相似问具有广度特性。当用户问的问法较为罕见时,通过找到与用户问解决的相似问,可以给予正确的回复。相关方案的响应方式没有有效区分标准问与相似问的不同特性。
发明内容
本申请实施例的目的在于提供一种FAQ系统的答案检索方法及装置、电子设备、计算机可读存储介质,用于在兼顾标准问和相似问的不同特性的情况下,确定最优的问题答案。
一方面,本申请提供了一种FAQ系统的答案检索方法,包括:
基于用户问与FAQ语料库中每一问题之间的第一相似度,确定若干作为指定标准问分组的标准问分组、以及每一指定标准问分组的第一分组得分;其中,所述FAQ语料库中问题包括标准问和相似问,所述标准问分组包括一个标准问和多个相似问;
基于每一指定标准问分组中标准问与所述用户问之间的第二相似度,确定每一指定标准问分组对应的第二分组得分;
对每一指定标准问分组的第一分组得分和第二分组得到加权求和,得到每一指定标准问分组的集成得分;
确定所述集成得分最高的指定标准问分组对应的标准答,为所述用户问的答案。
在一实施例中,所述基于用户问与FAQ语料库中每一问题之间的第一相似度,确定若干作为指定标准问分组的标准问分组、以及每一指定标准问分组的第一分组得分,包括:
基于所述用户问与每一问题之间的第一相似度,确定每一问题相对于所述用户问的第一相似度得分;
根据所有问题的第一相似度得分,确定若干指定标准问分组;
基于每一指定标准问分组内每一问题对应的第一相似度得分,确定每一指定标准问分组对应的第一分组得分。
在一实施例中,所述根据所有问题的第一相似度得分,确定若干指定标准问分组,包括:
筛选出第一相似度得分最高的指定数量的问题,作为指定问题;
确定所述指定问题所在的若干标准问分组,作为所述指定标准问分组。
在一实施例中,所述基于每一指定标准问分组内每一问题对应的第一相似度得分,确定每一指定标准问分组对应的第一分组得分,包括:
针对每一指定标准问分组,确定所述指定标准问分组中多个第一相似度得分的最大值或平均值或中位值,作为所述指定标准问分组的第一分组得分。
在一实施例中,在所述确定若干作为指定标准问分组的标准问分组、以及每一指定标准问分组的第一分组得分之前,所述方法还包括:
针对所述FAQ语料库中每一问题,根据第一相似度算法,确定所述问题与所述用户问之间的第一相似度。
在一实施例中,所述基于每一指定标准问分组中标准问与所述用户问之间的第二相似度,确定每一指定标准问分组对应的第二分组得分,包括:
基于每一指定标准问分组中标准问与所述用户问之间的第二相似度,确定每一标准问相对于所述用户问的第二相似度得分;
针对每一指定标准问分组,将所述指定标准问分组内标准问的第二相似度得分,作为所述指定标准问分组的第二分组得分。
在一实施例中,在所述确定每一指定标准问分组对应的第二分组得分之前,所述方法还包括:
针对若干指定标准问分组的每一标准问,根据第二相似度算法,确定所述标准问与所述用户问之间的第二相似度。
另一方面,本申请还提供了一种FAQ系统的答案检索装置,包括:
第一确定模块,用于基于用户问与FAQ语料库中每一问题之间的第一相似度,确定若干作为指定标准问分组的标准问分组、以及每一指定标准问分组的第一分组得分;其中,所述FAQ语料库中问题包括标准问和相似问,所述标准问分组包括一个标准问和多个相似问;
第二确定模块,用于基于每一指定标准问分组中标准问与所述用户问之间的第二相似度,确定每一指定标准问分组对应的第二分组得分;
合成模块,用于对每一指定标准问分组的第一分组得分和第二分组得到加权求和,得到每一指定标准问分组的集成得分;
第三确定模块,用于确定所述集成得分最高的指定标准问分组对应的标准答,为所述用户问的答案。
进一步的,本申请还提供了一种电子设备,所述电子设备包括:
处理器;
用于存储处理器可执行指令的存储器;
其中,所述处理器被配置为执行上述FAQ系统的答案检索方法。
另外,本申请还提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序可由处理器执行以完成上述FAQ系统的答案检索方法。
