半胱氨酸蛋白酶
文献发布时间:2023-06-19 18:32:25
技术领域
本发明涉及显示IgG半胱氨酸蛋白酶活性的新型多肽及其活体内和活体外用途。所述多肽的用途包括用于预防或治疗由IgG介导的疾病和病症的方法,以及用于分析IgG和体外F(ab’)
背景技术
IdeS(化脓性链球菌的免疫球蛋白G降解酶,
然而,IdeS是免疫原性蛋白。也就是说,当IdeS用作治疗剂时,接受IdeS的对象的免疫系统将经常对其进行应答。免疫系统对IdeS的反应将通常涉及对IdeS特异性的抗体的产生。这些抗体在本文中可称为对IdeS特异性的抗药物抗体(ADA)或“IdeS特异性ADA”。一般来说,对IdeS的免疫应答(特别是IdeS特异性ADA的产生)可能会引起两种相关类型的问题。首先,可能减少IdeS的效力,例如由于ADA结合,可能需要较高或重复剂量来达到相同的效果。具有这种效果的ADA可以被称为“中和ADA”。其次,可能存在不想要的或甚至有害的并发症,诸如由ADA与IdeS的免疫复合物触发的高度炎症应答。在给定的对象中对IdeS特异性的ADA数量越高,则这些问题的可能性就越大。患者中IdeS特异性ADA分子的存在和数量可以通过任何合适的方法(诸如试剂特异性CAP FEIA(ImmunoCAP)测试或对来自患者的血清样品进行的滴度测定)来测定。高于临床医生确定的阈值,患者中IdeS特异性ADA分子的数量可能妨碍了IdeS的施用,或表明需要更高剂量的IdeS。这样较高的剂量可进而导致患者中IdeS特异性ADA分子的数量增加,从而妨碍了IdeS的进一步施用。
IdeS是化脓性链球菌的毒力因子,化脓性链球菌对常见的感染如扁桃体炎和链球菌性咽喉炎(strep throat)负有责任。因此,大多数人类对象在这种情况下已经遇到了IdeS,并且可能在血流中具有抗IdeS抗体。在来自人类对象(可能由于先前的链球菌感染)的血清样品中以及在IVIg(静脉内免疫球蛋白,
IdeZ是由马链球菌兽疫亚种(
因此,仍然需要针对人IgG具有高活性(优选高于野生型IdeZ,甚至更优选高于IdeS)的衍生自IdeZ的半胱氨酸蛋白酶。特别是,仍然需要针对人IgG1和IgG2具有高活性(优选高于野生型IdeZ,甚至更优选高于IdeS)的衍生自IdeZ的半胱氨酸蛋白酶。
发明内容
IdeS的全序列作为NCBI参考序列号WP_010922160.1是公众可获得的,并在本文中作为SEQ ID NO:6提供。该序列包括N末端甲硫氨酸,接着是28个氨基酸的分泌信号序列。N末端甲硫氨酸和信号序列(于N末端的总共29个氨基酸)通常被去除以形成成熟的IdeS蛋白,其序列作为Genbank登录号ADF13949.1是公众可获得的,并在本文中作为SEQ ID NO:4提供。
IdeZ的全序列作为NCBI参考序列号WP_014622780.1是公众可获得的并且其在本文中作为SEQ ID NO:5提供。该序列包括N末端甲硫氨酸,接着是33个氨基酸的分泌信号序列。N末端甲硫氨酸和信号序列(于N末端的总共34个氨基酸)通常被去除以形成成熟的IdeZ蛋白,其序列在本文中作为SEQ ID NO:3提供。
本发明人已经能够识别IdeZ的序列中的特定位置,当如本文所述的进行修饰时,导致新型多肽,该新型多肽相对于IdeZ具有增加的针对人IgG的IgG半胱氨酸蛋白酶活性。本发明的多肽的对人IgG的IgG半胱氨酸蛋白酶活性(例如在切割人IgG时)优选地至少与IdeS的针对人IgG的IgG半胱氨酸蛋白酶活性一样高。本发明的多肽在切割人IgG上可能比IdeS的IgG半胱氨酸蛋白酶更有效,特别是当IgG是IgG1或IgG2同种型时。本发明的多肽在切割人IgG上可能比IdeS的IgG半胱氨酸蛋白酶更有效,特别是当用IgG1的第二链的切割来衡量时。本发明的多肽在切割IgG1上可能比IgG2更有效。本发明的多肽通常比IdeS具有更低的免疫原性,并且可优选地不比IdeZ具有更多的免疫原性。
除非另有说明,对本文公开的多肽中氨基酸位置的编号的所有提及均基于从N末端开始的SEQ ID NO:3中相应位置的编号。因此,由于SEQ ID NO:1缺少SEQ ID NO:5的N末端甲硫氨酸和33个氨基酸信号序列,因此将在SEQ ID NO:1的N末端的天冬氨酸(D)残基称为位置35,如这是SEQ ID NO:5中的相应位置一样。应用该编号方案,IdeS的IgG半胱氨酸蛋白酶活性的最关键残基是对应于SEQ ID NO:5的位置102处的半胱氨酸(C)。可能对IgG半胱氨酸蛋白酶活性重要的其他残基是SEQ ID NO:5的位置92处的赖氨酸(K)、位置272处的组氨酸(H)以及位置294和296处的两个天冬氨酸(D)。人们还发现,删除SEQ ID NO: 1的N末端处的前20个残基可以提高包含这种变化的多肽的效价,和/或可以减少免疫原性而不对效价产生负面影响。SEQ ID NO:1的N末端处的前20个残基由连续序列DDYQRNATEAYAKEVPHQIT组成。因此,根据本发明的多肽可以包含SEQ ID NO: 2的氨基酸序列(不包括连续序列DDYQRNATEAYAKEVPHQIT)。SEQ ID NO: 1的前20个残基对应于SEQ ID NO: 5的位置35-54。这种特殊的修饰在本文中可以通过术语“D35_T54del”被识别。因此,由于SEQ ID NO: 2缺乏N末端蛋氨酸,SEQ ID NO: 5的33个氨基酸信号序列,并且进一步删除了对应于SEQ IDNO: 5的位置35-54的序列DDYQRNATEAYAKEVPHQIT,因此将在SEQ ID NO: 2的N末端的丝氨酸(S)残基称为位置55,如这是SEQ ID NO: 5中的相应位置一样。
因此,在一个方面,本发明提供了一种多肽,其具有IgG半胱氨酸蛋白酶活性且包含如下氨基酸序列或由如下氨基酸序列组成:
(i)SEQ ID NO: 1;或者
(ii)SEQ ID NO: 2;或者
(iii)SEQ ID NO: 1或SEQ ID NO: 2的变体,其分别相对于SEQ ID NO: 1或SEQID NO: 2具有1、2、3、4、5、6、7、8、9或10个氨基酸修饰,条件是该序列保留:
(a)对应于SEQ ID NO: 5的位置95的位置处的天冬酰胺(N),
(b)对应于SEQ ID NO: 5的位置99的位置处的天冬氨酸(D),以及
(c)对应于SEQ ID NO: 5的位置226的位置处的天冬酰胺(N),
并且条件是当在同一测定中测量时,所述多肽至少在切割人IgG上与分别由SEQID NO: 1或2的氨基酸序列组成的多肽一样有效。
本发明还提供编码或表达本发明的多肽的多核苷酸、表达载体或宿主细胞。
本发明还提供一种治疗或预防对象中由IgG抗体介导的疾病或病症的方法,所述方法包含向对象施用治疗或预防有效量的本发明的多肽。该方法通常可以包含向对象多次施用所述多肽。
本发明还提供了一种活体外处理取自患者的血液的方法,典型地是患有由IgG抗体介导的疾病或病症的患者,该方法包含使血液与本发明的多肽接触。
本发明还提供了一种用于改善治疗或治疗剂对对象益处的方法,所述方法包含(a)向对象施用本发明的多肽;以及(b)随后将所述治疗或所述治疗剂施用于对象;其中:
-所述治疗是器官移植或者所述治疗剂是抗体,基因疗法(诸如病毒载体),对缺陷性内源性因子(诸如酶、生长或凝血因子)的替代,或者细胞治疗;
-所施用的所述多肽的量足以切割存在于对象血浆中的基本上所有IgG分子;以及
-步骤(a)和步骤(b)由足以切割存在于对象血浆中基本上所有IgG分子的时间间隔分隔。
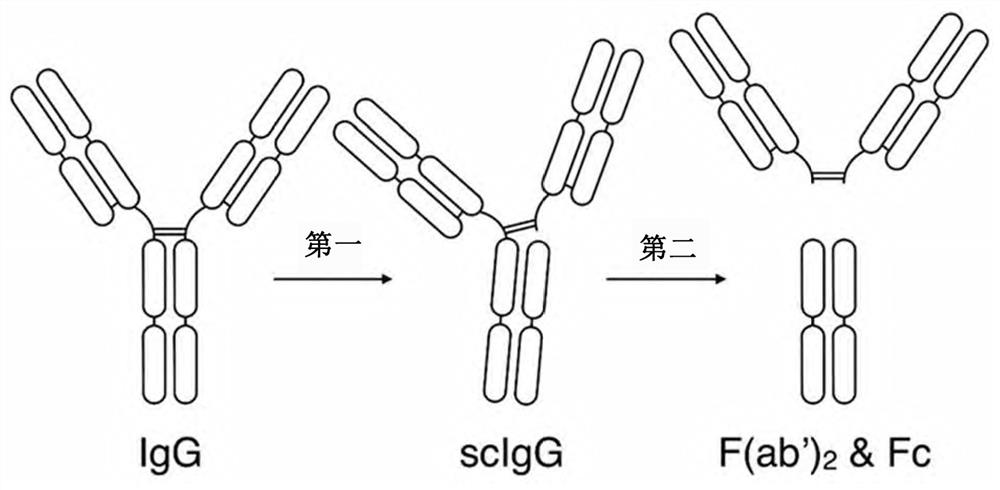
本发明还提供一种生成IgG的Fc片段、Fab片段或F(ab’)
还提供了用于实施根据本发明的方法的试剂盒。
附图说明
图1示出了pCART239(SEQ ID NO: 1,N末端为Met,C末端为His标签)的表达和纯化的SDS-PAGE分析。(A)pCART239的过表达——泳道1和2示出了从用IPTG诱导后1小时收获的细胞获得的裂解物;泳道3示出了汇集的裂解物。(B)pCART239的纯化——泳道1示出了NiNTA纯化过程中流过的流,显示裂解物中杂质的去除,泳道2和3代表纯化的pCART239(分别加样~0.5 µg和~3.0 µg蛋白)。
图2示出了用于可视化由IgG1(Humira)与IdeS和测试的IdeZ变体孵育产生的切割产物的代表性SDS-PAGE凝胶的结果,如图所示。泳道上方的浓度表示测试的IdeS/IdeZ变体的浓度。图A和B代表两个独立的实验。
图3示出了用于可视化由IgG2(XGEVA)与IdeS和测试的IdeZ变体孵育产生的切割产物的代表性SDS-PAGE凝胶的结果,如图所示。泳道上方的浓度表示测试的IdeS/IdeZ变体的浓度。图A和B代表两个独立的实验。
图4示出了用于可视化由(A)IgG1(Humira)、(B)IgG2(XGEVA)、(C)IgG3、(D)IgG4与IdeS和N240孵育产生的切割产物的代表性SDS-PAGE凝胶的结果,如图所示。泳道上方的浓度表示测试的IdeS/IdeZ变体的浓度。
图5示出了试验中一式三份样品的平均电化学发光(ECL)值的拟合滴定曲线,以确定与IdeS相比,N240的效价(IgG1的切割效力)。误差线代表SD。
图6示出了在有和没有诱饵(decoy)(pCART239的无活性版本)的情况下pCART239对血清IgG的消化。使用诱饵可以减少血清中存在的ADA的抑制作用。泳道上方的浓度表示测试的IdeZ变体的浓度。
图7示出了试验中一式三份样品和两个单独的稀释系列的平均电化学发光(ECL)值的拟合滴定曲线,以确定N240和IdeS在血清中的效价(IgG的切割效力)。误差线代表SD。
图8示出了对应于来自40个健康个体的血清和一个正常血清库(n=100)中预先存在的N240和IdeS ADA的水平的平均ECL值。
图9示出了本发明的多肽对IgG的分步切割的示意图。
SEQ ID NO: 1是本发明的一种多肽的序列。
具体实施方式
应当理解,所公开的产品和方法的不同应用可以根据本领域的具体需要进行调整。还应当理解,本文使用的术语仅用于描述本发明的具体实施方案的目的,而不是限制性的。
此外,在本说明书和所附权利要求书中使用的情况下,除非内容另有明确指示,否则单数形式“一”、“一个/一种”和“该/所述”包括复数指示物。因此,例如,提及“一种多肽”包括“多种多肽”等。
“多肽”在本文中以其最广泛的含义用于指两个或更多个亚基氨基酸、氨基酸类似物或其他肽模拟物的化合物。因此,术语“多肽”包括短肽序列以及还包括更长的多肽和蛋白质。如本文所用,术语“氨基酸”是指天然和/或非天然或合成的氨基酸(包括D或L光学异构体二者),以及氨基酸类似物和肽模拟物。
术语“患者”和“对象/受试者”可互换使用,并且通常是指人。除非另有说明,提及IgG通常是指人IgG。
本文引用的所有出版物、专利和专利申请,无论是上文还是下文,均通过引用整体并入本文。
本发明涉及具有IgG半胱氨酸蛋白酶活性的新型多肽,其中所述多肽在切割人IgG上比IdeZ更有效。本发明的多肽针对人IgG的IgG半胱氨酸蛋白酶活性优选地至少与IdeS针对人IgG的IgG半胱氨酸蛋白酶活性一样高。此外,本发明的多肽通常比IdeS具有更低的免疫原性,并且可以优选地不超过IdeZ的免疫原性。在相对于本发明的多肽的对照或比较的上下文中,“IdeS”和“IdeZ”分别是指由氨基酸序列SEQ ID NO:4和3组成的多肽。可替换地或此外,当用作对照或比较时,“IdeS”和“IdeZ”可以分别指包含氨基酸序列SEQ ID NO:4和3的多肽,其具有在N末端附加的甲硫氨酸(M)残基和/或在C末端的标签,以帮助在标准细菌表达系统中表达和从标准细菌表达系统分离。合适的标签包括组氨酸标签,其可以直接连接到多肽的C末端或者通过任何合适的接头序列(诸如3个、4个或5个甘氨酸残基)间接连接。组氨酸标签通常由六个组氨酸残基组成,尽管它可以比此更长(通常高达7个、8个、9个、10个或20个氨基酸)或更短(例如5个、4个、3个、2个或1个氨基酸)。本文使用的示例性IdeS多肽的序列是作为SEQ ID NO:13而被提供的对照。该多肽包含具有附加的N末端甲硫氨酸和组氨酸标签的序列SEQ ID NO:4,并且在本文中可以称为pCART124。本文使用的示例性IdeZ多肽的序列是作为SEQ ID NO:14而被提供的对照。该多肽包含具有附加的N末端甲硫氨酸和组氨酸标签的序列SEQ ID NO:3,并且在本文中可以称为pCART144。
IgG半胱氨酸蛋白酶活性可以通过任何合适的方法来评估,例如通过将多肽与含有IgG的样品孵育并确定IgG切割产物的存在。在存在或不存在抑制剂(诸如中和抗体)的情况下可以评估效力。然而,本文中的效力通常是指在不存在这种抑制剂的情况下评估的效力,除非另有说明。合适的方法在实施例中描述。多肽在切割IgG上的效力在本文中可称为多肽的“效价(potency)”。本发明的多肽的效价优选地为在同一种测定中测量的IdeZ的效价的至少2.0倍大。本发明的多肽的效价可以为在同一种测定中测量的IdeZ的效价的至少1.5倍、2.0倍、2.5倍、3.0倍、4.0倍、4.5倍、5.0倍、6.0倍、7.0倍、7.5倍或8.0倍大。可替换地或另外的,本发明的多肽的效价优选地至少等于在同一种测定中测量的IdeS的效价。可替换地或另外的,本发明的多肽的效价优选地至少大于在同一种测定中测量的IdeS的效价。本发明的多肽的效价可以为在同一种测定中测量的IdeS的效价的至少1.1倍、1.2倍、1.3倍、1.4倍、1.5倍、1.6倍、1.7倍、1.8倍、1.9倍、2.0倍、2.5倍、3.0倍、4.0倍大。本发明的多肽的效价优选地为在同一种测定中测量的IdeS的效价的至少2.0倍,更优选地至少3.0或至少4.0倍大。
本发明的多肽通常比IdeS具有更低的免疫原性,因此相对于IdeZ的效价已增加的效价和/或与IdeS的效价相当的效价是针对人IgG的半胱氨酸蛋白酶活性的可接受的最低标准。然而,相对于IdeS的效价增加是理想的提高。这种效价增加通常将使得较低剂量的本发明的多肽的使用与更高剂量的IdeS具有相同的治疗效果。较低剂量还可以允许本发明的多肽相对于IdeS的更多数目的重复施用。这是因为较低剂量的使用减少了与治疗剂的免疫原性相关的问题,因为免疫系统对于以较低浓度存在的试剂不太有可能应答或将对其应答较少。
用于评估多肽在切割IgG上的效力的测定,即用于评估多肽的效价的测定,是本领域熟知的,并且可以使用任何合适的测定。合适的测定包括基于ELISA的测定,诸如实施例中描述的测定。在这种测定中,测定板的孔通常将用抗体靶(诸如牛血清白蛋白(BSA))包被。然后将待测试的多肽的样品加入到孔中,随后是靶特异性抗体的样品,该抗体是在该实施例中对BSA特异性的抗体(并且其对IdeS的切割敏感)。允许多肽和抗体在适合于IgG半胱氨酸蛋白酶活性的条件下相互作用。在适当的间隔后,将洗涤测定板,并将在适合与靶特异性抗体结合的条件下加入特异性结合该靶特异性抗体的Fc区的检测抗体。检测抗体将结合于在每个孔中已与靶结合的任何完整靶特异性抗体的Fc区。洗涤后,存在于孔中的检测抗体的量将与结合到该孔的靶特异性抗体的量成比例。检测抗体可以直接地或间接地缀合到标记物或另一报告体系(诸如酶)上,使得可以确定残留在每个孔中的检测抗体的量。在孔中存在的所测试的多肽的效价越高,则完整的靶特异性抗体将保留得越少,并因此将存在越少的检测抗体。通常,在给定测定板上的至少一个孔将包括IdeS取代待测试的多肽,使得所测试的多肽的效价可以直接与IdeS的效价进行比较。还可以包括IdeZ或IdeZ的已知变体进行比较。
其他测定可以通过直接可视化和/或定量由所测试的多肽切割IgG而产生的IgG片段来确定所测试的多肽的效价。这种类型的测定也在实施例中描述。这样的测定通常将IgG样品与在滴定系列中以不同浓度的测试多肽(或与作为对照的IdeS、IdeZ和IdeZ的已知变体中的一种或多种)孵育。然后使用凝胶电泳(例如通过SDS-PAGE)分离以各浓度孵育产生的产物。然后完整IgG和由IgG的切割产生的片段可以通过尺寸来识别,并通过用合适染料染色的强度来定量。切割片段的数量越大,则以给定浓度的所测试的多肽的效价就越高。本发明的多肽通常以比IdeZ和/或IdeS更低的浓度(在滴定系列中的较低点)产生可检测量的切割片段。这种类型的测定还可以能够识别在切割IgG分子的第一或第二重链上更有效的测试多肽,因为也可以确定由每个切割事件产生的不同片段的数量。适用于本文所述效价测定的IgG样品可以来自不同的来源。例如,可以使用商业抗体制剂。商业抗体制剂通常是纯的,具有同种型和亚类特异性。替代地,可以使用包含混合的IgG群体的样品,如人血清。包含IgG的血清的样品可以包含针对IdeS和/或IdeZ的ADA。因此,适用于本文所述效价测定的IgG样品可以包含ADA。本发明的多肽在切割IgG分子的第一链上可能比第二链更有效(与IdeS和/或IdeZ相比)(参见图9中的示意图),特别是当IgG是IgG2同种型时。替代地,本发明的多肽在切割IgG分子的第二链上可能比第二链更有效(与IdeS和/或IdeZ相比)(参见图9中的示意图),特别是当IgG是IgG1同种型时。本发明的多肽可以在切割IgG1上比IgG2更有效(当与IdeS和/或IdeZ相比时)。
也可以使这种类型的测定适应于确定IdeS特异性ADA的存在可以降低本发明的多肽的效价的程度。在该适应性测定中,当将IgG样品与测试多肽(或与作为对照的IdeS)孵育时,包含与反应介质一起的含有IdeS特异性ADA的血清或IVIg制品。优选地,本发明的多肽的效价不受ADA的存在的影响,或者在同一种测定中相比于IdeS的效价,本发明的多肽的效价被ADA的存在所降低得更少。换言之,优选地,IdeS特异性ADA对本发明的多肽的中和效应与在同一种测定中所测量的IdeS特异性ADA对IdeS的中和效应相同或较之更低。
如上所述,本发明的多肽通常比IdeS具有更低的免疫原性。也就是说,当以相等的剂量或浓度存在并且在同一种测定中测量时,本发明的多肽可以导致与IdeS相同的免疫应答或优选地较之更低的免疫应答。本发明的多肽的免疫原性通常不超过在同一种测定中所测量的IdeS的免疫原性的50%、不超过45%、不超过40%、不超过35%、不超过30%或不超过25%。优选地,本发明的多肽的免疫原性不超过在同一种测定中所测量的IdeS的免疫原性的25%。
用于评估多肽的免疫原性的测定也是本领域熟知的,并且可以使用任何合适的测定。用于评估多肽的免疫原性相对于IdeS的免疫原性的优选测定涉及评估对IdeS特异性的ADA还与本发明的多肽结合的程度。实施例中描述了这种类型的测定。患者中IdeS特异性ADA分子的存在和数量可以通过任何合适的方法来确定,例如制剂特异性CAP FEIA(ImmunoCAP)测试或对患者血清样品进行的滴度测定。
一种这样的测定涉及对IdeS与测试多肽之间对于结合IdeS特异性ADA的竞争的测试。通常,将测定板的孔用IdeS包被,随后施用含有IdeS特异性ADA(例如IVIg制品)和测试多肽(或作为对照的IdeS)的溶液的预孵育混合物。预孵育是在IgG半胱氨酸蛋白酶活性的抑制剂(例如碘乙酸(IHAc))存在的情况下和高盐浓度下进行的,使得仅允许蛋白质与ADA之间的高亲和力结合。允许已预孵育的混合物与IdeS包被的孔相互作用。任何不结合测试多肽的IdeS特异性ADA将与孔上的IdeS结合。在合适的间隔后,将洗涤测定板,并在适合结合的条件下加入特异性结合IgG的检测抗体。检测抗体将与每个孔中已结合于IdeS的任何ADA结合。洗涤后,存在于孔中的检测抗体的量将与已结合于测试多肽的ADA的量成反比。检测抗体可以直接地或间接地缀合到标记物或另一报告体系(诸如酶)上,使得可以确定残留在每个孔中的检测抗体的量。通常,给定测定板上的至少一个孔将用IVIg和IdeS的预孵育混合物代替待测试的多肽进行测试,使得ADA与所测试的多肽的结合可直接地与对IdeS的结合进行比较。也可以包括IdeZ作为进一步对照。
另一种合适的测定包括测试不同浓度的IdeS特异性ADA(例如IVIg制品)的滴定系列相比于作为对照的IdeS和/或IdeZ与测试多肽结合的程度。优选地,相对于可检测到与IdeS结合的ADA的浓度,本发明的多肽将需要更高的ADA结合浓度以成为可检测到的。实施例中描述了这样的测定。这样的测定通常包括用测试多肽或对照包被测定板的孔,随后用来自滴定系列的不同浓度的IdeS特异性ADA与每个孔孵育。孵育是在IgG半胱氨酸蛋白酶活性的抑制剂(例如碘乙酸(IHAc))存在的情况下并在高盐浓度下进行的,使得仅允许蛋白质与ADA之间的高亲和力结合。在合适的间隔后,将洗涤测定板,并在适合结合的条件下加入特异性结合IgG F(ab′)
本节列出了本发明的多肽的结构特征,其此外适用于前面部分中概述的功能特征。
