车辆排班方法和系统
文献发布时间:2024-04-18 19:58:53
技术领域
本说明书涉及数据处理领域,尤其涉及一种车辆排班方法和系统。
背景技术
公共交通是城市中人们出行的一种重要交通方式。公共交通的合理车辆排班能够保证在不同的时间段内,车辆服务的频率和数量满足乘客的需求,从而提高运输效率、减少交通拥堵、提升乘客满意度和保障安全稳定。
目前,多采用排班员手动创建时刻表和排班计划的方式来进行排班。然而,这种排班方式耗时耗力,并且由于排班员需要根据不同时间段(比如,周内和周末、不同月份一般期望基于客流规律采用不同的发车计划)对时刻表和排班计划进行周期性调整,因此,对于车辆排班的排班效率提出了更高的要求。综上,需要提供一种新的车辆排班方法和系统,能够提升排班效率。
背景技术部分的内容仅仅是发明人个人所知晓的信息,并不代表上述信息在本公开申请日之前已经进入公共领域,也不代表其可以成为本公开的现有技术。
发明内容
本说明书提供一种车辆排班效率更高的车辆排班方法和系统。
第一方面,本说明书提供一种车辆排班方法,包括:获得待排班线路的排班所需数据,所述待排班线路对应多个车辆,每个所述车辆对应至少一个车次;基于各个所述车辆对应的车次,通过发车概率预测模型确定多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率;所述发车概率预测模型为预先训练的机器学习模型;基于每个发车时刻变量下的各个车次的发车概率和所述排班所需数据,确定排班结果,所述排班结果包括多个发车时刻以及所述车次与所述发车时刻之间的对应关系;以及输出所述排班结果。
在一些实施例中,所述基于各个所述车辆对应的车次,通过发车概率预测模型确定多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率,包括:基于各个所述车辆对应的车次,以及各个所述车辆对应的车次之间的关联关系生成图结构数据;以及将所述图结构数据输入所述发车概率预测模型,确定多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率。
在一些实施例中,所述基于各个所述车辆对应的车次,以及各个所述车辆对应的车次之间的关联关系生成图结构数据,包括:以各个所述车辆中对应的车次中每个车次为节点,并基于各个所述车辆对应的车次之间的关联关系将所述节点进行连接,得到所述图结构数据,所述节点采用特征属性数据进行表示;其中,所述图结构数据包括多行节点,每行节点对应所述多个车辆中的一个车辆的车次。
在一些实施例中,各个所述车辆对应的车次之间的关联关系包括相同班型中发车时刻变量之间的关联关系,以及不同班型中首班发车时刻变量和末班发车时刻变量之间的关联关系。
在一些实施例中,所述相同班型是指营运条件相同的车辆,所述不同班型是指营运条件不同的车辆。
在一些实施例中,所述发车概率模型为预设图神经网络,所述将所述图结构数据输入所述发车概率预测模型,确定多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率,包括:采用所述预设图神经网络对所述图结构数据进行至少一次特征提取,得到目标图结构数据;以及基于所述目标图结构数据预测各个发车时刻变量的候选发车顺序的概率分布结果。
在一些实施例中,所述发车概率预测模型的训练数据包括多个排班计划及每个排班计划对应的真实发车顺序,训练目标包括约束发车概率预测模型输出的预测发车顺序与真实发车顺序之间的差异小于预设差异。
在一些实施例中,所述图结构数据中每个节点对应有特征属性数据,所述特征属性数据包括如下至少一项:每个节点对应的车辆的车次数量;每个节点对应的车次的最大工作时长;每个节点对应的车次的最小累积单程时长和最大累积单程时长;发车方向;每个节点对应的车辆的车次编号;每个节点对应的发车时刻变量的取值范围;每个节点对应的发车顺序;发车间隔的取值范围。
在一些实施例中,所述待排班线路对应有上行方向和下行方向,以及所述多个车次包括上行车次和下行车次,每个车辆对应的多个车次中所述上行车次和所述下行车次交替出现。
在一些实施例中,所述基于每个发车时刻变量下的各个车次的发车概率和所述排班所需数据,确定排班结果,包括:基于每个发车时刻变量下的各个车次的发车概率,确定多个发车时刻变量中每个发车时刻变量下发车概率小于预设概率阈值的目标车次;以及基于所述目标车次和所述排班所需数据,对所述多个发车时刻变量对应的多个发车时刻与所述对应关系进行联合求解,得到所述排班结果。
在一些实施例中,所述基于所述目标车次和所述排班所需数据,对所述多个发车时刻变量对应的多个发车时刻与所述对应关系进行联合求解,得到所述排班结果,包括:基于所述目标车次,确定待求解的排序矩阵中与所述目标车次对应位置的元素取值为预设值,得到待求解的目标排序矩阵,所述排序矩阵用于约束所述联合求解时所述多个车次中上行车次的发车时刻和下行车次的发车时刻分别为有序序列;以及采用预设排班模型基于所述目标排序矩阵和所述排班所需数据,对所述多个发车时刻变量对应的多个发车时刻与所述对应关系进行联合求解,得到排班结果。
在一些实施例中,所述采用预设排班模型基于所述目标排序矩阵和所述排班所需数据,对所述多个发车时刻变量对应的多个发车时刻与所述对应关系进行联合求解,得到排班结果,包括:基于所述目标排序矩阵和所述多个车次中所述上行车次的发车时刻及所述下行车次的发车时刻,确定目标函数,所述目标函数以所述多个车辆对应的各个车次的发车时刻作为未知量;基于所述排班所需数据生成所述目标函数的排班约束条件;以及基于所述排班所需数据和所述排班约束条件对所述目标函数进行所述多个发车时刻变量对应的多个发车时刻与所述对应关系的联合求解,得到所述排班结果。
在一些实施例中,所述基于所述目标排序矩阵和所述多个车次中所述上行车次的发车时刻及所述下行车次的发车时刻,确定目标函数,包括:基于所述目标排序矩阵和所述多个车次中所述上行车次的发车时刻的乘积,得到上行发车时刻向量,并基于所述上行发车时刻向量确定上行发车间隔向量;基于所述目标排序矩阵和所述多个车次中所述下行车次的发车时刻的乘积,得到下行发车时刻向量,并基于所述下行发车时刻向量确定下行发车间隔向量;以及基于所述上行发车间隔向量和所述下行发车间隔向量,确定所述目标函数。
在一些实施例中,所述目标函数以最大化所述排班结果对应的发车间隔的平滑度为排班目标。
在一些实施例中,所述基于所述排班所需数据和所述排班约束条件对所述目标函数进行所述多个发车时刻变量对应的多个发车时刻与所述对应关系的联合求解,得到所述排班结果,包括:在所述排班约束条件下,采用整数规划算法对所述目标函数进行所述多个发车时刻变量对应的多个发车时刻与所述对应关系进行联合求解,得到所述排班结果。
在一些实施例中,所述排班约束条件包括下述中的至少一项:所述上行车次的发车时刻不早于所述上行首班发车时刻,且不晚于所述上行末班发车时刻;所述下行车次的发车时刻不早于所述下行首班发车时刻,且不晚于所述下行末班发车时刻;相邻两个车次之间的发车间隔不超过所述最大发车间隔;每个车辆的第j+1个车次的发车时刻不早于第j个车次的到达时刻,j为正整数;每个车辆的总工作时长不超过所述单日最大工作时长;在所述高峰时段内的相邻两个车次之间的发车间隔不超过所述高峰时段内的发车间隔上限;每个车辆的午休时段位于所述午休时间范围内,且所述午休时段位于相邻两个车次之间;以及每个车辆的晚餐时段位于所述晚餐时间范围内,且所述晚餐时段位于相邻两个车次之间。
在一些实施例中,所述排班所需数据包括下述中的至少一项:所述多个车辆中从上行始发的车辆数和从下行始发的车辆数;所述待排班线路对应的上行首班发车时刻、上行末班发车时刻、下行首班发车时刻、下行末班发车时刻;所述待排班线路对应的最大发车间隔;所述待排班线路对应的单程时长;所述待排班线路对应的高峰时段、以及所述高峰时段内的发车间隔上限;所述多个车辆中每个车辆对应的目标车次数量和单日最大工作时长;午休时间范围和午休时长;以及晚餐时间范围和晚餐时长。
第二方面,本说明书还提供一种车辆排班系统,包括:至少一个存储介质,存储有至少一个指令集,用于进行车辆排班;以及至少一个处理器,同所述至少一个存储介质通信连接,其中,当所述车辆排班系统运行时,所述至少一个处理器读取所述至少一个指令集,并且根据所述至少一个指令集的指示执行本说明书第一方面所述的车辆排班方法。
