一种Python模型分布式在线部署方法及系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于模型部署技术领域,尤其涉及一种Python模型分布式在线部署方法及系统。
背景技术
随着海量数据的累积以及AI理论技术的不断发展,机器学习和深度学习模型已经被应用到了工业、金融、零售、汽车、医疗等各种领域。Python作为当下数据分析和模型训练最常用的工具,被广泛用于各领域模型的开发。Python模型开发完成后,需要以在线部署的方式将模型应用起来。目前Python模型部署有以下两种方式,其流程见图1。
1.算法工程师使用Flask来搭建简易的web服务,web服务使用Python来加载模型,对外提供服务。
2.算法工程师将Python模型文件、模型训练逻辑以及模型调用文档交付给部署工程师,然后部署工程师将模型转化为某一特定形式,例如PMML文件等,再以Java或C++程序加载模型,并对外提供服务。
因为模型在线部署有高并发、高可用和高容错等要求,不同领域模型更新发版可能很频繁,且模型离线数据处理和特征工程也需要在在线预测时实现;所以,以上两种Python模型部署的方式,都有各自存在的缺点。
第一种算法工程师使用Flask来搭建简易的web服务的方式,首先Flask服务性能很差,不能在调用量很大时满足性能要求;其次模型在线部署对高并发、高可用和容错性有一定要求,让算法工程师来承担部署工作,效率并不高;最后离线数据处理和特征工程也需要算法工程时实现一套在线的程序,进一步加大了Python模型部署的工作量。
第二种算法工程师和部署工程师合作将模型部署上线的方式,首先算法工程师将Python模型文件、模型训练逻辑以及模型调用文档交付给部署工程师,然后部署工程师需要将离线数据处理和特征工程转化为可上线的程序以及将模型转化为可上线的形式,这样存在一定的沟通成本,而且部署工程师在将模型转化为可上线的形式时,需要保证Python模型离线训练和在线预测结果的一致性,对部署工程师的能力要求很高,所以这种方式耗时耗力且效率低下。
发明内容
本发明的目的在于针对现有技术的不足,提供一种Python模型分布式在线部署方法及系统,解决了如下技术问题:
1.如何满足任意不同类型Python模型部署上线的需求;
2.如何实现Python在线模型的高并发、高可用和容错等要求;
3.如何在不影响业务调用的情况下,实现模型版本的热更新;
4.如何让离线数据处理和特征工程也能快速地上线且保证离线和在线逻辑的一致性和数据的准确性,提高运行效率。
本发明的目的是通过以下技术方案实现的:
根据本说明书的第一方面,提供一种Python模型分布式在线部署方法,该方法包括:
通过数据处理和特征工程代码转换器,将Python模型训练前置的离线数据处理和特征工程的逻辑转换为在线Python代码;
通过模型引擎加载不同种类的Python模型;
采用分布式部署框架对Python模型进行在线部署,包括:
使用分布式文件存储系统存储用户上传的Python模型文件,使得每个模型引擎都能够加载Python模型文件;
根据并发调用量的大小和每个模型引擎能够处理的请求数量,计算当前所需的模型引擎数量;
当部署新的Python模型时,设置该模型的实例数y,根据模型引擎所在服务器资源使用情况,选中资源最充足的y个模型引擎来部署该模型。
进一步地,所述代码转换器用于用户通过界面的方式配置模型训练前置的离线数据处理和特征工程的逻辑,并将用户配置以JSON格式进行存储;读取用户配置,根据离线数据处理和特征工程的逻辑来生成相同逻辑的在线Python代码。
进一步地,所述代码转换器采用基于Jython的在线Python代码计算方式,将Python代码转换为字节码然后在JVM中运行。
进一步地,所述模型引擎用于加载不同种类的Python模型,包括:
模型文件初始化:根据用户上传的Python模型文件,将Python模型加载到内存中生成模型预测对象;
模型输入参数和模型预测结果识别:解析Python模型文件内容,转成Python对象,通过读取Python对象变量的方式识别模型输入参数和模型预测结果;
模型预测:当请求数据分发到模型引擎时,将接收的数据转换为Python模型的输入参数格式,根据入参数据调用内存中生成的模型预测对象,得到并返回模型预测结果。