本发明的多肽通常具有至少100个、150个、200个、250个、260个、270个、280个、290个、300个或310个氨基酸的长度。本发明的多肽通常具有不大于400个、350个、340个、330个、320个或315个氨基酸的长度。应当理解,上述列出的下限中的任一者可以与上述列出的上限中的任一者组合,以提供本发明的多肽的长度范围。例如,多肽可以具有100个至400个氨基酸的长度,或具有250个至350个氨基酸的长度。多肽优选地具有290个至320个氨基酸的长度,最优选地具有300个至315个氨基酸的长度。
本发明的多肽的初级结构(氨基酸序列)是SEQ ID NO: 1,其是基于野生型成熟IdeZ序列(SEQ NO: 3)的特定变体。话句话说,SEQ ID NO: 1与SEQ ID NO: 3通过初级多肽序列中的一组特定点突变相关(与SEQ ID NO: 3相比),这些突变负责提高其针对人IgG的效价。
本发明的另一种多肽是SEQ ID NO:2,其与SEQ ID NO:1相关。SEQ ID NO: 2除了在SEQ ID NO: 1的N末端处缺失前20个氨基酸(对应于连续的序列DDYQRNATEAYAKEVPHQIT)外,与SEQ ID NO: 1相同。换句话说,与野生型IdeZ序列(SEQ ID NO: 3)相比,SEQ ID NO:2在初级多肽序列的点突变方面也与SEQ ID NO: 1相同。
本发明还涉及SEQ ID NO: 1或SEQ ID NO: 2的变体,该变体分别相对于SEQ IDNO: 1或SEQ ID NO: 2具有1、2、3、4、5、6、7、8、9或10个氨基酸修饰,条件是该序列保留:(a)对应于SEQ ID NO: 5的位置95的位置处的天冬酰胺(N),(b)对应于SEQ ID NO: 5的位置99的位置处的天冬氨酸(D),和(c)对应于SEQ ID NO: 5的位置226的位置处的天冬酰胺(N),并且条件是当在同一测定中测量时,所述多肽至少在切割人IgG上与分别由SEQ ID NO: 1或2的氨基酸序列组成的多肽一样有效。任选地,SEQ ID NO: 1或SEQ ID NO: 2的变体中的一个或多个氨基酸修饰不导致与SEQ ID NO: 3的多肽序列中相应位置中存在的相同氨基酸,优选地,其中所有修饰不导致与SEQ ID NO: 3的多肽序列中相应位置中存在的相同氨基酸。
本发明的多肽序列包含SEQ ID NO: 1或SEQ ID NO: 2的氨基酸序列的变体,其中相对于SEQ ID NO: 1或SEQ ID NO: 2的序列进行了1、2、3、4、5、6、7、8、9或10个氨基酸修饰,例如氨基酸增加、删除或取代,所述序列必须保留:(a)对应于SEQ ID NO: 5的位置95的位置处的天冬酰胺(N),(b)对应于SEQ ID NO: 5的位置99的位置处的天冬氨酸(D),和(c)对应于SEQ ID NO: 5的位置226的位置处的天冬酰胺(N)。另外,这些修饰最好是保守的氨基酸取代。SEQ ID NO: 1或SEQ ID NO: 2的氨基酸序列的变体可以包含一个或多个修饰(分别相对于SEQ ID NO: 1或SEQ ID NO: 2作出),这些修饰不会导致与SEQ ID NO: 3的多肽序列中相应位置中存在的氨基酸相同。优选地,在SEQ ID NO: 1或SEQ ID NO: 2的氨基酸序列的变体中,所有修饰(分别相对于SEQ ID NO: 1或SEQ ID NO: 2作出)不会导致与SEQ ID NO: 3的多肽序列中相应位置中存在的氨基酸相同。
保守取代用类似化学结构、类似化学性质和/或类似侧链体积的其他氨基酸代替氨基酸。引入的氨基酸可能具有与其代替的氨基酸相似的极性、亲水性、疏水性、碱度、酸度、中性或电荷。替代地,保守取代可以引入另一芳族或脂族的氨基酸,代替预先存在的芳族或脂族的氨基酸。保守的氨基酸变化是本领域公知的,并且可以根据如下表A1中所限定的20种主要氨基酸的性质进行选择。当氨基酸具有相似的极性时,这可以通过参考表A2中氨基酸侧链的亲水尺度(hydropathy scale)来确定。
氨基酸序列SEQ ID NO: 1或SEQ ID NO: 2中的某些残基(除对应于SEQ ID NO: 5的位置95、99和226外)优选地保留在包含1、2、3、4、5、6、7、8、9或10个氨基酸修饰的变体序列中。例如,所述变体序列通常保留已知是IgG半胱氨酸蛋白酶活性所需的某些残基。因此,在本发明的多肽的氨基酸序列中必须保留对应于SEQ ID NO:5的位置102的半胱氨酸。任选地,还保留了对应于SEQ ID NO:5的位置92的赖氨酸(K)、对应于SEQ ID NO:5的位置272的组氨酸(H)以及对应于SEQ ID NO:5的位置294和位置296的每一个的天冬氨酸(D)。因此,根据本发明的SEQ ID NO:或SEQ ID NO:2的多肽变体通常在应于SEQ ID NO:5的位置102的位置处具有半胱氨酸(C);以及任选地在对应于SEQ ID NO:5的位置92、位置272、位置294和位置296的位置处分别具有赖氨酸(K)、组氨酸(H)、天冬氨酸(D)和天冬氨酸酸(D)。
本发明人还确定,对SEQ ID NO: 1或SEQ ID NO: 2序列的某些其他修饰可以增加本发明多肽的效价和/或可以减少IdeS特异性ADA对本发明多肽的识别。因此,根据本发明的SEQ ID NO: 1或SEQ ID NO: 2的多肽变体可以包含在对应于SEQ ID NO: 5的位置84、93、97、137、139、140、147、150、162、165、166、171、174、205、226、237、239、243、250、251、254、255、282、288、312、315、347、349的1、2、3、4、5、6、7、8、9或10个位置处进行的氨基酸取代。
取代通常用具有不同性质的另一种氨基酸来替代现有的氨基酸。例如,不带电荷的氨基酸可以被带电荷的氨基酸替代,反之亦然。处于这些位置的优选取代在下表B中使用单个字母代码而列出:
每种取代在本文可以使用通过组合从左到右的每行的第一列、第二列和第三列中的条目而获得的项来提及。例如,表B的第一行中的取代在本文中可以称为“H84N”,第二行中的取代可以被称为“A93T”,依此类推。7
下表C总结了相对于野生型IdeZ序列(SEQ ID NO:3)做出的变化以生产本文描述的某些多肽的氨基酸序列。
本文提到的某些多肽的氨基酸序列全长在下面再现。
DDYQRNATEAYAKEVPHQITSVWTKGVTPPEQFTQGEDVIHAPYLAHQGWYDITKAFNGKDDLLCGAATAGNMLHWWFDQNKTEIEAYLSKHPEKQKIIFRNQELFDLKAAIDTKDSQTNSQLFNYFRDKAFPNLSARQLGVMPDLVLDMFINGYYLNVFKTQSTDVNRPYQDKDKRGGIFDAVFTRGNQTTLLTARHDLKNKGLNDISTIIKQELTEGRALALSHTYANVSISHVINLWGADFNAEGNLEAIYVTDSDANASIGMKKYFVGINAHGHVAISAKKIEGENIGAQVLGLFTLSSGKDIWQKLS
SEQ ID NO: 2
SVWTKGVTPPEQFTQGEDVIHAPYLAHQGWYDITKAFNGKDDLLCGAATAGNMLHWWFDQNKTEIEAYLSKHPEKQKIIFRNQELFDLKAAIDTKDSQTNSQLFNYFRDKAFPNLSARQLGVMPDLVLDMFINGYYLNVFKTQSTDVNRPYQDKDKRGGIFDAVFTRGNQTTLLTARHDLKNKGLNDISTIIKQELTEGRALALSHTYANVSISHVINLWGADFNAEGNLEAIYVTDSDANASIGMKKYFVGINAHGHVAISAKKIEGENIGAQVLGLFTLSSGKDIWQKLS
SEQ ID NO: 3(IdeZ成熟序列)
DDYQRNATEAYAKEVPHQITSVWTKGVTPLTPEQFRYNNEDVIHAPYLAHQGWYDITKAFDGKDNLL
SEQ ID NO: 4(IdeS成熟序列)
DSFSANQEIRYSEVTPYHVTSVWTKGVTPPANFTQGEDVFHAPYVANQGWYDITKTFNGKDDLLCGAATAGNMLHWWFDQNKDQIKRYLEEHPEKQKINFNGEQMFDVKEAIDTKNHQLDSKLFEYFKEKAFPYLSTKHLGVFPDHVIDMFINGYRLSLTNHGPTPVKEGSKDPRGGIFDAVFTRGDQSKLLTSRHDFKEKNLKEISDLIKKELTEGKALGLSHTYANVRINHVINLWGADFDSNGNLKAIYVTDSDSNASIGMKKYFVGVNSAGKVAISAKEIKEDNIGAQVLGLFTLSTGQDSWNQTN
SEQ ID NO: 5(IdeZ全序列)
MKTIAYPNKPHSLSAGLLTAIAIFSLASSNITYADDYQRNATEAYAKEVPHQITSVWTKGVTPLTPEQFRYNNEDVIHAPYLAHQGWYDITKAFDGKDNLL
SEQ ID NO: 6 (IdeS 全序列)
MRKRCYSTSAAVLAAVTLFVLSVDRGVIADSFSANQEIRYSEVTPYHVTSVWTKGVTPPANFTQGEDVFHAPYVANQGWYDITKTFNGKDDLLCGAATAGNMLHWWFDQNKDQIKRYLEEHPEKQKINFNGEQMFDVKEAIDTKNHQLDSKLFEYFKEKAFPYLSTKHLGVFPDHVIDMFINGYRLSLTNHGPTPVKEGSKDPRGGIFDAVFTRGDQSKLLTSRHDFKEKNLKEISDLIKKELTEGKALGLSHTYANVRINHVINLWGADFDSNGNLKAIYVTDSDSNASIGMKKYFVGVNSAGKVAISAKEIKEDNIGAQVLGLFTLSTGQDSWNQTN
SEQ ID NO: 7 (pCART207)
MDDYQRNATEAYAKEVPHQITSVWTKGVTPPEQFTQGEDVIHAPYLAHQGWYDITKAFDGKDNLLCGAATAGNMLHWWFDQNKTEIEAYLSKHPEKQKIIFRNQELFDLKAAIDTKDSQTNSQLFNYFRDKAFPNLSARQLGVMPDLVLDMFINGYYLNVFKTQSTDVNRPYQDKDKRGGIFDAVFTRGDQTTLLTARHDLKNKGLNDISTIIKQELTEGRALALSHTYANVSISHVINLWGADFNAEGNLEAIYVTDSDANASIGMKKYFVGINAHGHVAISAKKIEGENIGAQVLGLFTLSSGKDIWQKLS
SEQ ID NO: 8 (pCART229)
MDDYQRNATEAYAKEVPHQITSVWTKGVTPPEQFTQGEDVIHAPYLAHQGWYDITKAFDGKDNLLCGAATAGNMLHWWFDQNKTEIEAYLSKHPEKQKIIFRNQELFDLKAAIDTKDSQTNSQLFNYFRDKAFPNLSARQLGVMPDLVLDMFINGYYLNVFKTQSTDVNRPYQDKDKRGGIFDAVFTRGNQTTLLTARHDLKNKGLNDISTIIKQELTEGRALALSHTYANVSISHVINLWGADFNAEGNLEAIYVTDSDANASIGMKKYFVGINAHGHVAISAKKIEGENIGAQVLGLFTLSSGKDIWQKLS
SEQ ID NO: 9 (pCART239)
MDDYQRNATEAYAKEVPHQITSVWTKGVTPPEQFTQGEDVIHAPYLAHQGWYDITKAFNGKDDLLCGAATAGNMLHWWFDQNKTEIEAYLSKHPEKQKIIFRNQELFDLKAAIDTKDSQTNSQLFNYFRDKAFPNLSARQLGVMPDLVLDMFINGYYLNVFKTQSTDVNRPYQDKDKRGGIFDAVFTRGNQTTLLTARHDLKNKGLNDISTIIKQELTEGRALALSHTYANVSISHVINLWGADFNAEGNLEAIYVTDSDANASIGMKKYFVGINAHGHVAISAKKIEGENIGAQVLGLFTLSSGKDIWQKLSGGGHHHHHH
SEQ ID NO: 10 (N240)
MDDYQRNATEAYAKEVPHQITSVWTKGVTPPEQFTQGEDVIHAPYLAHQGWYDITKAFNGKDDLLCGAATAGNMLHWWFDQNKTEIEAYLSKHPEKQKIIFRNQELFDLKAAIDTKDSQTNSQLFNYFRDKAFPNLSARQLGVMPDLVLDMFINGYYLNVFKTQSTDVNRPYQDKDKRGGIFDAVFTRGNQTTLLTARHDLKNKGLNDISTIIKQELTEGRALALSHTYANVSISHVINLWGADFNAEGNLEAIYVTDSDANASIGMKKYFVGINAHGHVAISAKKIEGENIGAQVLGLFTLSSGKDIWQKLS
SEQ ID NO: 11 (pCART242)
MSVWTKGVTPPEQFTQGEDVIHAPYLAHQGWYDITKAFNGKDDLLCGAATAGNMLHWWFDQNKTEIEAYLSKHPEKQKIIFRNQELFDLKAAIDTKDSQTNSQLFNYFRDKAFPNLSARQLGVMPDLVLDMFINGYYLNVFKTQSTDVNRPYQDKDKRGGIFDAVFTRGNQTTLLTARHDLKNKGLNDISTIIKQELTEGRALALSHTYANVSISHVINLWGADFNAEGNLEAIYVTDSDANASIGMKKYFVGINAHGHVAISAKKIEGENIGAQVLGLFTLSSGKDIWQKLSGGGHHHHHH
SEQ ID NO: 12 (pCART243 –无活性IdeZ变体)
MDDYQRNATEAYAKEVPHQITSVWTKGVTPPEQFTQGEDVIHAPYLAHQGWYDITKAFNGKDDLLGGAATAGNMLHWWFDQNKTEIEAYLSKHPEKQKIIFRNQELFDLKAAIDTKDSQTNSQLFNYFRDKAFPNLSARQLGVMPDLVLDMFINGYYLNVFKTQSTDVNRPYQDKDKRGGIFDAVFTRGNQTTLLTARHDLKNKGLNDISTIIKQELTEGRALALSHTYANVSISHVINLWGADFNAEGNLEAIYVTDSDANASIGMKKYFVGINAHGHVAISAKKIEGENIGAQVLGLFTLSSGKDIWQKLSGGGHHHHHH
本发明的多肽可以包含SEQ ID NO:1或SEQ ID NO:2的序列,基本上由其组成或由其组成。SEQ ID NO:1或SEQ ID NO:2中的每一个可以任选地包括在N末端的附加的甲硫氨酸和/或在C末端的组氨酸标签。组氨酸标签优选地由六个组氨酸残基组成。组氨酸标签优选地通过3×甘氨酸或5×甘氨酸残基的接头连接到C末端。
在相关情况下,可以使用任何合适的算法来计算氨基酸同一性。例如,PILEUP和BLAST算法可用于计算同一性或排齐序列(诸如识别等同或相应序列(通常在其默认设置上),例如,如在Altschul S .F .(1993)J Mol Evol 36:290-300;Altschul,S,F等人(1990)J Mol Biol 215:403-10中描述的。用于进行BLAST分析的软件可通过国家生物技术信息中心(http://www .ncbi .nlm .nih .gov/)公开获得。该算法包括首先通过在查询序列中识别长度为W的短字符来识别高得分序列对(HSP),该短字符与数据库序列中相同长度的字符比对时匹配或满足一些正值阈值得分T。T被称为相邻字得分阈值(neighbourhoodword score threshold)(Altschul等人,同上)。这些初始命中相邻字符(initialneighbourhood word hit)作为用于启动搜索以找到包含它们的HSP的种子。只要可以增加累积比对得分,则命中字符(word hit)沿着每个序列在两个方向上扩展。在以下情况下,命中字符在每个方向上的扩展停止:累积比对分数自其最大实现值下降量X;由于一个或多个负面得分残基比对的积累,累积得分达到零或以下;或者达到任一序列的结束。BLAST算法参数W、T和X决定了比对的灵敏度和速度。BLAST程序使用字长(W)为11,BLOSUM62评分矩阵(参见Henikoff和Henikoff(1992)
BLAST算法对两个序列之间的相似性进行统计分析;参见例如,Karlin和Altschul(1993)
本文公开的多肽可以通过任何合适的手段生产。例如,多肽可以使用本领域已知的标准技术(诸如Fmoc固相化学、Boc固相化学法或通过溶液相肽合成法)直接合成。替代地,多肽可以通过用编码所述多肽的核酸分子或载体来转化细胞(通常为细菌细胞)来产生。在细菌宿主细胞中通过表达产生多肽在下面描述并在实施例中举例说明。本发明提供了编码本发明的多肽的核酸分子和载体。本发明还提供了包含这种核酸或载体的宿主细胞。提供了作为SEQ ID NO:16至23的编码本发明的多肽和本文公开的其他的示例性多核苷酸分子。这些序列中的每一个包括在5’端的N末端甲硫氨酸的密码子(ATG),以及在3’端的终止密码子(TAA)之前,3× Gly接头和6× His组氨酸标签的密码子,其可任选地被排除。
术语“核酸分子”和“多核苷酸”在本文中可互换使用,并且是指任何长度的核苷酸的聚合形式,要么是脱氧核糖核苷酸或核糖核苷酸,要么是它们的类似物。多核苷酸的非限制性实例包括基因、基因片段、信使RNA(mRNA)、cDNA、重组多核苷酸、质粒、载体、任何序列的已分离的DNA、任何序列的已分离的RNA、核酸探针和引物。本发明的多核苷酸可以以分离的或基本上分离的形式提供。所谓基本上分离,这意味着多肽与任何周围介质的分离可能是基本的但不是全部的。多核苷酸可以与不干扰其预期用途的载体或稀释剂混合,并仍然被认为是基本上分离的。“编码”所选择的多肽的核酸序列是当被置于适当调节序列的控制下时(例如在表达载体中)被转录(在DNA的情况下)和被翻译(在mRNA的情况下)成多肽的核酸分子。编码序列的界限由处于5’(氨基)末端的起始密码子和处于3’(羧基)末端的翻译终止密码子而确定。出于本发明的目的,这样的核酸序列可以包括但不限于来自病毒的、原核的或真核的mRNA的cDNA,来自病毒的或者原核的DNA或RNA的基因组序列,以及甚至合成的DNA序列。转录终止序列可以位于编码序列的3’。
多核苷酸可以按照本领域众所周知的方法合成,如通过举例在Sambrook等人(1989,Molecular Cloning-a laboratory manual;Cold Spring Harbor Press)中所描述的。本发明的核酸分子可以以表达盒的形式提供,表达盒包括与所插入的序列可操作地连接的控制序列,从而允许活体内表达本发明的多肽。这些表达盒进而通常在载体(例如,质粒或重组病毒载体)内提供。这样的表达盒可以直接被施用于宿主对象。替代地,包含本发明多核苷酸的载体可以被施用于宿主对象。优选地,使用遗传载体制备和/或施用多核苷酸。合适的载体可以是能够携带足够量的遗传信息并允许表达本发明的多肽的任何载体。
因此,本发明包括包含这样的多核苷酸序列的表达载体。这样的表达载体在分子生物学领域中被常规构建,并且可以例如涉及使用质粒DNA和适当的启始子(initiator)、启动子、增强子和可能是必需的并且位于正确的方向的其他元件,诸如例如聚腺苷酸化信号,以允许表达本发明的肽。其他合适的载体对于本领域技术人员是显而易见的。这方面的另一举例,我们参考Sambrook等人。
本发明还包括已被修饰以表达本发明的多肽的细胞。这样的细胞通常包括原核细胞(诸如细菌细胞),例如大肠杆菌。可以使用常规方法培养这样的细胞以产生本发明的多肽。
可以将多肽衍生或修饰以帮助其生产、分离或纯化。例如,当通过在细菌宿主细胞中重组表达来产生本发明的多肽时,多肽的序列可以包括在N末端的附加的甲硫氨酸(M)残基以提高表达。作为另一实例,本发明的多肽可以通过加入能够直接并特异性结合到分离手段的配体来进行衍生或修饰。替代地,多肽可以通过加入结合对的一个成员来进行衍生或修饰,并且分离手段包括通过加入结合对的另一成员来进行衍生或修饰的试剂。可以使用任何合适的结合对。在用于本发明的多肽通过加入结合对的一个成员来进行衍生或修饰的优选实施方案中,多肽优选为组氨酸标签的或生物素标签的。典型地,在基因水平上包括组氨酸或生物素标签的氨基酸编码序列,并且多肽在大肠杆菌中重组表达。组氨酸或生物素标签通常存在于多肽的任一端,优选地存在于C末端。它可以直接连接到多肽,或者通过任何合适的接头序列(诸如3个、4个或5个甘氨酸残基)间接连接。组氨酸标签通常由六个组氨酸残基组成,尽管它可以比此更长(通常高达7个、8个、9个、10个或20个氨基酸)或者更短(例如5个、4个、3个、2个或1个氨基酸)。