由以上技术方案可知,本说明书提供的车辆排班方法和系统,该方案在获得待排班线路的排班所需数据之后,基于参与待排班线路的排班过程的多个车辆对应的车次,通过预先训练的发车概率模型对发车时刻表中多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率进行预测,并基于预测结果和排班所需数据进行车辆排班,以对多个发车时刻以及所述车次与所述发车时刻之间的对应关系进行求解,获得排班结果。该方案中,由于预测的多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率与待求解的未知量之间具有对应关系,因此,通过每个发车时刻变量下的各个车次的发车概率能够确定待求解的未知量中部分变量的取值,从而减少待求解的未知量,提高计算效率,进而提高排班效率。
本说明书提供的车辆排班方法和系统的其他功能将在以下说明中部分列出。根据描述,以下数字和示例介绍的内容将对那些本领域的普通技术人员显而易见。本说明书提供的车辆排班方法和系统的创造性方面可以通过实践或使用下面详细示例中所述的方法、装置和组合得到充分解释。
附图说明
为了更清楚地说明本说明书实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示出了根据本说明书的实施例提供的车辆排班场景示意图;
图2示出了根据本说明书的实施例提供的一种计算设备600的硬件结构图;
图3示出了根据本说明书的实施例提供的一种车辆排班方法P100的流程图;
图4示出了根据本说明书的实施例提供的车辆排班过程的示意图;
图5示出了根据本说明书的实施例提供的发车概率预测过程的流程图;
图6示出了根据本说明书的实施例提供的图结构数据的示意图;
图7示出了根据本说明书的实施例提供的基于发车概率确定排班过程的流程图;以及
图8示出了根据本说明书的实施例提供的车辆排班的流程图;
图9示出了根据本说明书的实施例提供的排班结果的图表展示示意图;
图10示出了图9所示排班结果对应的上行发车间隔曲线的示意图;以及
图11示出了图9所示排班结果对应的下行发车间隔曲线的示意图。
具体实施方式
以下描述提供了本说明书的特定应用场景和要求,目的是使本领域技术人员能够制造和使用本说明书中的内容。对于本领域技术人员来说,对所公开的实施例的各种局部修改是显而易见的,并且在不脱离本说明书的精神和范围的情况下,可以将这里定义的一般原理应用于其他实施例和应用。因此,本说明书不限于所示的实施例,而是与权利要求一致的最宽范围。
这里使用的术语仅用于描述特定示例实施例的目的,而不是限制性的。比如,除非上下文另有明确说明,这里所使用的,单数形式“一”,“一个”和“该”也可以包括复数形式。当在本说明书中使用时,术语“包括”、“包含”和/或“含有”意思是指所关联的整数,步骤、操作、元素和/或组件存在,但不排除一个或多个其他特征、整数、步骤、操作、元素、组件和/或组的存在或在该系统/方法中可以添加其他特征、整数、步骤、操作、元素、组件和/或组。
考虑到以下描述,本说明书的这些特征和其他特征、以及结构的相关元件的操作和功能、以及部件的组合和制造的经济性可以得到明显提高。参考附图,所有这些形成本说明书的一部分。然而,应该清楚地理解,附图仅用于说明和描述的目的,并不旨在限制本说明书的范围。还应理解,附图未按比例绘制。
本说明书中使用的流程图示出了根据本说明书中的一些实施例的系统实现的操作。应该清楚地理解,流程图的操作可以不按顺序实现。相反,操作可以以反转顺序或同时实现。此外,可以向流程图添加一个或多个其他操作。可以从流程图中移除一个或多个操作。
为了方便描述,首先对本说明书中出现的相关术语进行如下解释:
交通线路:是指车辆按照一定的路线和站点规划,定期运营的公共交通线路。交通线路通常包括起始站点(以下将简称为起点)、途经站点和终止站点(以下将简称为终点),沿途的站点之间会有固定的距离和停靠时间。车辆从起点出发沿着交通线路行驶,并在沿途站点或终点停靠供乘客上车或下车,从而将乘客运输至目的地。一条交通线路可以对应有两个行驶方向,分别称为上行方向和下行方向。举例来说,假设起点为站点A,终点为站点B,则车辆从站点A向站点B行驶的方向可以称为上行方向,从站点B向站点A行驶的方向可以称为下行方向。
发车时刻表:对于一条交通线路而言,通常在始发站点会按照一定时间间隔进行多次发车。其中,每次发车称为一个车次。这样,在始发站点发车的所有车次的发车时刻组成发车时刻表。也就是说,发车时刻表对应于在始发站点发车的所有车次的发车时刻的序列。举例而言,假设某个交通线路从早上6:00开始直至晚上22:30,每隔10分钟发出一个车次,则该交通线路的发车时刻表可以表示为:{6:00,6:10,6:20,…,22:20,22:30}。发车时刻表中所有发车时刻的数量对应于从始发站点发出的所有车次的数量(即车次数)。通常,一条交通线路的上行方向和下行方向分别对应一个发车时刻表。其中,上行方向和下行方向对应的发车时刻表可以相同也可以不同。
排班计划:可以是指一条交通线路对应的车辆发车计划。排班计划至少包括每个车辆分别在哪些时刻发车,或者说,排班计划至少包括每个车辆对应的完整的车次链(车次序列)。
整数规划:整数规划是指规划中的全部变量或者部分变量被限制为整数。整数规划属于一种优化问题,其目标是在满足部分或全部变量为整数以及一定约束条件下,在一组变量中找到可行解,使得目标函数取得最小值或最大值。当目标函数和约束条件均为线性表达式时,整数规划可以被称为整数线性规划。整数线性规划是所有整数规划问题中容易求解的一类问题。
神经网络:是一种模仿生物神经网络(动物的)中枢神经系统,特别是大脑的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。
图(graph):是一种抽象数据类型,用于实现数学中图论的无向图和有向图的概念。图的数据结构包含一个有限(可能是可变的)的集合作为节点集合,以及一个无序对(对应无向图)或有序对(对应有向图)的集合作为边(有向图中也称作弧)的集合。
图神经网络:使用神经网络来学习图结构数据,提取和发掘图结构数据中的特征和模式,满足聚类、分类、预测、分割、生成等图学习任务需求的算法总称。
在公共交通运营场景下,合理的车辆排班是确保其正常运营的关键因素之一。合理的车辆排班可以提高公交车运营效率和服务质量,缓解城市交通压力,并且也可以减轻公交车司机的工作负荷,避免疲劳驾驶,从而保障乘客的出行安全。因此,制定合理的排班计划极为重要。
相关技术中,通常由排班员手动进行车辆排班。而合理的排班计划需要依赖丰富的人工经验来获得,这使得车辆排班的效果受限于人工经验的丰富程度。对于一些经验欠缺的排班员来说,其编排的车辆排班计划的合理性也会较差。而对于经验丰富的排班员来说,通常也需要花费一两天的时间才能编制出一个排班计划,这样很耗时耗力,导致排班员可能在未来很长一段时间内都不想对此排班计划进行改动。但是在不同的时间段,比如周内和周末,不同月份(出行旺季和出行淡季)下,客流量有着较大差异,如果采用统一的排班计划,就会出现客流量较小时,采用较小的发车间隔,导致车辆空载的情况出现,从而导致公交运力资源的浪费,而在客流量较大时,采用较大的发车间隔,又会导致乘客等车时间较长且车内乘客较多,公交车变得较为拥挤,给乘客带来不好的乘车体验。
在一些实施例中,为了提高车辆排班效率,可以采用预设排班模型将排班过程中需要求解的时刻表和车辆与车次之间的对应关系(排班计划)进行联合求解。在该方案中,需要确定待求解的核心决策变量和排班目标,并基于所获取的排班所需数据确定排班约束条件,进而在排班约束条件下对目标函数进行联合求解,从而获得在排班约束条件下满足排班目标的时刻表和车次与发车时刻之间的对应关系,即排班结果。
其中,核心决策变量是预设排班模型的核心部分,其表示模型中需要优化的变量。核心决策变量可以为排班计划中的每个车次(T
T
其中,x
所有车辆对应的上行车次的发车时刻的集合可以记为
将集合