本申请方案,通过用户问与FAQ语料库中所有问题的第一相似度,可以筛选出若干与用户问较为近似的指定标准问分组,并确定每一指定标准问分组相对于用户问的第一分组得分;基于每一指定标准问分组中标准问与用户问之间的第二相似度,可以确定每一指定标准问分组对应的第二分组得分;对第一分组得分和第二分组得分加权求和之后,可以得到每一指定标准问的集成得分,并以集成得分最高的指定标准问对应的标准答,作为用户问的答案;
在检索答案过程中,首先以包含标准问和相似问的所有问题的范围,确定与用户问较为相似的指定标准问分组,进而从指定标准问分组中确定标准问与用户问的第二相似度得分,作为第二分组得分;以第一分组得分和第二分组得分确定的集成得分,可以兼顾检索的广度特性和精度特性,从而可以更准确地获得用户问的答案。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例中所需要使用的附图作简单地介绍。
图1为本申请一实施例提供的FAQ语料库的组织形式示意图;
图2为本申请一实施例提供的FAQ系统的答案检索方法的应用场景示意图;
图3为本申请一实施例提供的电子设备的结构示意图;
图4为本申请一实施例提供的FAQ系统的答案检索方法的流程示意图;
图5为本申请一实施例提供的步骤410的细节流程示意图;
图6为本申请一实施例提供的步骤420的细节流程示意图;
图7为本申请一实施例提供的确定集成得分的示意图;
图8为本申请一实施例提供的FAQ系统的答案检索装置的框图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行描述。
相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本申请的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
图2为本申请实施例提供的FAQ系统的答案检索方法的应用场景示意图。如图2所示,该应用场景包括客户端20和服务端30;客户端20可以是主机、手机、平板电脑等用户终端,用于向服务端30发送用户问;服务端30可以是搭载FAQ系统的服务器、服务器集群或云计算中心,可以在FAQ系统中检测出对应于用户问的答案,并返回客户端20。
如图3所示,本实施例提供一种电子设备1,包括:至少一个处理器11和存储器12,图3中以一个处理器11为例。处理器11和存储器12通过总线10连接,存储器12存储有可被处理器11执行的指令,指令被处理器11执行,以使电子设备1可执行下述的实施例中方法的全部或部分流程。在一实施例中,电子设备1可以是上述服务端30,用于执行FAQ系统的答案检索方法。
存储器12可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(Static Random Access Memory,简称SRAM),电可擦除可编程只读存储器(Electrically Erasable Programmable Read-Only Memory,简称EEPROM),可擦除可编程只读存储器(Erasable Programmable Read Only Memory,简称EPROM),可编程只读存储器(Programmable Red-Only Memory,简称PROM),只读存储器(Read-Only Memory,简称ROM),磁存储器,快闪存储器,磁盘或光盘。
本申请还提供了一种计算机可读存储介质,存储介质存储有计算机程序,计算机程序可由处理器11执行以完成本申请提供的FAQ系统的答案检索方法。
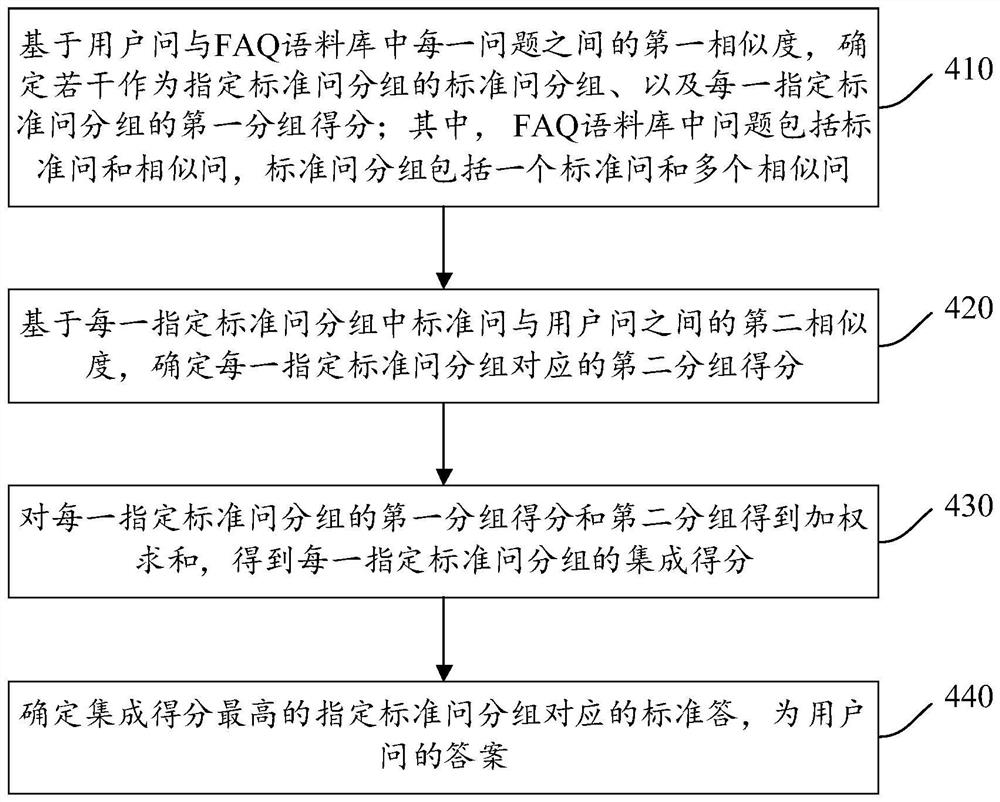
参见图4,为本申请一实施例提供的FAQ系统的答案检索方法的流程示意图,如图4所示,该方法可以包括以下步骤410-步骤440。
步骤410:基于用户问与FAQ语料库中每一问题之间的第一相似度,确定若干作为指定标准问分组的标准问分组、以及每一指定标准问分组的第一分组得分;其中,FAQ语料库中问题包括标准问和相似问,标准问分组包括一个标准问和多个相似问。