多肽的氨基酸序列可以被修饰为包括非天然存在的氨基酸,例如以增加稳定性。当通过合成方法产生多肽时,可以在生产过程中引入这些氨基酸。多肽还可以在合成或重组生产后进行修饰。还可以使用D-氨基酸产生多肽。在这些情况下,氨基酸将以C至N方向相反的顺序被连接。这在生产此类多肽的技术中是常规的。
许多侧链修饰是本领域已知的,并且可以对所述多肽的侧链做出,使多肽保留本文可能指定的任何进一步所需的活性或特性。还将理解,多肽可以被化学修饰,例如翻译后修饰。例如,它们可以被糖基化、磷酸化或包含修饰的氨基酸残基。
多肽可以被聚乙二醇化。本发明的多肽可以是基本上分离的形式。它可以与不会干扰预期用途的载体(carrier)或稀释剂(如下所述的)混合,并仍然被认为是基本上分离的。它还可以是基本上纯化的形式,在这种情况下,它在制品中将通常包含至少90%,例如至少95%、98%或99%的蛋白质。
另一方面,本发明提供包含本发明的多肽的组合物。例如,本发明提供包含本发明的一种或多种多肽和至少一种药学上可接受的载体或稀释剂的组合物。在与组合物的其他成分相容的意义上,一种或多种载体必须是“可接受的”,并且对施用组合物的对象无害。通常,载体和最终组合物是无菌的和无热原的。
合适的组合物的配制可以使用标准的药物制剂化学和方法学来进行,所有这些对于相当熟练的技术人员来说都是容易获得的。例如,试剂可以与一种或多种药学上可接受的赋形剂或媒介物组合。辅助物质(诸如润湿剂或乳化剂)、pH缓冲物质、还原剂等可以存在于赋形剂或媒介物中。合适的还原剂包括半胱氨酸、硫代甘油、硫代内酯素、谷胱甘肽等。赋形剂、媒介物和辅助物质通常是在接受组合物的个体中不诱导免疫应答的药用剂,并且其可以被施用而没有不适当的毒性。药学上可接受的赋形剂包括但不限于液体(诸如水)、盐水、聚乙二醇、透明质酸、甘油、硫代甘油和乙醇。其中还可以包括药学上可接受的盐,例如,无机酸盐诸如盐酸盐、氢溴酸盐、磷酸盐、硫酸盐等;和有机酸盐,诸如乙酸盐、丙酸盐、丙二酸盐、苯甲酸盐等。在Remington’s Pharmaceutical Sciences(Mack Pub .Co .,N .J.1991)中获得药学上可接受的赋形剂、媒介物和辅助物质的详细讨论。
这样的组合物可以以适于推注施用(bolus administration)或连续施用的形式制备、包装或出售。可注射组合物可以以单位剂型制备、包装或销售,诸如在含有防腐剂的安瓿或多剂量容器中。组合物包括但不限于悬浮液、溶液、在油性或水性媒介物中的乳剂、糊剂和可植入的缓释或可生物降解制剂。这样的组合物还可以包含一种或多种另外的成分,包括但不限于悬浮剂、稳定剂或分散剂。在用于肠胃外施用的组合物的一个实施方案中,活性成分以干燥(例如,粉末或颗粒)形式提供,用于以合适的媒介物(例如,无菌无热原的水)复原,之后肠胃外施用已复原的组合物。组合物可以以无菌可注射的水性或油性悬浮液或溶液的形式制备、包装或销售。这种悬浮液或溶液可以根据已知技术配制,并且除了活性成分之外,还可以包含另外的成分,诸如本文所述的分散剂、润湿剂或悬浮剂。例如可以使用无毒性肠胃外可接受的稀释剂或溶剂(诸如水或1,3-丁二醇)来制备这种无菌可注射制剂。其他可接受的稀释剂和溶剂包括但不限于林格氏溶液、等渗氯化钠溶液和固定油(诸如合成的单甘油酯或二甘油酯)。
有用的其他肠胃外施用的组合物包括那些包括以微晶形式、在脂质体制品中或作为可生物降解聚合物体系的组分的活性成分的组合物。用于持续释放或植入的组合物可以包含药学上可接受的聚合性或疏水性材料,诸如乳液、离子交换树脂、微溶性聚合物或微溶盐。组合物可以适合于通过任何合适的途径施用,包括例如皮内、皮下、经皮、肌内、动脉内、腹膜内、关节内、骨内、囊内或其他合适的施用途径。优选的组合物适于通过静脉输注施用。
本发明提供了本发明的多肽在各种方法中的用途。例如,本发明的多肽可为生物技术提供有用的工具。该多肽可用于IgG(特别是人IgG)的特异性活体外切割。在这种方法中,可以在允许发生特异性半胱氨酸蛋白酶活性的条件下将多肽与含有IgG的样品孵育。可以验证特异性切割,并使用任何合适的方法(诸如在WO2003051914和WO2009033670中描述的那些方法)分离切割产物。因此,该方法可以特别用于产生Fc和F(ab’)
该方法还可以被用于检测或分析样品中的IgG或从样品中除去IgG。用于检测样品中IgG的方法通常包括在允许IgG特异性结合和切割的条件下将多肽与样品一起孵育。IgG的存在可以通过检测特异性IgG切割产物来验证,其可以随后被分析。
根据本发明的多肽还可以用于治疗或预防。在治疗应用中,将多肽或组合物以足以治愈、减轻或部分阻止病症或其一种或多种症状的量施用于已经患有疾患或病症的对象。这种治疗性疗法可能导致疾病症状的严重程度降低,或者无症状期的频率或持续时间的增加的疾病。足以实现此目的的量被定义为“治疗有效量”。在预防性应用中,将多肽或组合物以足以预防或延缓症状的发展的量施用于尚未表现出疾患或病症的症状的对象。这样的量被定义为“预防有效量”。通过任何合适的手段对象可能被确定为有发展疾病或病症的风险。因此,本发明还提供了用在人或动物体的治疗中的本发明的多肽。本文还提供了预防或治疗对象的疾病或病症的方法,该方法包括以预防或治疗有效量向对象施用本发明的多肽。多肽可以与免疫抑制剂共同施用。多肽优选通过静脉输注施用,但可以通过任何合适的途径施用,包括例如皮内、皮下、经皮、肌内、动脉内、腹膜内、关节内、骨内、囊内或其他合适的施用途径。施用的所述多肽的量可以在0.01 mg/kg BW至2 mg/kg BW之间,在0.05至1.5mg/kg BW之间,在0.1 mg/kg BW至1 mg/kg BW之间,优选地在0.15 mg/kg至0.7 mg /kg BW之间,以及最优选地在0.2 mg/kg至0.3 mg/kg BW之间,特别是0.25 mg/kg BW。多肽可以多次施用于同一对象,条件是对象血清中能够结合于多肽的ADA的数量不超过临床医生所确定的阈值。对象血清中能够结合于多肽的ADA的数量可以通过任何合适的方法确定,诸如试剂特异性CAP FEIA(ImmunoCAP)测试或滴度测定。
本发明的多肽可特别用于治疗或预防由致病性IgG抗体介导的疾病或病症。因此,本发明提供了用于治疗或预防由致病性IgG抗体介导的疾病或病症的本发明的多肽。本发明还提供了治疗或预防由致病性IgG抗体介导的疾病或病症的方法,包括向个体施用本发明的多肽。该方法可以包括重复施用所述多肽。本发明还提供了用于在制造用于治疗或预防由致病性IgG抗体介导的疾病或病症(特别是全部或部分由致病性IgG抗体介导的自身免疫性疾病)的药物中的应用的本发明的多肽。
致病性抗体通常可以对抗原是特异性的,在全部或部分由抗体介导的自身免疫性疾病中靶向该抗原。表D列出了这些疾病和相关抗原的列表。本发明的多肽可用于治疗这些疾病或病症中的任何一种。该多肽对于治疗或预防全部或部分由致病性IgG抗体介导的自身免疫性疾病特别有效。
在另一个实施方案中,本发明的多肽可以被用在改善治疗或治疗剂对对象的益处的方法中。该方法包含两个步骤,其在本文中被称为步骤(a)和步骤(b)。
步骤(a)包括向对象施用本发明的多肽。所施用的多肽的量优选足以切割存在于对象血浆中的基本上所有的IgG分子。步骤(b)包括随后向对象施用所述治疗或治疗剂。通过时间间隔将步骤(a)和(b)分隔,该时间间隔优选足以发生切割存在于对象血浆中的基本上所有的IgG分子。所述间隔通常可以是至少30分钟和最多21天。
益处得到改善的治疗剂通常是用于治疗癌症或其他疾病而被施用的抗体。治疗剂可以是IVIg。在本实施方案的情况下,本发明可以替代地描述为提供用于治疗对象中的癌症或其他疾病的方法,该方法包含:(a)向对象施用本发明的多肽;以及(b)随后向对象施用治疗有效量的作为用于所述癌症或所述其他疾病的治疗的抗体;其中:
-所施用的所述多肽的量足以切割存在于对象血浆中的基本上所有的IgG分子;以及
-通过至少30分钟和最多21天的时间间隔将步骤(a)和步骤(b)分隔。
换言之,本发明还提供了用于在这种方法中用于治疗癌症或其他疾病的用途的多肽。本发明还提供了该试剂在制备用于通过这种方法治疗癌症或其他疾病的药物中的应用。癌症可能是急性淋巴细胞白血病、急性骨髓性白血病、肾上腺皮质癌、艾滋病相关癌症、艾滋病相关淋巴瘤、肛门癌、阑尾癌、儿童小脑或大脑星形细胞瘤、基底细胞癌、肝外胆管癌、膀胱癌、骨癌、骨肉瘤/恶性纤维组织细胞瘤、脑干神经胶质瘤(glioma),脑癌、脑肿瘤(小脑星形细胞瘤)、脑肿瘤(脑星形细胞瘤/恶性神经胶质瘤)、脑肿瘤(室管膜瘤)、脑肿瘤(成神经管细胞瘤)、脑肿瘤(幕上原始神经外胚层肿瘤)、脑肿瘤(视觉通路和下丘脑神经胶质瘤)、乳腺癌、支气管腺瘤/类癌、伯基特淋巴瘤(Burkitt lymphoma)、类癌肿瘤,胃肠道类癌肿瘤、未知原发癌、中枢神经系统淋巴瘤、小脑星形细胞瘤、大脑星形细胞瘤/恶性神经胶质瘤、宫颈癌、慢性淋巴细胞性白血病、慢性骨髓性白血病慢性骨髓增生性疾病、结肠癌、皮肤T细胞淋巴瘤、促结缔组织增生性小圆细胞瘤、子宫内膜癌、室管膜瘤、食管癌、尤文氏肿瘤家族中的尤文氏肉瘤、儿童颅外生殖细胞瘤、性腺外生殖细胞瘤、肝外胆管癌、眼癌(眼内黑色素瘤)、眼癌(视网膜母细胞瘤)、胆囊癌、胃的(胃)癌、胃肠癌类肿瘤、胃肠道间质瘤(GIST)、生殖细胞肿瘤(颅外的、性腺外的或卵巢的)、妊娠滋养细胞肿瘤、脑干神经胶质瘤、神经胶质瘤、儿童大脑星形细胞瘤、儿童视觉通路和下丘脑神经胶质瘤、胃类癌、毛细胞白血病、头颈癌、心脏癌、肝细胞(肝)癌、霍奇金淋巴瘤、下咽癌、下丘脑和视觉通路胶质瘤、眼内黑色素瘤、胰岛细胞癌(内分泌胰腺)、卡波西肉瘤、肾癌(肾细胞癌)、喉癌、白血病、急性淋巴母细胞性白血病(也称为急性淋巴细胞性白血病)、急性髓细胞白血病(也称为急性骨髓性白血病)、慢性淋巴细胞白血病(也称为慢性淋巴细胞性白血病)、慢性骨髓细胞性白血病(也称为慢性骨髓性白血病)、毛细胞白血病、唇和口腔癌、脂肪肉瘤、肝癌(原发性)、肺癌、非小细胞肺癌、小细胞肺癌、淋巴瘤、艾滋病相关的淋巴瘤、伯基特淋巴瘤、皮肤T细胞淋巴瘤、霍奇金淋巴瘤、非霍奇金淋巴瘤(除了霍奇金的所有淋巴瘤的旧分类)、原发性中枢神经系统淋巴瘤、巨球蛋白血症、Waldenström、骨的恶性纤维性组织细胞瘤/骨肉瘤、成神经管细胞瘤、黑色素瘤、眼内(眼)黑色素瘤、Merkel细胞癌、成人恶性间皮瘤、间皮瘤、转移性鳞状细胞颈癌伴隐匿原发灶(Metastatic Squamous Neck Cancer with OccultPrimary)、口癌(Mouth Cancer)、多发性内分泌肿瘤综合征、多发性骨髓瘤/浆细胞肿瘤、蕈样肉芽肿、骨髓增生异常综合征、骨髓增生异常/骨髓增生性疾病、慢性骨髓性白血病、成人急性骨髓性白血病、儿童急性骨髓性白血病、骨髓瘤、多发(骨髓癌)骨髓增生性疾病、鼻腔和鼻旁窦癌、鼻咽癌、神经母细胞瘤、非霍奇金淋巴瘤、非小细胞肺癌、口腔癌(OralCancer)、口咽癌、骨肉瘤/骨骼恶性纤维组织细胞瘤、卵巢癌、卵巢上皮癌(表面上皮间质肿瘤)、卵巢生殖细胞瘤、卵巢低度恶性潜能肿瘤、胰腺癌、胰腺癌(胰岛细胞)、鼻旁窦和鼻腔癌、甲状旁腺癌、阴茎癌、咽癌、嗜铬细胞瘤、松果体星形细胞瘤、松果体生殖细胞瘤、成松果体细胞瘤和幕上原始神经外胚层肿瘤、垂体腺瘤、血浆细胞瘤形成/多发性骨髓瘤、胸膜肺母细胞瘤、原发性中枢神经系统淋巴瘤、前列腺癌、直肠癌、肾细胞癌(肾癌)、肾盂和输尿管移行细胞癌、视网膜母细胞瘤、横纹肌肉瘤、唾液腺癌、肉瘤、尤文氏家族肿瘤、卡波西肉瘤、软组织肉瘤、子宫肉瘤、塞泽里(Sézary)综合征、皮肤癌(非黑色素瘤)、皮肤癌(黑色素瘤)、皮肤癌(默克尔细胞)、小细胞肺癌、小肠癌、软组织肉瘤、鳞状细胞癌、转移性鳞状细胞颈癌伴隐匿原发灶、胃癌、幕上原始神经外胚层肿瘤、T细胞淋巴瘤、皮肤的癌症-见蕈样肉芽肿和塞泽里综合征、睾丸癌、喉癌、胸腺瘤、胸腺瘤和胸腺癌、甲状腺癌、甲状腺癌、肾盂和输尿管移行细胞癌、滋养细胞肿瘤、输尿管和肾盂移行细胞癌、尿道癌、子宫癌(子宫内膜)、子宫肉瘤、阴道癌、视觉通路和下丘脑神经胶质瘤、外阴癌、Waldenström巨球蛋白血症和肾母细胞瘤(肾癌)。
癌症优选为前列腺癌、乳腺癌、膀胱癌、结肠癌、直肠癌、胰腺癌、卵巢癌、肺癌、子宫颈癌、子宫内膜癌、肾(肾细胞)癌、食管癌、甲状腺癌、皮肤癌、淋巴瘤、黑色素瘤或白血病。
步骤(b)中施用的抗体优选地对与一种或多种以上癌症类型相关的肿瘤抗原是特异性的。用于该方法的抗体的感兴趣的靶包括CD2、CD3、CD19、CD20、CD22、CD25、CD30、CD32、CD33、CD40、CD52、CD54、CD56、CD64、CD70、CD74、CD79、CD80、CD86、CD105、CD138、CD174、CD205、CD227、CD326、CD340、MUC16、GPNMB、PSMA、Cripto、ED-B、TMEFF2、EphA2、EphB2、FAP、αv整联蛋白、间皮素、EGFR、TAG-72、GD2、CA1X、5T4、α4β7整联蛋白、Her2。其他靶是细胞因子(诸如白介素IL-1至IL-13)、肿瘤坏死因子α&β、干扰素α、β和γ、肿瘤生长因子β(TGF-β)、集落刺激因子(CSF)和粒细胞单核细胞集落刺激因子(GMCSF)。参见Human Cytokines:Handbook for Basic&Clinical Research(Aggrawal et al. eds., BlackwellScientific, Boston, MA 1991)。其他靶是激素、酶以及细胞内和细胞间信使(诸如腺苷酸环化酶、鸟苷酸环化酶和磷脂酶C)。其他感兴趣的靶是白细胞抗原,诸如CD20和CD33。药物也可能是感兴趣的靶。靶分子可以是人类的、哺乳动物的或细菌的。其他靶是来自微生物病原体(病毒和细菌二者)以及肿瘤的抗原,诸如蛋白质、糖蛋白和碳水化合物。U.S. 4,366,241中还描述了其他靶。
可以将抗体直接地或间接地接附到细胞毒性部分或接附到可检测标记。使用本领域已知的各种方法中的一种或多种通过一种或多种施用途径可以施用抗体。施用的途径和/或方式将根据期望的结果而变化。针对抗体的优选施用途径包括静脉内、肌内、皮内、腹膜内、皮下、脊髓或其他肠胃外施用途径,例如通过注射或输注。本文所用的短语“肠胃外施用”是指通常通过注射而不是肠内施用和外用施用(topical administration)的施用方式。可替换地,抗体可以通过非肠胃外途径施用,诸如外用、表皮或粘膜施用途径。局部施用(local administration)也是优选的,包括肿瘤周围、接近肿瘤(juxtatumoral)、肿瘤内、病灶内、病灶周围、腔内灌注(intra cavity infusion)、囊内(intravesicle)施用和吸入。
本发明的抗体的合适剂量可由熟练的医生确定。可以改变抗体的实际剂量水平,以获得对特定患者、组合物和施用方式实现所期望的治疗响应有效而对患者无毒的活性成分的量。所选择的剂量水平将取决于多种药代动力学因素,包括所采用的特定抗体的活性,施用途径,施用时间,抗体排泄速率,治疗持续时间,与所采用的特定组合物组合使用的其他药物、化合物和/或材料,所治疗患者的年龄、性别、体重、病症、一般健康状况和先前病史等医学领域众所周知的因素。
抗体的合适剂量可以是例如在待治疗患者的约0.1 μg/kg至约100 mg/kg体重的范围内。例如,合适的剂量可以是每天约1 μg/kg至约10 mg/kg体重或每天约10 μg/kg至约5 mg/kg体重。
可以调节剂量方案以提供最佳期望的响应(例如,治疗响应)。例如,可以施用单次推注,或者该方法的步骤(b)可以包括随时间施用的几个分开的剂量,或者可以根据治疗情况的紧急程度所指示的按比例减少或增加剂量,只要不超过步骤(a)和步骤(b)之间所需的间隔。以便于剂量的施用和均匀性的剂量单位形式配制肠胃外组合物是特别有利的。本文所用的剂量单位形式是指适合作为待治疗对象的单位剂量的物理上离散的单位;每个单位含有与所需药物载体相关联的被计算以产生所需治疗效果的预定量的活性化合物。
步骤(b)的抗体可以与化疗或放射治疗组合施用。该方法可以进一步包括施用额外的抗癌抗体或其他治疗剂,其可以作为组合治疗的一部分与步骤(b)的抗体一起在单一组合物中或在单独的组合物中施用。例如,步骤(b)的抗体可以在其他药剂之前、之后或同时施用。
抗体可以是阿巴伏单抗(Abagovomab)、阿昔单抗(Abciximab)、阿克托虚单抗(Actoxumab)、阿达木单抗(Adalimumab)、阿德木单抗(Adecatumumab)、阿非莫单抗(Afelimomab)、阿夫土珠单抗(Afutuzumab)、培化阿珠单抗(Alacizumab pegol)、ALD518、阿仑单抗(Alemtuzumab)、阿利库单抗(Alirocumab)、喷替酸阿妥莫单抗(Altumomabpentetate)、阿麦妥昔单抗(Amatuximab)、麻安莫单抗(Anatumomab mafenaox)、安芦珠单抗(Anrukinzumab)、阿泊珠单抗(Apolizumab)、阿西莫单抗(Arcitumomab)、阿塞珠单抗(Aselizumab)、阿替奴单抗(Atinumab)、阿利珠单抗(Atlizumab)(=托珠单抗(tocilizumab))、阿托木单抗(Atorolimumab)、巴匹珠单抗(Bapineuzumab)、巴利昔单抗(Basiliximab)、巴土昔单抗(Bavituximab)、贝妥莫单抗(Bectumomab)、贝利木单抗(Belimumab)、Benralizumab(贝瑞伐单抗)、柏替莫单抗(Bertilimumab)、贝索单抗(Besilesomab)、贝伐单抗(Bevacizumab)、贝兹罗图单抗(Bezlotoxumab)、比西单抗(Biciromab)、比麦芦单抗(Bimagrumab)、比伐单抗默坦辛(Bivatuzumab mertansine)、兰妥莫单抗(Blinatumomab)、骨硬化素单抗(Blosozumab)、本妥西单抗维多汀(Brentuximabvedotin)、布雷奴单抗(Briakinumab)、布罗达单抗(Brodalumab)、卡那单抗(Canakinumab)、美坎珠单抗默坦辛(Cantuzumab mertansine)、坎妥珠单抗拉夫坦辛(Cantuzumab ravtansine)、卡普拉西珠单抗(Caplacizumab)、卡罗单抗喷地肽(Capromabpendetide)、卡鲁单抗(Carlumab)、卡妥索单抗(Catumaxomab)、CC49、西利珠单抗(Cedelizumab)、培舍珠单抗(Certolizumab pegol)、西妥昔单抗(Cetuximab)、Ch .14.18、泊西他珠单抗(Citatuzumab bogatox)、西妥木单抗(Cixutumumab)、克拉扎珠单抗(Clazakizumab)、克立昔单抗(Clenoliximab)、克立瓦妥珠单抗特他坦(Clivatuzumabtetraxetan)、可那木单抗(Conatumumab)、扣西珠单抗(Concizumab)、克雷内珠单抗(Crenezumab)、CR6261、达西妥珠单抗(Dacetuzumab)、达克珠单抗(Daclizumab)、达洛妥珠单抗(Dalotuzumab)、达拉妥木单抗(Daratumumab)、德美西珠单抗(Demcizumab)、地诺单抗(Denosumab)、地莫单抗(Detumomab)、阿托度单抗(Dorlimomab aritox)、卓齐妥单抗(Drozitumab)、度利戈妥单抗(Duligotumab)、度匹鲁单抗(Dupilumab)、度斯吉妥单抗(Dusigitumab)、依美昔单抗(Ecromeximab)、艾库组单抗(Eculizumab)、埃巴单抗(Edobacomab)、依决洛单抗(Edrecolomab)、依法珠单抗(Efalizumab)、依夫单抗(Efungumab)、埃罗妥珠单抗(Elotuzumab)、艾西莫单抗(Elsilimomab)、依纳伐妥珠单抗(Enavatuzumab)、培戈赖莫单抗(Enlimomab