之后,利用上行排序矩阵
进一步的,可以对上行发车时刻向量
其中,
同样地,也可以得到下行车次对应的向量
在确定核心决策变量之后,便可以以最大化发车间隔平滑度作为排班目标生成目标函数,并对目标函数中需要求解的变量进行联合求解,从而得到上行发车时刻向量
可以看到,上述联合求解过程中需要求解的上行排序矩阵和下行排序矩阵的计算复杂度较高,导致计算效率较低,进而影响排班效率。
为了进一步提高排班效率,本说明书实施例提供了一种新的排班方法和系统,通过对多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率进行预测,并基于预测结果进行车辆排班,从而提高车辆排班效率。
需要说明的是,上述公交运营场景只是本说明书实施例适用的多个使用场景中的一个,本说明书实施例提供的车辆排班方法及系统不仅可应用于公交运营场景,还可以应用于需要对车辆进行排班的所有场景,比如客运场景、货运场景、轨道交通运营场景等等。在本说明书实施例中,车辆包括但不限于:公交车、客车、货车、高铁、地铁等。
图1示出了根据本说明书的实施例提供的车辆排班场景示意图。车辆排班场景001可以是任意需要进行车辆排班的场景,比如,公交运营场景、客运场景、货运场景、轨道交通运营场景等。如图1所示,车辆排班场景001可以包括目标用户100、客户端200、服务器300以及网络400。
目标用户100可以为触发车辆排班的用户,目标用户100可以在客户端200进行车辆排班的触发操作。通常,目标用户100可以是交通运营单位的排班人员。
客户端200可以为响应于目标用户100的触发操作而执行车辆排班任务的设备。在一些实施例中,客户端200可以包括移动设备、平板电脑、笔记本电脑、机动车辆的内置设备或类似内容,或其任意组合。在一些实施例中,所述移动设备可包括智能家居设备、智能移动设备、虚拟现实设备、增强现实设备或类似设备,或其任意组合。在一些实施例中,所述智能家居装置可包括智能电视、台式电脑等,或任意组合。在一些实施例中,所述智能移动设备可包括智能手机、个人数字辅助、游戏设备、导航设备等,或其任意组合。在一些实施例中,所述虚拟现实设备或增强现实设备可能包括虚拟现实头盔、虚拟现实眼镜、虚拟现实手柄、增强现实头盔、增强现实眼镜、增强现实手柄或类似内容,或其中的任何组合。例如,所述虚拟现实设备或所述增强现实设备可能包括智能眼镜、头戴式显示器、VR等。在一些实施例中,所述机动车中的内置装置可包括车载计算机、车载电视等。
在一些实施例中,本说明书后文描述的车辆排班方法可以在客户端200上执行。此时,客户端200可以存储有执行所述车辆排班方法的数据或指令,并可以执行或用于执行所述数据或指令。在一些实施例中,客户端200可以包括具有数据信息处理功能的硬件设备和驱动该硬件设备工作所需必要的程序。
在一些实施例中,客户端200可以安装有一个或多个应用程序(APP)。所述APP能够为目标用户100提供通过网络400同外界交互的能力以及界面。所述APP包括但不限于:网页浏览器类APP程序、搜索类APP程序、聊天类APP程序、购物类APP程序、视频类APP程序、理财类APP程序、即时通信工具、邮箱客户端、社交平台软件等等。在一些实施例中,客户端200上可以安装有目标APP。在一些实施例中,所述目标用户100可以通过所述目标APP触发车辆排班请求。所述目标APP可以响应于所述车辆排班请求,执行本说明书后文描述的车辆排班方法。
在一些实施例中,如图1所示,客户端200可以与服务器300通信连接。服务器300可以是提供各种服务的服务器,例如对客户端200提供车辆排班服务的后台服务器。客户端200和服务器300可以部署在一个实体设备上,也可以分别部署在不同的实体设备上。在一些实施例中,客户端200可以通过网络400与服务器300交互,以接收或发送消息等。比如,客户端200可以向服务器300发送排班所需数据。服务器300可以与多个客户端200通信连接,并分别接收每个客户端200发送的数据。
在一些实施例中,本说明书后文描述的车辆排班方法也可以在服务器300上执行。此时,服务器300可以存储有执行所述车辆排班方法的数据或指令,并可以执行或用于执行所述数据或指令。在一些实施例中,服务器300可以包括具有数据信息处理功能的硬件设备和驱动该硬件设备工作所需必要的程序。
网络400是用以在客户端200和服务器300之间提供通信连接的介质。网络400可以促进信息或数据的交换。如图1所示,客户端200和服务器300可以通过网络400连接,并且通过网络400互相传输信息或数据。在一些实施例中,网络400可以是任何类型的有线或无线网络,也可以是其组合。比如,网络400可以包括电缆网络,有线网络、光纤网络、电信通信网络、内联网、互联网、局域网(LAN)、广域网(WAN)、无线局域网(WLAN)、大都市市区网(MAN)、广域网(WAN)、公用电话交换网(PSTN)、蓝牙网络、ZigBee网络、近场通信(NFC)网络或类似网络。在一些实施例中,网络400可以包括一个或多个网络接入点。例如,网络400可以包括有线或无线网络接入点,如基站或互联网交换点,通过该接入点,客户端200和服务器300的一个或多个组件可以连接到网络400以交换数据或信息。
应该理解,图1中的客户端200、服务器300和网络400的数目仅仅是示意性的。根据实现需要,可以具有任意数目的客户端200、服务器300和网络400。
需要说明的是,本说明书后文描述的车辆排班方法可以完全在客户端200上执行,也可以完全在服务器300上执行,还可以部分在客户端200上执行部分在服务器300上执行。
图2示出了根据本说明书的实施例提供的一种计算设备的硬件结构图。计算设备600可以执行本说明书后文描述的车辆排班方法。计算设备600可以作为客户端200或服务器300。
如图2所示,计算设备600可以包括至少一个存储介质630和至少一个处理器620。在一些实施例中,计算设备600还可以包括通信端口650和内部通信总线610。在一些实施例中,计算设备600还可以包括I/O组件660。
内部通信总线610可以连接不同的系统组件。例如,存储介质630、处理器620、通信端口650、以及I/O组件660均可以同内部通信总线610连接。
I/O组件660支持计算设备600和其他组件之间的输入/输出。
通信端口650用于计算设备600同外界的数据通信。比如,通信端口650可以用于计算设备600同网络400之间的数据通信。通信端口650可以是有线通信端口也可以是无线通信端口。
存储介质630可以包括数据存储装置。所述数据存储装置可以是非暂时性存储介质,也可以是暂时性存储介质。比如,所述数据存储装置可以包括磁盘632、只读存储介质(ROM)634或随机存取存储介质(RAM)636中的一种或多种。存储介质630还包括存储在所述数据存储装置中的至少一个指令集。所述指令集可以包括计算机程序代码,所述计算机程序代码可以包括用于执行本说明书后文描述的车辆排班方法的程序、例程、对象、组件、数据结构、过程、模块等等。
处理器620用以执行上述至少一个指令集。当计算设备600运行时,处理器620读取所述至少一个指令集,并且根据所述至少一个指令集的指示执行所述车辆排班方法。处理器620可以执行所述车辆排班方法的所有步骤或者部分步骤。处理器620可以是一个或多个处理器的形式。在一些实施例中,处理器620可以包括一个或多个硬件处理器,例如微控制器,微处理器,精简指令集计算机(RISC),专用集成电路(ASIC),特定于应用的指令集处理器(ASIP),中心处理单元(CPU),图形处理单元(GPU),物理处理单元(PPU),微控制器单元,数字信号处理器(DSP),现场可编程门阵列(FPGA),高级RISC机器(ARM),可编程逻辑器件(PLD),能够执行一个或多个功能的任何电路或处理器等,或其任何组合。仅仅为了说明问题,在本说明书中计算设备600中仅描述了一个处理器620。然而,应当注意,计算设备600还可以包括多个处理器,因此,本说明书中披露的操作和/或方法步骤可以由一个处理器执行,也可以由多个处理器联合执行。例如,如果在本说明书中描述处理器620执行步骤A和步骤B,则应该理解,步骤A和步骤B也可以由两个不同处理器620联合或分开执行(例如,第一处理器执行步骤A,第二处理器执行步骤B,或者第一和第二处理器共同执行步骤A和B)。
