非结构化事件抽取方法
文献发布时间:2023-06-19 18:35:48
技术领域
本发明属于自然语言处理的技术领域,具体涉及一种非结构化事件抽取方法。
背景技术
当前大数据时代为社会治理、舆情分析和态势感知等重大社会需求提出了更高的要求。在生活和生产中,政府部门、企业公司以及个人正面对着越来越多与工作、生活密切相关的非结构化文本信息。以前主要以人力方法通过查阅大量资料进行信息获取,然而在当下,人力搜索已经无法高效高质量地从海量信息中获取到有效信息。事件是各种事件要素的组合,事件要素之间产生不同交互。事件抽取任务定义为从未处理的文本中获得需要关注的事件信息,可能包含人、时间和地点等要素。事件抽取技术可以抽取文本中提到的事件、触发器和每个事件对应的参数,并分类每个参数的作用。
发明内容
本发明的目的在于针对现有技术中的上述不足,提供一种非结构化事件抽取方法,以解决现有人力搜索已经无法高效高质量地从海量信息中获取到有效信息的问题。
为达到上述目的,本发明采取的技术方案是:
一种非结构化事件抽取方法,其包括以下步骤:
S1、采用嵌入方法获取输入文本的向量表示,并通过有监督的词级别注意力机制在关注事件触发词的状态下获得句子语义;
S2、根据有监督的句子级别注意力机制在重点关注包含事件触发词的句子的状态下获得文档语义;
S3、采用文本嵌入方法获取文本中代表主题信息重点语句的主题句的向量表示;
S4、将待分类的事件触发词候选词与获得的所述文档语义进行融合,并输入到分类器,得到事件触发词抽取结果;
S5、采用嵌入方法获得输入文本的向量表示,并获得融合事件类型信息和实体类型信息的语义增强的词表示;
S6、根据获得的语义增强的词表示,采用Bi-GRU结构获取深层次上下文信息,并结合事件特征和句子特征获得融合特征信息;
S7、将融合特征信息输入到分类器中,得到事件元素抽取结果。
进一步地,步骤S1中获得的句子语义为:
其中,s
计算词级别的loss函数为:
其中,L
进一步地,步骤S2中文档语义的获取:
其中,L为句数;
计算句级别的loss函数:
其中,L
进一步地,步骤S3中主题句的获取,包括:
将重点语句的多句主题句通过BERT预训练模型得到向量嵌入s
struct=[s
其中,s
进一步地,步骤S4具体包括:
将获得的句子语义、文档语义、主题语义和词表达结合,得到融合语义r
r
其中,w
基于Bi-GRU结构,得到隐藏表示
采用归一化处理,得到K维的概率向量P
计算文档集的loss函数:
其中,
进一步地,步骤S5具体包括:
采用one-hot词向量方法编码实体类型信息和事件类型信息,采用BERT预训练语言模型编码词向量,得到融合多重信息的词表示。
进一步地,步骤S6中获得融合特征信息为O=[E;S]。其中,O为最后事件元素分类器的输入,E为事件向量,S为句子动态向量。
进一步地,步骤S7具体包括:
根据获取的融合特征信息,构造分类器
采用经典的分类器输出的负对数概率作为损失函数:
其中,L为损失函数,y
本发明提供的非结构化事件抽取方法,具有以下有益效果:
本发明通过Bi-GRU结构挖掘上下文语义信息,采用词级别注意力关注句子中的事件触发词,采用句子级别注意力关注包含触发词的句子,综合关注的结果获得文档语义和主题句语义,提升了事件触发词抽取任务性能。
本发明通过结合BERT预训练模型和多重语义信息获得丰富的词表示,通过已抽取出的事件触发词和候选事件元素获得事件特征表示,然后基于注意力机制获得动态的句子向量表示,结合事件特征和句子表示进行事件元素抽取,有效提升了事件元素抽取任务性能。
附图说明
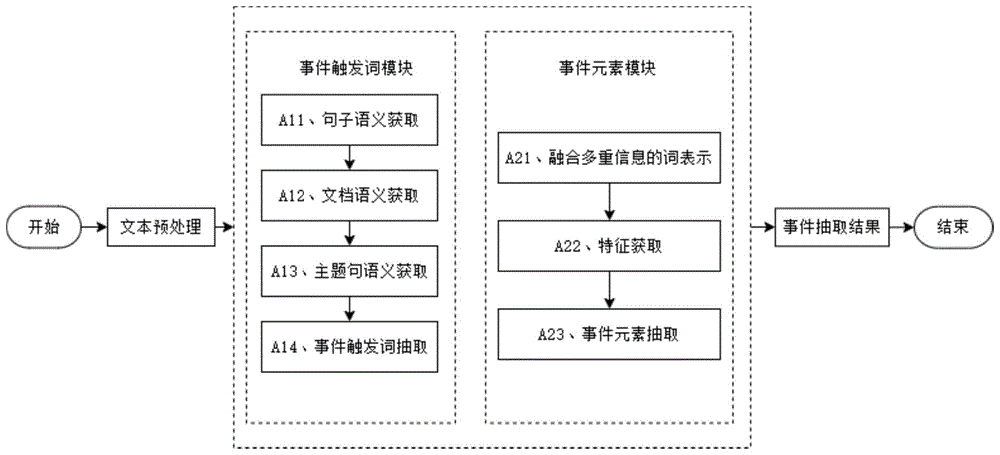