pegol)、依诺珠单抗(Enokizumab)、依诺替库单抗(Enoticumab)、恩西妥昔西单抗(Ensituximab)、西-依匹妥莫单抗(Epitumomabcituxetan)、依帕珠单抗(Epratuzumab)、厄利珠单抗(Erlizumab)、厄马索单抗(Ertumaxomab)、埃达珠单抗(Etaracizumab)、依托珠单抗(Etrolizumab)、依伏罗库单抗(Evolocumab)、艾韦单抗(Exbivirumab)、法索单抗(Fanolesomab)、法拉莫单抗(Faralimomab)、法勒珠单抗(Farletuzumab)、法西奴单抗(Fasinumab)、FBTA05、非维珠单抗(Felvizumab)、非扎奴单抗(Fezakinumab)、芬克拉妥珠单抗(Ficlatuzumab)、芬妥木单抗(Figitumumab)、弗拉伏妥单抗(Flanvotumab)、芳妥珠单抗(Fontolizumab)、佛拉鲁单抗(Foralumab)、佛拉韦芦单抗(Foravirumab)、夫苏木单抗(Fresolimumab)、弗拉奴单抗(Fulranumab)、弗妥昔单抗(Futuximab)、加利昔单抗(Galiximab)、甘尼妥单抗(Ganitumab)、甘特芦单抗(Gantenerumab)、加韦莫单抗(Gavilimomab)、吉妥珠单抗奥佐米星(Gemtuzumab ozogamicin)、吉沃珠单抗(Gevokizumab)、吉瑞妥昔单抗(Girentuximab)、格列姆巴妥木单抗维多汀(Glembatumumab vedotin)、戈利木单抗(Golimumab)、戈米昔单抗(Gomiliximab)、GS6624、伊巴珠单抗(Ibalizumab)、伊莫单抗替坦(Ibritumomabtiuxetan)、伊克芦库单抗(Icrucumab)、伊戈伏单抗(Igovomab)、英西单抗(Imciromab)、英加妥珠单抗(Imgatuzumab)、英克勒库单抗(Inclacumab)、英达妥昔单抗拉夫坦辛(Indatuximab ravtansine)、英利昔单抗(Infliximab)、英妥木单抗(Intetumumab)、伊诺莫单抗(Inolimomab)、伊珠单抗奥佐米星(Inotuzumab ozogamicin)、伊匹木单抗(Ipilimumab)、伊妥木单抗(Iratumumab)、伊托珠单抗(Itolizumab)、伊克塞珠单抗(Ixekizumab)、凯利昔单抗(Keliximab)、拉贝珠单抗(Labetuzumab)、兰帕珠单抗(Lampalizumab)、来金珠单抗(Lebrikizumab)、来马索单抗(Lemalesomab)、乐地单抗(Lerdelimumab)、来沙木单抗(Lexatumumab)、利韦单抗(Libivirumab)、利格珠单抗(Ligelizumab)、林妥珠单抗(Lintuzumab)、利利单抗(Lirilumab)、罗戴西珠单抗(Lodelcizumab)、罗伏妥珠单抗默坦辛(Lorvotuzuma bmertansine)、鲁卡妥木单抗(Lucatumumab)、鲁米昔单抗(Lumiliximab)、马帕妥木单抗(Mapatumumab)、马司莫单抗(Maslimomab)、马利木单抗(Mavrilimumab)、马妥珠单抗(Matuzumab)、美泊利单抗(Mepolizumab)、美替木单抗(Metelimumab)、米拉珠单抗(Milatuzumab)、明瑞莫单抗(Minretumomab)、米妥莫单抗(Mitumomab)、莫加木珠单抗(Mogamulizumab)、莫罗木单抗(Morolimumab)、莫他珠单抗(Motavizumab)、莫西妥莫单抗假单胞菌外毒素(Moxetumomabpasudotox)、莫罗单抗-CD3(Muromonab-CD3)、他那可单抗(Nacolomab tafenatox)、那米鲁单抗(Namilumab)、他那莫单抗(Naptumomab estafenatox)、纳那妥单抗(Narnatumab)、那他珠单抗(Natalizumab)、奈巴库单抗(Nebacumab)、奈昔木单抗(Necitumumab)、奈瑞莫单抗(Nerelimomab)、耐斯伐库单抗(Nesvacumab)、尼妥珠单抗(Nimotuzumab)、尼伏鲁单抗(Nivolumab)、诺莫单抗默喷坦(Nofetumomab merpentan)、阿托珠(Obinutuzumab)、奥卡拉妥珠单抗(Ocaratuzumab)、奥瑞珠单抗(Ocrelizumab)、奥度莫单抗(Odulimomab)、奥法木单抗(Ofatumumab)、奥拉妥单抗(Olaratumab)、奥洛珠单抗(Olokizumab)、奥马珠单抗(Omalizumab)、奥纳妥珠单抗(Onartuzumab)、莫奥珠单抗(Oportuzumab monatox)、奥戈伏单抗(Oregovomab)、奥替库单抗(Orticumab)、奥特利昔珠单抗(Otelixizumab)、奥昔鲁单抗(Oxelumab)、奥扎尼珠单抗(Ozanezumab)、奥左拉珠单抗(Ozoralizumab)、帕吉巴昔单抗(Pagibaximab)、帕利珠单抗(Palivizumab)、帕木单抗(Panitumumab)、帕诺库单抗(Panobacumab)、巴萨妥珠单抗(Parsatuzumab)、帕考珠单抗(Pascolizumab)、帕特克珠单抗(Pateclizumab)、帕曲妥单抗(Patritumab)、培妥莫单抗(Pemtumomab)、培拉珠单抗(Perakizumab)、培妥珠单抗(Pertuzumab)、培克珠单抗(Pexelizumab)、皮地珠单抗(Pidilizumab)、皮那妥珠单抗维多汀(Pinatuzumab vedotin)、平妥莫单抗(Pintumomab)、普拉库鲁单抗(Placulumab)、泊拉妥珠单抗维多汀(Polatuzumab vedotin)、泊尼珠单抗(Ponezumab)、普立昔单抗(Priliximab)、普立托昔单抗(Pritoxaximab)、普立妥木单抗(Pritumumab)、PRO 140、奎利珠单抗(Quilizumab)、雷妥莫单抗(Racotumomab)、雷得妥单抗(Radretumab)、雷韦单抗(Rafivirumab)、雷莫芦单抗(Ramucirumab)、雷珠单抗(Ranibizumab)、雷西库单抗(Raxibacumab)、瑞加韦单抗(Regavirumab)、瑞利珠单抗(Reslizumab)、利妥木单抗(Rilotumumab)、利妥昔单抗(Rituximab)、罗妥木单抗(Robatumumab)、罗度单抗(Roledumab)、罗莫索珠单抗(Romosozumab)、罗利珠单抗(Rontalizumab)、罗维珠单抗(Rovelizumab)、鲁利珠单抗(Ruplizumab)、沙马珠单抗(Samalizumab)、沙里鲁单抗(Sarilumab)、沙妥莫单抗喷地肽(Satumomab pendetide)、司库奴单抗(Secukinumab)、司里班妥单抗(Seribantumab)、司托昔抗(Setoxaximab)、司韦单抗(Sevirumab)、西罗珠单抗(Sibrotuzumab)、西法木单抗(Sifalimumab)、西妥昔单抗(Siltuximab)、西妥珠单抗(Simtuzumab)、西利珠单抗(Siplizumab)、西芦库单抗(Sirukumab)、索兰珠单抗(Solanezumab)、索利托单抗(Solitomab)、索耐珠单抗(Sonepcizumab)、松妥珠单抗(Sontuzumab)、司他木鲁单抗(Stamulumab)、硫索单抗(Sulesomab)、苏韦珠单抗(Suvizumab)、他巴鲁单抗(Tabalumab)、他卡妥珠单抗(Tacatuzumab tetraxetan)、他度珠单抗(Tadocizumab)、他利珠单抗(Talizumab)、他尼珠单抗(Tanezumab)、帕他莫单抗(Taplitumomab paptox)、替非珠单抗(Tefibazumab)、阿替莫单抗(Telimomab aritox)、替妥莫单抗(Tenatumomab)、替奈昔单抗(Teneliximab)、替利珠单抗(Teplizumab)、替妥木单抗(Teprotumumab)、TGN1412、替昔木单抗(Ticilimumab)(=曲美木单抗(tremelimumab))、替拉珠单抗(Tildrakizumab)、替加珠单抗(Tigatuzumab)、TNX-650、托珠单抗(Tocilizumab)(=阿利珠单抗(atlizumab))、托拉珠单抗(Toralizumab)、托西莫单抗(Tositumomab)、特拉罗奴单抗(Tralokinumab)、曲妥珠单抗(Trastuzumab)、TRBS07、曲加珠单抗(Tregalizumab)、曲美木单抗(Tremelimumab)、妥可妥珠单抗西莫白介素(Tucotuzumab celmoleukin)、妥韦单抗(Tuvirumab)、优利妥昔单抗(Ublituximab)、优瑞鲁单抗(Urelumab)、优托珠单抗(Urtoxazumab)、优特克单抗(Ustekinumab)、伐利昔单抗(Vapaliximab)、伐特珠单抗(Vatelizumab)、维多珠单抗(Vedolizumab)、维妥珠单抗(Veltuzumab)、维帕莫单抗(Vepalimomab)、维森库单抗(Vesencumab)、维西珠单抗(Visilizumab)、伏洛昔单抗(Volociximab)、伏司妥珠单抗马佛多汀(Vorsetuzumab mafodotin)、伏妥昔单抗(Votumumab)、扎芦木单抗(Zalutumumab)、扎木单抗(Zanolimumab)、扎妥昔单抗(Zatuximab)、齐拉木单抗(Ziralimumab)或阿左莫单抗(Zolimomab aritox)。
优选的抗体包括那他珠单抗(Natalizumab)、维多珠单抗(Vedolizumab)、贝利木单抗(Belimumab)、阿塞西普(Atacicept)、阿法赛特(Alefacept)、奥特利昔珠单抗(Otelixizumab)、替利珠单抗(Teplizumab)、利妥昔单抗(Rituximab)、奥法木单抗(Ofatumumab)、奥瑞珠单抗(Ocrelizumab)、依帕珠单抗(Epratuzumab)、阿仑单抗(Alemtuzumab)、阿巴西普(Abatacept)、依库丽单抗(Eculizumab)、奥马珠单抗(Omalizumab)、卡那单抗(Canakinumab)、美泊利单抗(Meplizumab)、瑞利珠单抗(Reslizumab)、托珠单抗(Tocilizumab)、优特克单抗(Ustekinumab)、布拉吉单抗(Briakinumab)、依那西普(Etanercept)、英夫利西单抗(Inlfliximab)、阿达木单抗(Adalimumab)、培舍珠单抗(Certolizumab pegol)、戈利木单抗(Golimumab)、曲妥珠单抗(Trastuzumab)、吉妥珠单抗(Gemtuzumab)、奥佐米星(Ozogamicin)、伊莫单抗(Ibritumomab)、替坦(Tiuxetan)、托西替莫单抗(Tostitumomab)、西妥昔单抗(Cetuximab)、贝伐单抗(Bevacizumab)、帕木单抗(Panitumumab)、地诺单抗(Denosumab)、伊匹木单抗(Ipilimumab)、本妥西单抗(Brentuximab)和维多汀(Vedotin)。
益处得到改善的治疗通常是器官移植。器官可以选自肾脏、肝脏、心脏、胰腺、肺或小肠。待治疗的对象可以优选地被致敏或高度被致敏。“被致敏”是指对象已经发展出针对人类主要组织相容性(MHC)抗原(也称为人白细胞抗原(HLA))的抗体。抗HLA抗体源自于异源致敏的B细胞,并通常存在于以前通过输血、先前移植或怀孕而已致敏的患者中(Jordan等人,2003)。
潜在的移植受体是否被致敏可以通过任何合适的方法来确定。例如,可以使用群体反应性抗体(PRA)测试来确定受体是否被致敏。PRA得分>30%通常被认为是指患者是“高度免疫学风险”或“被致敏”。可替换地,可以进行交叉匹配测试,其中将潜在移植供体的血液样品与预期受体的血液样品混合。正交叉匹配意味着受体具有与供体样品起反应的抗体,表明受体被致敏并且不应该发生移植。交叉匹配测试通常在马上移植前作为最后检查而进行。
由于急性抗体介导的排斥的风险,针对潜在供体的MHC抗原的高滴度抗体(即供体特异性抗体(DSA))的存在是对移植的直接禁忌症。简而言之,对供体MHC抗原的致敏化阻碍了合适供体的识别。正交叉匹配测试是移植的明确障碍。由于等待肾移植的患者的大约三分之一患者被致敏,同时多达15%的患者高度被致敏,这导致等待移植的患者的积累。在美国,2001-2002年期间肾移植等候名单上的中位数时间对于群体反应性抗体(PRA)得分为0-9%的那些为1329天,对于PRA为10-79%的那些为1920天,以及对于PRA为80%或以上的那些为3649天(OPTN数据库,2011)。
对克服DSA障碍的一种被接受的策略是应用血浆置换或免疫吸附,其通常与例如静脉注射γ-球蛋白(IVIg)或利妥昔单抗组合,以将DSA的水平降低到可以考虑移植的水平(Jordan et al., 2004;Montgomery et al., 2000;Vo et al., 2008a;Vo et al.,2008b)。然而,血浆置换、免疫吸附和IVIg治疗由于它们涉及长时间的重复治疗而具有效率低下和需要严格的规划的缺点。当来自死亡供体的器官变得可用时,必须在几小时内移植,因为长时间的冷缺血时间是肾移植术中延迟移植物功能和同种异体移植物丢失(allograft loss)的最重要的危险因素之一(Ojo et al., (1997) Transplantation 63:968-74)。
相比之下,本发明的方法允许在潜在的移植受体中快速、短时间和安全地去除DSA。在就要移植前施用本发明的多肽具有使高度被致敏的患者有效脱敏的能力,从而允许移植并避免急性抗体介导的排斥。在移植前单一剂量的多肽将使成千上万个具有供体特异性IgG抗体的患者的移植成为可能。
在该实施方式的情况中,该方法可以替代地描述为一种用于治疗对象的器官衰竭的方法,该方法包含:(a)向对象施用本发明的多肽,以及(b)随后将替换器官移植到该对象中;其中:
-所施用的所述多肽的量足以切割存在于受试者血浆中的基本上所有IgG分子;以及
-通过至少30分钟和最多21天的时间间隔将步骤(a)和(b)分隔。
换言之,该实施 可以被描述为一种用于防止对象中移植器官的排斥(特别是急性抗体介导的移植排斥)的方法,该方法包括在器官移植前至少30分钟和最多21天向对象施用本发明的多肽,其中施用的所述多肽的量足以切割存在于对象血浆中的基本上所有IgG分子。本发明还提供了本发明的多肽在此种治疗器官衰竭或预防移植排斥(特别是急性抗体介导的移植排斥)的方法中的用途。本发明还提供了本发明的多肽在制造通过这种方法来治疗器官衰竭或预防移植排斥的药物中的用途。在该实施方式中,本发明的方法可另外包括在移植时或紧接在移植之前进行的步骤,该步骤包括患者中的T细胞和/或B细胞的诱导抑制。所述诱导抑制通常可包括施用有效量的杀死或抑制T细胞的剂,和/或施用有效量的杀死或抑制B细胞的试剂。杀死或抑制T细胞的剂包括莫罗单抗(Muromonab)、巴利昔单抗、达克珠单抗、抗胸腺细胞球蛋白(ATG)抗体和淋巴细胞免疫球蛋白、抗胸腺细胞球蛋白制品(ATGAM)。已知利妥昔单抗杀死或抑制B细胞。
具有IgG半胱氨酸蛋白酶活性的多肽(如本发明的多肽)也可以被用于诱导对象的造血细胞嵌合(hematopoietic chimerism)的方法中,例如在向对象移植造血干/祖细胞(HSPC)的情况下。因此,本发明的多肽可以被用于诱导对象的造血细胞嵌合的方法中,该方法包含进行本发明的预处理方案(conditioning regimen),随后以足够的量且在适合诱导对象的造血细胞嵌合的条件下向对象施用HSPC。该方法可以替代地被描述为一种用于稳定移植HSPC的方法。HSPC可以是自体的(使用对象/患者自己的细胞)或同源的(细胞来自遗传相同的双胞胎),或者可以是同种异体的(细胞来自单独的、非相同的供体)。免疫并发症降低了HSPC在受体中成功移植的可能性,这对同种异体细胞来说是最重要的,因此诱导造血细胞嵌合的方法对这种细胞是最有利的。然而,即使是自体细胞,如果有受体以前没有接触过的产物的表达,也会发生免疫并发症。如果自体细胞被基因修饰以表达基因疗法,该细胞可以被充分改变以引起免疫反应。例如,可能会对表达的基因疗法产物产生免疫反应。如果HSPC被基因修饰以表达与受体的HLA不匹配的不同的HLA类型,则类似的情况也会发生。
具有IgG半胱氨酸蛋白酶活性的多肽(如本发明的多肽)也可以与过继细胞转移免疫疗法(adoptive cell transfer immunotherapy)组合使用。过继细胞转移免疫疗法的效力可能会因转移细胞(如CAR-T细胞)的有限存活和有限持续活性而降低。具有IgG半胱氨酸蛋白酶的蛋白质可以保护转移细胞。特别是,预先存在的抗体和用转移细胞给药后产生的抗体可能会缩短转移细胞的潜能,而转移细胞的治疗效果将受益于通过受体的条件作用(conditioning)去除抗体效应功能。因此,施用具有IgG半胱氨酸蛋白酶活性的蛋白质可以提高转移细胞的存活和活性,从而提高过继细胞转移免疫疗法的病人的益处,并在例如癌症治疗方面提供更好的治疗和预后。在这种情况下,治疗癌症的方法可以包含在施用一个或多个剂量的过继细胞转移免疫疗法之前和/或之后,施用具有IgG半胱氨酸蛋白酶活性的本发明的多肽。在治疗自身免疫性疾病、感染和由有害抗体介导的疾病的方法的情况下,具有IgG半胱氨酸蛋白酶活性的多肽(如本发明的多肽)也可以与过继细胞转移免疫疗法组合使用。这种方法将使预先存在的抗药物抗体(ADA)和由过继细胞转移免疫疗法引起的抗体都被灭活。
实施例
除非另有说明,否则所用的方法是标准生物化学和分子生物学技术。合适的方法教科书的实例包括Sambrook et al., Molecular Cloning, A Laboratory Manual(1989)和Ausubel et al., Current Protocols in Molecular Biology (1995), JohnWiley and Sons, Inc。
分析成熟的IdeZ分子和序列,并识别适合突变的区域。在某些情况下,使用计算机评估(
将pCART239表达质粒转化到大肠杆菌T7E2(SOURCE)中并接种在含有50 μg/ml卡那霉素的LB琼脂糖平板上。挑取单个菌落,并在37℃、250 rpm下开始过夜培养(10 ml LB-培养基)。第二天将含有125 ml LB-培养基+50 µg/ml卡那霉素+1:100,000稀释防沫剂的2个烧瓶接种5 ml过夜培养物。接种时培养瓶已处于37℃,且培养物生长至OD值0.6-0.7(37℃,300 rpm)。此时,加入IPTG(终浓度1 mM)以诱导表达,并将培养物进一步孵育至少2小时。孵育后,通过离心(10分钟,4000 xg,4℃)收获细菌悬浮液,并丢弃上清液。将沉淀物在PBS(30 ml)中洗涤一次,重新离心丢弃上清液,最后的沉淀物在-20℃下冷冻,并在冷冻室中保存过夜。为了裂解细菌,根据制造商的说明使用Panda Plus 2000均质器(GEA),或者使用冻融方案(在10 ml PBS中三次冻融循环,借助无菌玻璃珠)。冻融循环后,将管离心(20分钟,25 000 xg,4°C)以分离出细菌裂解物(上清液),然后在冰上储存。将最终的细菌裂解液汇集起来,通过0.2 µm的尼龙过滤器(HPF Millex®-Nylon)进行无菌过滤,并使用Ni-NTA预包装的旋转柱(ThermoFisher)纯化蛋白质。纯化后,在洗脱液中加入DTT(终浓度5 mM)和EDTA(终浓度5 mM),之后更换缓冲液(Amicon Ultra-4 10K)。用NanoDrop 2000分光光度计(Thermo Scientific)测量蛋白质的浓度。使用十二烷基硫酸钠聚丙烯酰胺凝胶电泳(SDS-PAGE)无污染的12%Mini-PROTEAN®TGX
在该实施例中,人IgG1由Humira(Abbvie)代表,IgG2由XGEVA(Amgen)代表。这些被用来比较IdeZ变体以及IdeS阳性对照在切割单克隆人IgG方面的活性。IdeZ变体酶(和IdeS)在0.05% BSA的PBS中以1:3的稀释步骤从3.3 µg/ml的起始浓度开始滴定,切割产物通过SDS-PAGE(4-20%梯度凝胶)进行分析。测试的pCART242多肽相当于SEQ ID NO: 2增加了(1)N端蛋氨酸和(2)通过短的甘氨酸接头(3×甘氨酸)连接到C末端的C末端6×组氨酸标签。
1. 将25 µl的酶和对照(缓冲液)稀释液转移到多孔板中。
2. 在每个孔中加入25 µl 2 mg/ml的Humira或XGEVA溶液开始反应。这导致反应中每种抗体1 mg/ml。考虑到连续稀释,测试的最大IdeZ(或IdeS)浓度为3.3 µg/ml,最低为0.057 ng/ml。
3. 板在37℃下缓慢旋转孵育2小时。