本说明书的实施例还提供一种车辆排班系统。所述车辆排班系统可以包括如图2所示的计算设备600。
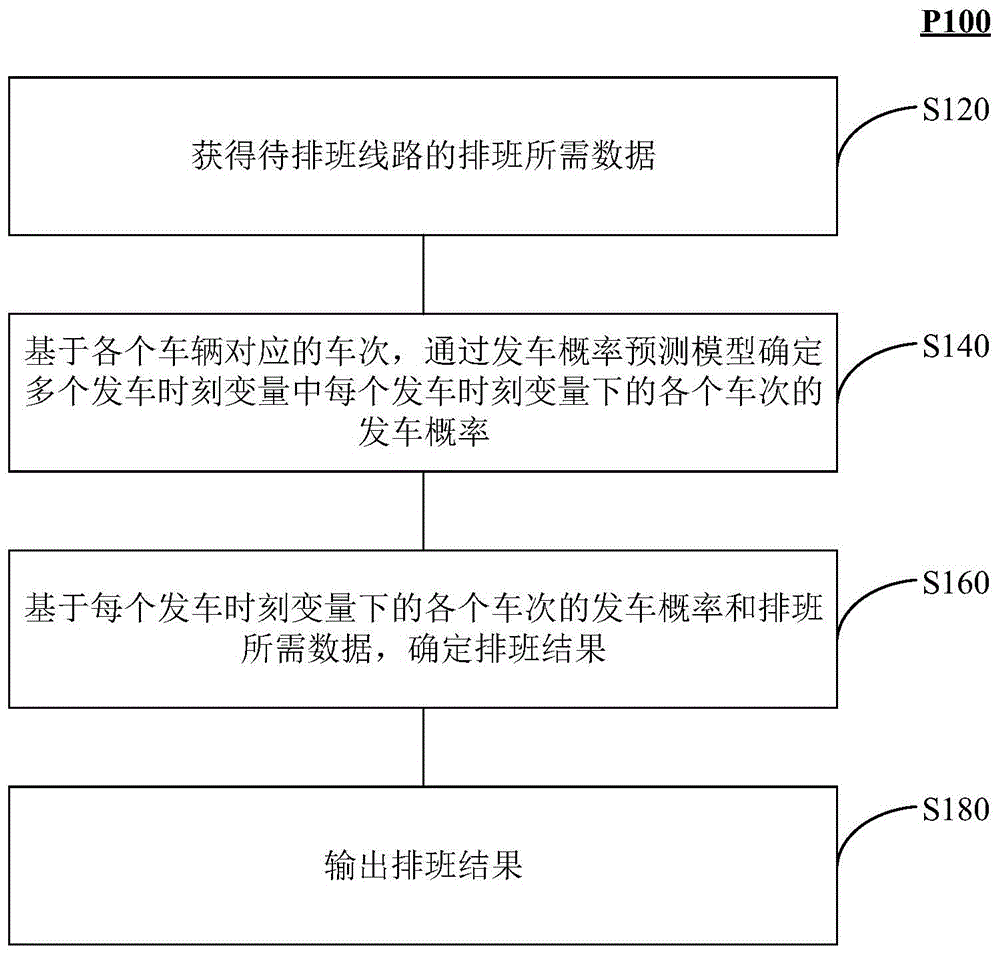
图3示出了根据本说明书的实施例提供的一种车辆排班方法P100的流程图。如前,计算设备600可以执行本说明书的车辆排班方法P100。具体地,计算设备600可以读取存储在其本地存储介质中的指令集,然后根据指令集的规定,执行本说明书的车辆排班方法P100。如图3所示,车辆排班方法P100可以包括:
S120:获得待排班线路的排班所需数据。
其中,待排班线路是指待进行车辆排班的目标交通线路。待排班线路可以对应多个车辆,每个车辆对应至少一个车次。
待排班线路对应的多个车辆是指可以参与目标交通线路的排班过程,并且在完成排班的目标交通线路上行驶的车辆。待排班线路对应有上行方向和下行方向。关于上行方向和下行方向的定义可以参见前述术语解释部分的介绍,此处不再赘述。
多个车辆中每个车辆可以对应至少一个车次。该至少一个车次是指在排班计划中,每辆车每天参与几个车次,其可以按照车辆运营公司的排班员的要求预先设定好,即每辆车对应的车次数是预先设定的常量。多个车辆对应的车次数取值可以完全相同,或者完全不同,或者部分相同。
每个车辆对应的多个车次可以对应多个发车时刻变量。其中,多个车次中的每个车次可以分别对应一个发车时刻变量,该发车时刻变量的取值为未知量。也就是说,每个车次会对应有一个发车时刻,但该车次对应的发车时刻具体是哪个时刻是不知道的。即每个车次对应的发车时刻是未知的,需要经过车辆排班方法P100得到。
多个车辆中每个车辆对应的至少一个车次可以包括上行车次和下行车次。上行车次是指多个车次中沿着上行方向行驶的车次。下行车次是指多个车次中沿着下行方向行驶的车次。在至少一个车次包括一个车次的情况下,该车次可以是上行车次,也可以是下行车次。在至少一个车次包括多个车次的情况下,该多个车次中上行车次和下行车次交替出现。也就是说,每个车辆沿着待排班线路首先行驶一个上行车次,再行驶一个下行车次,接下来再依次行驶一个上行车次和一个下行车次,如此反复,直至多个车次全部行驶完成。或者,每个车辆沿着待排班线路首先行驶一个下行车次,再行驶一个上行车次,接下来再依次行驶一个下行车次和一个上行车次,如此反复,直至多个车次全部行驶完成。
为了便于理解,下面结合图4对上述介绍的发车时刻、车辆、车次进行说明:
图4示出了根据本说明书的实施例提供的车辆排班过程的示意图。假设待排班线路的上行方向为从站点A至站点B,下行方向为从站点B到站点A。如图4所示,该待排班线路对应的排班结果可以包括发车时刻表(即多个车辆对应的所有车次的发车时刻)、以及排班计划(即多个车辆对应的车次与发车时刻之间的对应关系)。
继续参见图4,发车时刻表可以包括上行时刻表和下行时刻表。其中,上行时刻表中包括p个上行车次(从站点A出发的车次)的发车时刻。图4中将s个上行车次分别记为:T_u1、T_u2、T_u3、…、T_us,上述s个上行车次的发车时刻分别为:6:00、6:10、6:20、6:30、…、22:30。下行时刻表中包括q个下行车次(从站点B出发的车次)的发车时刻。图4中将q个下行车次分别记为:T_d1、T_d2、T_d3、…、T_dq,上述q个下行车次的发车时刻分别为:6:15、6:25、6:35、6.45、…、22:15。
排班计划中包括每个车辆所对应的车次序列。例如,车辆1对应的车次序列包括:上行车次T_u1、下行车次T_d3、上行车次T_u4、…。车辆N对应的车次序列包括:下行车次T_d1、上行车次T_u3、下行车次T_dq、…。由此可见,每个车辆对应的车次序列中,上行车次和下行车次交替出现。
基于上述排班计划,以车辆1为例,车辆1的发车计划如下:在6:00从站点A出发驶向站点B,在6:35从站点B出发驶向站点A,在6:30从站点A出发驶向站点B,以此类推。
在本说明书实施例中,排班所需数据是指对计算设备600对待排班线路进行排班时所需要的数据。排班所需数据为已知量,计算设备600基于排班所需数据能够实现对待排班线路进行车辆排班。
排班所需数据可以包括如下中至少一项:
(1)多个车辆中从上行始发的车辆数和从下行始发的车辆数。
其中,在多个车辆中,有些车辆的第一个车次是上行车次,有些车辆的第一个车次是下行车次。因此,“从上行始发的车辆数”是指第一个车次为上行车次的车辆的数量,“从下行始发的车辆数”是指第一个车次为下行车次的车辆的数量。
(2)待排班线路对应的上行首班发车时刻、上行末班发车时刻、下行首班发车时刻、下行末班发车时刻。
其中,上行首班发车时刻是指上行方向中首次发车的发车时刻,其对应上行发车时刻序列表中的第一个发车时刻。上行末班发车时刻是指上行方向中最后一次发车的发车时刻,其对应上行发车时刻序列表中的最后一个发车时刻。
举例来说,上行发车时刻序列为{6:00,6:10,6:20……,22:00}。则上行首班发车时刻为6:00,上行末班发车时刻是指22:00。
同样地,下行首班发车时刻是指下行方向中首次发车的发车时刻,其对应下行发车时刻序列表中的第一个发车时刻。下行末班发车时刻是指下行方向中最后一次发车的发车时刻,其对应下行发车时刻序列表中的最后一个发车时刻。
举例来说,下行发车时刻序列为{20:30,20:10,19:50……,6:30}。则下行首班发车时刻为20:30,下行末班发车时刻是指6:30。
(3)待排班线路对应的最大发车间隔。
待排班线路对应有发车时刻序列表。假设发车时刻序列表中有M个发车时刻,该M个发车时刻中每相邻两个发车时刻之间的M-1个时间差即为发车间隔,该M-1个发车间隔中的最大值即为最大发车间隔。
(4)待排班线路对应的单程时长。
待排班线路对应的单程时长是指每个车次从起点行驶至终点所花费的总共时长。单程时长可以根据不同的时间段发生变化。比如,待排班线路在高峰时间段的单程时长较平峰时间段大。再比如,待排班线路在周末人流量较少的情况下所需要的单程时长较周内人流量较多的情况下所需要的单程时长小。
(5)待排班线路对应的高峰时段、以及高峰时段内的发车间隔上限。
高峰时段是指车流量和/人流量较大的时间段。高峰时段可以分为早高峰时段和晚高峰时段,比如,在早晨上班时间段7:00至9:00,由于上班的人多采用自己开车或者乘坐公共交通工具等方式,使得马路上车辆和行人汇聚较多,会造成上班时间的早高峰时段。而在晚上下班时间段17:00至19:00,又是下班时间的晚高峰时段。
高峰时段可以对应多个发车间隔。该多个发车间隔可以是相同的,也可以是不同的。在该多个不同的发车间隔中,最大的发车间隔即为高峰时段内的发车间隔上限。
(6)多个车辆中每个车辆对应的目标车次数量和单日最大工作时长。
多个车辆中每个车辆分别对应有发车次数。每个车辆对应的发车次数可以相同,也可以不同。
在公交线路中,每个车辆对应的车次数量若较大,会形成车辆运输资源的浪费,而每个车辆对应的车次数量若较少,又会导致无法获得合理的排班计划。因此,每个车辆对应有一个期望的发车次数。该期望的发车次数即为每个车辆的目标车次数量。
每个车辆对应的单日最大工作时长是指每个车辆从第一个车次对应的发车时刻到最后一个车次对应的到达时刻之间的时长。
(7)午休时间范围和午休时长。
午休时间范围是指车辆司机能够午休的时间段,比如,中午11.30至下午13:00。
午休时长是指午休时间范围的上限与下限之间的时间差。比如,中午11.30至下午13:00为午休时间范围,则午休时长为13:00减去11:30得到的时间差,即一个半小时。
(8)晚餐时间范围和晚餐时长。
关于晚餐时间范围和晚餐时长的定义,与午休时间范围和午休时长的定义类似,具体可以参考午休时间范围和午休时长的定义,此处不再详细介绍。
需要说明的是,上述的排班所需数据的编号(1)至(8)仅代表对其标识和区分,并不代表对其的排序,每项排班所需数据并无优先级顺序。
计算设备600可以基于与用户交互的方式来获得排班所需数据。比如,计算设备600可以通过显示器呈现上述排班所需数据的可填写项,以获得用户在上述排班所需数据的可填写项位置处输入的具体数值。
