一种大模型高效调优的任意形状智能分割算法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及医学图像分割的技术领域,具体涉及一种大模型高效调优的任意形状智能分割算法。
背景技术
近年来,越来越多的大模型的出现如CLIP,ChatGPT,BERT等,这些大模型在庞大的数据集进行训练得到,且在广泛的下游任务中具有强大的泛化能力。而SAM(Segment-Anything-Model)就是最近由Meta公司提出的一个能够广泛的适应各种下游分割任务的一个基础大模型。它主要由三部分组成,一个强大的图像编码器,提示编码器和掩码解码器。SAM允许用户在分割图片的时,通过手动添加点或者边界框作为提示送入网络。
虽然SAM能够作为一个强大的通用视觉分割的模型,但是许多研究已经表明,在医学图像分割上还是不是很理想。SAM在医学图像上失败的主要原因是缺乏训练数据,尽管SAM在训练过程中建立了一个复杂而有效的数据库,但是其中的医疗数据案例很少,且医学图像与自然图像的差别较大,比如医学图像的边界比较模糊,具有较低对比度,和视觉识别不准确的特征。
目前,使通用大模型适应下游任务的最常见方法是对所有模型参数进行微调。然而,这会导致为每个任务提供单独的微调模型参数副本,当服务于执行大量任务的模型时,这是非常昂贵的。随着基础模型规模的不断扩大,这个问题尤为突出。为了缓解这个问题,已经提出了一些轻量级的替代方案,仅更新少量额外参数,同时保持大多数预训练参数冻结。如使用叫适配器的小神经模块插入到预训练网络的每一层,并且在微调时仅训练适配器。
随着医学成像设备的快速发展和普及,成像技术在临床中得到了广泛应用,成为了开展疾病诊断、手术计划制定、预后评估、随访不可或缺的辅助手段。医学图像往往在诊断和治疗过程中起着至关重要的作用。因此,医学图像成为了是临床分析和医疗干预的最重要的证据来源之一。
医学图像分割能够从特定组织图像中提取关键信息,是实现医学图像可视化关键步骤。分割后的图像被提供给医生用于组织体积的定量分析、诊断、病理改变组织的定位、解剖结构的描绘、治疗计划等不同任务。医学图像信息量巨大,临床上手工勾画医学图像目标区域是一件费时费力的工作,给临床医生的日常工作增加了很大负担。
因此,研究一个基于对基础大模型进行微调的大模型高效调优的任意形状智能分割算法是一个急需解决的问题。
发明内容
本发明的目的是提供一种高效的,准确的大模型高效调优的任意形状智能分割算法。
本发明的目的是这样实现的:
一种大模型高效调优的任意形状智能分割算法,包括以下步骤:
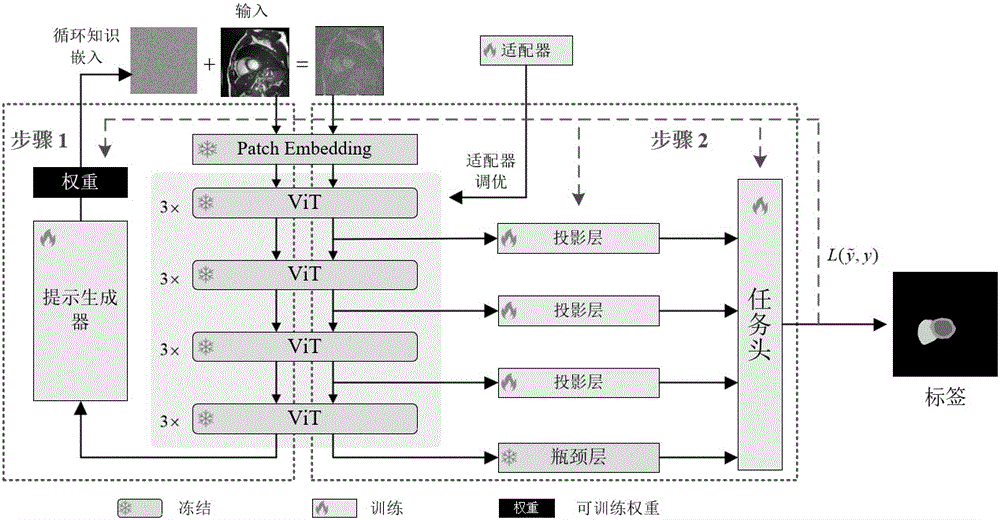
步骤一:对医学图像进行预处理,使用滤波器对医学图像的图片进行去噪,对图像的进行归一化,使用随机旋转对图像进行增强;将步骤一构成网络的输入图像传入搭建好的模型进行学习,以消除图像中无关的信息,增强有关信息的可学习性;所述模型包括循环先验知识嵌入模块、语义相关高效参数调优、任务判别投影层聚合模型中深浅特征和特定任务头进行分割;
步骤二:循环先验知识嵌入模块的构建,通过循环先验知识嵌入得到可调提示,缩小预训练任务与下游任务之间的任务分布偏移,使得预训练模型理解任务;
步骤三:语义相关适配器调优,同时调整多头注意力层和MLP层,高效利用增加的小部分参数学习语义相关特征,达到高效参数调优的目的;
步骤四:任务判别投影层聚合模块的构建,通过任务判别投影层,将ViT主干中不同阶段的深浅特征投影并聚合到新的数据空间,学习特定任务的判别特征,得到具有高度任务相关性的图像编码特征;
步骤五:特定任务头分割,通过上采样和多尺度卷积对图像编码特征进行解码,最终通过特定的解码器得到任务相关的分割掩码。
所述步骤二的具体操作如下:通过给图像的每个像素附加相关视觉提示来增强输入图像,自适应的改变图像语义;使用SAM的冻结参数的编码器模块,得到的图像特征是在模型预训练的先验知识上学习到,再通过循环先验知识嵌入模块,生成可调提示,下游数据重新表述为预训练阶段学习到的模型知识,使任务分布协同于模型的原始分布,让预训练模型能够理解任务;视觉提示和原图像大小相同,通过提示模块为每个单独的图像产生相应的视觉提示,灵活的改变原始图像的语义信息。
所述步骤三的具体操作如下:使用平行于ViT主干的适配器,它并行的插入ViT主干,能够同时调整多头注意力层和前向传播层,利用适配器所增加的小部分参数;通过部分参数量的增加,调整冻结的ViT主干,在不破坏其参数泛化性的情况下,学习语义相关特征,使其能够适应各种下游任务,达到高效调优的效果。