用户问为搭载FAQ系统的服务端需要答复的问题,服务端可以从与其对接的用户终端接收到用户问。用户问可能使用正式和规范的语言,也可能使用不规范的语言。
标准问分组包括一个标准问和多个相似问,标准问分组中的多个相似问与标准问对应,表达同一个意思。以图1为例,标准问1和相似问1.1、相似问1.2、相似问1.3、相似问1.4、相似问1.5构成一个标准问分组;标准问2和相似问2.1、相似问2.2、相似问2.3、相似问2.4构成一个标准问分组;标准问3和相似问3.1、相似问3.2构成一个标准问分组。
第一相似度可以通过相似度算法确定,用于表示用户问的文本,与标准问或相似问的文本之间的相似度。第一分组得分用于表示用户问的文本,与标准问分组内问题的文本的整体相似度。
服务端可以基于用户问与FAQ语料库中每一问题之间的相似度,筛选出若干与用户问足够近似的标准问分组,作为指定标准问分组,并可确定指定标准问分组对应的第一分组得分。
步骤420:基于每一指定标准问分组中标准问与用户问之间的第二相似度,确定每一指定标准问分组对应的第二分组得分。
其中,第二相似度可以通过相似度算法确定,用于表示用户问的文本,与每一指定标准问分组中标准问的文本之间的相似度。第二分组得分用于表示用户问的文本,与标准问分组内问题的文本的整体相似度。
在一实施例中,针对每一指定标准问分组中的标准问,可以将该标准问对应的第一相似度作为第二相似度,从而减少计算量,提高检索效率。
第二分组得分仅与指定标准问分组的标准问有关,因此,一般情况下,同一指定标准问分组的第一分组得分与第二分组得分不同。
步骤430:对每一指定标准问分组的第一分组得分和第二分组得到加权求和,得到每一指定标准问分组的集成得分。
针对每一指定标准问分组,服务端可以根据预配置的权重系数,对第一分组得分和第二分组得分加权求和,得到该指定标准问分组的集成得分。该集成得分为最终确定的用户问的文本,与指定标准问分组内问题的文本的整体相似度。
步骤440:确定集成得分最高的指定标准问分组对应的标准答,为用户问的答案。
在确定每一指定标准问分组对应的集成得分之后,服务端可以从多个集成得分中确定最高的集成得分,并将集成得分最高的指定标准问分组对应的标准答,作为用户问的答案。服务端可以向用户问的来源返回该标准答。
通过上述措施,依据第一相似度确定的第一分组得分,可以反映用户问与所有问题的相对相似性;依据第二相似度确定的第二分组得分,可以反映用户问与指定标准问分组内标准问的相对相似性。通过以第一分组得分和第二分组得分确定集成得分后,以集成得分确定用户问的答案,可以在检索答案时兼顾精度特征和广度特性,从而提高FAQ系统的整体检索准确性。
在一实施例中,参见图5,为本申请一实施例提供的步骤410的细节流程示意图,如图5所示,在执行步骤410时,可以执行如下步骤411-步骤413。
步骤411:基于用户问与每一问题之间的第一相似度,确定每一问题相对于用户问的第一相似度得分。
其中,第一相似度得分用于表示标准问或相似问的文本,与用户问的文本之间相似度的相对值。
服务端可以通过softmax函数对每个问题的第一相似度进行处理,从而得到每一问题相对于用户问的第一相似度得分。处理过程可通过如下公式(1)来表示:
这里,x
通过上述公式(1)确定的所有问题的第一相似度得分之和为1。
步骤412:根据所有问题的第一相似度得分,确定若干指定标准问分组。
在获得所有问题的第一相似度得分之后,可以依据多个第一相似度得分,筛选出整体文本与用户问的文本最为相似的若干标准问分组,作为指定标准问分组。
步骤413:基于每一指定标准问分组内每一问题对应的第一相似度得分,确定每一指定标准问分组对应的第一分组得分。
筛选出指定标准问分组之后,针对每一指定标准问分组,服务端可以获取该指定标准问分组内多个第一相似度得分,并根据多个第一相似度得分确定该指定标准问分组对应的第一分组得分。由于第一分组得分与分组内所有第一相似度得分相关,因此,第一分组得分可以从包含相似问和标准问的检索范围的维度上,表征指定标准问分组的文本与用户问的文本在整体上的相似性。
