一种面向边缘智能的多神经网络实现工作流调度方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于工作流任务调度技术领域,涉及一种面向边缘智能的多神经网络实现工作流调度方法,针对边缘计算场景,提出了一种解决边缘计算中多神经网络训练任务的DeepINT方法,即通过将计算任务从边缘设备(MD)卸载到边缘节点服务器(eNB)来加速多CNN的训练任务,同时对MD的CPU和GPU动态调频,最小化系统训练时延和MD的能耗。
背景技术
人工智能(AI)技术,特别是深度神经网络(DNN),已经取得了最先进的性能,并广泛应用于各种应用领域。最近,随着高性能片上系统(SoC)的出现,在移动设备和物联网设备上运行DNN应用程序获得了极大的欢迎和关注。然而,在资源有限的终端设备上执行所有计算密集型DNN推理任务是具有挑战性的,这可能会导致无法忍受的延迟和能耗。为了缓解上述问题,边缘计算范式的出现,将计算、存储和网络资源部署到网络边缘,可以通过将部分计算任务卸载到边缘节点来加速DNN推理。
边缘设备目前能够完成CNN任务,但是,因为边缘设备具有有限的存储器、计算资源和功率处理能力,不能满足实际场景中的完成多神经网络任务、节约计算资源和减小训练时延的需求。本专利提出了一种边缘智能场景下的多神经网络任务工作流调度方法,基于元启发式优化技术粒子群优化(PSO)实现,给出了从工作流到任务执行位置、CPU频率、GPU频率的可能调度方案,以最小化边缘计算中的延迟和能耗。
发明内容
本发明的目的是针对边缘计算场景中,执行多个神经网络模型训练任务的环境下,提出一种面向边缘智能的多神经网络实现工作流调度方法。
边缘设备目前能够完成CNN任务,但是,因为边缘设备具有有限的存储器、计算资源和功率处理能力,不能满足实际场景中的完成多神经网络任务、节约计算资源和减小训练时延的需求;本发明提出了一种边缘智能场景下的多神经网络任务工作流调度方法DeepINT,基于元启发式优化技术粒子群优化(PSO)实现,给出了从工作流到任务执行位置、CPU频率、GPU频率的可能调度方案,以最小化边缘计算中的延迟和能耗;
第一方面,本发明提供一种面向边缘智能的多神经网络实现工作流调度方法,包括以下步骤:
步骤(1)、建立资源限制下的最优工作流调度模型;
步骤(2)、初始化工作流;
步骤(3)、使用粒子群算法进行优化迭代,得到最优工作流调度模型的最优解,通过比较这些最优解,获得多神经网络DNNs的最优卸载点以及CPU、GPU的最优工作频率;粒子群中的相互作用基于拓扑邻域,每个粒子
在粒子群优化的过程中,循环迭代,直到达到最大迭代次数或者适应度值达到预设阈值,输出最优粒子;在每次迭代过程中,粒子的速度和位置分别由式(1)-(2)表示为:
其中w表示为惯性权重参数;c
采用自适应策略调整前粒子空间搜索能力,根据单个神经网络DNN的网络结构和粒子的质量获取惯性权重参数w,以更加适应DNN模型的有向无环图DAG结构;根据全局最优粒子和当前粒子之间的差异来自适应地调整粒子的搜索能力,具体的计算公式如下:
其中
