一种社交文本分类方法、系统、计算机设备和存储介质
文献发布时间:2024-04-18 19:52:40
技术领域
本申请属于自然语言处理技术领域,具体的涉及一种基于图卷积网络的社交文本分类方法、系统、计算机设备和存储介质。
背景技术
用户标签分类是指根据用户的行为模式、发言内容、信息数据等多方面进行对用户进行标签化的处理过程。现有技术中,在用户标签的类别划分方法大致可以分为三种,一种是基于推荐算法的用户习惯分析,如利用矩阵分解、因子分解机、深度协同神经网络(Deep Cooperative Neural Network,DeepCoNN)等推荐算法,可在电商、短视频等领域构建人们的消费习惯、浏览习惯的人物画像。第二种是基于关键词提取的人物画像分析,如LDA主题词提取模型、tf-idf关键词抽取算法以及BI-lstm-attenion的深度学习词语提取模型。第三种是基于文本分类模型的用户画像构建,如利用TextCnn、TextRnn、transformer模型对用户的聊天文本打上文本标签,根据标签结果对人物进行类别划分。然而,在实际应用中,上述方案仍然存在分类不够准确等问题。
发明内容
针对上述问题,本发明第一方面提出一种基于图卷积网络的社交文本分类方法,包括步骤:获取社交文本数据,社交文本数据包括用户和用户的文本内容;对每个用户的文本内容进行计算,获得用户文本向量;以用户文本向量为节点,以用户间发送的文本内容的数量为边,构建用户关联图;基于用户关联图进行图卷积运算,获得关联文本向量;基于关联文本向量,获得用户的文本内容的分类标签。
优选地,应用训练好的BERT-attention模型获得用户文本向量。
优选地,BERT-attention模型的输入为句子集合X,句子集合X的构建包括步骤:对用户的文本内容进行初级分类;在每个分类中抽取一定数量的句子,组成句子集合X,其中,每个分类抽取的句子数量与该分类中句子数量在文本内容的所有句子数量的占比成正比。
优选地,BERT-attention模型将输入的文本内容计算为句向量,并应用自注意力机制,对句向量进行加权求和,获得用户文本向量。
优选地,用户关联图的边仅在发送的文本内容的数量大于阈值的用户之间构建。
优选地,用户的文本内容的分类标签基于关联文本向量以及用户文本向量获得。
优选地,用户的文本内容的分类标签的计算具体包括步骤:将关联文本向量和用户文本向量进行拼接,获得拼接向量;对拼接向量进行分类处理,获得用户的文本内容的分类标签。
本发明第二方面提出一种基于图卷积网络的社交文本分类系统,包括:
数据爬取模块,配置用于获取社交文本数据,社交文本数据包括用户和用户的文本内容;
文本内容分类模块,配置用于对每个用户的文本内容进行计算,获得用户文本向量;
用户关联图构建模块,配置用于以用户文本向量为节点,以用户间发送的文本内容的数量为边,构建用户关联图;
图卷积模块,配置用于基于用户关联图进行图卷积运算,获得关联文本向量;
用户画像模块,配置用于基于关联文本向量,获得用户的文本内容的分类标签。
本发明第三方面提出一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现如第一方面中任一项所述的方法。
本发明第四方面提出一种计算机可读存储介质,存储有计算机程序,计算机程序被处理器执行时实现如第一方面中任一项所述的方法。