图1为非结构化事件抽取方法的流程图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
实施例1,本实施例的非结构化事件抽取方法,通过充分挖掘语言文本中的语义信息,准确、高效抽取事件触发词和事件元素从而提高事件抽取方法的效果,其具体包括:事情触发词抽取和事件元素抽取;
其中,事情触发词抽取,其包括步骤S1~步骤S4,具体如下:
步骤S1、采用嵌入方法获取输入文本的向量表示,并通过有监督的词级别注意力机制在关注事件触发词的状态下获得句子语义;
本步骤具体包括:
对于一个句子s
将获得的向量拼接输入到Bi-GRU结构中,获得深层次的语义信息;通过注意力机制让文本中的事件触发词获得更多的关注;通过结合语义表示和注意力机制获得句子表示。
步骤S2、根据有监督的句子级别注意力机制在重点关注包含事件触发词的句子的状态下获得文档语义;
本步骤具体包括:
获得了句子语义{s
步骤S3、采用文本嵌入方法获取文本中代表主题信息重点语句的主题句的向量表示;
本步骤具体包括:
选取文章标题以及第一段和最后一段第一句话作为文章主题句,主题句明显表达了文章主题信息,采用BERT预训练语言模型得到主题句语义信息。
步骤S4、将待分类的事件触发词候选词与获得的所述文档语义进行融合,并输入到分类器,得到事件触发词抽取结果;
本步骤具体包括:
将词表示、主题句表示、文档表示和实体类型信息相融合,通过Bi-GRU结构获得隐藏表示,然后进行softmax归一化处理,得到事件触发词分类结果。
事件元素抽取,其包括步骤S5~步骤S7,具体如下:
步骤S5、采用嵌入方法获得输入文本的向量表示,并获得融合事件类型信息和实体类型信息的语义增强的词表示;
本步骤具体包括:
事件类型信息和实体类型信息对于事件元素分类具有重要作用,采用one-hot词向量技术对事件类型信息和实体类型信息进行编码,获得向量表示;采用BERT预训练语言模型对文本进行编码获得向量表示,融合事件类型信息和实体类型信息得到语义增强的词表示。
步骤S6、根据获得的语义增强的词表示,采用Bi-GRU结构获取深层次上下文信息,并结合事件特征和句子特征获得融合特征信息;
本步骤具体包括:
将获取到的语义增强的词表示通过Bi-GRU结构提取到深层次上下文信息,将事件触发词和候选事件元素结合生成事件向量表示,通过注意力机制赋予单词不同的权重进而得到动态表示的句子向量,融合事件向量和句子向量得到融合特征信息。
步骤S7、将融合特征信息输入到分类器中,得到事件元素抽取结果;
本步骤具体包括:
将融合特征信息输入到事件元素分类器中,输出最后的事件元素抽取结果。
实施例2,参考图1,本实施例的非结构化事件抽取方法,将事件抽取任务分为事件触发词抽取和事件元素抽取两个子任务。首先在自然语言文本中找出代表事件类型的事件触发词,通过对文本进行嵌入获得向量表示,通过不同层次的注意力机制获得语义特征,输入到分类器中获得事件触发词抽取结果。然后进行事件元素抽取,事件元素是事件中的参与者,因此基于事件触发词抽取结果和多重语义信息构建事件元素抽取模型,获得语义特征,输入到分类器中获得事件元素抽取结果,其具体包括以下步骤;
步骤A1、事件触发词抽取:
事件触发词抽取方法分为句子语义获取、文档语义获取和主题句语义获取。最后将待分类的事件触发词候选词与获得的语义进行融合,输入到分类器中,得到事件触发词抽取结果。
本步骤具体包括以下步骤:
步骤A11、句子语义获取:
一个文档包含句子s
采用BERT预训练语言模型对单词进行编码,BERT预训练语言模型基于多个Transformer编码器采用了双向编码结构,实现了词向量的动态表示,编码丰富的语义信息。