进一步地,用户将Python模型封装成模型模版定义的格式,然后压缩为ZIP压缩包,再将Python模型文件压缩包上传,模型引擎解压模型文件压缩包后进行后续处理。
进一步地,所述模型引擎内置Python算法包以支持Python模型的加载,如果需要用到模型引擎内没有的算法包,用户需将算法包和模型文件一起上传。
进一步地,所述分布式部署框架将所有调用模型的请求负载均衡到每一个模型引擎,当请求并发量大时增加模型实例数,当请求并发量小时减少模型实例数。
进一步地,所述分布式部署框架将模型部署信息存储在Zookeeper上,当有模型引擎因为异常退出时,获取该异常模型引擎上存储的模型部署信息,然后根据正常模型引擎对应的服务器资源使用情况,挑选出资源最充足的模型引擎,将部署在异常模型引擎上的模型迁移到其他正常的模型引擎上;将异常模型引擎上正在处理的模型调用请求,转发到其他正常的模型引擎。
进一步地,所述分布式部署框架将模型部署信息存储在Zookeeper上,当用户更新模型版本时,依次滚动更新每一个模型引擎上的模型文件,当一个模型引擎上的模型文件在更新时,其他模型引擎上的模型还能继续使用,更新成功时,再更新下一个模型引擎上的模型文件,更新失败时会自动回滚到上一个版本的模型文件。
根据本说明书的第二方面,提供一种Python模型分布式在线部署系统,该系统基于分布式部署框架实现,该系统包括代码转换器和模型引擎;
所述代码转换器用于将Python模型训练前置的离线数据处理和特征工程的逻辑转换为在线Python代码;
所述模型引擎用于加载不同种类的Python模型;
所述分布式部署框架实现Python模型的分布式在线部署,包括:
使用分布式文件存储系统存储用户上传的Python模型文件,使得每个模型引擎都能够加载Python模型文件;
根据并发调用量的大小和每个模型引擎能够处理的请求数量,计算当前所需的模型引擎数量;
当部署新的Python模型时,设置该模型的实例数y,根据模型引擎所在服务器资源使用情况,选中资源最充足的y个模型引擎来部署该模型。
本发明的有益效果是:
1.通过本发明提供的Python模型分布式部署方法及系统,算法工程师可以快速将Python模型及前置的数据处理、特征工程等部署上线;无需部署工程师介入,从而减少了人力成本;通过将在线Python代码转换为字节码然后在JVM中运行,提高运行效率。
2.通过本发明提供的Python模型分布式部署方法及系统,Python模型可以快速部署上线,可以轻松满足高并发、高可用和容错性等要求,算法工程师只需将时间和精力花费在建模上,从而提高了模型开发效率,缩短了模型迭代周期。
附图说明
图1为现有Python模型部署流程图;
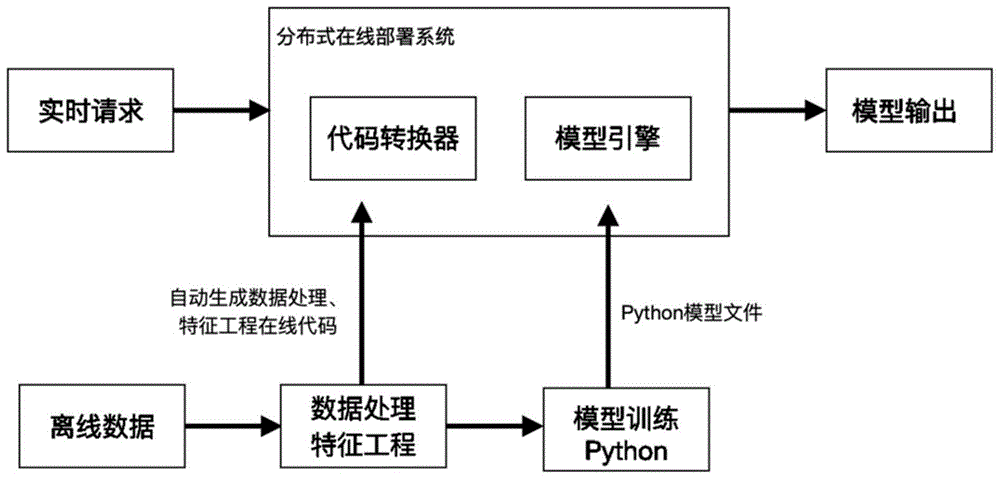
图2为一示例性实施例提供的Python模型分布式在线部署流程图;
图3为一示例性实施例提供的数据处理和特征工程代码转换器配置界面;
图4为一示例性实施例提供的分布式部署架构图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其它不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
本发明提供一种Python模型分布式在线部署方法及系统,模型部署流程图见图2,下面详细阐述本发明的技术方案和实现细节。
首先,设计并实现了一个数据处理和特征工程代码转换器,该代码转换器的关键步骤如下:
1、该代码转换器内置了常见的数学函数、时间函数、字符串函数、数组函数、正则函数以及各种常见的运算符。
2、支持让用户通过界面的方式配置模型前置的离线批量数据处理和特征工程的逻辑,然后将用户的配置以JSON格式存储在系统中,该代码转换器的配置界面见图3。
3、该代码转换器可以读取用户的配置,根据离线数据处理和特征工程的逻辑来生成相同逻辑的在线Python代码,从而保证了离线和在线数据的一致性和准确性。
4、该代码转换器提供了一个基于Jython的在线Python代码计算方式,将Python代码转换为字节码然后在JVM中运行,减少了每次运行时的代码编译时间,从而提高了在线运行的效率。