4. 孵育后,在微量滴定板上将10 µl的每个样品与30 µl 2x SDS加样缓冲液混合。过夜储存后(4-8℃),将其转移到1.5 ml的管中并在92℃下孵育5分钟,将10 µl样品加样到15孔的4-20% Mini-PROTEAN®TGX™预制凝胶上,在非还原条件下对样品进行SDS-PAGE分析。
图2和图3分别显示了IdeZ变体消化IgG1(Humira)和IgG2(XGEVA)的凝胶。不同的图代表了不同的实验组(但每个示例中的方案是相同的)。
根据凝胶中显示的切割模式,估计IgG1/IgG2的第一和第二重链的切割的大约浓度如下:
表1A:IgG1的第一和第二重链的切割的大约浓度(图2A)。
表1B:IgG1的第一和第二重链的切割的大约浓度(图2B)。
表2A:IgG2的第一和第二重链的切割的大约浓度(图3A)。
表2B:IgG2的第一和第二重链的切割的大约浓度(图3B)。
IdeS、pCART207、pCART229在IgG1(Humira)切割上的效力非常相似。与IdeS和非常相似的变体pCART229相比,pCART239和N240的效力更高。N240和pCART242在切割第二IgG1重链上看上去比IdeS更有效。N240和pCART242比pCART229和pCART207对IgG2(Xgeva)的主要第二切割具有更高的效力,且在切割IgG2的第一重链上也更有效力。
该报告描述了N240通过消化各种IgG亚类的体外活性的特征。对于IgG亚类的情况,比较了两个不同的内部生产的N240批次,所用的参考材料是IdeS。
1. 将25 µl N240或IdeS酶和对照(缓冲液)稀释液转移到多孔板。酶在每个连续的孔之间以0.05 %BSA的PBS 1:3连续稀释。
2. 反应开始时,在每个孔中加入25 µl的2 mg/ml的人IgG溶液。这导致反应中每种抗体1 mg/ml。使用的IgG1是Humira(Abbvie),使用的IgG2是XGEVA(Amgen),使用的IgG3来自Sigma(I5654 Lot#SLBW0899),使用的IgG4来自Abcam(ab90286 Lot#GR3180469)。
3. 板在37℃下缓慢旋转孵育2小时。
4. 孵育后,在微量滴定板上将10 µl的每个样品与30 µl 2x SDS加样缓冲液混合。过夜储存后(4-8℃),将其转移到1.5 ml的管中并在92℃下孵育5分钟,将10 µl样品加样到15孔的4-20% Mini-PROTEAN®TGX™预制凝胶上。
显示N240和IdeS对IgG亚类的消化的凝胶显示在图4中。
根据凝胶的目测结果估计的EC
表3:IgG1、IgG2、IgG3和IgG4消化的EC
1. 所有四个人类亚类IgG1、IgG2、IgG3和IgG4都被N240切割。
2. 清楚的看到N240的活性较高(相对于IdeS),特别是对第二链切割。与N240相比,IdeS对IgG1的EC
3. 在IgG2、IgG3和IgG4的情况下,N240的效力与IdeS相似或略低。
MSD效力测定背后的原理的更详细的总结在下面实施例5中讨论。
简而言之,将山羊抗人IgG,F(ab')2片段特异性涂在96孔MSD板上。阻断后,洗涤板,并将以一系列的浓度稀释的N240参考材料和IdeS测试样品添加至板。加入固定浓度的人IgG,并在37℃下孵育板。孵育和洗涤后,将含有生物素化的小鼠抗人IgG(Fc特异性)和SULFO-TAG标记的链霉亲和素的检测混合物添加至板。在最后一次孵育和洗涤后,加入读数缓冲液(Read Buffer)。使用MSD仪器,测量SULFO-TAG的发光强度,以提供样品中非切割的和单一切割的IgG的定量测量。N240参考材料和IdeS测试样品以一式两份的孔和一式三份的板进行分析。每个参考和测试样品的EC
图5显示了得到的代表IdeS和N240的IgG切割的稀释曲线。
经计算,与IdeS相比,N240的平均相对效力为约300%。
IdeZ变体pCART239通过测量其在血清中的活性被进一步表征。
来自100个体的人类血清库被用作IgG底物。
用于pCART239的稀释系列如下:30、15、7.5、3.75、1.9、0.9、0.2、0.2、0.1、0.06和0.03 µg/mL,并遵循实施例2和中3所述的活性测定和SDS-PAGE分析方案。
显示pCART239对血清IgG的消化的凝胶显示在图6中。图中显示pCART239在血清库中具有IgG切割活性,凝胶估计切割IgG到scIgG以大约0.9 µg/ml的酶(图6,上图)。scIgG被进一步消化成F(ab')
在血清中获得的活性值低于在缓冲液中获得的活性值,这是以前研究中已知的现象,因为血清中存在抑制性抗药物抗体(ADA)。为了验证血清中除了抑制性ADA之外没有其他特异性抑制因子,进行添加0.1 mg/ml的pCART239的无活性变体(pCART243)的实验。这种添加是高摩尔过量的,并且应该与失活的ADA结合至血清中pCART239的活性被恢复的程度。事实证明是这样的(图6,下图),pCART243的存在使IgG的切割在更低的pCART239浓度下发生。完整的IgG在0.03 µg/ml时就已经开始被消化,所有的IgG在0.5 µg/ml时被转化为scIgG。
为了进一步研究N240在血清中的活性,在血清基质中进行了MSD效价测定。
这些测定的原理是用F(ab)
实验室方案的简要概括:将多滴定板的孔用山羊抗人Fab特异性F(ab)
由此产生的代表IdeS和N240的IgG切割的标准曲线显示在图7中。下表显示了基于由剂量响应曲线确定的EC
表4:根据EC
N240在血清中具有活性。在之前的实施例中,N240在缓冲溶液中的效价比Ilifidase的效价高约4倍,但当这两种酶在血清中进行比较时,该差异较小。在MSD效价分析中,与IdeS相比,N240在血清中对人IgG的活性仍显示出大幅提高(~142%)。
除以下内容外,遵循实施例5中所述的常规MSD方案。
多阵列MSD板涂有20 µg/ml N240或IdeS。在用来自健康个体(n = 40)和一个人类血清库(n = 100)的血清(1:100稀释度)孵育之前,用鱼胶封闭板。检测试剂是抗人F(ab')
结果见图8。该结果表明,针对N240的ADA水平低于针对IdeS的ADA。
序列表
<110> 汉莎生物制药股份有限公司
<120> 半胱氨酸蛋白酶
<130> 195420-22F-CNP
<150> GB 2007431.6
<151> 2020-05-19
<160> 23
<170> PatentIn version 3.5
<210> 1
<211> 312
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 1
Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val Pro
1 5 10 15
His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Glu Gln
20 25 30
Phe Thr Gln Gly Glu Asp Val Ile His Ala Pro Tyr Leu Ala His Gln
35 40 45
Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asn Gly Lys Asp Asp Leu Leu
50 55 60
Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp Gln
65 70 75 80
Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys His Pro Glu Lys Gln
85 90 95
Lys Ile Ile Phe Arg Asn Gln Glu Leu Phe Asp Leu Lys Ala Ala Ile
100 105 110
Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu Phe Asn Tyr Phe Arg
115 120 125
Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln Leu Gly Val Met Pro
130 135 140
Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr Tyr Leu Asn Val Phe
145 150 155 160
Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr Gln Asp Lys Asp Lys
165 170 175
Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asn Gln Thr Thr
180 185 190
Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys Gly Leu Asn Asp Ile
195 200 205
Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly Arg Ala Leu Ala Leu
210 215 220
Ser His Thr Tyr Ala Asn Val Ser Ile Ser His Val Ile Asn Leu Trp
225 230 235 240
Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu Ala Ile Tyr Val Thr
245 250 255
Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val Gly
260 265 270
Ile Asn Ala His Gly His Val Ala Ile Ser Ala Lys Lys Ile Glu Gly
275 280 285
Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Ser Gly
290 295 300
Lys Asp Ile Trp Gln Lys Leu Ser
305 310
<210> 2
<211> 292
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 2
Ser Val Trp Thr Lys Gly Val Thr Pro Pro Glu Gln Phe Thr Gln Gly
1 5 10 15
Glu Asp Val Ile His Ala Pro Tyr Leu Ala His Gln Gly Trp Tyr Asp
20 25 30
Ile Thr Lys Ala Phe Asn Gly Lys Asp Asp Leu Leu Cys Gly Ala Ala
35 40 45
Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp Gln Asn Lys Thr Glu
50 55 60
Ile Glu Ala Tyr Leu Ser Lys His Pro Glu Lys Gln Lys Ile Ile Phe
65 70 75 80
Arg Asn Gln Glu Leu Phe Asp Leu Lys Ala Ala Ile Asp Thr Lys Asp
85 90 95
Ser Gln Thr Asn Ser Gln Leu Phe Asn Tyr Phe Arg Asp Lys Ala Phe
100 105 110
Pro Asn Leu Ser Ala Arg Gln Leu Gly Val Met Pro Asp Leu Val Leu
115 120 125
Asp Met Phe Ile Asn Gly Tyr Tyr Leu Asn Val Phe Lys Thr Gln Ser
130 135 140
Thr Asp Val Asn Arg Pro Tyr Gln Asp Lys Asp Lys Arg Gly Gly Ile
145 150 155 160
Phe Asp Ala Val Phe Thr Arg Gly Asn Gln Thr Thr Leu Leu Thr Ala
165 170 175
Arg His Asp Leu Lys Asn Lys Gly Leu Asn Asp Ile Ser Thr Ile Ile
180 185 190
Lys Gln Glu Leu Thr Glu Gly Arg Ala Leu Ala Leu Ser His Thr Tyr
195 200 205
Ala Asn Val Ser Ile Ser His Val Ile Asn Leu Trp Gly Ala Asp Phe
210 215 220
Asn Ala Glu Gly Asn Leu Glu Ala Ile Tyr Val Thr Asp Ser Asp Ala
225 230 235 240
Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val Gly Ile Asn Ala His
245 250 255
Gly His Val Ala Ile Ser Ala Lys Lys Ile Glu Gly Glu Asn Ile Gly
260 265 270
Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Ser Gly Lys Asp Ile Trp
275 280 285
Gln Lys Leu Ser
290
<210> 3
<211> 315
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 3
Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val Pro
1 5 10 15
His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Leu Thr Pro
20 25 30
Glu Gln Phe Arg Tyr Asn Asn Glu Asp Val Ile His Ala Pro Tyr Leu
35 40 45
Ala His Gln Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asp Gly Lys Asp
50 55 60
Asn Leu Leu Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp
65 70 75 80
Phe Asp Gln Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys His Pro
85 90 95
Glu Lys Gln Lys Ile Ile Phe Asn Asn Gln Glu Leu Phe Asp Leu Lys
100 105 110
Ala Ala Ile Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu Phe Asn
115 120 125
Tyr Phe Arg Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln Leu Gly
130 135 140
Val Met Pro Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr Tyr Leu
145 150 155 160
Asn Val Phe Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr Gln Asp
165 170 175
Lys Asp Lys Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asp
180 185 190
Gln Thr Thr Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys Gly Leu
195 200 205
Asn Asp Ile Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly Arg Ala
210 215 220
Leu Ala Leu Ser His Thr Tyr Ala Asn Val Ser Ile Ser His Val Ile
225 230 235 240
Asn Leu Trp Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu Ala Ile
245 250 255
Tyr Val Thr Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys Lys Tyr
260 265 270
Phe Val Gly Ile Asn Ala His Gly His Val Ala Ile Ser Ala Lys Lys
275 280 285
Ile Glu Gly Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu
290 295 300
Ser Ser Gly Lys Asp Ile Trp Gln Lys Leu Ser
305 310 315
<210> 4
<211> 310
<212> PRT
<213> 化脓性链球菌(Streptococcus pyogenes)
<400> 4
Asp Ser Phe Ser Ala Asn Gln Glu Ile Arg Tyr Ser Glu Val Thr Pro
1 5 10 15
Tyr His Val Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Ala Asn
20 25 30
Phe Thr Gln Gly Glu Asp Val Phe His Ala Pro Tyr Val Ala Asn Gln
35 40 45
Gly Trp Tyr Asp Ile Thr Lys Thr Phe Asn Gly Lys Asp Asp Leu Leu
50 55 60
Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp Gln
65 70 75 80
Asn Lys Asp Gln Ile Lys Arg Tyr Leu Glu Glu His Pro Glu Lys Gln
85 90 95
Lys Ile Asn Phe Asn Gly Glu Gln Met Phe Asp Val Lys Glu Ala Ile
100 105 110
Asp Thr Lys Asn His Gln Leu Asp Ser Lys Leu Phe Glu Tyr Phe Lys
115 120 125
Glu Lys Ala Phe Pro Tyr Leu Ser Thr Lys His Leu Gly Val Phe Pro
130 135 140
Asp His Val Ile Asp Met Phe Ile Asn Gly Tyr Arg Leu Ser Leu Thr
145 150 155 160
Asn His Gly Pro Thr Pro Val Lys Glu Gly Ser Lys Asp Pro Arg Gly
165 170 175
Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asp Gln Ser Lys Leu Leu
180 185 190
Thr Ser Arg His Asp Phe Lys Glu Lys Asn Leu Lys Glu Ile Ser Asp
195 200 205
Leu Ile Lys Lys Glu Leu Thr Glu Gly Lys Ala Leu Gly Leu Ser His
210 215 220
Thr Tyr Ala Asn Val Arg Ile Asn His Val Ile Asn Leu Trp Gly Ala
225 230 235 240
Asp Phe Asp Ser Asn Gly Asn Leu Lys Ala Ile Tyr Val Thr Asp Ser
245 250 255
Asp Ser Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val Gly Val Asn