步骤(4)、根据步骤(3)得到的最优工作流卸载方案,从边缘设备MD上卸载部分训练任务到边缘节点服务器eNB上,并按照得到的CPU的最优工作频率、GPU的最优工作频率进行计算任务,优化多神经网络DNNs训练任务的计算时延和边缘设备MD的能耗。
第二方面,本发明提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行所述的方法。
第三方面,本发明提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的方法。
本发明的有益效果:
本发明设计了一种面向边缘智能的多神经网络计算工作流调度方法,通过将多神经网络训练任务卸载到资源充足的边缘节点,可以增强终端设备的计算能力,从而减少延迟并节省能源。另外提出自适应策略获取惯性权重参数w,以更加适应DNN模型的有向无环图DAG结构,提高神经网络DNN的搜索能力。
本发明根据边缘计算场景中,多个神经网络模型训练的复杂场景的实际需要,提供了一种时间性能刚好、边缘设备能耗更低的方案。本发明提出了DeepINT方法,这是一种将计算从边缘设备卸载到边缘节点来加速多DNN训练,同时降低系统能耗的方法。结果表明DeepINT优于现有系统,降低了联合推理延迟和能耗,提高了边缘智能场景下联合推理的可行性和效率。
附图说明
图1为MD与eNB联合计算CNNs任务的过程形成的简单工作流模型。
图2为DeepINT方法得到的工作流调度图。
图3为DeepINT方法、Server-only方法、Local-only方法MD能耗对比图。
图4为DeepINT方法、Server-only方法、Local-only方法任务计算总时延对比图。
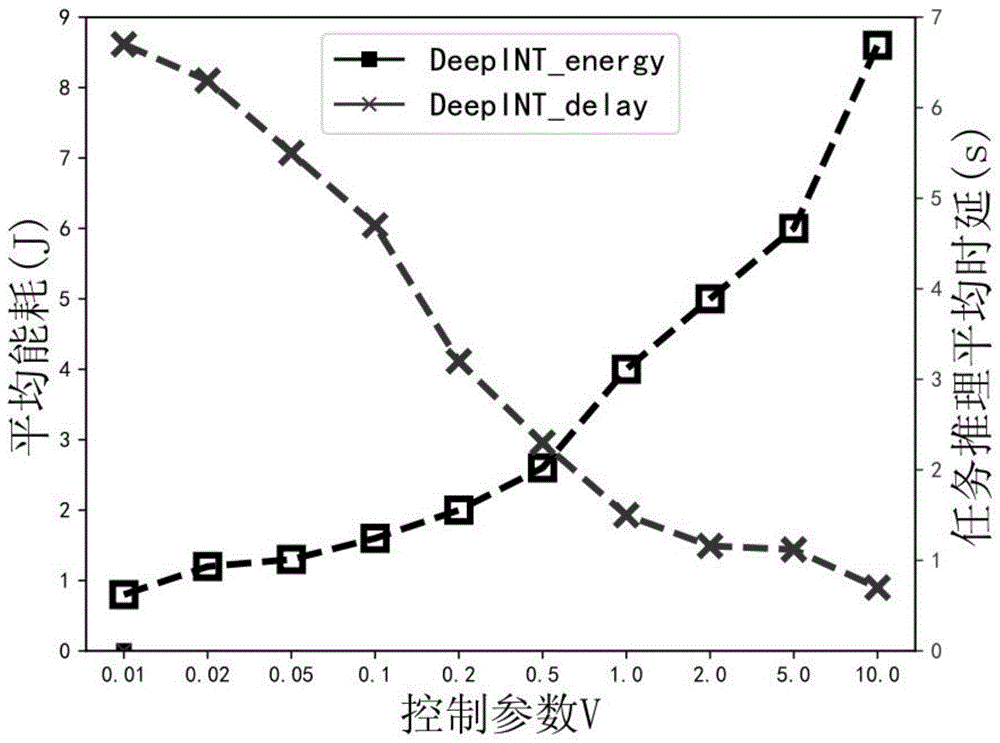
图5为DeepINT方法控制参数V与能耗、推理时延之间的关系图。
具体实施方式
下面结合附图对本发明做进一步的分析。
在边缘计算场景中进行DNNs计算任务,我们可以使用eNB来协助多个MD进行模型联合训练。eNB在地理位置上靠近多数的MD,又提供了相对可靠的短距离传输,因此在收集数据和训练模型方面可以显著降低了系统通信成本。
一种面向边缘智能的多神经网络实现工作流调度方法(DeepINT),其步骤是:
步骤(1)、建立资源限制下的最优工作流调度模型;
MD与eNB联合推理计算CNNs的过程形成的简单工作流模型如附图1所示。图中开头的空节点表示多个CNN的输入数据,尾端的空节点表示多个CNN的计算结果的集合。将模型的卷积核心Conv Kernel作为任务节点,任务节点t
1.1、构建在边缘设备和边缘节点服务器完成多神经网络DNNs训练任务的能耗模型:
1.1.1、边缘设备MD配备有高性能CPU和低性能CPU两种CPU架构,为了最小化功耗,假设所有低性能CPU内核和高性能CPU内核有相同的工作频率;这种边缘设备MD的CPU计算功率P
P
其中,α
1.1.2、不仅仅是CPU计算功率与频率有关,其计算能力也受频率的控制;因此,单核的CPU计算能力与CPU频率之间的关系由下公式表示:
c=βf
其中,c表示CPU单核的计算能力,即浮点运算,β表示CPU单个周期浮点计算值,f
C
其中,β
1.1.3、CPU的架构与GPU的架构设计差异巨大,因此边缘设备MD的GPU计算功率P