在一些实施例中,计算设备600可以提供每一项排班所需数据的输入框,用户可以在输入框中直接输入对应的排班所需数据的具体数值。
在另一些实施例中,计算设备600还可以提供每一项排班所需数据的数值可选项,用户可以在可选项中选择对应的排班所需数据的具体数值。
计算设备600可以基于用户输入或选择的排班所需数据的具体数值,以生成排班所需数据。
继续参阅图3,在步骤S120之后,所述方法P100还可以包括如下步骤S140。
S140:基于各个车辆对应的车次,通过发车概率预测模型确定多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率。
在示例实施例中,发车时刻表是多个车辆发车时的时间依据。发车时刻表中首班车发车时刻和末班车发车时刻是已知量,但首班车发车时刻和末班车发车时刻之间的所有发车时刻是未知量。另外,如前所述,发车时刻表中所有发车时刻的数量对应于多个车辆对应的车次。也就是说,多个车辆中的每个车辆的车次都会对应到发车时刻表中的一个发车时刻。但发车时刻表中每个发车时刻与车次之间的对应关系是未知的,即每个发车时刻对应的是哪个车次是未知的,需要通过本说明书实施例的车辆排班方法P100求解获得,为了便于说明,以下将发车时刻表中的每个发车时刻称为发车时刻变量。
多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率表征各个车次在多个发车时刻变量中每个发车时刻变量下的发车可能性大小。一个车次在某个发车时刻变量下的发车概率越大,表明该车次在该发车时刻变量下的发车可能性越大。反之,一个车次在某个发车时刻变量下的发车概率越小,表明该车次在该发车时刻变量下的发车可能性越小。
在实际的车辆排班场景中,许多不同交通线路的营运条件是相似的,或者同一条交通线路只需要在工作日和节假日之间进行局部调整。而机器学习技术拥有从数据中挖掘规律和模式的强大能力。因此,本说明书实施例通过预先训练一发车概率预测模型,并基于发车概率预测模型预测多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率,进而确定上述发车时刻变量的取值以及对应关系。其中,发车概率预测模型可以是预先训练的机器学习模型,比如,图神经网络、树模型、支持向量机等等。
下面结合附图对步骤S140的具体实现方式进行介绍:
图5示出了根据本说明书的实施例提供的发车概率预测过程的流程图。如图5所示,步骤S140可以包括如下步骤:
S140-2:基于各个车辆对应的车次,以及多个车辆对应的多个车次之间的关联关系生成图结构数据。
图结构数据是一个由有限个节点的集合和一个连接节点集合中任意两个节点间的边的集合的数学结构。在图结构数据中,每个节点代表一个对象,节点之间的关联关系采用连接线表示。图结构数据能够更加清晰地表示各个对象之间的关系。
图结构数据中的对象及对象之间的关系可以根据应用场景来确定。以车辆运营场景为例,计算设备600可以以各个车辆中对应的车次中每个车次为节点,并基于各个车辆应的车次之间的关联关系将节点进行连接,得到图结构数据。图结构数据包括多行节点,每行节点对应所述多个车辆中的一个车辆的车次。
其中,各个车辆对应的车次之间的关联关系包括相同班型中发车时刻变量之间的关联关系,以及不同班型中首班发车时刻变量和末班发车时刻变量之间的关联关系。
相同班型是指营运条件相同的车辆,所述不同班型是指营运条件不同的车辆。其中,班型可以根据车辆的营运条件来确定。营运条件可以包括排班所需数据。比如,车辆A和车辆B对应的车次数、最大工作时长、午休时间范围和午休时长、晚餐时间范围和晚餐时长相同,则计算设备600可以识别车辆A和车辆B的班型相同。若车辆A和车辆B对应的车次数、最大工作时长、午休时间范围和午休时长、晚餐时间范围和晚餐时长中至少一项不相同,则计算设备600识别车辆A和车辆B的班型不同。
下面结合附图对图结构数据进行介绍:
图6示出了根据本说明书的实施例提供的图结构数据的示意图。如图6所示,图结构数据包括多行节点,每行节点对应多个车辆中一个车辆的车次。即图结构数据中每行的节点对应一个班次,每行中节点的数量代表该班次下的车次数量。因此,图结构数据也可以理解为是班次-车次图。
图6中的u代表上行车次,d代表下行车次。可以看到,图6中每行分布有多个节点,且每行所分布的节点的数量可以相同,也可以不同。每个节点分别对应一个车次,也分别对应一个发车时刻变量。图6中均为实线圆圈的节点对应的车辆的班型相同,或者均为虚线圆圈的节点对应的车辆班型相同,而实线圆圈的节点对应的车辆的班型和虚线圆圈的节点对应的车辆的班型不同。
针对同一车辆的多个车次,计算设备600可以将多个车次中上行车次和下行车次交替连接。针对相同班型的任意两个车辆,计算设备600可以将两个车辆对应的上行车次一一对应连接,以及将两个车次对应的下行车次一一对应连接。针对不同班型的两个车辆,计算设备600可以将两个车辆各自的始发发车时刻变量和末班发车时刻变量进行连接,从而得到班次-车次图结构数据。
图结构数据中每个节点对应有特征属性数据,特征属性数据是对节点的表示。每个节点对应的特征属性数据可以包括如下至少一项:
(1)每行节点对应的车辆的车次数量。
继续参阅图6,假设每一行对应一个车辆,则每行节点对应的车辆的车次数量是指每一行中节点的总数量,即该车辆对应的车次序列。
(2)每个节点对应的车次的最大工作时长。
关于每个车次对应的最大工作时长可以参见前述排班所需数据中相关内容的介绍,此处不再赘述。
(3)每个节点对应的车次的最小累积单程时长和最大累积单程时长。
上行车次的单程时长的取值范围为20~35分钟,下行车次的单程时长的取值范围为30~50分钟,对某个班次,假设节点1为上行,节点2为下行,节点3为上行,那么节点3的最小累积单程时长为20+30=50分钟,最大累积单程时长为35+50=85分钟。
(4)发车方向。
发车方向可以包括上行方向和下行方向。
(5)每行节点对应的车辆的车次编号。
继续参阅图6,以图结构数据中第一行的所有节点为例,将第一行的所有节点按照从图中由左到右的顺序依次编号为1、2、3、……、8,每个数字即为各个节点对应的车辆的车次编号。
(6)每个节点对应的发车时刻变量的取值范围。
每个节点对应的发车时刻变量的取值不是固定的一个数值。受一些因素影响,每个节点可能不一定能够按照固定的发车时刻进行发车,因此,其发车时刻变量的取值是在一个时间范围内浮动。
(7)每个节点对应的发车顺序。
发车顺序可以理解为是在各个节点对应的发车序列中为第几个发车顺序。
(8)发车间隔的取值范围。
发车时刻表中每两个相邻的发车时刻之间的时间差也可能不是固定的。因此,发车间隔的取值也是在一个时间范围内浮动。
其中,特征属性数据可以由计算设备600基于与用户的交互来获得。具体获得过程可以参见排班所需数据的获得过程,此处不再赘述。
继续参阅图5,在步骤S140-2之后,所述步骤S140的具体实现方式还可以包括如下步骤S140-4。
S140-4:将图结构数据输入发车概率预测模型,确定多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率。
在获得图结构数据之后,计算设备600可以将各个发车时刻变量的车次顺序预测问题表示为图结构数据的节点多分类(graph node multi-class classification)问题。
预设图神经网络(Graph Neural Network,GNN)是一类使用神经网络来学习图结构数据的神经网络,其可以提取和发掘班次-车次图结构数据中的特征,满足多分类的任务需求。即计算设备600可以采用预设图神经网络对图结构数据进行至少一次特征提取,得到目标图结构数据,并基于目标图结构数据预测各个发车时刻变量的候选发车顺序的概率分布结果。其中,预设图神经网络的结构与上述的图结构数据的结构相同。预设图神经网络可以是图卷积神经网络(Graph Convolutional Network,GCN)。