本发明的方案以BERT、图卷积神经网络为技术基础,对社交人物在网络的社交言论的信息进行充分挖掘,并对人物进行标签划分。相对于现有的针对基于文本分类模型的用户画像标签划分技术,本方案不仅关注于人物自身的聊天文本,还从人物的整体社交内容进行信息挖掘与建模,对人物之间的关联进行量化,在建模过程中加入了与用户联系的关联用户的聊天内容信息,将其与用户本身的文本内容信息共同量化,得到了类别判断的人物画像方法,提高了社交文本分类的准确性。
附图说明
附图帮助进一步理解本申请。附图的元件不一定是相互按照比例的。为了便于描述,附图中仅示出了与有关发明相关的部分。
图1为本发明一实施例中基于图卷积网络的社交文本分类方法步骤图;
图2为本发明一实施例中基于图卷积网络的社交文本分类技术框架图;
图3为本发明一实施例中基于图卷积网络的社交文本分类模型框架图;
图4为本发明另一实施例中基于图卷积网络的社交文本分类系统框架图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅用于解释相关发明,而非对该发明的限定。
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的神经网络模型,由Google开发。它采用Transformer架构,并使用双向编码器来生成上下文相关的词向量表示。BERT能够在多项自然语言处理任务中达到最先进的性能水平,包括问答、情感分析、命名实体识别等。BERT模型的训练过程可以概括为两个阶段:预训练和微调。在预训练阶段,BERT使用海量未标注文本数据来学习通用语言表示,这些通用表示可以应用于各种自然语言处理任务。在微调阶段,BERT通过有监督学习从特定领域的标记数据中进行微调以提高其性能。
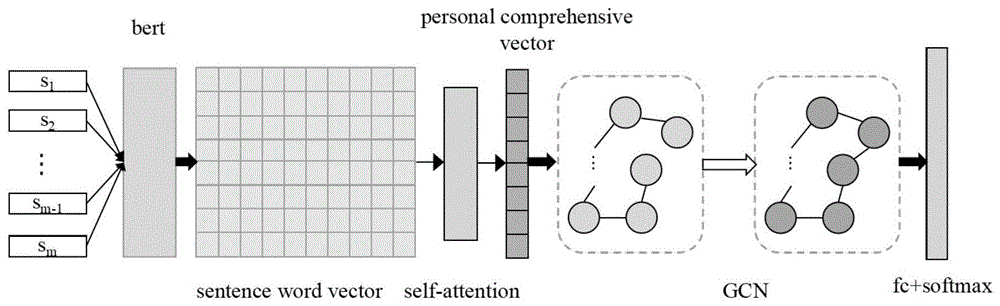
本发明的主要技术是首先利用BERT模型训练一个基类模型分类器,对聊天文本进行类别判断和句向量的转换,其次,以聊天者为单位,利用self-attention和图卷积神经网络(GCN)将自身和联系人两方面的聊天文本进行挖掘分析,最后通过挖掘分析的结果对人物打上类别标签。
图1为一具体实施例中基于图卷积网络的社交文本分类方法步骤图,图2为本实施例中基于图卷积网络的社交文本分类技术框架图。步骤具体包括:
S1,获取社交文本数据,社交文本数据包括用户和用户的文本内容。
通常,可以通过网络爬虫等方法从微博、QQ等社交软件上获取数据。具体地,本实施例中,通过网络爬虫的方法获取了群聊数据。将爬取的数据按照聊天内容和聊天者进行划分得到人员集合P={p
表1群聊数据格式示例
通常,由于聊天内容中含有部分网络语言的干扰词汇,首先需要对聊天文本进行数据清洗预处理。具体为以下步骤:一,利用正则表达式对文本中的手机号、身份证号、聊天的提示语句、网页链接等干扰文本进行过滤;二、利用收集到的表情符、词典、停用词词典对数据进行去表情符和停用词的过滤;三、利用收集的社交文本领域的专用词典作为用户词典,并利用jieba分词工具对聊天内容进行分词处理。
S2,对每个用户的文本内容进行计算,获得用户文本向量。
从预处理以后的数据集中抽取部分聊天内容形成数据集,将抽取的数据集进行数据标注。将标注好的数据集划分为训练集、测试集和验证集并进行情感分类模型的训练。本发明使用BERT模型进行基分类模型的训练,利用已经标注好的数据集训练一个文本分类模型。
本实施例中,基于BERT-attention模型进行用户文本向量的合成。用户文本向量是基于聊天者所有聊天内容量化得到的文本向量,用户文本向量的合成步骤为:
第一,使用已经训练好的BERT模型对用户的聊天内容进行文本分类的标记。
第二,设定句子抽取数量m,按照类别比例从聊天文本中抽取m条数据组成句子集合X={x