260 265 270
Ser Ala Gly Lys Val Ala Ile Ser Ala Lys Glu Ile Lys Glu Asp Asn
275 280 285
Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Thr Gly Gln Asp
290 295 300
Ser Trp Asn Gln Thr Asn
305 310
<210> 5
<211> 349
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 5
Met Lys Thr Ile Ala Tyr Pro Asn Lys Pro His Ser Leu Ser Ala Gly
1 5 10 15
Leu Leu Thr Ala Ile Ala Ile Phe Ser Leu Ala Ser Ser Asn Ile Thr
20 25 30
Tyr Ala Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu
35 40 45
Val Pro His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Leu
50 55 60
Thr Pro Glu Gln Phe Arg Tyr Asn Asn Glu Asp Val Ile His Ala Pro
65 70 75 80
Tyr Leu Ala His Gln Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asp Gly
85 90 95
Lys Asp Asn Leu Leu Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His
100 105 110
Trp Trp Phe Asp Gln Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys
115 120 125
His Pro Glu Lys Gln Lys Ile Ile Phe Asn Asn Gln Glu Leu Phe Asp
130 135 140
Leu Lys Ala Ala Ile Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu
145 150 155 160
Phe Asn Tyr Phe Arg Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln
165 170 175
Leu Gly Val Met Pro Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr
180 185 190
Tyr Leu Asn Val Phe Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr
195 200 205
Gln Asp Lys Asp Lys Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg
210 215 220
Gly Asp Gln Thr Thr Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys
225 230 235 240
Gly Leu Asn Asp Ile Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly
245 250 255
Arg Ala Leu Ala Leu Ser His Thr Tyr Ala Asn Val Ser Ile Ser His
260 265 270
Val Ile Asn Leu Trp Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu
275 280 285
Ala Ile Tyr Val Thr Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys
290 295 300
Lys Tyr Phe Val Gly Ile Asn Ala His Gly His Val Ala Ile Ser Ala
305 310 315 320
Lys Lys Ile Glu Gly Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe
325 330 335
Thr Leu Ser Ser Gly Lys Asp Ile Trp Gln Lys Leu Ser
340 345
<210> 6
<211> 339
<212> PRT
<213> 化脓性链球菌(Streptococcus pyogenes)
<400> 6
Met Arg Lys Arg Cys Tyr Ser Thr Ser Ala Ala Val Leu Ala Ala Val
1 5 10 15
Thr Leu Phe Val Leu Ser Val Asp Arg Gly Val Ile Ala Asp Ser Phe
20 25 30
Ser Ala Asn Gln Glu Ile Arg Tyr Ser Glu Val Thr Pro Tyr His Val
35 40 45
Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Ala Asn Phe Thr Gln
50 55 60
Gly Glu Asp Val Phe His Ala Pro Tyr Val Ala Asn Gln Gly Trp Tyr
65 70 75 80
Asp Ile Thr Lys Thr Phe Asn Gly Lys Asp Asp Leu Leu Cys Gly Ala
85 90 95
Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp Gln Asn Lys Asp
100 105 110
Gln Ile Lys Arg Tyr Leu Glu Glu His Pro Glu Lys Gln Lys Ile Asn
115 120 125
Phe Asn Gly Glu Gln Met Phe Asp Val Lys Glu Ala Ile Asp Thr Lys
130 135 140
Asn His Gln Leu Asp Ser Lys Leu Phe Glu Tyr Phe Lys Glu Lys Ala
145 150 155 160
Phe Pro Tyr Leu Ser Thr Lys His Leu Gly Val Phe Pro Asp His Val
165 170 175
Ile Asp Met Phe Ile Asn Gly Tyr Arg Leu Ser Leu Thr Asn His Gly
180 185 190
Pro Thr Pro Val Lys Glu Gly Ser Lys Asp Pro Arg Gly Gly Ile Phe
195 200 205
Asp Ala Val Phe Thr Arg Gly Asp Gln Ser Lys Leu Leu Thr Ser Arg
210 215 220
His Asp Phe Lys Glu Lys Asn Leu Lys Glu Ile Ser Asp Leu Ile Lys
225 230 235 240
Lys Glu Leu Thr Glu Gly Lys Ala Leu Gly Leu Ser His Thr Tyr Ala
245 250 255
Asn Val Arg Ile Asn His Val Ile Asn Leu Trp Gly Ala Asp Phe Asp
260 265 270
Ser Asn Gly Asn Leu Lys Ala Ile Tyr Val Thr Asp Ser Asp Ser Asn
275 280 285
Ala Ser Ile Gly Met Lys Lys Tyr Phe Val Gly Val Asn Ser Ala Gly
290 295 300
Lys Val Ala Ile Ser Ala Lys Glu Ile Lys Glu Asp Asn Ile Gly Ala
305 310 315 320
Gln Val Leu Gly Leu Phe Thr Leu Ser Thr Gly Gln Asp Ser Trp Asn
325 330 335
Gln Thr Asn
<210> 7
<211> 313
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 7
Met Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val
1 5 10 15
Pro His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Glu
20 25 30
Gln Phe Thr Gln Gly Glu Asp Val Ile His Ala Pro Tyr Leu Ala His
35 40 45
Gln Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asp Gly Lys Asp Asn Leu
50 55 60
Leu Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp
65 70 75 80
Gln Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys His Pro Glu Lys
85 90 95
Gln Lys Ile Ile Phe Arg Asn Gln Glu Leu Phe Asp Leu Lys Ala Ala
100 105 110
Ile Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu Phe Asn Tyr Phe
115 120 125
Arg Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln Leu Gly Val Met
130 135 140
Pro Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr Tyr Leu Asn Val
145 150 155 160
Phe Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr Gln Asp Lys Asp
165 170 175
Lys Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asp Gln Thr
180 185 190
Thr Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys Gly Leu Asn Asp
195 200 205
Ile Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly Arg Ala Leu Ala
210 215 220
Leu Ser His Thr Tyr Ala Asn Val Ser Ile Ser His Val Ile Asn Leu
225 230 235 240
Trp Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu Ala Ile Tyr Val
245 250 255
Thr Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val
260 265 270
Gly Ile Asn Ala His Gly His Val Ala Ile Ser Ala Lys Lys Ile Glu
275 280 285
Gly Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Ser
290 295 300
Gly Lys Asp Ile Trp Gln Lys Leu Ser
305 310
<210> 8
<211> 313
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 8
Met Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val
1 5 10 15
Pro His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Glu
20 25 30
Gln Phe Thr Gln Gly Glu Asp Val Ile His Ala Pro Tyr Leu Ala His
35 40 45
Gln Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asp Gly Lys Asp Asn Leu
50 55 60
Leu Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp
65 70 75 80
Gln Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys His Pro Glu Lys
85 90 95
Gln Lys Ile Ile Phe Arg Asn Gln Glu Leu Phe Asp Leu Lys Ala Ala
100 105 110
Ile Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu Phe Asn Tyr Phe
115 120 125
Arg Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln Leu Gly Val Met
130 135 140
Pro Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr Tyr Leu Asn Val
145 150 155 160
Phe Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr Gln Asp Lys Asp
165 170 175
Lys Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asn Gln Thr
180 185 190
Thr Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys Gly Leu Asn Asp
195 200 205
Ile Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly Arg Ala Leu Ala
210 215 220
Leu Ser His Thr Tyr Ala Asn Val Ser Ile Ser His Val Ile Asn Leu
225 230 235 240
Trp Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu Ala Ile Tyr Val
245 250 255
Thr Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val
260 265 270
Gly Ile Asn Ala His Gly His Val Ala Ile Ser Ala Lys Lys Ile Glu
275 280 285
Gly Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Ser
290 295 300
Gly Lys Asp Ile Trp Gln Lys Leu Ser
305 310
<210> 9
<211> 322
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 9
Met Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val
1 5 10 15
Pro His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Glu
20 25 30
Gln Phe Thr Gln Gly Glu Asp Val Ile His Ala Pro Tyr Leu Ala His
35 40 45
Gln Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asn Gly Lys Asp Asp Leu
50 55 60
Leu Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp
65 70 75 80
Gln Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys His Pro Glu Lys
85 90 95
Gln Lys Ile Ile Phe Arg Asn Gln Glu Leu Phe Asp Leu Lys Ala Ala
100 105 110
Ile Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu Phe Asn Tyr Phe
115 120 125
Arg Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln Leu Gly Val Met
130 135 140
Pro Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr Tyr Leu Asn Val
145 150 155 160
Phe Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr Gln Asp Lys Asp
165 170 175
Lys Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asn Gln Thr
180 185 190
Thr Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys Gly Leu Asn Asp
195 200 205
Ile Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly Arg Ala Leu Ala
210 215 220
Leu Ser His Thr Tyr Ala Asn Val Ser Ile Ser His Val Ile Asn Leu
225 230 235 240
Trp Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu Ala Ile Tyr Val
245 250 255
Thr Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val
260 265 270
Gly Ile Asn Ala His Gly His Val Ala Ile Ser Ala Lys Lys Ile Glu
275 280 285
Gly Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Ser
290 295 300
Gly Lys Asp Ile Trp Gln Lys Leu Ser Gly Gly Gly His His His His
305 310 315 320
His His
<210> 10
<211> 313
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 10
Met Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val
1 5 10 15