将词向量与实体类型向量拼接起来共同作为Bi-GRU的输入x
GRU结构中左侧部分为重置门r
r
其中,W
重置门通过对r
其中,
结合之前结构输出h
z
GRU最终步骤同时进行遗忘与记忆,使用了之前计算的更新门z
为了获得更深层次的语义,在词级别特征获取和句级别特征获取以及事件抽取输出模块中均选取了Bi-GRU结构,更好地挖掘事件句中的上下文信息。
通过Bi-GRU的双向通道,当前时刻的输出就综合了正向状态和反向状态,正向GRU在当前时刻状态记为
其中,
将h
在触发词抽取任务中,触发词对句子语义的表达应该比句子中其他词语获得更多的关注,包含触发词的句子应该比文档中其他句子获得更多的关注。
将隐藏表达u
其中,T为转置;
通过对h
在一个句子中,每一个词都被赋予一个事件触发词预测注意力标准值
通过定义事件触发词预测注意力标准值希望实际计算得到的注意力值α
其中,L
步骤A12、文档语义获取;
复杂的自然语言语境中,句子层面的语义信息不足以捕捉到这类复杂的事件信息,进行文档语义的获取;
获得了句子语义{s
其中,q
将q
经过softmax函数进行归一化,计算出该句的注意力分数β
其中,T为转置;c
因此通过对s
对于含有触发词的句子应该获得更大的权重,相较于其他句子应该获得更多的关注。类似于上文定义的触发词预测注意力标准值,定义了包含触发词的句子预测注意力标准值
理想状态下,包含触发词的句子预测注意力标准值应该为1,其他句子为0;由此得到了定义句级别的loss函数:
其中,L
步骤A13、主题句语义获取;
语料文章中标题以及第一段和最后一段第一句话能够较为明显地表达文章主题信息,对于这样的主题句对文章主题信息具有重要的代表作用,因此在触发词抽取中融入文档主题信息。
分别对三句主题句通过BERT预训练模型得到向量嵌入s
struct=[s
步骤A14、事件触发词抽取输出;
完成了上述步骤之后,对于给定文档,获得了文档表达d,句子表达s
r
通过Bi-GRU,得到隐藏表示
其中,
将上述两模块联合训练,得到loss函数L如下:
其中,
步骤A2、事件元素抽取;
事件元素抽取方法主要分为融合多重信息的词表示、事件和句子特征获取和输出部分,将特征输入到事件元素分类器得到抽取结果;
其具体包括以下步骤:
步骤A21、融合多重信息的词表示;
事件元素通常是由单词表示的实体或属性,采用one-hot词向量技术编码实体类型信息和事件类型信息,采用BERT预训练语言模型编码词向量,得到融合多重信息的词表示。
步骤A22、事件和句子特征获取;
获得融合多重信息的词表示信息后,采用Bi-GRU结构来提取比融合多重信息的词表示信息更高层次的上下文信息。
将x
r
z
其中,W
重置门通过计算得到状态
GRU最后进行遗忘与记忆,得到输出h
经过Bi-GRU双向通道的计算,获得双向的特征记为:
其中,
事件元素及其角色通常依赖于触发词而存在;结合触发词和元素生成事件向量
不同的触发词会关联不同的元素,句子的语义信息能够充分包含这样的特点,因此将句子动态地表示为S:
其中,对于注意力权重α
注意力分数中每个词和事件表示的相关性e
其中,h
步骤A23、事件元素抽取输出;
得到事件句子组合特征之后,元素抽取任务需要将每个元素分类为正确的角色,分类器可以构造为
本模型使用经典的分类器输出的负对数概率作为损失函数,定义如下:
其中当识别为正确参数角色时y
综合上述事件触发词抽取和事件元素抽取结果,即可得到事件抽取结果
虽然结合附图对发明的具体实施方式进行了详细地描述,但不应理解为对本专利的保护范围的限定。在权利要求书所描述的范围内,本领域技术人员不经创造性劳动即可做出的各种修改和变形仍属本专利的保护范围。