其次,设计并实现了一个可以加载任何不同种类模型的Python模型引擎,该模型引擎可以快速加载机器学习、深度学习、自然语言处理等各种不同种类的Python模型,该模型引擎实现了以下五个方法:
1、模型文件初始化;用户需要按照系统提供的模型模版,将Python模型封装成模版定义的格式,然后压缩为ZIP压缩包;再将模型文件压缩包上传到系统,该方法可以解压模型文件压缩包,然后将Python模型加载到内存中生成模型预测对象;模型引擎内置了大部分常用的Python算法包以支持Python模型的加载,如果需要用到模型引擎内没有的算法包,只需将算法包和模型文件一起上传到系统。
2、模型输入参数识别;该方法可以解析按照模型模版封装好的模型文件内容,转成Python对象,通过读取Python对象变量的方式,识别出Python模型输入参数的参数值、参数类型、参数参考值。
3、模型预测输出结果识别;该方法可以解析按照模型模版封装好的模型文件内容,转成Python对象,通过读取Python对象变量的方式,识别出Python模型输出结果的字段名、字段类型。
4、在线数据处理和特征工程计算;该方法可以根据用户在代码转换器中的配置,将离线的数据处理和特征工程逻辑转换为在线处理的Python代码,从而使离线数据处理和特征工程也能快速地上线。
5、模型预测;当请求数据分发到模型引擎时,该方法可以接收到数据,然后将其转换为Python模型的输入参数格式,根据入参数据调用内存中生成的模型预测对象,得到并返回模型预测结果。
然后,设计并实现了一个模型分布式部署框架,该框架旨在解决Python在线模型的高并发、高可用和容错性以及模型版本的热更新问题,其架构图见图4,该框架的核心功能如下所示:
1、该框架使用分布式文件存储系统HDFS来存储Python模型文件,从而使每一个模型引擎都可以加载模型文件。
2、该框架可以设置一个最小模型引擎数量x,当并发调用量较小时,只启动x个模型引擎;当并发调用量较大时,可以根据并发调用量的大小和每个模型引擎可以处理的请求数量,计算出当前所需的模型引擎数量,从而动态调整模型引擎的数量,节省服务器资源;框架会为每一个模型引擎分配一个访问地址,通过分配的地址可以调用部署在模型引擎的所有模型。一个模型引擎可以加载多个不同的模型,一个模型可以部署到多个不同的模型引擎上;当部署一个新的模型时,可以设置该模型的实例数y,框架可以根据模型引擎所在服务器资源使用情况,选中资源最充足的y个模型引擎来部署模型。
3、该框架可以将所有调用模型的请求负载均衡到每一个模型引擎,实现在线模型的高可用;当请求并发量大时,该框架会自动增加模型实例数,当请求并发量小时,该框架会自动减少模型实例数;所以该框架可以在满足高并发要求的同时,在并发小的情况下通过减少实例数来节省资源使用。
4、该框架将模型部署信息存储在Zookeeper上,所以当有模型引擎因为异常退出时,该框架获取到该异常模型引擎上存储的模型部署信息,然后根据正常模型引擎对应的服务器资源使用情况,挑选出资源最充足的模型引擎,将部署在异常模型引擎上的模型迁移到其他正常的模型引擎上;除此之外还会将异常模型引擎上正在处理的模型调用请求,转发到其他正常的模型引擎;从而保证了系统的容错性。
5、该框架还实现了模型版本的热更新;该框架将模型部署信息存储在Zookeeper上,框架可以读取该信息,记录下每个模型对应的模型引擎信息。当用户想更新模型版本时,框架会依次滚动更新每一个模型引擎上的模型文件,当一个模型引擎上的模型文件在更新时,其他模型引擎上的模型还能继续使用,更新成功时,再更新下一个模型引擎上的模型文件,更新失败时会自动回滚到上一个版本的模型文件;从而保证了在不影响业务调用的情况下,实现模型版本的热更新。
本发明提供的Python模型分布式在线部署方法及系统,能够保证在线模型的高并发、高可用和高容错;算法工程师只需要将模型文件上传到系统,系统会自动将Python模型部署上线,并提供在线调用文档,这样既可以减少人力成本,又能加快模型应用的效率。
以上所述仅是本发明的优选实施方式,虽然本发明已以较佳实施例披露如上,然而并非用以限定本发明。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何的简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。