P
其中η表示能量转换效率的系数;f
边缘设备MD的GPU计算能力表示为:
c
其中γ表示为GPU单个时期内能处理的浮点计算次数;
1.1.4、边缘设备MD执行任务的时间
其中,
所以,边缘设备MD向边缘节点服务器eNB传输数据的过程中总共消耗的能耗E表示为:
其中,P
1.2、执行终端-边缘协同训练时,第k个边缘设备MDk训练多神经网络DNNs中I
1.2.1、构建边缘设备MD本地执行训练时间模型:
假设边缘设备MDk本地执行训练的计算时间
1.2.2、训练数据传输时间建模:
终端-边缘协同训练过程中需要在边缘设备MD完成本地训练后,边缘设备MD再将自身训练结果数据上传到边缘节点服务器eNB;边缘节点服务器eNB继续训练当前边缘设备MD训练剩余的I-I
因此,边缘设备MD
其中r
1.2.3、构建边缘节点服务器eNB执行训练时间模型:
边缘节点服务器eNB会为每个异构的边缘设备MD平均分配固定数量的计算资源来保证边缘设备MDs之间的公平性;因此,边缘节点服务器eNB执行训练的计算时间
其中
1.2.4、构建全模型训练时延模型:
当执行终端-边缘协同训练时,MD
其中,
1.3为实现在边缘计算场景中高效地进行多神经网络DNNs的计算任务,提高计算效率并降低能耗;因此优化问题P表示如下:
其中V表示权衡低能耗和低延时的控制参数,V∈[0.01,100];
步骤(2)、初始化工作流;
任务初始组成的工作流全部在边缘设备MD上执行任务,并为每个任务随机设置变异率mR,mR∈[0,1];
在初始化工作流时,判断是否满足当前任务的前驱任务为边缘节点服务器eNB上执行或者变异率超过阈值,若是则当前任务将被分配到边缘节点服务器eNB上执行,若否则当前任务为边缘设备MD上执行且后继任务在边缘节点服务器eNB上执行,并且该任务成为DNNs的一个任务卸载点;
目标函数式(17)是一个非线性、不可微优化问题的函数,因此采用多维编码策略解决该问题;具体是:
初始化设置工作流中粒子的数量N
本实验中使用3个参数(网络带宽r、MD的高性能CPU与低性能CPU相等大小的工作频率f、MD的GPU工作频率f
步骤(3)、使用粒子群算法进行优化迭代,得到目标函数式(17)的最优值,通过比较这些最优值,获得多神经网络DNNs的最优卸载点以及CPU、GPU的最优工作频率;粒子群中的相互作用基于拓扑邻域,每个粒子
在粒子群优化的过程中,循环迭代,直到达到最大迭代次数或者适应度值达到预设阈值,输出最优粒子;在每次迭代过程中,粒子的速度和位置分别由式(18)-(19)表示为:
其中w表示为惯性权重参数,w∈[0.4,2];c
本发明改进了传统的线性变化策略,采用自适应策略调整前粒子空间搜索能力,根据单个神经网络DNN的网络结构和粒子的质量获取惯性权重参数w,以更加适应DNN模型的有向无环图DAG结构;此方法可以根据全局最优粒子和当前粒子之间的差异来自适应地调整粒子的搜索能力;当这两者之间的差值较小时,算法会加强局部搜索的能力,以加快收敛速度并找到最优解;具体的计算公式如下:
其中
正如附图2中所示,每个任务的x