Pro His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Glu
20 25 30
Gln Phe Thr Gln Gly Glu Asp Val Ile His Ala Pro Tyr Leu Ala His
35 40 45
Gln Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asn Gly Lys Asp Asp Leu
50 55 60
Leu Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp
65 70 75 80
Gln Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys His Pro Glu Lys
85 90 95
Gln Lys Ile Ile Phe Arg Asn Gln Glu Leu Phe Asp Leu Lys Ala Ala
100 105 110
Ile Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu Phe Asn Tyr Phe
115 120 125
Arg Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln Leu Gly Val Met
130 135 140
Pro Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr Tyr Leu Asn Val
145 150 155 160
Phe Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr Gln Asp Lys Asp
165 170 175
Lys Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asn Gln Thr
180 185 190
Thr Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys Gly Leu Asn Asp
195 200 205
Ile Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly Arg Ala Leu Ala
210 215 220
Leu Ser His Thr Tyr Ala Asn Val Ser Ile Ser His Val Ile Asn Leu
225 230 235 240
Trp Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu Ala Ile Tyr Val
245 250 255
Thr Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val
260 265 270
Gly Ile Asn Ala His Gly His Val Ala Ile Ser Ala Lys Lys Ile Glu
275 280 285
Gly Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Ser
290 295 300
Gly Lys Asp Ile Trp Gln Lys Leu Ser
305 310
<210> 11
<211> 302
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 11
Met Ser Val Trp Thr Lys Gly Val Thr Pro Pro Glu Gln Phe Thr Gln
1 5 10 15
Gly Glu Asp Val Ile His Ala Pro Tyr Leu Ala His Gln Gly Trp Tyr
20 25 30
Asp Ile Thr Lys Ala Phe Asn Gly Lys Asp Asp Leu Leu Cys Gly Ala
35 40 45
Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp Gln Asn Lys Thr
50 55 60
Glu Ile Glu Ala Tyr Leu Ser Lys His Pro Glu Lys Gln Lys Ile Ile
65 70 75 80
Phe Arg Asn Gln Glu Leu Phe Asp Leu Lys Ala Ala Ile Asp Thr Lys
85 90 95
Asp Ser Gln Thr Asn Ser Gln Leu Phe Asn Tyr Phe Arg Asp Lys Ala
100 105 110
Phe Pro Asn Leu Ser Ala Arg Gln Leu Gly Val Met Pro Asp Leu Val
115 120 125
Leu Asp Met Phe Ile Asn Gly Tyr Tyr Leu Asn Val Phe Lys Thr Gln
130 135 140
Ser Thr Asp Val Asn Arg Pro Tyr Gln Asp Lys Asp Lys Arg Gly Gly
145 150 155 160
Ile Phe Asp Ala Val Phe Thr Arg Gly Asn Gln Thr Thr Leu Leu Thr
165 170 175
Ala Arg His Asp Leu Lys Asn Lys Gly Leu Asn Asp Ile Ser Thr Ile
180 185 190
Ile Lys Gln Glu Leu Thr Glu Gly Arg Ala Leu Ala Leu Ser His Thr
195 200 205
Tyr Ala Asn Val Ser Ile Ser His Val Ile Asn Leu Trp Gly Ala Asp
210 215 220
Phe Asn Ala Glu Gly Asn Leu Glu Ala Ile Tyr Val Thr Asp Ser Asp
225 230 235 240
Ala Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val Gly Ile Asn Ala
245 250 255
His Gly His Val Ala Ile Ser Ala Lys Lys Ile Glu Gly Glu Asn Ile
260 265 270
Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Ser Gly Lys Asp Ile
275 280 285
Trp Gln Lys Leu Ser Gly Gly Gly His His His His His His
290 295 300
<210> 12
<211> 322
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 12
Met Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val
1 5 10 15
Pro His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Glu
20 25 30
Gln Phe Thr Gln Gly Glu Asp Val Ile His Ala Pro Tyr Leu Ala His
35 40 45
Gln Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asn Gly Lys Asp Asp Leu
50 55 60
Leu Gly Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp
65 70 75 80
Gln Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys His Pro Glu Lys
85 90 95
Gln Lys Ile Ile Phe Arg Asn Gln Glu Leu Phe Asp Leu Lys Ala Ala
100 105 110
Ile Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu Phe Asn Tyr Phe
115 120 125
Arg Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln Leu Gly Val Met
130 135 140
Pro Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr Tyr Leu Asn Val
145 150 155 160
Phe Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr Gln Asp Lys Asp
165 170 175
Lys Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asn Gln Thr
180 185 190
Thr Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys Gly Leu Asn Asp
195 200 205
Ile Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly Arg Ala Leu Ala
210 215 220
Leu Ser His Thr Tyr Ala Asn Val Ser Ile Ser His Val Ile Asn Leu
225 230 235 240
Trp Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu Ala Ile Tyr Val
245 250 255
Thr Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val
260 265 270
Gly Ile Asn Ala His Gly His Val Ala Ile Ser Ala Lys Lys Ile Glu
275 280 285
Gly Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Ser
290 295 300
Gly Lys Asp Ile Trp Gln Lys Leu Ser Gly Gly Gly His His His His
305 310 315 320
His His
<210> 13
<211> 320
<212> PRT
<213> 化脓性链球菌(Streptococcus pyogenes)
<400> 13
Met Asp Ser Phe Ser Ala Asn Gln Glu Ile Arg Tyr Ser Glu Val Thr
1 5 10 15
Pro Tyr His Val Thr Ser Val Trp Thr Lys Gly Val Thr Pro Pro Ala
20 25 30
Asn Phe Thr Gln Gly Glu Asp Val Phe His Ala Pro Tyr Val Ala Asn
35 40 45
Gln Gly Trp Tyr Asp Ile Thr Lys Thr Phe Asn Gly Lys Asp Asp Leu
50 55 60
Leu Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp Trp Phe Asp
65 70 75 80
Gln Asn Lys Asp Gln Ile Lys Arg Tyr Leu Glu Glu His Pro Glu Lys
85 90 95
Gln Lys Ile Asn Phe Asn Gly Glu Gln Met Phe Asp Val Lys Glu Ala
100 105 110
Ile Asp Thr Lys Asn His Gln Leu Asp Ser Lys Leu Phe Glu Tyr Phe
115 120 125
Lys Glu Lys Ala Phe Pro Tyr Leu Ser Thr Lys His Leu Gly Val Phe
130 135 140
Pro Asp His Val Ile Asp Met Phe Ile Asn Gly Tyr Arg Leu Ser Leu
145 150 155 160
Thr Asn His Gly Pro Thr Pro Val Lys Glu Gly Ser Lys Asp Pro Arg
165 170 175
Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly Asp Gln Ser Lys Leu
180 185 190
Leu Thr Ser Arg His Asp Phe Lys Glu Lys Asn Leu Lys Glu Ile Ser
195 200 205
Asp Leu Ile Lys Lys Glu Leu Thr Glu Gly Lys Ala Leu Gly Leu Ser
210 215 220
His Thr Tyr Ala Asn Val Arg Ile Asn His Val Ile Asn Leu Trp Gly
225 230 235 240
Ala Asp Phe Asp Ser Asn Gly Asn Leu Lys Ala Ile Tyr Val Thr Asp
245 250 255
Ser Asp Ser Asn Ala Ser Ile Gly Met Lys Lys Tyr Phe Val Gly Val
260 265 270
Asn Ser Ala Gly Lys Val Ala Ile Ser Ala Lys Glu Ile Lys Glu Asp
275 280 285
Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr Leu Ser Thr Gly Gln
290 295 300
Asp Ser Trp Asn Gln Thr Asn Gly Gly Gly His His His His His His
305 310 315 320
<210> 14
<211> 325
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 14
Met Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val
1 5 10 15
Pro His Gln Ile Thr Ser Val Trp Thr Lys Gly Val Thr Pro Leu Thr
20 25 30
Pro Glu Gln Phe Arg Tyr Asn Asn Glu Asp Val Ile His Ala Pro Tyr
35 40 45
Leu Ala His Gln Gly Trp Tyr Asp Ile Thr Lys Ala Phe Asp Gly Lys
50 55 60
Asp Asn Leu Leu Cys Gly Ala Ala Thr Ala Gly Asn Met Leu His Trp
65 70 75 80
Trp Phe Asp Gln Asn Lys Thr Glu Ile Glu Ala Tyr Leu Ser Lys His
85 90 95
Pro Glu Lys Gln Lys Ile Ile Phe Asn Asn Gln Glu Leu Phe Asp Leu
100 105 110
Lys Ala Ala Ile Asp Thr Lys Asp Ser Gln Thr Asn Ser Gln Leu Phe
115 120 125
Asn Tyr Phe Arg Asp Lys Ala Phe Pro Asn Leu Ser Ala Arg Gln Leu
130 135 140
Gly Val Met Pro Asp Leu Val Leu Asp Met Phe Ile Asn Gly Tyr Tyr
145 150 155 160
Leu Asn Val Phe Lys Thr Gln Ser Thr Asp Val Asn Arg Pro Tyr Gln
165 170 175
Asp Lys Asp Lys Arg Gly Gly Ile Phe Asp Ala Val Phe Thr Arg Gly
180 185 190
Asp Gln Thr Thr Leu Leu Thr Ala Arg His Asp Leu Lys Asn Lys Gly
195 200 205
Leu Asn Asp Ile Ser Thr Ile Ile Lys Gln Glu Leu Thr Glu Gly Arg
210 215 220
Ala Leu Ala Leu Ser His Thr Tyr Ala Asn Val Ser Ile Ser His Val
225 230 235 240
Ile Asn Leu Trp Gly Ala Asp Phe Asn Ala Glu Gly Asn Leu Glu Ala
245 250 255
Ile Tyr Val Thr Asp Ser Asp Ala Asn Ala Ser Ile Gly Met Lys Lys
260 265 270
Tyr Phe Val Gly Ile Asn Ala His Gly His Val Ala Ile Ser Ala Lys
275 280 285
Lys Ile Glu Gly Glu Asn Ile Gly Ala Gln Val Leu Gly Leu Phe Thr
290 295 300
Leu Ser Ser Gly Lys Asp Ile Trp Gln Lys Leu Ser Gly Gly Gly His
305 310 315 320
His His His His His
325
<210> 15
<211> 20
<212> PRT
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 15
Asp Asp Tyr Gln Arg Asn Ala Thr Glu Ala Tyr Ala Lys Glu Val Pro
1 5 10 15
His Gln Ile Thr
20
<210> 16
<211> 969
<212> DNA
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 16
atggacgatt accaaaggaa tgctacggaa gcttatgcca aagaagtacc acatcagatc 60
acttctgtat ggaccaaagg tgttacacca cccgagcagt ttactcaagg tgaagatgtg 120
atccatgcgc catatcttgc tcatcaaggc tggtacgata tcaccaaggc cttcgatggg 180
aaggataatc tcttgtgtgg cgcagcaacg gcaggtaata tgctgcattg gtggtttgat 240
caaaataaaa cagagattga agcctattta agtaaacacc ctgaaaagca aaaaatcatt 300
tttcgtaacc aagagctatt tgatttgaaa gctgctatcg ataccaagga cagtcaaacc 360
aatagtcagc tttttaatta ttttagagat aaagcctttc caaatctatc agcacgtcaa 420
ctcggggtta tgcctgatct tgttctagat atgtttatca atggttacta cttaaatgtg 480
tttaaaacac agtctactga tgtcaatcga ccttatcagg acaaggacaa acgaggtggt 540
attttcgatg ctgttttcac cagaggagat cagacaacgc tcttgacagc tcgtcatgat 600
