大坝渗流预测方法及系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明公开了一种大坝渗流预测方法及系统,具体为一种基于EEMD-GRU的大坝渗流预测方法及系统,属于大坝安全监测技术领域。
背景技术
水利工程承担着防洪排涝、引水发电、农业灌溉、城市供水等重要任务。与其他基础设施一样,大坝在服役过程中也会受到各种物理、化学等不确定性因素的影响,致使大坝出现老化、病险,甚至失效。渗流是直观反映大坝安全性态的典型效应量之一,也是大坝面临的常见问题。
利用实测数据序列预测大坝渗流,是定量分析大坝渗流安全性态的重要方法。现有技术通常采用统计模型预测大坝渗流,限于当前监测技术及分析理论制约,统计模型在拟合精度与预报能力上难以进一步提高,导致所得预测结果精度较低。
发明内容
本申请的目的在于,提供一种大坝渗流预测方法及系统,以解决现有技术中利用统计模型预测大坝渗流存在的预测精度低的技术问题。
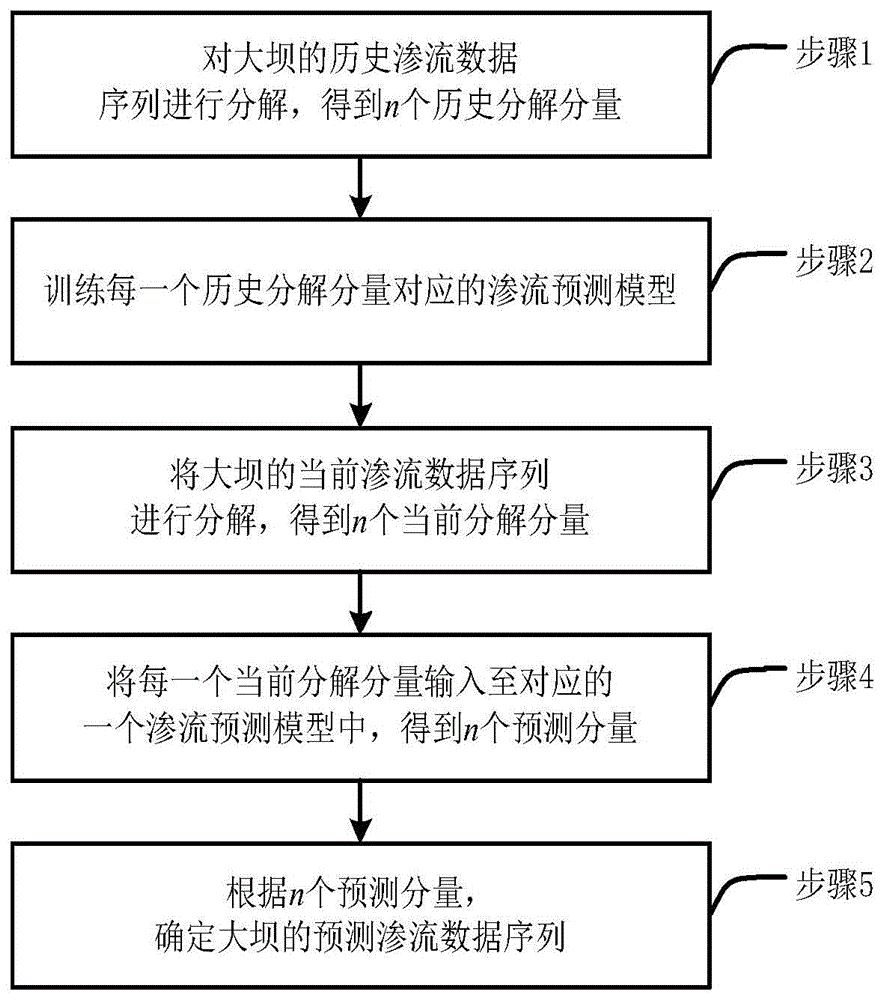
本发明的第一方面提供了一种大坝渗流预测方法,包括:
步骤1、对大坝的历史渗流数据序列进行分解,得到n个历史分解分量;
步骤2、训练每一个所述历史分解分量对应的渗流预测模型;
步骤3、将大坝的当前渗流数据序列进行分解,得到n个当前分解分量;
步骤4、将每一个当前分解分量输入至对应的一个渗流预测模型中,得到n个预测分量;
步骤5、根据所述n个预测分量,确定大坝的预测渗流数据序列。
优选地,所述步骤5具体包括:
将所述n个预测分量进行累加,得到大坝的预测渗流数据序列。
优选地,所述步骤1具体包括:
步骤1.1、将均方根相等的M个不同的白噪声序列分别加入至大坝的历史渗流数据序列中,得到M组待处理序列;
步骤1.2、对每组所述待处理序列进行分解,得到每组所述待处理序列对应的n个过程分解分量;
步骤1.3、根据每组所述待处理序列的n个过程分解分量,确定所述大坝的历史渗流数据序列对应的n个历史分解分量。
优选地,所述步骤1.3具体包括:
获取多组所述待处理序列的每一个对应过程分解分量的均值,得到所述大坝的历史渗流数据序列对应的n个历史分解分量。
优选地,所述渗流预测模型为门控循环单元神经网络模型。
优选地,所述历史渗流数据序列包括历史水压序列、历史温度序列、历史时效序列中的至少一种以及历史渗流序列。
本发明的第二方面提供了一种大坝渗流预测系统,包括:
第一分解模块,所述第一分解模块用于对大坝的历史渗流数据序列进行分解,得到n个历史分解分量;
训练模块,所述训练模块用于训练每一个所述历史分解分量对应的渗流预测模型;
第二分解模块,所述第二分解模块用于将大坝的当前渗流数据序列进行分解,得到n个当前分解分量;
第一预测模块,所述第一预测模块用于将每一个当前分解分量输入至对应的一个渗流预测模型中,得到n个预测分量;
第二预测模块,所述第二预测模块用于根据所述n个预测分量,确定大坝的预测渗流数据序列。
本发明的大坝渗流预测方法及系统,相较于现有技术,具有如下有益效果:
本发明可以挖掘非线性大坝渗流数据中的部分隐藏信息,提高计算精度。与常规模型相比,本发明提出的EEMD-GRU渗流预测模型有更好的预测效果,各项评价指标优于单一的神经网络,可以更充分发挥出人工智能算法带来的算力提高,为大坝渗流预测提供了新方法。