第三,利用训练的BERT分类器对输入的句子进行embedding操作得到sentence_embedding,对汇总后的句向量进行self-attention加权求和得到个人的文本向量v。具体的公式表示如下:
其中f代表BERT模型的生成函数,
S3,以用户文本向量为节点,以用户间发送的文本内容的数量为边,构建用户关联图。
社交文本是一种人与人之间交流、互动的文本形式,在社交文本中一个人的影响力不仅仅来自于自己,也来自于身边的联系人。图卷积神经网络(GCN)是一种以图的形式捕捉节点间信息的深度学习模型,本实施例中,以聊天内容为连接边,聊天者的用户文本向量为节点向量进行图卷积神经网络的建立。
构建用户关联图的具体步骤包括:以聊天者的用户文本向量为节点,以聊天者与其他聊天者发送的文本数量构建连接的边,为了减少无效边的构建,本发明设置一个阈值数m,如果用户间发送的文本数量大于m才进行边的构建。构建的邻接矩阵a
其中,n
S4,基于用户关联图进行图卷积运算,获得关联文本向量。
依据图卷积和用户对应的用户综合文本向量进行全局图卷积迭代,而在图卷积中节点的输出值也可以作为输入值进行多次迭代,本实施例使用3层图卷积进行迭代,多次对图信息的节点进行全局提取。设依存图g=(v,ε),v和ε代表节点集合和边集合,那么第k层节点i的向量输出
A
h
S5,基于关联文本向量,获得用户的文本内容的分类标签。选用合适的分类函数,对关联文本向量进行分类,可以获得分类标签。
优选实施例中,可以根据个人文本向量和关联文本向量共同得到人物的标签。图3为本实施例中模型的框架图,本实施例中,对得出的关联文本向量和个人文本向量进行拼接,利用全连接和softmax函数进行概率类别的判别。具体的函数公式如下:
x=concat(h
z=fc(dropout(x))
pred=soft max(z)
最后根据pred的概率结果进行argmax判断,将概率最大的值对应的类别作为用户的类别标签。
损失函数仍然采用交叉熵损失函数,在全连接层加入dropout函数和L1正则项系数来防止模型过拟合,损失函数的公式如下:
L=-∑y
y
图4为另一具体实施例中基于图卷积网络的社交文本分类系统400,包括:
数据爬取模块401,配置用于获取社交文本数据,社交文本数据包括用户和用户的文本内容;
文本内容分类模块402,配置用于对每个用户的文本内容进行计算,获得用户文本向量;
用户关联图构建模块403,配置用于以用户文本向量为节点,以用户间发送的文本内容的数量为边,构建用户关联图;
图卷积模块404,配置用于基于用户关联图进行图卷积运算,获得关联文本向量;
用户画像模块405,配置用于基于关联文本向量,获得用户的文本内容的分类标签。
本发明针对社交文本分类提出了一种基于Bert和GCN的人物画像分析的方法,以聊天者的文本为主要分析内容,通过句向量转化,自注意力机制等深度学习方法从聊天者自身与关联人员的社交文本内容两方面进行量化得到人物类别画像。本方法可弥补了现有技术中的分类模型对人物聊天内容挖掘不充分,没有考虑到聊天者的关联性等不足。本发明在各类终端APP的人物画像等功能方面具有广泛的应用前景。
尽管结合优选实施方案具体展示和介绍了本申请的内容,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本申请的精神和范围内,没有做出创造性劳动的情况下,在形式上和细节上对本申请做出的各种变化,均为本申请的保护范围。
- 一种含镍废水的处理系统及处理方法
- 一种高浓度含苯胺废水和含苯甲醛废水的综合预处理方法
- 一种低浓度含镍废水的协同处理方法
- 一种低浓度含强络合镍废水的处理方法