ttaaaaaata aaggactaaa tgacatcagc accattatca agcaagaact gactgaagga 660
agagcccttg ctttatcaca tacctacgcc aatgttagca ttagccatgt gattaacttg 720
tggggagctg attttaatgc tgaaggaaac cttgaggcca tctatgtcac agactcagat 780
gctaatgcgt ctattggtat gaaaaaatat tttgtcggca ttaatgctca tggacatgtc 840
gccatttctg ccaagaaaat agaaggagaa aacattggcg ctcaagtatt aggcttattt 900
acgctttcca gtggcaagga catttggcag aaactgagcg gcggtggcca tcatcaccat 960
caccactaa 969
<210> 17
<211> 969
<212> DNA
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 17
atggacgatt accaaaggaa tgctacggaa gcttatgcca aagaagtacc acatcagatc 60
acttctgtat ggaccaaagg tgttacacca cccgagcagt ttactcaagg tgaagatgtg 120
atccatgcgc catatcttgc tcatcaaggc tggtacgata tcaccaaggc cttcgatggg 180
aaggataatc tcttgtgtgg cgcagcaacg gcaggtaata tgctgcattg gtggtttgat 240
caaaataaaa cagagattga agcctattta agtaaacacc ctgaaaagca aaaaatcatt 300
tttcgtaacc aagagctatt tgatttgaaa gctgctatcg ataccaagga cagtcaaacc 360
aatagtcagc tttttaatta ttttagagat aaagcctttc caaatctatc agcacgtcaa 420
ctcggggtta tgcctgatct tgttctagat atgtttatca atggttacta cttaaatgtg 480
tttaaaacac agtctactga tgtcaatcga ccttatcagg acaaggacaa acgaggtggt 540
attttcgatg ctgttttcac cagaggaaac cagacaacgc tcttgacagc tcgtcatgat 600
ttaaaaaata aaggactaaa tgacatcagc accattatca agcaagaact gactgaagga 660
agagcccttg ctttatcaca tacctacgcc aatgttagca ttagccatgt gattaacttg 720
tggggagctg attttaatgc tgaaggaaac cttgaggcca tctatgtcac agactcagat 780
gctaatgcgt ctattggtat gaaaaaatat tttgtcggca ttaatgctca tggacatgtc 840
gccatttctg ccaagaaaat agaaggagaa aacattggcg ctcaagtatt aggcttattt 900
acgctttcca gtggcaagga catttggcag aaactgagcg gcggtggcca tcatcaccat 960
caccactaa 969
<210> 18
<211> 969
<212> DNA
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 18
atggacgatt accaaaggaa tgctacggaa gcttatgcca aagaagtacc acatcagatc 60
acttctgtat ggaccaaagg tgttacacca cccgagcagt ttactcaagg tgaagatgtg 120
atccatgcgc catatcttgc tcatcaaggc tggtacgata tcaccaaggc cttcaatggg 180
aaggatgatc tcttgtgtgg cgcagcaacg gcaggtaata tgctgcattg gtggtttgat 240
caaaataaaa cagagattga agcctattta agtaaacacc ctgaaaagca aaaaatcatt 300
tttcgtaacc aagagctatt tgatttgaaa gctgctatcg ataccaagga cagtcaaacc 360
aatagtcagc tttttaatta ttttagagat aaagcctttc caaatctatc agcacgtcaa 420
ctcggggtta tgcctgatct tgttctagat atgtttatca atggttacta cttaaatgtg 480
tttaaaacac agtctactga tgtcaatcga ccttatcagg acaaggacaa acgaggtggt 540
attttcgatg ctgttttcac cagaggaaac cagacaacgc tcttgacagc tcgtcatgat 600
ttaaaaaata aaggactaaa tgacatcagc accattatca agcaagaact gactgaagga 660
agagcccttg ctttatcaca tacctacgcc aatgttagca ttagccatgt gattaacttg 720
tggggagctg attttaatgc tgaaggaaac cttgaggcca tctatgtcac agactcagat 780
gctaatgcgt ctattggtat gaaaaaatat tttgtcggca ttaatgctca tggacatgtc 840
gccatttctg ccaagaaaat agaaggagaa aacattggcg ctcaagtatt aggcttattt 900
acgctttcca gtggcaagga catttggcag aaactgagcg gcggtggcca tcatcaccat 960
caccactaa 969
<210> 19
<211> 942
<212> DNA
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 19
atggacgatt accaaaggaa tgctacggaa gcttatgcca aagaagtacc acatcagatc 60
acttctgtat ggaccaaagg tgttacacca cccgagcagt ttactcaagg tgaagatgtg 120
atccatgcgc catatcttgc tcatcaaggc tggtacgata tcaccaaggc cttcaatggg 180
aaggatgatc tcttgtgtgg cgcagcaacg gcaggtaata tgctgcattg gtggtttgat 240
caaaataaaa cagagattga agcctattta agtaaacacc ctgaaaagca aaaaatcatt 300
tttcgtaacc aagagctatt tgatttgaaa gctgctatcg ataccaagga cagtcaaacc 360
aatagtcagc tttttaatta ttttagagat aaagcctttc caaatctatc agcacgtcaa 420
ctcggggtta tgcctgatct tgttctagat atgtttatca atggttacta cttaaatgtg 480
tttaaaacac agtctactga tgtcaatcga ccttatcagg acaaggacaa acgaggtggt 540
attttcgatg ctgttttcac cagaggaaac cagacaacgc tcttgacagc tcgtcatgat 600
ttaaaaaata aaggactaaa tgacatcagc accattatca agcaagaact gactgaagga 660
agagcccttg ctttatcaca tacctacgcc aatgttagca ttagccatgt gattaacttg 720
tggggagctg attttaatgc tgaaggaaac cttgaggcca tctatgtcac agactcagat 780
gctaatgcgt ctattggtat gaaaaaatat tttgtcggca ttaatgctca tggacatgtc 840
gccatttctg ccaagaaaat agaaggagaa aacattggcg ctcaagtatt aggcttattt 900
acgctttcca gtggcaagga catttggcag aaactgagct aa 942
<210> 20
<211> 909
<212> DNA
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 20
atgtctgtat ggaccaaagg tgttacacca cccgagcagt ttactcaagg tgaagatgtg 60
atccatgcgc catatcttgc tcatcaaggc tggtacgata tcaccaaggc cttcaatggg 120
aaggatgatc tcttgtgtgg cgcagcaacg gcaggtaata tgctgcattg gtggtttgat 180
caaaataaaa cagagattga agcctattta agtaaacacc ctgaaaagca aaaaatcatt 240
tttcgtaacc aagagctatt tgatttgaaa gctgctatcg ataccaagga cagtcaaacc 300
aatagtcagc tttttaatta ttttagagat aaagcctttc caaatctatc agcacgtcaa 360
ctcggggtta tgcctgatct tgttctagat atgtttatca atggttacta cttaaatgtg 420
tttaaaacac agtctactga tgtcaatcga ccttatcagg acaaggacaa acgaggtggt 480
attttcgatg ctgttttcac cagaggaaac cagacaacgc tcttgacagc tcgtcatgat 540
ttaaaaaata aaggactaaa tgacatcagc accattatca agcaagaact gactgaagga 600
agagcccttg ctttatcaca tacctacgcc aatgttagca ttagccatgt gattaacttg 660
tggggagctg attttaatgc tgaaggaaac cttgaggcca tctatgtcac agactcagat 720
gctaatgcgt ctattggtat gaaaaaatat tttgtcggca ttaatgctca tggacatgtc 780
gccatttctg ccaagaaaat agaaggagaa aacattggcg ctcaagtatt aggcttattt 840
acgctttcca gtggcaagga catttggcag aaactgagcg gcggtggcca tcatcaccat 900
caccactaa 909
<210> 21
<211> 969
<212> DNA
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 21
atggacgatt accaaaggaa tgctacggaa gcttatgcca aagaagtacc acatcagatc 60
acttctgtat ggaccaaagg tgttacacca cccgagcagt ttactcaagg tgaagatgtg 120
atccatgcgc catatcttgc tcatcaaggc tggtacgata tcaccaaggc cttcaatggg 180
aaggatgatc tcttgggtgg cgcagcaacg gcaggtaata tgctgcattg gtggtttgat 240
caaaataaaa cagagattga agcctattta agtaaacacc ctgaaaagca aaaaatcatt 300
tttcgtaacc aagagctatt tgatttgaaa gctgctatcg ataccaagga cagtcaaacc 360
aatagtcagc tttttaatta ttttagagat aaagcctttc caaatctatc agcacgtcaa 420
ctcggggtta tgcctgatct tgttctagat atgtttatca atggttacta cttaaatgtg 480
tttaaaacac agtctactga tgtcaatcga ccttatcagg acaaggacaa acgaggtggt 540
attttcgatg ctgttttcac cagaggaaac cagacaacgc tcttgacagc tcgtcatgat 600
ttaaaaaata aaggactaaa tgacatcagc accattatca agcaagaact gactgaagga 660
agagcccttg ctttatcaca tacctacgcc aatgttagca ttagccatgt gattaacttg 720
tggggagctg attttaatgc tgaaggaaac cttgaggcca tctatgtcac agactcagat 780
gctaatgcgt ctattggtat gaaaaaatat tttgtcggca ttaatgctca tggacatgtc 840
gccatttctg ccaagaaaat agaaggagaa aacattggcg ctcaagtatt aggcttattt 900
acgctttcca gtggcaagga catttggcag aaactgagcg gcggtggcca tcatcaccat 960
caccactaa 969
<210> 22
<211> 963
<212> DNA
<213> 化脓性链球菌(Streptococcus pyogenes)
<400> 22
atggatagtt tttctgctaa tcaagagatt agatattcgg aagtaacacc ttatcacgtt 60
acttccgttt ggaccaaagg agttactcct ccagcaaact tcactcaagg tgaagatgtt 120
tttcacgctc cttatgttgc taaccaagga tggtatgata ttaccaaaac attcaatgga 180
aaagacgatc ttctttgcgg ggctgccaca gcagggaata tgcttcactg gtggttcgat 240
caaaacaaag accaaattaa acgttatttg gaagagcatc cagaaaagca aaaaataaac 300
ttcaatggcg aacagatgtt tgacgtaaaa gaagctatcg acactaaaaa ccaccagcta 360
gatagtaaat tatttgaata ttttaaagaa aaagctttcc cttatctatc tactaaacac 420
ctaggagttt tccctgatca tgtaattgat atgttcatta acggctaccg ccttagtcta 480
actaaccacg gtccaacgcc agtaaaagaa ggtagtaaag atccccgagg tggtattttt 540
gacgccgtat ttacaagagg tgatcaaagt aagctattga caagtcgtca tgattttaaa 600
gaaaaaaatc tcaaagaaat cagtgatctc attaagaaag agttaaccga aggcaaggct 660
ctaggcctat cacacaccta cgctaacgta cgcatcaacc atgttataaa cctgtgggga 720
gctgactttg attctaacgg gaaccttaaa gctatttatg taacagactc tgatagtaat 780
gcatctattg gtatgaagaa atactttgtt ggtgttaatt ccgctggaaa agtagctatt 840
tctgctaaag aaataaaaga agataatata ggtgctcaag tactagggtt atttacactt 900
tcaacagggc aagatagttg gaatcagacc aatggcggtg gccatcatca ccatcaccac 960
taa 963
<210> 23
<211> 978
<212> DNA
<213> 马链球菌兽疫亚种(Streptococcus equi ssp. Zooepidemicus)
<400> 23
atggacgatt accaaaggaa tgctacggaa gcttatgcca aagaagtacc acatcagatc 60
acttctgtat ggaccaaagg tgttacacca ctaacacccg agcagtttcg atataataac 120
gaagatgtga tccatgcgcc atatcttgct catcaaggct ggtacgatat caccaaggcc 180
ttcgatggga aggataatct cttgtgtggc gcagcaacgg caggtaatat gctgcattgg 240
tggtttgatc aaaataaaac agagattgaa gcctatttaa gtaaacaccc tgaaaagcaa 300
aaaatcattt ttaacaacca agagctattt gatttgaaag ctgctatcga taccaaggac 360
agtcaaacca atagtcagct ttttaattat tttagagata aagcctttcc aaatctatca 420
gcacgtcaac tcggggttat gcctgatctt gttctagata tgtttatcaa tggttactac 480
ttaaatgtgt ttaaaacaca gtctactgat gtcaatcgac cttatcagga caaggacaaa 540
cgaggtggta ttttcgatgc tgttttcacc agaggagatc agacaacgct cttgacagct 600
cgtcatgatt taaaaaataa aggactaaat gacatcagca ccattatcaa gcaagaactg 660
actgaaggaa gagcccttgc tttatcacat acctacgcca atgttagcat tagccatgtg 720
attaacttgt ggggagctga ttttaatgct gaaggaaacc ttgaggccat ctatgtcaca 780
gactcagatg ctaatgcgtc tattggtatg aaaaaatatt ttgtcggcat taatgctcat 840
ggacatgtcg ccatttctgc caagaaaata gaaggagaaa acattggcgc tcaagtatta 900
ggcttattta cgctttccag tggcaaggac atttggcaga aactgagcgg cggtggccat 960
catcaccatc accactaa 978
- 选择性组织蛋白酶半胱氨酸蛋白酶抑制剂的制备方法
- 基质金属蛋白酶可裂解的和丝氨酸或半胱氨酸蛋白酶可裂解的底物及其使用方法