附图说明
图1为本发明大坝渗流预测方法的流程图;
图2为本发明大坝渗流预测系统的结构示意图;
图3中的(a)为本发明实施例中P8-11的渗流序列过程线;(b)为本发明实施例中P9-11的渗流序列过程线;(c)为本发明实施例中P10-11的渗流序列过程线;
图4是本发明实施例中训练集中P8-11渗流序列的EEMD分解结果;
图5是本发明实施例中各模型在P8-11测点的渗流预测结果;
图6是本发明实施例中各模型在P9-11测点的渗流预测结果;
图7是本发明实施例中各模型在P10-11测点的渗流预测结果。
图中,101为第一分解模块;102为训练模块;103为第二分解模块;104为第一预测模块;105为第二预测模块。
具体实施方式
以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、技术之类的具体细节,以便透彻理解本发明实施例。然而,本领域的技术人员应当清楚,在没有这些具体细节的其它实施例中也可以实现本发明。在其它情况中,省略对众所周知的系统、装置、电路以及方法的详细说明,以免不必要的细节妨碍本发明的描述。
本发明的第一方面提供了一种大坝渗流预测方法,如图1所示,包括:
步骤1、对大坝的历史渗流数据序列进行分解,得到n个历史分解分量。
本发明实施例是通过大坝安全监测系统获取的历史渗流数据序列,并对历史渗流数据序列进行剔除粗差等预处理工作以后,才对其进行的分解,分解所采用的方法为集合经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)。其中历史渗流数据序列包括历史水压序列、历史温度序列、历史时效序列中的至少一种以及历史渗流序列。
本发明实施例的步骤1具体包括:
步骤1.1、将均方根相等的M个不同的白噪声序列分别加入至大坝的历史渗流数据序列中,得到M组待处理序列。
示例性地,在大坝渗流数据序列中加入随机高斯白噪声序列n
x
式中:x(t)为大坝的历史渗流数据序列;x
利用上述方法,在大坝的历史渗流数据序列中,每次加入均方根相等的M-1个不同的白噪声序列,得到M组待处理序列。
步骤1.2、对每组待处理序列进行分解,得到每组待处理序列对应的n个过程分解分量。
示例性地,利用EMD,将每组待处理序列x
步骤1.3、根据每组待处理序列的n个过程分解分量,确定大坝的历史渗流数据序列对应的n个历史分解分量,具体包括:
获取M组待处理序列的每一个对应过程分解分量的均值,得到大坝的历史渗流数据序列对应的n个历史分解分量,示例性地:
计算M组待处理序列的每个对应IMF过程分解分量和剩余分量的均值,并将得到的IMF过程分解分量及剩余分量的均值作为EEMD最后的分解结果,表示为:
步骤2、训练每一个历史分解分量对应的渗流预测模型,得到n个渗流预测模型。
本发明实施例中,通过大坝安全监测系统获取大坝的历史渗流数据序列对应的环境量数据,根据环境量数据计算得到环境影响因子,并获取历史环境影响因子序列。由于不同环境影响因子的量纲不同,为了提高模型的预测精度,本发明实施例对得到的历史环境影响因子序列进行归一化处理。本发明实施例后续均利用归一化处理后的序列训练渗流预测模型。