预设图神经网络可以包括多个堆叠的图卷积层,比如4个图卷积层堆叠在一起。多个堆叠的图卷积层中每个图卷积层分别对上一个图卷积层的输出执行图卷积操作,并将图卷积结果输入至下一个图卷积层继续进行图卷积操作,以此类推,最后一个图卷积层的输出即为目标图结构数据。
为了便于说明,本说明书实施例以4个图卷积层为例,将多个堆叠的图卷积层按照卷积顺序依次记为图卷积层0、图卷积层1、图卷积层2和图卷积层3,来对各个图卷积层的卷积操作过程进行介绍。
继续参阅图6,在利用发车概率预测模型基于图结构数据预测发车概率时,计算设备600首先将图结构数据输入至图卷积层0进行一次图卷积操作,得到新的图结构数据1(图中矩形方块示出);然后,计算设备600将新的图结构数据1输入至图卷积层1继续进行图卷积操作,得到新的图结构数据2(图中矩形方块示出);进而,计算设备600将新的图结构数据2输入至图卷积层2继续进行图卷积操作,得到新的图结构数据3(图中矩形方块示出);最后,计算设备600将新的图结构数据3输入至图卷积层3继续进行图卷积操作,得到新的图结构数据4(图中矩形方块示出)。新的图结构数据4即为最终的目标图结构数据。
在上述图卷积操作过程中,计算设备600是基于每个节点的邻居节点的特征表示(特征属性数据)来更新该节点自身的特征表示。具体的,计算设备600可以采用加权求和、平均值、累加和等方式来更新每个节点的特征表示。以平均值为例,上述多个图卷积层中每个图卷积层的卷积操作可以表示为如下公式:
式中,
根据上述公式(1)可知,计算设备600在更新节点i在第k’+1个图卷积层的特征表示的过程中,是将节点i在第k’个图卷积层的特征表示
以图6中第1行第2个节点(以下称为节点12)为例,节点12的邻居节点(在图中与节点12具有连接关系的节点)为节点11、节点13和节点22,计算设备600是将节点12的所有邻居节点11、邻居节点13和邻居节点22在第k’个图卷积层的特征表示求平均值,再和节点11在第k’个图卷积层的特征表示累加,最后经过单层感知机,从而得到节点i在第k’+1个图卷积层的新的特征表示。
本说明书实施例中多层堆叠的图卷积层的每一层都会对上一层的节点表示进行进一步的加工和融合,以获得一个新的特征表示。这个新的特征表示不仅包括节点自身的特征表示,还考虑了节点之间的关系。也就是说,每个节点都受到邻居节点的影响,形成一种信息传递的模式。这种层次化的处理使得GNN能够在不同抽象层次上理解图结构数据,能够对图结构数据中每个节点进行更深层次的特征表示,从而更加准确地预测每个发车时刻变量下车次顺序的概率。
其中,图神经网络可以包括图卷积网络GCN、图注意力网络等各种图神经网络的变体。
计算设备600在提取到各个节点的深层次特征表示之后,便可以采用masksoftmax激活函数来生成每个发车时刻变量的候选发车顺序的多项概率分布结果。继续参阅图6,图6中最左边的大括号中y1表示排班计划中第1个节点,每个大括号中等号右边的1至M表示发车时刻表中发车时刻变量的编号。也就是说,计算设备600最终获得的是各个节点中每个节点在发车时刻表中每个发车时刻变量下的发车概率的多项概率分布结果,即在发车时刻表中每个发车时刻变量下的各个车次的发车概率的多项概率分布结果。
在本步骤中,发车概率预测模型为预先训练的机器学习模型。也就是说,计算设备600在应用发车概率预测模型预测发车概率之前,通常需要训练发车概率预测模型。因此,发车概率预测模型的训练过程可以如下:比如,计算设备600获得训练样本及其对应的标签,并基于训练样本及其对应的标签和损失函数对待训练的图神经网络进行训练,直至待训练的图神经网络收敛,得到发车概率预测模型。
其中,发车概率预测模型的训练样本包括多个排班计划及每个排班计划对应的真实发车顺序,训练目标包括约束发车概率预测模型输出的预测发车顺序与真实发车顺序之间的差异小于预设差异。
其中,训练样本中多个排班计划中的每个排班计划中包括多个车辆中每个车辆对应的至少一个车次,每个车次对应有发车时刻。将所有车次对应的发车时刻按照由早到晚进行排序,即可得到真实发车顺序。该真实发车顺序即为该训练样本对应的标签。
损失函数可以为交叉熵损失函数。计算设备600可以基于训练过程中预测的各个发车时刻变量的候选发车顺序的概率分布结果,确定预测发车顺序。预测发车顺序可以理解为是发车时刻表中每个发车时刻变量对应的车次。之后,计算设备600可以基于预测发车顺序和真实发车顺序之间的差异确定发车概率预测损失,并基于发车概率预测损失对待训练的图神经网络进行收敛,从而得到发车概率预测模型。其中,收敛的条件可以是发车概率预测损失小于预设损失,训练次数达到预设训练次数,或者模型精度达到预设精度等等。
继续参阅图3,在步骤S140之后,所述方法P100还可以包括如下步骤S160。
S160:基于每个发车时刻变量下的各个车次的发车概率和排班所需数据,确定排班结果。
其中,排班结果包括多个发车时刻以及车次与发车时刻之间的对应关系。
继续参阅图6,可以看到,该多项概率分布结果是一个(w
矩阵中的每一行可以理解为是班次-车次图中w
计算设备600将上述多项概率分布结果拆分成上行方向的多项概率分布结果和下行方向的多项概率分布结果。上行方向的多项概率分布结果可以表示为w
参见前述介绍的上行排序矩阵和下行排序矩阵的表达式,可以发现,多项概率分布结果与排序矩阵之间具有对应关系。即上行方向的多项概率分布结果中每一行的w
排序矩阵中的变量的取值具有明确的场景含义。以排序矩阵中某个元素b
由于排序矩阵中每行之和为1,且每列之和为1,且每行只有1个元素为1,以及每列只有1个元素为1。因此,排序矩阵中的所有变量中只有很小一部分取值为1,计算设备600预测这部分取值为1的变量较为困难。但是,计算设备600确定哪些变量取值为0是相对容易的。因此,计算设备600可以通过对各发车时刻变量的候选发车顺序进行预测,从而基于每个发车时刻变量下的各个车次的发车概率确定排序矩阵中极有可能取值为0的变量,以减少排序矩阵的求解量,进而提高车辆排班效率。
下面结合附图对该过程进行详细介绍:
图7示出了根据本说明书的实施例提供的基于发车概率确定排班过程的流程图。如图7所示,步骤S160的具体实现方式可以包括如下步骤:
S160-2:基于每个发车时刻变量下的各个车次的发车概率,确定多个发车时刻变量中每个发车时刻变量下发车概率小于预设概率阈值的目标车次。
计算设备600可以将每个节点的预测概率作为该节点对应的发车顺序的推理置信度。如果第j个发车时刻变量属于第M个发车顺序的置信度极低,则意味着排序矩阵中的布尔变量b
也就是说,计算设备600是将图结构数据中的各个节点对应的发车概率与预设概率阈值进行比较。在某个节点对应的发车概率小于预设概率阈值的情况下,将该节点对应的车次确定为目标车次。目标车次代表该节点对应的车次一定不会分配到该节点对应的发车时刻。
在一些实施例中,发车概率小于预设概率阈值的节点的数量可能为多个,此时计算设备600可以将发车概率最小的节点对应的车次确定为目标车次。
S160-4:基于目标车次和排班所需数据,对多个发车时刻变量对应的多个发车时刻与对应关系进行联合求解,得到排班结果。
计算设备600在获得目标车次之后,便可以基于目标车次,确定待求解的排序矩阵中与目标车次对应位置的元素取值为预设值,得到待求解的目标排序矩阵,并采用预设排班模型基于目标排序矩阵和排班所需数据,对多个发车时刻变量对应的多个发车时刻,以及多个车次和多个发车时刻之间的对应关系进行联合求解,得到排班结果。
其中,排序矩阵用于约束联合求解时多个车次中上行车次的发车时刻和下行车次的发车时刻分别为有序序列。
举例来说,上行方向的多项概率分布结果中,第1行第3个元素对应的概率值小于预设概率阈值,则是将上行排序矩阵中第1行第3个元素对应的元素取值为预设值。其中,预设值可以是0。
在获得目标排序矩阵之后,计算设备600便可以基于目标排序矩阵和排班所需数据进行车辆排班。
图8示出了根据本说明书的实施例提供的车辆排班的流程图。如图8所示,S160-中联合求解的具体实现方式可以包括如下步骤:
S720:基于目标排序矩阵和多个车次中上行车次的发车时刻及下行车次的发车时刻,确定目标函数,目标函数以多个车辆对应的各个车次的发车时刻作为未知量。