在一实施例中,服务端在根据所有问题的第一相似度得分,确定若干指定标准问分组时,可以筛选出第一相似度得分最高的指定数量的问题,作为指定问题。这里,指定数量可以根据经验值进行配置。示例性的,指定数量可以是标准问分组总量的百分之十,比如,标准问分组总量为100,指定数量可以是10。
筛选出的指定问题为与用户问的相对相似度最大的问题。一般,指定问题可以包括标准问和相似问;如果用户问的语言不规范,指定问题可能仅包含相似问。
在确定多个指定问题,服务端可以确定指定问题所在的若干标准问分组,包含指定问题的标准问分组在整体上与用户问较为相似,可以作为指定标准问分组。
在一实施例中,在基于每一指定标准问分组内每一问题对应的第一相似度得分,确定每一指定标准问分组对应的第一分组得分时,针对每一指定标准问分组,一种情况下,服务端可以确定该指定标准问分组中多个第一相似度得分的最大值,作为指定标准问分组的第一分组得分;另一种情况下,服务端可以确定该指定标准问分组中多个第一相似度得分的平均值,作为指定标准问分组的第一分组得分;再一种情况下,服务端可以确定该指定标准问分组中多个第一相似度得分的中位值,作为指定标准问分组的第一分组得分。
在以中位值作为第一分组得分时,若指定标准问分组内的问题数量为偶数,服务端可以将中间位置的两个第一相似度得分计算均值,并将该均值作为第一分组得分。
在一实施例中,服务端在执行步骤410之前,可以针对FAQ语料库中每一问题,根据第一相似度算法,确定该问题与用户问之间的第一相似度。
其中,第一相似度算法可以为bm25(Best Match 25)算法、编辑距离算法、编码向量距离算法等任意一种。
在一实施例中,参见图6,为本申请一实施例提供的步骤420的细节流程示意图,如图6所示,在执行步骤420时,可以执行如下步骤421-步骤422。
步骤421:基于每一指定标准问分组中标准问与用户问之间的第二相似度,确定每一标准问相对于用户问的第二相似度得分。
其中,第二相似度得分用于表示标准问的文本,与用户问的文本之间相似度的相对值。
服务端可以通过softmax函数对每个标准问的第二相似度进行处理,从而得到每一问题相对于用户问的第二相似度得分。处理过程可通过如下公式(2)来表示:
这里,x
通过上述公式(2)确定的所有指定标准问分组内标准问对应的第二相似度得分之和为1。
步骤422:针对每一指定标准问分组,将指定标准问分组内标准问的第二相似度得分,作为指定标准问分组的第二分组得分。
在获得各指定标准问分组内标准问对应的第二相似度得分之后,服务端可以将该第二相似度得分,作为标准问所在的指定标准问分组的第二分组得分。由于第二分组得分与分组内的标准问有关,第二分组得分可以从标准问的检索范围的维度上,表征指定标准问分组的文本与用户问的文本的相似性。
在一实施例中,服务端在执行步骤420之前,可以针对若干指定标准问分组的每一标准问,根据第二相似度算法,确定标准问与用户问之间的第二相似度。
其中,第二相似度算法可以为bm25算法、编辑距离算法、编码向量距离算法等任意一种。服务端所选择的第二相似度算法可以与第一相似度算法相同,也可以与第一相似度算法不同。
下面对FAQ系统的答案检索方法的整体流程进行说明:
示例性的,FAQ系统的FAQ语料库包括10个标准问分组,每一标准问分组均包括一个标准问和10个对应于标准问的相似问,每一标准问分组对应唯一的标准答。在这种情况下,FAQ语料库中一共有110个问题。
服务端在获取用户问之后,可以通过编码向量距离算法,计算用户问与110个问题中每一问题的第一相似度,共得到110个第一相似度。进一步的,通过softmax函数,确定每一问题的第一相似度得分。
服务端可以筛选出第一相似度得分最高的10个问题,作为指定问题,并可以确定这10个指定问题位于3个标准问分组内,将这3个标准问分组作为指定标准问分组,称为组1、组2、组3。服务端选择指定标准问分组中第一相似度得分的最大值,作为第一分组得分。此时,组1的第一分组得分为0.36,组2的第一分组得分为0.25,组3的第一分组得分为0.14。