示例性地,本发明实施例的环境影响因子包括水压分量P
水压分量P
P=P
其中水压分量P
温度分量与环境温度、坝体内部温度场有关,考虑到温度监测数据不连续的情况,本发明用简谐波函数表示温度分量。选择4个多周期简谐波作为温度因子:
其中t
坝前淤积、坝体裂隙等因素也会引起渗流状况的改变,因此本发明实施例选取2个时效因子:θ-θ
本发明实施例的步骤2具体包括:
步骤2.1、将一个历史分解分量输入至渗流预测模型中,训练该历史分解分量对应的渗流预测模型。
步骤2.2、重复步骤2.1,直至得到与n个历史分解分量一一对应的n个渗流预测模型。
示例性地,本发明实施例将8个水压分量、4个温度分量和2个时效分量以及历史渗流序列输入至Excel表格中组合在一起后进行分解,总共得到n个历史分解分量,然后训练每个历史分解分量对应的渗流预测模型。
本发明实施例中,使用门控循环单元神经网络模型(gated recurrent unit,GRU)作为渗流预测模型。
门控循环单元神经网络模型的工作原理为:
在t时刻,门控循环单元的输入为x
r
z
式中:r
然后再对r
式中:h′
最后计算当前时刻的隐藏层输出h
更新门的输出z
步骤3、将大坝的当前渗流数据序列进行分解,得到n个当前分解分量。
本发明实施例中当前渗流数据序列包括当前水压序列、当前温度序列、当前时效序列中的至少一种以及当前渗流序列。本发明实施例当前渗流数据序列的分解方法与历史渗流数据序列的分解方法相同,在此不再赘述,得到n个当前分解分量。
步骤4、将每一个当前分解分量输入至对应的一个渗流预测模型中,得到n个预测分量。
示例性地,将当前渗流数据序列对应的第一个当前分解分量输入至第一个历史分解分量训练的渗流预测模型中,得到1个预测分量。重复该方法,得到n个预测分量。
步骤5、根据n个预测分量,确定大坝的预测渗流数据序列。
示例性地,将n个预测分量进行累加,得到大坝的预测渗流数据序列。
循环神经网络(RNN)通过将上一时刻的神经元状态值输入当前神经元,实现了时间序列数据的挖掘。门控循环单元神经网络(GRU)在循环神经网络(Recurrent NeuralNetwork,RNN)的基础之上,通过添加门结构控制之前时刻的影响程度,解决了RNN的梯度爆炸和消失的缺陷,使得GRU能够更好地处理和挖掘时间序列。此外,由于大坝渗流数据序列具有明显的非线性、非平稳特征,且序列中不可避免地存在一定噪声。因此,挖掘隐藏信息并降低噪声,对渗流数据的准确预测有重要意义。本发明使用集合经验模态分解(EEMD)通过加入白噪声改善了经验模态分解(EMD)中的模态混叠现象,显著提高了渗流预测能力。
本发明方法利用EEMD将大坝渗流数据分解为频率不同的本征模态函数分量(IMF),获取各分量对应的GRU预测模型,最终将预测结果累加得到大坝渗流预测值,通过预测值和实测值对比可以定量监控大坝渗流的安全状态。
本发明的第二方面提供了一种大坝渗流预测系统,如图2所示,包括第一分解模块101、训练模块102、第二分解模块103、第一预测模块104和第二预测模块105。
其中,第一分解模块101用于对大坝的历史渗流数据序列进行分解,得到n个历史分解分量;
训练模块102用于训练每一个历史分解分量对应的渗流预测模型;