步骤(4)、根据步骤(3)得到的最优工作流卸载方案,从边缘设备MD上卸载部分训练任务到边缘节点服务器eNB上,并按照得到的CPU的最优工作频率、GPU的最优工作频率进行计算任务,优化多神经网络DNNs训练任务的计算时延和边缘设备MD的能耗。
本发明采用DeepINT方法、Server-only方法、Local-only方法对MD在能耗、系统时延两个方面进行对比。
1)对比三种方法的能耗
在实验中,我们设定网络带宽的值在10至100Mbps之间波动,并保持其它几个变量不变,将MD的CPU频率固定在1.8GHz,MD的GPU的计算能力设定为2.6GFLOPs,eNB的CPU频率设置为3.6GHz,eNB的GPU计算能力设定为4.4GFLOPs,将控制参数V设置为1。三种方法在不同网络带宽下的MD能耗对比如附图3所示,我们可以看出在带宽为10至20Mbps的区间内,相较于Local-only和Server-only方法,DeepINT方法在MD能耗方面表现优秀,带宽为10Mbps时,DeepINT方法在MD执行任务推理时的平均能耗要低于Server-only方法45%;在30至100Mbps的区间内,DeepINT方法在MD执行任务推理时的平均能耗要低于Local-only方法50%以上,而与Server-only方法的差异性较小。
2)对比三种方法的系统总时延
三种方法在不同网络带宽下的任务推理总时延对比如附图4所示,我们可以看出在带宽为10至100Mbps中,DeepINT方法的推理总时延都要优于其它两种方法,并且看出在当前实验设置参数下,DeepINT方法的具有一定的稳定性,随着带宽线性增加,任务推理总时延均成线性下降,因此该方法抗网络带宽波动的情况表现优异。而Server-only方法由于任务完整性传输机制,并且传输的初始数据量较大,该方法在带宽较小时受到网络带宽影响非常大。在网络带宽在40Mbps以上时,DeepINT方法在任务推理总时延方面比Local-only方法至少减少25%,比Server-only方法至少减少10%。
3)控制参数V的选取
比较DeepINT方法控制参数在能耗和推理时延两个方面均衡表现,如附图5所示,随着V从0.01变为10,DeepINT的能耗在逐渐增加,并且增加速度也在提升,而任务推理平均时延在逐渐下降。当V值较小时,系统注重MD的能耗问题,导致任务高时延但低能耗。相反,当V值非常大时,这表明系统强调系统的任务推理时延而不是设备能耗。这表明控制参数V确实能实现系统中MD能耗和推理时延均衡。因此,可以在实际场景中选择适当的V以满足自定义的能量消耗和延迟要求。
实验结果表明,本发明DeepINT方法的性能优异,可以大幅度减少能耗和提高系统推理时延,能够应用于大多数的现实实际场景中。并且,该方法设计了控制参数V,可以在使用场景中根据实际需要平衡能耗与时延。从以上两种性能综合看来,无论网络带宽传输速率为任意值,DeepINT方法的性能表现都要优于其它两种方法,尤其在网络大幅波动时DeepINT方法表现出优异的稳定性。
表1不同带宽下不同方法的能耗(J)
表2不同带宽下不同方法系统总时延(s)
表3不同控制参数V下,DeepINT方法的平均能耗(J)和平均时延(s)的对比
- 一种移动边缘计算环境下面向工作流的容错调度方法
- 一种移动边缘计算环境下面向工作流的容错调度方法