服务端可以通过编码向量距离算法,分别计算三个指定标准问分组中标准问与用户问之间的第二相似度,并通过softmax函数,确定每一指定标准问分组内标准问的第二相似度得分,作为指定标准问分组的第二分组得分。此时,组1的第二分组得分为0.4,组2的第二分组得分为0.3,组3的第二分组得分为0.3。
服务端可以按照平均权重加权的方式,对每一指定标准问分组的第一分组得分和第二分组得分进行计算,得到组1的集成得分0.38,组2的集成得分0.275,组3的集成得分0.22。这种情况下,服务端可以将组1对应的标准答,作为用户问的答案。
参见图7,为本申请一实施例提供的确定集成得分的示意图,如图7所示,FAQ语料库包含三个标准问分组,各标准问分组内标准问分别标号为1、2、3,标准问1所在分组内,与其对应的相似问标号为1.1、1.2、1.3、1.4;标准问2所在分组内,与其对应的相似问标号为2.1、2.2、2.3、2.4;标准问3所在分组内,与其对应的相似问标号为3.1、3.2、3.3、3.4。
通过第一相似度算法确定用户问与每一问题的第一相似度,并基于第一相似度得到第一相似度得分。图7中得分1、得分1.1……得分3.4为各标号对应问题的第一相似度得分。从多个第一相似度得分中筛选出最大的5个第一相似度得分为得分1、得分1.3、得分1.4、得分2.2、得分2.4。这种情况下,可以确定指定标准问分组为标准问1和标准问2所在分组。通过指定标准问分组中的第一相似度得分,确定第一分组得分1和第一分组得分2。
通过第二相似度算法确定用户问与标准问1和标准问2之间的第二相似度,并以第二相似度确定第二相似度得分,作为第二分组得分1和第二分组得分2。依据第一分组得分1和第二分组得分1,可以得到标准问1所在分组的集成得分1;依据第一分组得分2和第二分组得分2,可以得到标准问2所在分组的集成得分2。在获得集成得分1和集成得分2之后,将集成得分高的一组对应的标准答,作为用户问的答案。
图8是本发明一实施例的一种FAQ系统的答案检索装置的框图,如图8所示,该装置可以包括:
第一确定模块810,用于基于用户问与FAQ语料库中每一问题之间的第一相似度,确定若干作为指定标准问分组的标准问分组、以及每一指定标准问分组的第一分组得分;其中,所述FAQ语料库中问题包括标准问和相似问,所述标准问分组包括一个标准问和多个相似问;
第二确定模块820,用于基于每一指定标准问分组中标准问与所述用户问之间的第二相似度,确定每一指定标准问分组对应的第二分组得分;
合成模块830,用于对每一指定标准问分组的第一分组得分和第二分组得到加权求和,得到每一指定标准问分组的集成得分;
第三确定模块840,用于确定所述集成得分最高的指定标准问分组对应的标准答,为所述用户问的答案。
上述装置中各个模块的功能和作用的实现过程具体详见上述FAQ系统的答案检索方法中对应步骤的实现过程,在此不再赘述。
在本申请所提供的几个实施例中,所揭露的装置和方法,也可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,附图中的流程图和框图显示了根据本申请的多个实施例的装置、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分,模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。在有些作为替换的实现方式中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
另外,在本申请各个实施例中的各功能模块可以集成在一起形成一个独立的部分,也可以是各个模块单独存在,也可以两个或两个以上模块集成形成一个独立的部分。
功能如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。