第二分解模块103用于将大坝的当前渗流数据序列进行分解,得到n个当前分解分量;
第一预测模块104用于将每一个当前分解分量输入至对应的一个渗流预测模型中,得到n个预测分量;
第二预测模块105用于根据n个预测分量,确定大坝的预测渗流数据序列。
下面将以更为具体的实施例详述本发明的方法。
采用本发明的大坝渗流预测方法对某水电站大坝的渗流监测数据进行预测及监控,具体包括以下步骤:
步骤1、选取11#坝段上分别位于坝体上游侧高程2229m的P8-11渗流计、高程2250m的P9-11渗流计和高程2270m的P10-11渗流计,选定自2019年1月2日至2021年3月10日的渗流计测值进行分析,P8-11、P9-11和P10-11三个测点渗流序列过程线如图3所示。
步骤2、将2019年1月2日至2020年3月10日的数据作为训练集,2020年3月11日至2021年3月10日的数据作为测试集。对训练集中的大坝渗流数据序列进行EEMD分解,以P8-11测点为例,分解结果如图4所示。历史渗流数据序列被分解为9个不同尺度的IMF历史分解分量,频率由高到低,对应的IMF图像越来越平滑。
步骤3、将IMF历史分解分量输入至渗流预测模型中,训练每个历史分解分量对应的渗流预测模型。每个渗流预测模型设置1层隐含层,隐藏单元数为64,最大迭代次数设置为120,初始学习率为0.08。
步骤4、将测试集中的渗流数据序列记为当前渗流数据序列,将当前渗流数据序列进行分解,得到9个当前分解分量,并将9个当前分解分量分别输入至各自对应的渗流预测模型中,得到9个预测渗流分量序列。
步骤5、对得到的预测渗流分量序列进行反归一化处理,并将每一项预测渗流分量序列进行累加,得到最终大坝的预测渗流数据序列。为进一步验证本发明渗流预测模型的预测性能,分别采用长短期记忆网络模型(Long Short-Term Memory,LSTM)、GRU模型、EEMD-LSTM模型对三个测点渗流数据进行实验验证对比。图5、图6、图7分别为P8-11、P9-11、P10-11三个测点的各个模型预测结果与实际渗流序列对比情况。从图中可以看出,本发明提出的EEMD-GRU渗流预测模型有更好的预测效果,各项评价指标优于单一的神经网络,可以更充分发挥出人工智能算法带来的算力提高,为大坝渗流预测提供了新方法。
本发明公开的基于EEMD-GRU的大坝渗流预测方法,主要是鉴于大坝渗流监测数据具有非线性、非平稳的特征,且数据序列包含一定噪声,导致模型预测精度不高而提出的。本发明首先利用集合经验模态分解(EEMD)将大坝渗流数据分解为频率不同的本征模态函数分量(IMF),并将各分量作为门控循环单元神经网络(GRU)模型的输入并对其预测,将预测结果累加得到最终渗流预测值。EEMD-GRU模型有效的提高了渗流预测精度,更加精确地预测了大坝渗流变化趋势,有效保证了大坝安全。
以上所述,仅是本申请的几个实施例,并非对本申请做任何形式的限制,虽然本申请以较佳实施例揭示如上,然而并非用以限制本申请,任何熟悉本专业的技术人员,在不脱离本申请技术方案的范围内,利用上述揭示的技术内容做出些许的变动或修饰均等同于等效实施案例,均属于技术方案范围内。
- 一种基于无人机检测大坝背面混凝土表面渗流系统及方法
- 一种基于无人机检测大坝背面混凝土表面渗流系统及方法