所述步骤四的具体操作如下:SAM是基于提示的无差别分割模型,且在原始的SAM的编码器中,使用了大量级联的ViT模块,通过任务判别投影层,将ViT主干中不同阶段的浅层特征和深层特征投影到一个新的数据空间中,聚合并学习对特定任务的判别特征,得到具有高度任务相关性的图像嵌入。
所述步骤五的具体操作如下:使用多尺度卷积,同时考虑不同感受野下的特征,使用了分组卷积,将数据的通道分为多个组进行卷积操作,能够在减少参数量的同时,提高模型的计算效率和模型的训练速度,减少过拟合的风险,最后通过解码器得到输出分割掩码。
本发明的有益效果是:本发明使用了循环先验知识嵌入模块,根据模型先验知识的理解,能够有效生成可调视觉提示,自适应的改变图像语义。使用语义相关适配器能够同时调优ViT模块中冻结的多头注意力层和前向传播层,可以更好的利用适配器增加的小部分参数,达到高效调优的目的。使用任务判别投影层聚合ViT主干中不同阶段的深浅特征,学习特定任务的判别特征,最终通过任务头得到高质量分割掩码。经过实验表明,本发明模型可训练参数量只有总参数量的7%,且在心脏数据集上的分割结果分数达到91.48%。
附图说明
图1为本发明的整体流程图;
图2为本发明中平行适配器调优模块。
具体实施方式
以下结合附图和实施例对本发明作进一步说明。
一种大模型高效调优的任意形状智能分割算法,包括以下步骤:
步骤一:对医学图像进行预处理,如调整图像均值和方差;使用滤波器对医学图像的图片进行去噪,对图像的进行归一化,使用随机旋转对图像进行增强,最终得到输入数据;将步骤一构成网络的输入图像传入搭建好的模型,进行学习;所述模型包括循环先验知识嵌入模块、语义相关高效参数调优、任务判别投影层聚合模型中深浅特征和特定任务头进行分割。
步骤二:循环先验知识嵌入模块的构建
如图1中所示的提示生成器,主要由一系列级联的逆卷积和非线性层构成,每次卷积维度之后维度减半,特征大小扩张一倍。将预训练模型得到的图像嵌入送入提示生成器后,最后的输出为和输入图像大小一致的可调提示,在通过一个可学习权重添加到输入图像上,实现自适应的调整图像语义。带有提示符的图像
z
其中z
步骤三:语义相关适配器调优
如图2中所示,我们的语义相关适配器是平行的插入到每一个ViT模块中,冻结ViT模块中的所有参数,只训练并行的适配器。该适配器通过只增加很小的一部分参数,同时对ViT模块中所有参数进行高效调优,学习语义相关特征。使得冻结的模型适应特定的下游任务。适配器可以表示为:
Adapter(X)=X+σ(XW
其中,X∈R
模型特征通过一个ViT模块的输出可以表示为:
h←h+s·Δh(4)
Δh=Adapter(h)(5)
其中,s∈[0,1]为平行适配器的可训练放缩参数。
SAM的编码器由N个ViT模块的级联组合而成,我们的平行适配器则并行的插入每一个ViT模块中,通过更新一小部分参数,高效的微调整个冻结的编码器,使得模型适应下游任务。
步骤四:任务判别投影层聚合模块的构建
SAM是基于提示的无差别分割模型,且由于SAM是基础大模型,模型的深度很深,到了训练的后面阶段,图像的浅层特征已经被覆盖和遗忘,但对于医学图像而言,图像具有丰富的浅层特征如形状轮廓等,对于得到优质的分割掩码十分重要,所以我们使用任务判别投影层,将ViT主干中不同阶段的浅层特征和深层特征投影到一个新的数据空间中,聚合并学习对特定任务的判别特征,得到具有高度任务相关性的图像嵌入。该聚合过程可以描述为:
F
F
F′
步骤五:特定任务头分割
对于特定的任务头,在我们的医学图像分割下游任务,我们使用了多尺度卷积,同时考虑不同感受野下的特征。使用分组卷积,将数据的通道分为多个组进行卷积操作,能够在减少参数量的同时,提高模型的计算效率和模型的训练速度,减少过拟合的风险,最后通过一个解码器得到输出分割掩码。
本发明公开了一种大模型高效调优的任意形状智能分割算法,我们使用了循环先验知识嵌入模块,根据模型先验知识的理解,能够有效生成可调视觉提示,自适应的改变图像语义。使用语义相关适配器能够同时调优ViT模块中冻结的多头注意力层和前向传播层,可以更好的利用适配器增加的小部分参数,达到高效调优的目的。使用任务判别投影层聚合ViT主干中不同阶段的深浅特征,学习特定任务的判别特征,最终通过任务头得到高质量分割掩码。经过实验表明,我们的模型可训练参数量只有总参数量的7%,且在心脏数据集上的分割结果分数达到91.48%。