在本说明书实施例中,计算设备600将多个车辆记为N个车辆,并将N个车辆对应的车次记为M个车次,然后以N个车辆对应的各车次的发车时刻作为未知量(变量)生成目标函数。举例而言,将第i个车辆对应的车次数量记为M
本领域技术人员能够理解,上述生成的目标函数,虽然显式上只包含一种未知量x
在一些实施例中,计算设备600可以以最大化所述排班结果对应的发车间隔平滑度作为排班目标,确定所述目标函数。
其中,发车间隔平滑度表征的是发车间隔的波动程度或者变化的趋势。当发车间隔的波动程度较大(例如某个时间区间内发车间隔多次发生变化)时,发车间隔平滑度较低,将发车间隔的波动程度较小(例如某个时间区间内发车间隔保持不变)时,发车间隔平滑度较高。举例而言,假设以时间作为横轴,以发车间隔作为纵轴,基于M个车次中相邻车次之间的发车间隔绘制出发车间隔曲线(折线)。当发车间隔平滑度较高时,该曲线相对稳定,波动较小(即发生弯折的位置较少),大部分时间区间内呈现为水平直线。当发车间隔平滑度较低时,该曲线波动加大(即在较多的位置发生弯折),呈现水平直线的时间区间较少且较短。
在一些实施例中,计算设备600在以最大化所述排班结果对应的发车间隔平滑度作为排班目标的情况下,可以采用如下方式生成目标函数。
(1)基于目标排序矩阵和所述多个车次中所述上行车次的发车时刻的乘积,得到上行发车时刻向量,并基于所述上行发车时刻向量确定上行发车间隔向量。
为了方便描述,本说明书实施例中将第i个车辆对应的第j个车次记为T
T
其中,x
所有车辆对应的上行车次的发车时刻的集合可以记为
将集合
利用上行排序矩阵
进一步的,可以对上行发车时刻向量
其中,
(2)基于所述目标排序矩阵和所述多个车次中所述下行车次的发车时刻的乘积,得到下行发车时刻向量,并基于所述下行发车时刻向量确定下行发车间隔向量。
所有车辆对应的下行车次的发车时刻的集合可以记为
将集合
/>
利用下行排序矩阵
进一步的,可以对下行发车时刻向量
其中,
(3)基于上行发车间隔向量和所述下行发车间隔向量,确定目标函数。
在计算设备600得到上行发车间隔向量
例如,计算设备600可以对上行发车间隔向量
其中,
计算设备600还可以对下行发车间隔向量
其中,
进一步的,计算设备600可以基于上行发车间隔差分向量
其中,‖*‖
由上式可见,目标表达式
继续参阅图7,在步骤S720之后,S160-4中的联合求解还可以包括步骤S740。
S740:基于排班所需数据生成目标函数的排班约束条件。
在一些实施例中,排班约束条件可以包括下述的条件A至条件D。
条件A:任意上行车次的发车时刻不早于上行首班发车时刻,且不晚于上行末班发车时刻。假设上行首班发车时刻记为
条件B:第一个上行车次的发车时刻等于上行首班发车时刻,且最后一个上行车次的发车时刻等于上行末班发车时刻。条件B可以表达为:
其中,
条件C:任意下行车次的发车时刻不早于下行首班发车时刻,且不晚于下行末班发车时刻。假设下行首班发车时刻记为记为
条件D:第一个下行车次的发车时刻等于下行首班发车时刻,且最后一个下行车次的发车时刻等于下行末班发车时刻。条件D可以表达为:
其中,
在一些实施例中,所述排班所需数据可以包括目标线路对应的最大发车间隔。通常,该最大发车间隔是基于目标线路的运营需求而预先定义的。该情况下,排班约束条件可以包括下述的条件E。
条件E:任意相邻两个车次之间的发车间隔不能超过最大发车间隔。假设目标线路所要求的最大发车间隔记为H
其中,
在一些实施例中,所述排班所需数据还可以包括单程时长δ
其中,
条件F:任意车次的发车时刻与单程时长之和等于到达时刻,且同一车辆对应的相邻两个车次正常接续(即,同一车辆的第j+1个车次的发车时刻不早于第j个车次的到达时刻)。条件F可以表达为:
在一些实施例中,所述排班所需数据还可以包括每个车辆对应的最大车次数量、以及每个车辆的单日最大工作时长。该情况下,所述排班约束条件还可以包括下述条件G。
条件G:每个车辆的总工作时长不大于所述单日最大工作时长。假设每个车辆的单日最大工作时长记为L
在一些实施例中,所述排班所需数据还可以包括高峰时段、以及高峰时段内的发车间隔上限。该情况下,所述排班约束条件还可以包括下述条件H。
条件H:在高峰时段内的相邻两个车次之间的发车间隔不超过所述高峰时段内的发车间隔上限。假设高峰时段的起始时刻记为
在一些实施例中,所述排班所需数据还可以包括午休时间范围、以及每个车辆的午休时长。该情况下,所述排班约束条件还可以包括下述条件I。
条件I:每个车辆的午休时段位于所述午休时间范围内,并且,所述午休时段位于相邻两个车次之间。假设第i个车辆的午休时段的起始时刻记为l
l
l
l
满足其一
在一些实施例中,所述排班所需数据还可以包括晚餐时间范围、以及每个车辆的晚餐时长。该情况下,所述排班约束条件还可以包括下述条件J。
条件J:每个车辆的晚餐时段位于所述晚餐时间范围内,并且,所述晚餐时段位于相邻两个车次之间。假设第i个车辆的晚餐时段的起始时刻记为l
l
l
l
满足其一
需要说明的是,上述条件A至条件J作为一些可能的示例。在实际交通运营中,基于目标线路的实际运营需求,计算设备600生成的排班约束条件可以包括条件A至条件J中的一项或者多项。
在一些实施例中,所述排班约束条件满足线性,换言之,所述排班约束条件被表达为线性表达式。也就是说,计算设备600可以基于所述排班所需数据生成满足线性的排班约束条件。本领域技术人员能够理解,当所述排班约束条件满足线性时,使得目标函数更易于求解,从而能够在较短的求解时间内得到最优解。
在一些实施例中,计算设备600可以采用如下方式生成满足线性的排班约束条件:基于所述排班所需数据生成非线性的约束条件(如前述条件A至条件J中的一项或者多项),进而对所述非线性的约束条件进行线性化处理,得到满足线性的排班约束条件。例如,计算设备600可以采用多种线性化技术,包括但不限于大M法、引入辅助布尔变量等技术,对上述非线性的约束条件进行线性化处理,得到满足线性的排班约束条件。
本说明书实施例中,计算设备600通过将非线性的约束条件转换为满足线性的排班约束条件,使得较为复杂的营运需求被转换为易于求解的线性约束表达式,能够减低后续步骤中目标函数的求解难度,使得目标函数更易于求解,从而计算设备600能够在较短的求解时间内得到最优解。
需要说明的是,本说明书实施例对于S720和S740的执行顺序不做限定,二者的执行顺序可以互换,或者二者还可以同时执行。
继续参阅图7,在步骤S740之后,S160-4中的联合求解还可以包括步骤S760。
S760:基于排班所需数据和排班约束条件对目标函数进行多个发车时刻变量对应的多个发车时刻,以及多个车次和多个发车时刻之间的对应关系的联合求解,得到排班结果。
计算设备600在确定出目标函数和排班约束条件之后,可以在排班约束条件下对目标函数执行联合求解,即同步求解“多个车辆对应的所有车次的发车时刻”以及“多个车次和多个发车时刻之间的对应关系”,从而得到排班结果。需要说明的是,计算设备600对目标函数的求解方式可以存在多种,例如可以开源求解器进行求解,还可以采用其他方式进行求解,本说明书实施例对此不做限定。
在一些实施例中,考虑到实际交通运营中相邻车次之间的发车间隔通常是整数分钟,因此,计算设备600可以将各车次的发车时刻表达为以分钟为单位的整数,即,将变量x
例如:假设在第n
第1个车次的发车时刻可以记为T
第2个车次的发车时刻可以记为T
第3个车次的发车时刻可以记为T
…
第n
第n
第n
…
第n
这样,普通的规划求解问题可以被转换为整数规划求解问题。计算设备600可以在排班约束条件下,采用整数规划算法对目标函数进行联合求解从而得到排班结果。例如,在一些实施例中,计算设备600可以采用开源的整数约束规划求解器(Solving ConstraintInteger Programs,SCIP)对目标函数进行求解。实践证明,在排班约束条件满足线性的条件下,采用SCIP可以在较短的时间内(例如16分钟内)求解得到满足所述排班约束条件的最优解或者近似最优解。
由此可见,本说明书实施例通过采用整数规划算法对目标函数进行求解,使得排班结果中各车次的发车时刻均为以分钟为单位的整数,也就是说,能够求解得到在满足排班约束条件下的最优整数解或者接近最优整数解,从而更加符合实际交通运营的需求。
需要说明的是,计算设备600在对目标函数
本说明书实施例中,计算设备600基于发车概率与预设概率阈值的比较,从而将排序矩阵中那些极有可能取值为0的变量的取值固定,进而只需要关注搜索空间更小的subINLP(Integer Nonlinear Programming,整数非线性规划)问题的求解。其中,subINLP代表INLP问题的子问题。
S180:输出排班结果。
计算设备600在得到排班结果之后,可以输出排班结果。在一些实施例中,若计算设备600作为客户端200,则计算设备600可以通过显示屏显示排班结果。在一些实施例中,若计算设备600作为服务器300,则计算设备600可以向客户端200发送排班结果,以便客户端展示该排班结果。
在一些实施例中,为了更加直观地展示排班结果,计算设备600在得到排班结果之后,可以基于排班结果所包含的所有车次的发车时刻、以及所有车辆的车次与发车时刻之间的对应关系,生成车辆排班图表。进而,计算设备600可以通过显示屏显示该车辆排班图表。或者,计算设备600可以向其他设备(例如客户端200)发送该车辆排班图表,以便通过其他设备以图表形式展示该排班结果。
在客户端200得到排班结果之后,可以对排班结果进行展示。图9示出了根据本说明书的实施例提供的排班结果的图表展示示意图。如图9所示,计算设备600可以基于排班结果生成车辆排班图表,并通过显示屏展示该车辆排班图表。在该车辆排班图表中,横轴表示时刻,纵轴表示车辆的标识。用户通过该车辆排班图表,可以直观地获知每个车辆对应的每个车次的发车时刻、单程时长和到达时刻。在每个车辆对应的车次序列中,上行车次和下行车次间隔出现。并且,车辆排班图表中还展示了每个车辆对应的午休时段和晚餐时段。调度人员基于该车辆排班图表可以便捷地对车辆进行调度。
基于图9所示的排班结果,对所有上行车次的发车时刻进行排序,并分别计算相邻两个车次之间的时间间隔,进而可以绘制得到所述排班结果对应的上行发车间隔曲线。类似的,基于图9所示的排班结果,对所有下行车次的发车时刻进行排序,并分别计算相邻两个车次之间的时间间隔,进而可以绘制得到所述排班结果对应的下行发车间隔曲线。
图10示出了图9所示排班结果对应的上行发车间隔曲线的示意图,图11示出了图9所示排班结果对应的下行发车间隔曲线的示意图。在图10和图11中,横轴表示时刻,纵轴表示发车间隔(以分钟为单位)。参见图10和图11,无论是在上行方向,还是下行方向上,发车间隔的变化次数均较少,发车间隔曲线在多个时间区间内均表现为水平直线。通过图10和图11所示的发车间隔曲线可以看出,采用本说明书实施例提供的车辆排班方法进行排班,使得排班结果中各车次之间的发车间隔波动较小,满足发车间隔平滑度最大化的排班目标。
综上所述,本说明书提供的车辆排班方法和系统,在获得待排班线路的排班所需数据之后,基于参与待排班线路的排班过程的多个车辆对应的车次,通过预先训练的发车概率模型对发车时刻表中多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率进行预测,并基于预测结果和排班所需数据进行车辆排班,以对多个发车时刻以及所述车次与发车时刻之间的对应关系进行求解,获得排班结果。该方案中,由于预测的多个发车时刻变量中每个发车时刻变量下的各个车次的发车概率与待求解的未知量之间具有对应关系,因此,通过每个发车时刻变量下的各个车次的发车概率能够确定待求解的未知量中部分变量的取值,从而减少待求解的未知量,提高计算效率,进而提高排班效率。另外,基于班次-车次之间的关系生成图结构数据,并采用图结构数据来预测各个发车时刻变量中每个发车时刻变量下的各个车次的发车概率,能够更好地挖掘各个车次之间的关系,从而更加准确地预测各个发车时刻变量中每个发车时刻变量下的各个车次的发车概率,进而提高车辆排班的合理性。
本说明书另一方面提供一种非暂时性存储介质,存储有至少一组用来进行车辆排班的可执行指令。当所述可执行指令被处理器执行时,所述可执行指令指导所述处理器实施本说明书所述的车辆排班方法P100的步骤。在一些可能的实施方式中,本说明书的各个方面还可以实现为一种程序产品的形式,其包括程序代码。当所述程序产品在计算设备600上运行时,所述程序代码用于使计算设备600执行本说明书描述的车辆排班方法P100的步骤。用于实现上述方法的程序产品可以采用便携式紧凑盘只读存储器(CD-ROM)包括程序代码,并可以在计算设备600上运行。然而,本说明书的程序产品不限于此,在本说明书中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统使用或者与其结合使用。所述程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。所述计算机可读存储介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读存储介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。可读存储介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、RF等等,或者上述的任意合适的组合。可以以一种或多种程序设计语言的任意组合来编写用于执行本说明书操作的程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如Java、C++等,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在计算设备600上执行、部分地在计算设备600上执行、作为一个独立的软件包执行、部分在计算设备600上部分在远程计算设备上执行、或者完全在远程计算设备上执行。
上述对本说明书特定实施例进行了描述。其他实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者是可能有利的。
综上所述,在阅读本详细公开内容之后,本领域技术人员可以明白,前述详细公开内容可以仅以示例的方式呈现,并且可以不是限制性的。尽管这里没有明确说明,本领域技术人员可以理解本说明书需求囊括对实施例的各种合理改变,改进和修改。这些改变,改进和修改旨在由本说明书提出,并且在本说明书的示例性实施例的精神和范围内。
此外,本说明书中的某些术语已被用于描述本说明书的实施例。例如,“一个实施例”,“实施例”和/或“一些实施例”意味着结合该实施例描述的特定特征,结构或特性可以包括在本说明书的至少一个实施例中。因此,可以强调并且应当理解,在本说明书的各个部分中对“实施例”或“一个实施例”或“替代实施例”的两个或更多个引用不一定都指代相同的实施例。此外,特定特征,结构或特性可以在本说明书的一个或多个实施例中适当地组合。
应当理解,在本说明书的实施例的前述描述中,为了帮助理解一个特征,出于简化本说明书的目的,本说明书将各种特征组合在单个实施例、附图或其描述中。然而,这并不是说这些特征的组合是必须的,本领域技术人员在阅读本说明书的时候完全有可能将其中一部分设备标注出来作为单独的实施例来理解。也就是说,本说明书中的实施例也可以理解为多个次级实施例的整合。而每个次级实施例的内容在于少于单个前述公开实施例的所有特征的时候也是成立的。
本文引用的每个专利,专利申请,专利申请的出版物和其他材料,例如文章,书籍,说明书,出版物,文件,物品等,可以通过引用结合于此。用于所有目的全部内容,除了与其相关的任何起诉文件历史,可能与本文件不一致或相冲突的任何相同的,或者任何可能对权利要求的最宽范围具有限制性影响的任何相同的起诉文件历史。现在或以后与本文件相关联。举例来说,如果在与任何所包含的材料相关联的术语的描述、定义和/或使用与本文档相关的术语、描述、定义和/或之间存在任何不一致或冲突时,使用本文件中的术语为准。
最后,应理解,本文公开的申请的实施方案是对本说明书的实施方案的原理的说明。其他修改后实施例也在本说明书的范围内。因此,本说明书披露的实施例仅仅作为示例而非限制。本领域技术人员可以根据本说明书中的实施例采取替代配置来实现本说明书中的申请。因此,本说明书的实施例不限于申请中被精确地描述过的实施例。